¿Qué es la clasificación?
La clasificación binaria es la clasificación con dos categorías. Por ejemplo, podríamos etiquetar a los pacientes como no diabéticos o diabéticos.
Para predecir la clase, se calcula la probabilidad de cada clase posible como un valor entre 0 (imposible) y 1 (cierto). La probabilidad total para todas las clases siempre es 1, ya que el paciente es definitivamente diabético o no diabético. Así, si la probabilidad prevista de que un paciente sea diabético es de 0,3, existe una probabilidad correspondiente de 0,7 de que el paciente no sea diabético.
Un valor de umbral, a menudo 0,5, se usa para determinar la clase predicha. Si la clase positiva (en este caso, diabético) tiene una probabilidad prevista mayor que el umbral, entonces se predice una clasificación de diabético.
Entrenamiento y evaluación de un modelo de clasificación
La clasificación es un ejemplo de técnica de aprendizaje automático supervisado, lo que significa que se basa en datos que incluyen valores conocidos de características y valores conocidos de etiquetas. En este ejemplo, los valores de características son medidas de diagnóstico para pacientes y los valores de etiqueta son una clasificación de no diabético o diabético. Se usa un algoritmo de clasificación para ajustar un subconjunto de los datos a una función que pueda calcular la probabilidad de cada etiqueta de clase a partir de los valores de las características. Los datos restantes se usan para evaluar el modelo al comparar las predicciones que genera a partir de las características con las etiquetas de clase conocidas.
Un ejemplo sencillo
Vamos a explorar un ejemplo para ayudar a explicar los principios clave. Supongamos que tenemos los siguientes datos sobre los pacientes, que constan de una característica única (nivel de glucosa en sangre) y una etiqueta de clase (0 para no diabético, 1 para diabético).
| Glucosa en sangre | Diabético |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
Usaremos las ocho primeras observaciones para entrenar un modelo de clasificación, y comenzaremos por trazar la característica de glucosa en sangre (x) y la etiqueta de diabético predicha (y).
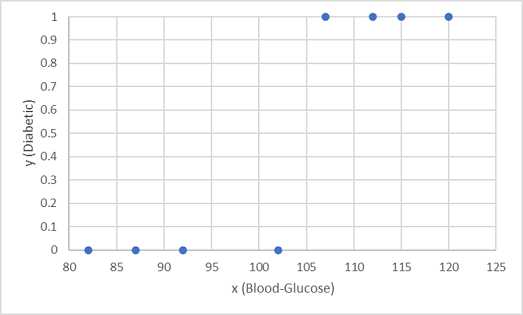
Lo que se necesita es una función que calcule un valor de probabilidad para y según x (en otras palabras, se necesita la función f(x) = y). Del gráfico se puede ver que los pacientes con un bajo nivel de glucosa en sangre son todos no diabéticos, mientras que los pacientes con un nivel mayor de glucosa en sangre son diabéticos. Al parecer, cuanto mayor sea el nivel de glucosa en la sangre, más probable es que el paciente sea diabético, donde el punto de la inflexión se encuentra en algún lugar entre 100 y 110. Es necesario encontrar una función que calcule un valor de y entre 0 y 1 para dichos valores.
Una de ellas es una función logística, que forma una curva sigmoidea (con forma de S).
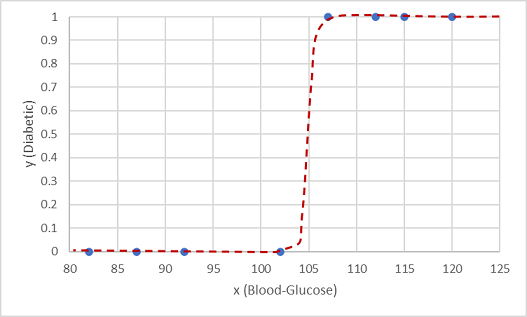
Ahora podemos usar la función para calcular un valor de probabilidad donde y sea positivo (es decir, el paciente es diabético) a partir de cualquier valor de x buscando el punto en la línea de función para x. Podemos establecer un valor de umbral de 0,5 como punto de corte para la predicción de la etiqueta de clase.
Vamos a probarlo con los dos valores de datos que hemos conservado.
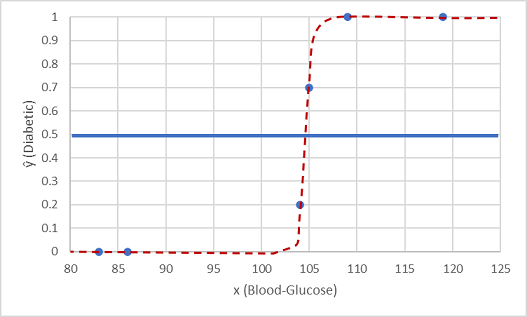
Los puntos trazados debajo de la línea de umbral producen una clase predicha de 0 (no diabéticos), y los puntos por encima de la línea se predicen como 1 (diabético).
Ahora podemos comparar las predicciones de etiqueta basándonos en la función logística encapsulada en el modelo (ŷ, o "y-hat") con las etiquetas de clase reales (y).
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |