Descripción de los almacenamientos de datos
Un data warehouse es un almacén centralizado y estructurado diseñado para consultas analíticas e informes. A diferencia de las bases de datos operativas que controlan las transacciones empresariales diarias, un data warehouse consolida los datos de varios orígenes en un formato optimizado para el análisis.
La creación de una data warehouse moderna normalmente implica:
- Ingesta de datos : traslado de datos desde sistemas de origen al almacenamiento.
- Data storage: almacenamiento de los datos en un formato optimizado para análisis.
- Procesamiento de datos : transformación de los datos en un formato listo para su consumo por parte de las herramientas analíticas.
- Análisis y entrega de datos : análisis de los datos para obtener información y entregarlos a la empresa.
Diseño de un data warehouse
Los almacenes de datos contienen tablas organizadas en un esquema optimizado para el modelado multidimensional. En este enfoque, se agrupan datos numéricos relacionados con eventos por distintos atributos. Por ejemplo, puede analizar el importe total pagado por los pedidos de venta de una fecha concreta o en un almacén determinado.
Tablas de un almacén de datos
Organizas tablas de almacén de datos para admitir un análisis eficaz de grandes cantidades de datos. Esta organización, conocida como modelado dimensional, implica estructurar tablas en tablas de hechos y tablas de dimensiones.
Las tablas de hechos contienen los datos numéricos que desea analizar. Las tablas de hechos suelen tener un gran número de filas y son el origen de datos principal para el análisis. Por ejemplo, una tabla de hechos podría contener el importe total pagado por los pedidos de venta de una fecha concreta o en un almacén determinado.
Las tablas de dimensiones contienen información descriptiva sobre los datos de las tablas de hechos. Las tablas de dimensiones suelen tener algunas filas y proporcionan contexto para los datos de las tablas de hechos. Por ejemplo, una tabla de dimensiones puede contener información sobre los clientes que han realizado pedidos de venta.
Además de las columnas de atributos, una tabla de dimensiones contiene una columna de clave única que identifica de forma única cada fila de la tabla. De hecho, es habitual que una tabla de dimensiones incluya dos columnas de clave:
- Una clave suplente es un identificador único para cada fila de la tabla de dimensiones. A menudo es un valor entero que el sistema de administración de bases de datos genera automáticamente al insertar una nueva fila.
- Una clave alternativa suele ser una clave natural o empresarial que identifica una instancia específica de una entidad en el sistema de origen transaccional, como un código de producto o un identificador de cliente.
Necesita claves suplentes y alternativas en una data warehouse, ya que sirven para diferentes propósitos. Las claves suplentes son específicas de la data warehouse y ayudan a mantener la coherencia y la precisión. Las claves alternativas son específicas del sistema de origen y ayudan a mantener la rastreabilidad entre el data warehouse y el sistema de origen.
Tipos especiales de tablas de dimensiones
Los tipos especiales de dimensiones proporcionan contexto adicional y permiten un análisis de datos más completo.
Las dimensiones de tiempo proporcionan información sobre el período de tiempo en el que se produjo un evento. Esta tabla permite a los analistas de datos agregar datos a intervalos temporales. Por ejemplo, una dimensión de tiempo podría incluir columnas para el año, trimestre, mes y día de un pedido de ventas.
Las dimensiones que cambian lentamente realizan un seguimiento de los cambios en los atributos de dimensión a lo largo del tiempo, como los cambios en la dirección de un cliente o el precio de un producto. Son importantes en una data warehouse porque permiten analizar y comprender los cambios en los datos a lo largo del tiempo. Las dimensiones que cambian lentamente garantizan que los datos permanezcan actualizados y precisos, lo que es importante para tomar decisiones de negocio acertadas.
Diseños de esquema de almacén de datos
En la mayoría de las bases de datos transaccionales usadas en las aplicaciones empresariales, los datos se normalizan para reducir la duplicación. Sin embargo, en un data warehouse, los datos de dimensión se desnormalizan* para reducir el número de combinaciones necesarias para consultar los datos.
A menudo, un data warehouse usa un esquema star, en el que una tabla de hechos se relaciona directamente con las tablas de dimensiones, como se muestra en este ejemplo:
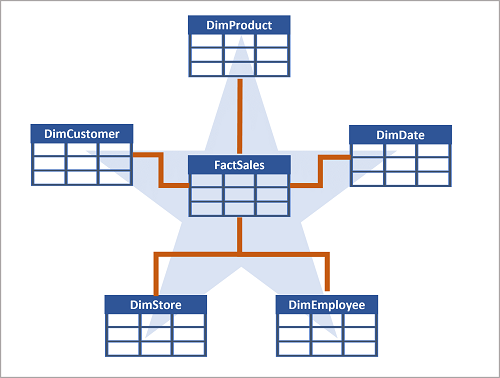
Puede usar atributos de dimensión para agrupar números de tabla de hechos en distintos niveles. Por ejemplo, podría encontrar los ingresos totales de ventas de toda una región o solo de un cliente. Puede almacenar la información de cada nivel en la misma tabla de dimensiones.
Sugerencia
Consulte ¿Qué es un esquema de estrella? para obtener más información sobre el diseño de esquemas de estrella para Fabric.
Si hay muchos niveles o atributos compartidos por diferentes cosas, podría tener sentido usar un esquema de copo de nieve en su lugar. Este es un ejemplo:
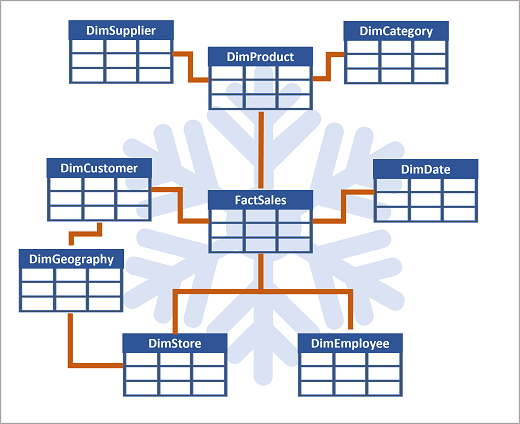
En este caso, la tabla DimProduct divide (normaliza) en tablas de dimensiones independientes para categorías de productos y proveedores.
- Cada fila de la tabla DimProduct contiene valores clave para las filas correspondientes en las tablas DimCategory y DimSupplier.
Una tabla DimGeography contiene información sobre dónde se encuentran los clientes y almacenes.
- Cada fila de las tablas DimCustomer y DimStore contiene un valor de clave para la fila correspondiente de la tabla DimGeography .