Use a notebook to load data into your Lakehouse
In this tutorial, learn how to read/write data into your lakehouse with a notebook.Spark API and Pandas API are supported to achieve this goal.
Load data with an Apache Spark API
In the code cell of the notebook, use the following code example to read data from the source and load it into Files, Tables, or both sections of your lakehouse.
To specify the location to read from, you can use the relative path if the data is from the default lakehouse of current notebook, or you can use the absolute ABFS path if the data is from other lakehouse. you can copy this path from the context menu of the data
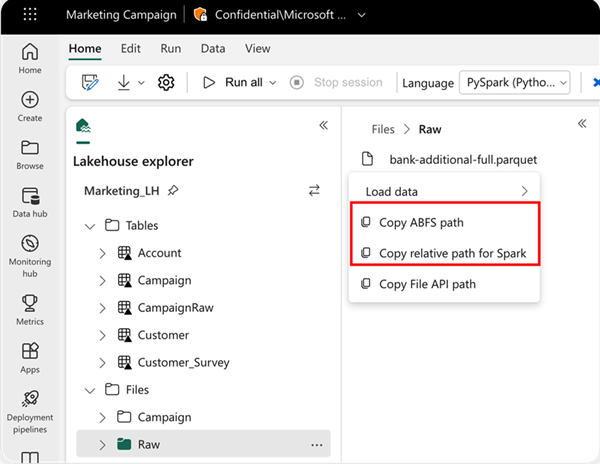
Copy ABFS path : this return the absolute path of the file
Copy relative path for Spark : this return the relative path of the file in the default lakehouse
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default Lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default Lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default Lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Load data with a Pandas API
To support Pandas API, the default Lakehouse will be automatically mounted to the notebook. The mount point is '/lakehouse/default/'. You can use this mount point to read/write data from/to the default lakehouse. The "Copy File API Path" option from the context menu will return the File API path from that mount point. The path returned from the option Copy ABFS path also works for Pandas API.
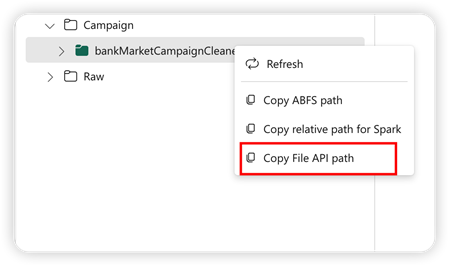
Copy File API Path :This return the path under the mount point of the default lakehouse
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tip
For Spark API, please use the option of Copy ABFS path or Copy relative path for Spark to get the path of the file. For Pandas API, please use the option of Copy ABFS path or Copy File API path to get the path of the file.
The quickest way to have the code to work with Spark API or Pandas API is to use the option of Load data and select the API you want to use. The code will be automatically generated in a new code cell of the notebook.

Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for