Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this tutorial, you use notebooks with Spark runtime to transform and prepare raw data in your lakehouse.
Prerequisites
Before you begin, you must complete the previous tutorials in this series:
- Create a lakehouse
- Ingest data into the lakehouse
- Ensure lakehouse schemas are enabled in your lakehouse.
Prepare data
From the previous tutorial steps, you have raw data ingested from the source to the Files section of the lakehouse. Now you can transform that data and prepare it for creating Delta tables.
Download the notebooks from the Lakehouse Tutorial Source Code folder.
In your browser, go to your Fabric workspace in the Fabric portal.
Select Import > Notebook > From this computer.

Select Upload from the Import status pane that opens on the right side of the screen.
Select only the notebook that matches your preferred coding language.
- PySpark (
Prepare and transform data - PySpark.ipynb) - Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
- PySpark (
Select Open. A notification indicating the status of the import appears in the top right corner of the browser window.
After the import is successful, go to the items view of the workspace to verify the imported notebook.
Select the wwilakehouse lakehouse to open it, so that the notebook you open next is linked to it.
From the top navigation menu, select Open notebook > Existing notebook.
Select your imported notebook for PySpark or Spark SQL and select Open. The notebook is already linked to your opened lakehouse, as shown in the lakehouse Explorer.



You're now ready to run the notebook cells that create and transform your Delta tables.
In the following sections, run the notebook cells sequentially. To execute a cell, select the Run icon that appears to the left of the cell on hover. You can also select Run all on the top ribbon (Home) to run all cells in sequence.
Important
This tutorial requires lakehouse schemas to be enabled. If schemas aren't enabled, the code in this tutorial won't work as intended.
In the imported notebook, you see both Path 1 and Path 2 sections. For this tutorial, use Path 1 (lakehouse schemas enabled) and ignore Path 2 (lakehouse schemas not enabled).
Create Delta tables
In this section, you run the notebook cells to create Delta tables from the raw data.
The tables follow a star schema, which is a common pattern for organizing analytical data:
- A fact table (
fact_sale) contains the measurable events of the business — in this case, individual sales transactions with quantities, prices, and profit. - Dimension tables (
dimension_city,dimension_customer,dimension_date,dimension_employee,dimension_stock_item) contain the descriptive attributes that give context to the facts, such as where a sale happened, who made it, and when.
In this tutorial page, select the tab that matches the notebook you imported, and keep using that same tab for all steps. The tabs are in this article, not in the notebook.
Cell 1 - Spark session configuration. This cell enables two Fabric features that optimize how data is written and read in subsequent cells. V-order optimizes the parquet file layout for faster reads and better compression. Optimize write reduces the number of files written and increases individual file size.
Run this cell, and wait for it to finish before moving on to the next step.
Cell 2 - Fact - Sale. This cell reads raw parquet data from
Files/wwi-raw-data/full/fact_sale_1y_full, adds date part columns (Year, Quarter, and Month), and writesfact_saleas a Delta table partitioned by Year and Quarter.Run this cell, and wait for it to finish before moving on to the next step.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Cell 3 - Dimensions. This cell reads the five dimension parquet datasets and writes them as Delta tables (
dimension_city,dimension_customer,dimension_date,dimension_employee, anddimension_stock_item) underTables/dbo/....Run this cell, and wait for it to finish before moving on to the next step.
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)To validate the created tables, right-click the wwilakehouse lakehouse in the explorer and then select Refresh. The tables appear.
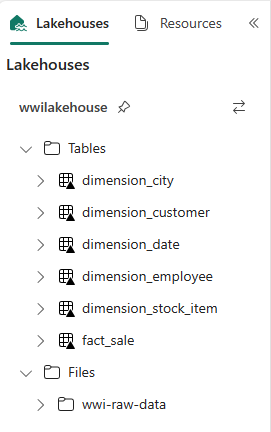

Transform data for business aggregates
In this section, you continue in the same notebook and run the next cells to create aggregate tables from the Delta tables you created in the previous section.
Make sure the notebook is still linked to wwilakehouse.
Cell 4 - Load source tables for transformation (PySpark only). If you're using the PySpark notebook, run this cell to load Delta tables into DataFrames for the aggregation steps that follow.
Run this cell, and wait for it to finish before moving on to the next step.
Cell 5 - Create
aggregate_sale_by_date_city. This cell joins sales, date, and city data, then creates the city-level aggregate table.Run this cell, and wait for it to finish before moving on to the next step.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Cell 6 - Create
aggregate_sale_by_date_employee. This cell joins sales, date, and employee data, then creates the employee-level aggregate table.Run this cell, and wait for it to finish before moving on to the next step.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")To validate the created tables, right-click the wwilakehouse lakehouse in the explorer and then select Refresh. The aggregate tables appear.
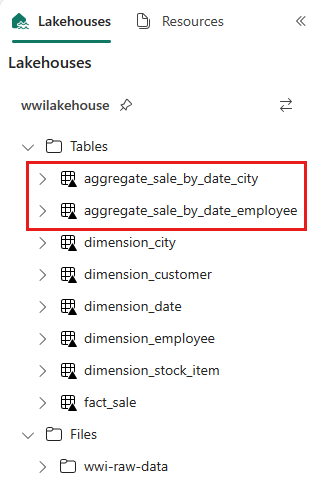

This tutorial writes data as Delta lake files. Fabric automatically discovers and registers these tables in the metastore, so you don't need to run separate CREATE TABLE statements.