Reconocimiento de voz
Sugerencia
Consulte la pestaña Texto e imágenes para obtener más detalles.
El reconocimiento de voz, que a menudo se denomina voz a texto (STT) es una funcionalidad de inteligencia artificial que permite a las aplicaciones y agentes responder a la entrada hablada. El reconocimiento de voz toma la palabra hablada y lo convierte en datos, normalmente texto. El software de conversión de voz en texto suele usar varios modelos, entre los que se incluyen:
- Modelo acústico que convierte el audio en phonemes (representaciones de sonidos específicos).
- Modelo de lenguaje que asigna phonemes a palabras.
Las palabras que reconoce la voz de IA se convierten en texto. Puede usar el texto con diversos fines, como proporcionar subtítulos, crear transcripciones de llamadas, automatizar el dictado de notas y mucho más.
Voz de Azure: conversión de voz en texto
Azure Speech incluye una API de conversión de voz a texto que puede usar para procesar la entrada de voz desde un micrófono o un archivo de audio.
Nota:
Una API (interfaz de programación de aplicaciones) es un conjunto de reglas y puntos de conexión que permiten que una aplicación de software se comunique y use la funcionalidad o los datos de otra aplicación.
Microsoft Foundry es una plataforma de Microsoft que ayuda a los desarrolladores a crear, probar e implementar aplicaciones y agentes de inteligencia artificial al reunir modelos, herramientas, datos y servicios en un solo lugar.
En el nuevo portal de Microsoft Foundry, podemos explorar las funcionalidades de conversión de voz a texto de Azure en el área de juegos de Foundry. Para ir al área de juegos, vaya a la página Compilar y, a continuación, a Modelos y, a continuación, a la pestaña Servicios de IA . En la pestaña , puede encontrar una selección de servicios de INTELIGENCIA ARTIFICIAL disponibles para pruebas, incluido Azure Speech - Speech to Text.
En el área de juegos, puede cargar un archivo de audio o grabarse hablando. Voz de Azure transcribe lo que se dice, lo que le da una idea de cómo su propia aplicación respondería a la entrada de audio.

El área de juegos en el portal de Foundry es un excelente lugar para experimentar con Azure Speech, pero para usar la conversión de voz en texto en una aplicación, es necesario escribir código.
Uso del SDK de conversión de voz en texto de Azure
El SDK de Voz en texto de Azure es una biblioteca cliente que permite a las aplicaciones convertir audio hablado en texto escrito. El SDK de conversión de voz a texto está diseñado para facilitar la incorporación del reconocimiento de voz a las aplicaciones.
Nota:
Una biblioteca cliente es un conjunto de código listo que los desarrolladores pueden usar en su aplicación para comunicarse fácilmente con un servicio o API.
El SDK permite que la aplicación:
- Capturar o enviar audio desde un micrófono, un archivo de audio o una secuencia de audio
- Envíe ese audio a Azure Speech de manera segura
- Recibir texto transcrito casi en tiempo real o después de que se complete el procesamiento
El SDK controla las redes, la autenticación, el streaming de audio y el análisis de respuesta para que los desarrolladores puedan centrarse en la lógica de la aplicación.
Desarrollo de una aplicación
El SDK de voz a texto se usa normalmente en el nivel de cliente o servicio de una aplicación. El SDK actúa como puente entre el código de la aplicación y el servicio De voz de Azure.
Para usar el SDK de Python de Voz de Azure, debe tener instalada la versión compatible de Python y el SDK de Python de Voz de Azure.
El SDK de Python se puede instalar en el terminal de Visual Studio Code mediante:
pip install azure-cognitiveservices-speech
Nota:
El código de la aplicación se escribe en editores de código, como Visual Studio Code. Un terminal del editor de código es una ventana de línea de comandos integrada dentro del editor donde puede ejecutar comandos sin salir del entorno de desarrollo.
Para usar Azure Speech, también debe crear un recurso Foundry. El punto de conexión y la clave del recurso Foundry se usan en el código para autenticar la conexión.
Después de instalar el SDK de Python y crear un recurso Foundry, puede crear y ejecutar el programa. Tenga en cuenta el siguiente código de Python. Al ejecutarlo:
- La aplicación inicializa el SDK de Voz: proporciona un punto de conexión y autenticación (clave o id. de Microsoft Entra).
- Audio se captura o carga: entrada del micrófono o un archivo o secuencia de audio
- El audio se envía a Voz de Azure: el SDK transmite o carga audio de forma segura.
- El reconocimiento de voz se ejecuta en la nube: los modelos de voz de Azure analizan el audio.
- Se devuelven los resultados de texto: la aplicación recibe texto reconocido y metadatos opcionales.
import azure.cognitiveservices.speech as speechsdk
# Set up the speech config using resource endpoint
endpoint_url = "ENDPOINT"
speech_key = "FOUNDRY_KEY"
speech_config = speechsdk.SpeechConfig(
subscription=speech_key,
endpoint=endpoint_url
)
# Create a recognizer with microphone input
audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(
speech_config=speech_config,
audio_config=audio_config
)
# Event handlers
def recognized_handler(evt):
print(f"Recognized: {evt.result.text}")
def recognizing_handler(evt):
print(f"Recognizing: {evt.result.text}")
# Connect event handlers
speech_recognizer.recognized.connect(recognized_handler)
speech_recognizer.recognizing.connect(recognizing_handler)
# Start continuous recognition
speech_recognizer.start_continuous_recognition()
print("Say something...")
# Keep the program running
input("Press Enter to stop...")
speech_recognizer.stop_continuous_recognition()
Ejemplo de aplicación cliente
Por ejemplo, supongamos que quiere desarrollar una aplicación ligera que transcriba automáticamente los mensajes de correo de voz. En el editor de código, tenemos un archivo de audio y un archivo de Python, que contiene código de aplicación.
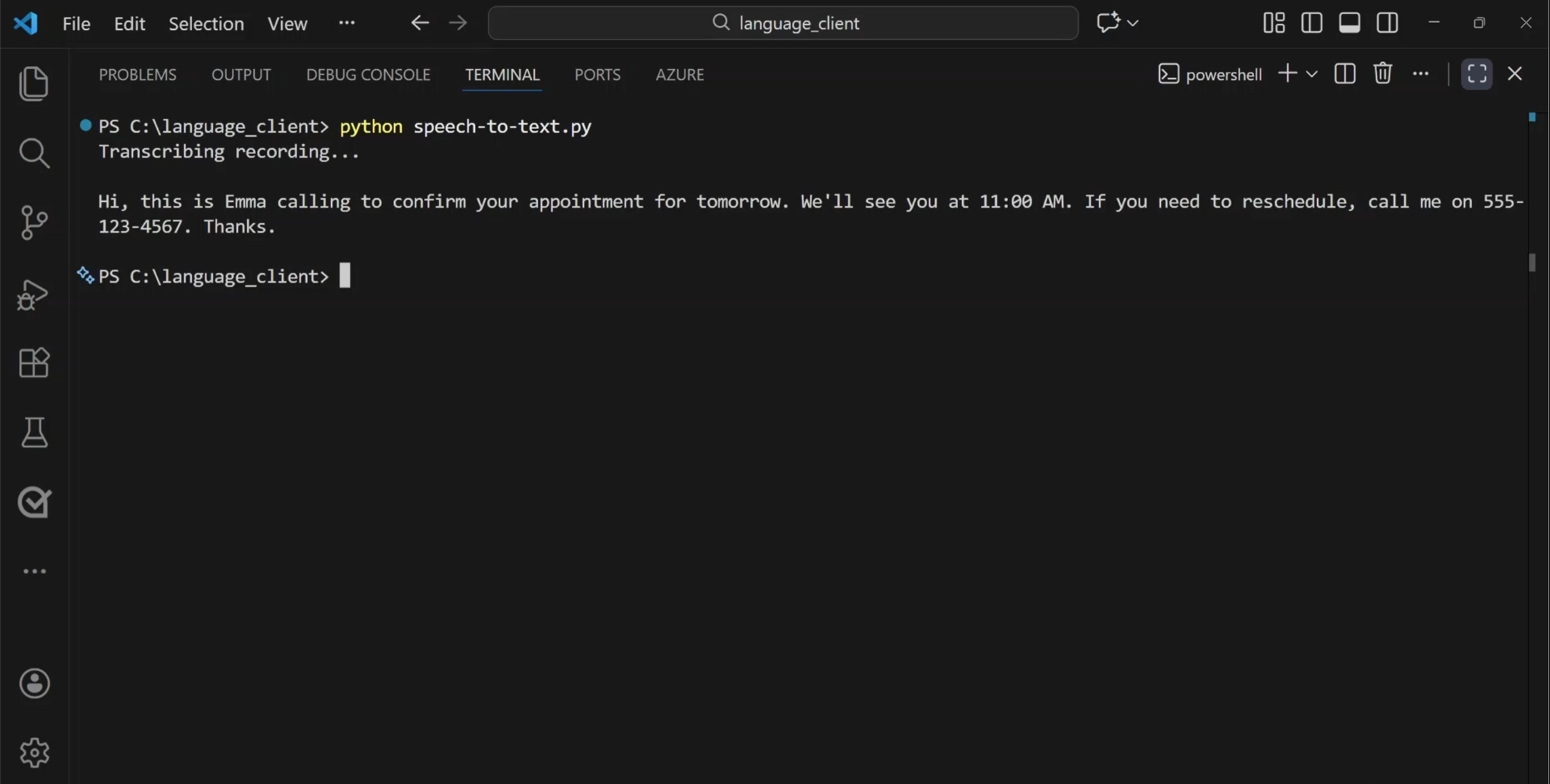
Supongamos que tiene un archivo de audio que contiene una grabación de correo de voz. Para transcribir el mensaje, empiece especificando el punto de conexión y la clave y el origen de audio que desea transcribir. A continuación, use un SpeechRecognizer objeto para realizar la transcripción antes de mostrar los resultados.

Una vez ejecutado el código, puede ver el texto de transcripción.
Opciones de procesamiento de audio
Puede usar la API de conversión de voz en texto de Azure Speech para realizar la transcripción por lotes o en tiempo real del audio en un formato de texto. La fuente de audio de la transcripción puede ser una transmisión de audio en tiempo real desde un micrófono o un archivo de audio.
Transcripción en tiempo real: la voz en tiempo real en texto le permite transcribir secuencias de audio a texto. Puede usar la transcripción en tiempo real para presentaciones, demostraciones o cualquier otra situación en la que una persona hable.
Para que la transcripción en tiempo real funcione, la aplicación debe escuchar audio entrante desde un micrófono u otro origen de entrada de audio, como un archivo de audio. El código de la aplicación transmite el audio al servicio, que devuelve el texto transcrito.
Transcripción de Batch: No todos los escenarios de Speech to text son en tiempo real. Es posible que tenga grabaciones de audio almacenadas en un recurso compartido de archivos, en un servidor remoto o incluso en almacenamiento de Azure. Puede apuntar a archivos de audio con un URI de firma de acceso compartido (SAS) y recibir resultados de transcripción de forma asincrónica.
La transcripción por lotes se debe ejecutar de forma asincrónica porque los trabajos por lotes se programan en función de la mejor opción. Normalmente, un trabajo comienza a ejecutarse en cuestión de minutos a partir de la solicitud, pero no hay ninguna estimación para cuando un trabajo cambia al estado en ejecución.
El reconocimiento de voz en Azure Speech es una excelente manera de crear soluciones que transcriban audio grabado o automaticen subtítulos de voz. A continuación, aprenda a incorporar la síntesis de voz en una aplicación.