Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The partition feature in Lakehouse table as destination offers the capability to load data to Lakehouse table with partitions. The partitions are generated in Lakehouse destination, and then benefit the downstream jobs or consumption.
This tutorial helps you learn how to load data to Lakehouse using partition in a pipeline. As an example, you load sample dataset into Lakehouse using one or multiple partition columns by taking the following steps. The sample dataset Public Holidays is used as sample data.
Prerequisite
- Make sure you have a Project Microsoft Fabric enabled Workspace: Create a workspace.
Create a pipeline
Navigate to Power BI.
Select the Power BI icon in the bottom left of the screen, then select Fabric to open homepage of Data Factory.
Navigate to your Microsoft Fabric workspace. If you created a new workspace in the prior Prerequisites section, use this one.
Select + New item.
Search for and select Pipeline and then input a pipeline name to create a new pipeline. to create a new pipeline.
Load data to Lakehouse using partition columns
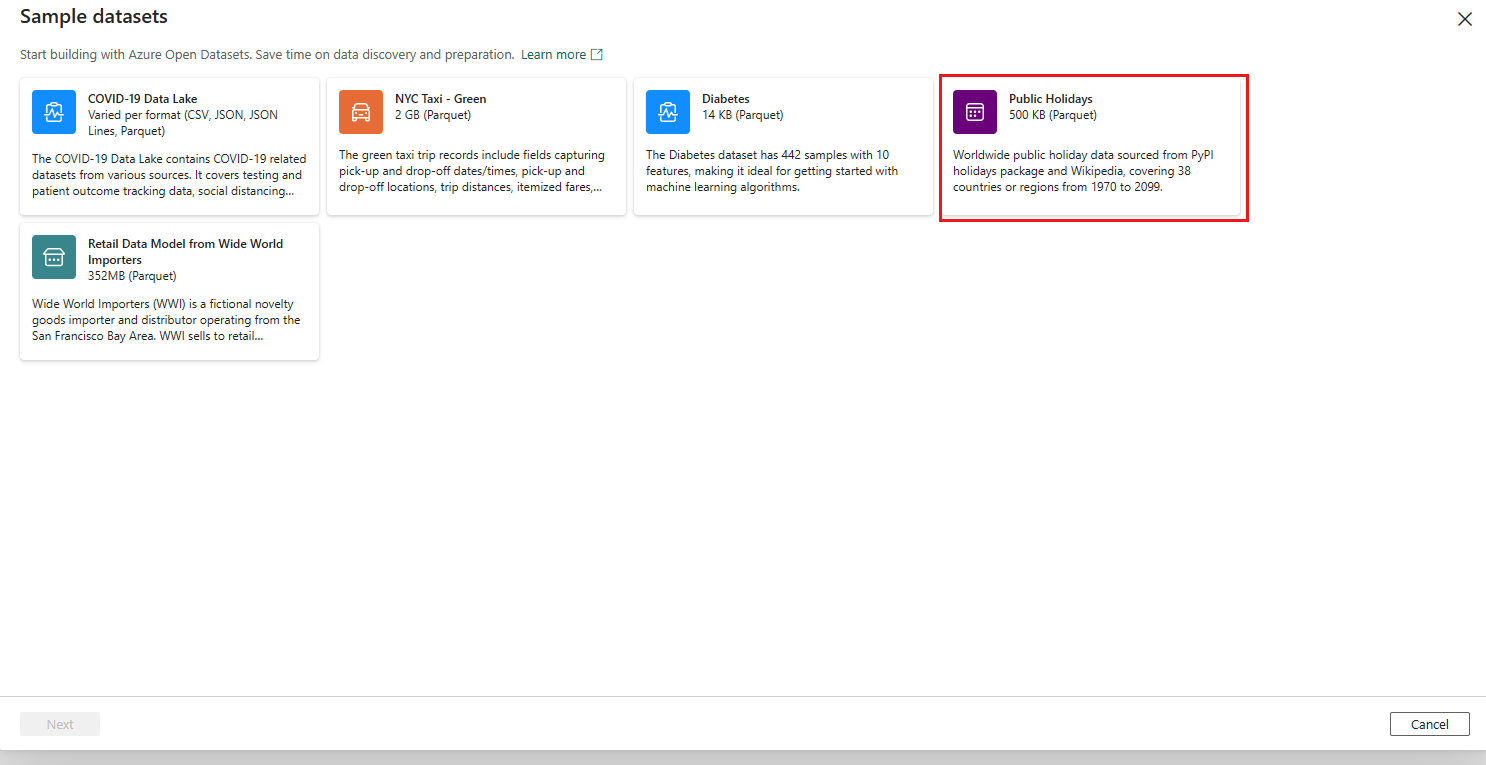
Open your pipeline and add a copy activity by selecting Pipeline activity -> Copy data. Under Source, select More at the bottom of the connection list, then select Public Holidays under Sample data tab.

Under Destination tab, select More at the bottom of the connection list, then select an existing Lakehouse in OneLake tab, specify your Lakehouse or create a new Lakehouse in Home tab. Choose Table in Root folder and specify your table name.
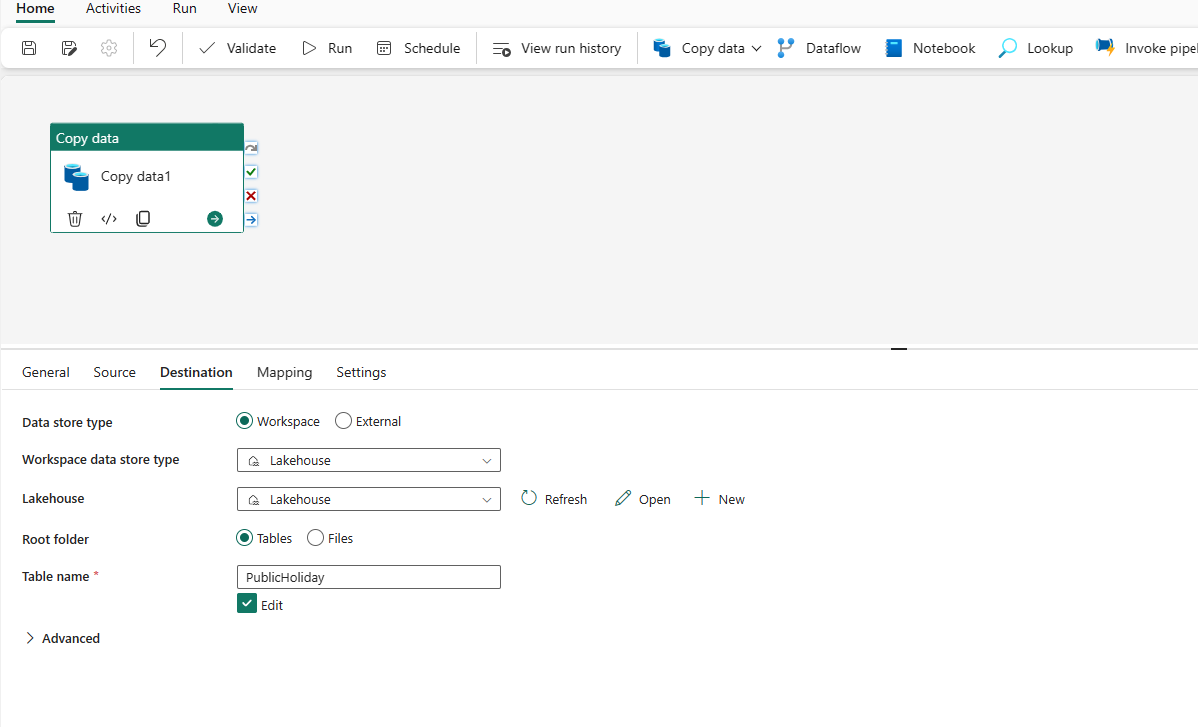
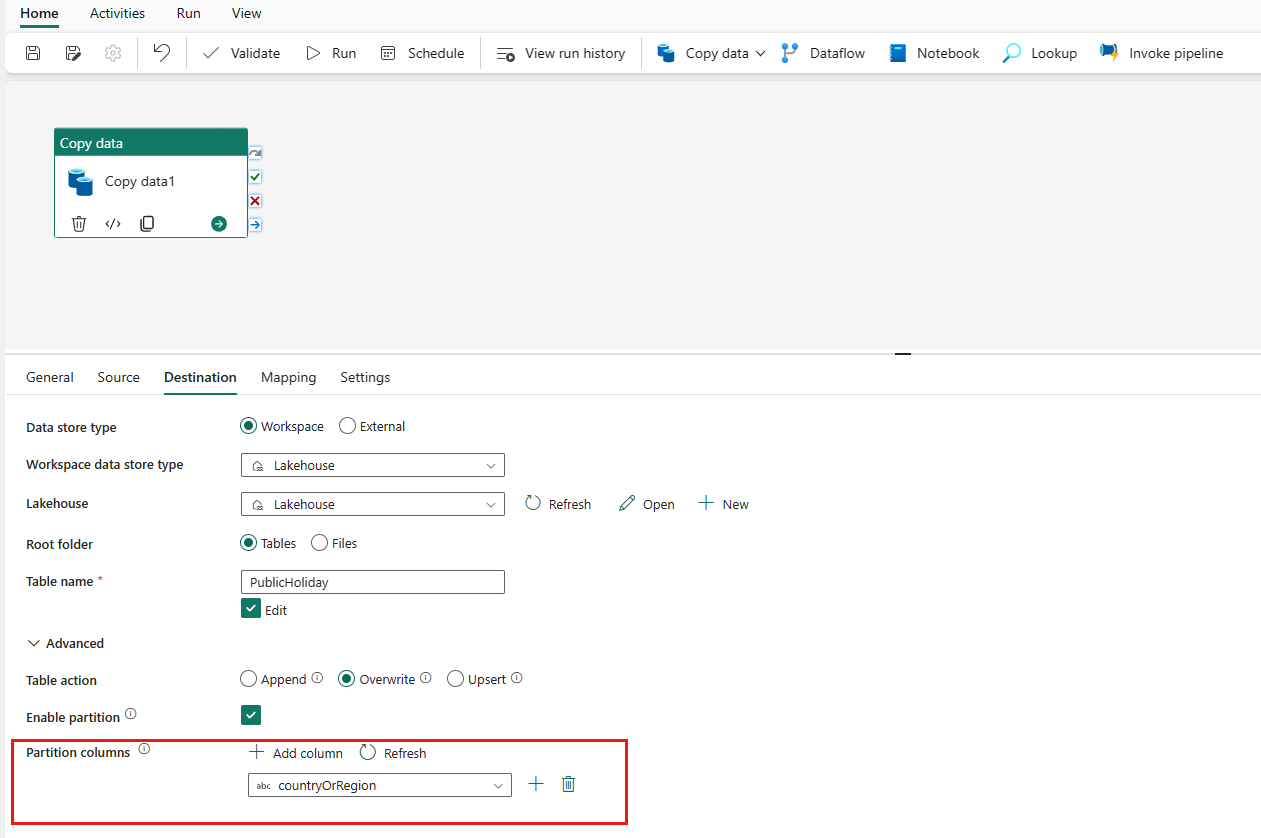
Expand Advanced, in Table action, select Overwrite, and then select Enable partition, under Partition columns, select Add column, and choose the column you want to use as the partition column. You can choose to use a single column or multiple columns as the partition column.
If you use a single column, countryOrRegion (string type) is selected as an example in this tutorial. The data will be partitioned by different column values.
Note
The partition column that can be selected should be string, integer, boolean and datetime type. Columns of other data types are not displayed in the drop-down list.
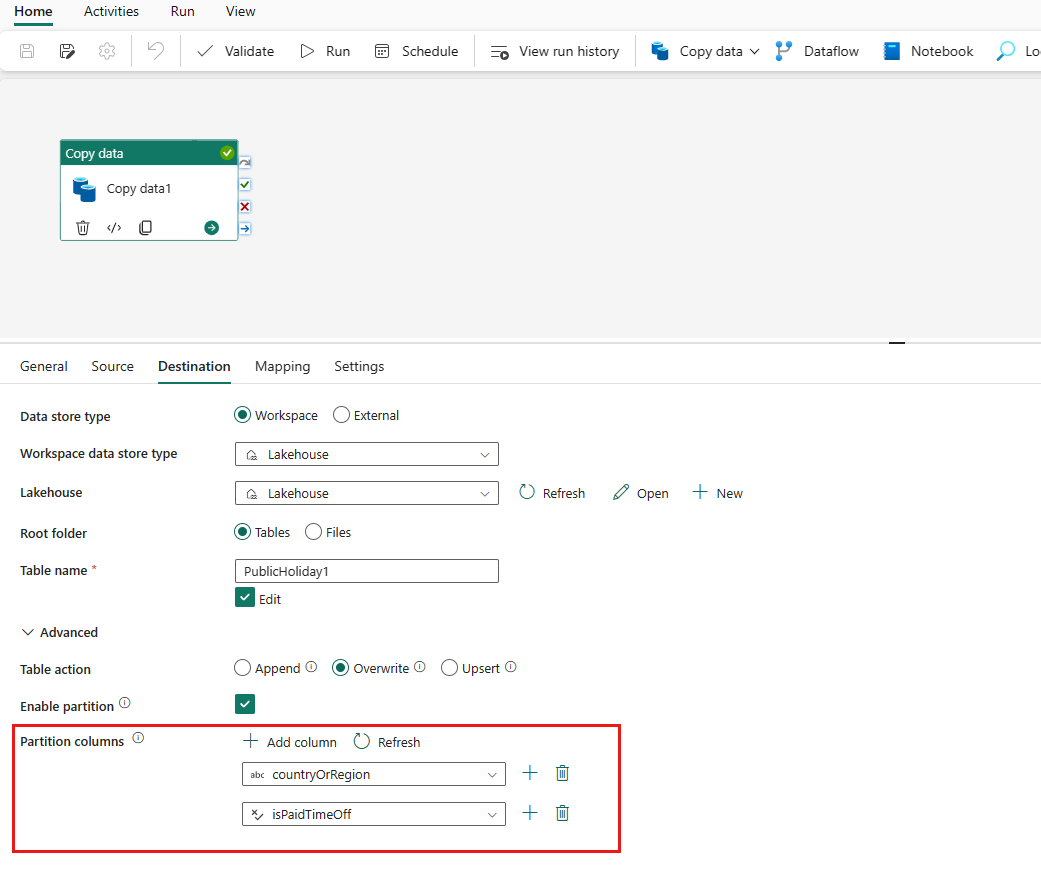
If you use multiple partition columns, add one more column and select isPaidTimeOff which is boolean type as an example. Then run the pipeline. The logic is that the table is partitioned by the first added column values firstly, and then the partitioned data continue to be partitioned by the second added column values.
Tip
You can drag columns to change the sequence of columns, and the partition sequence will also change.
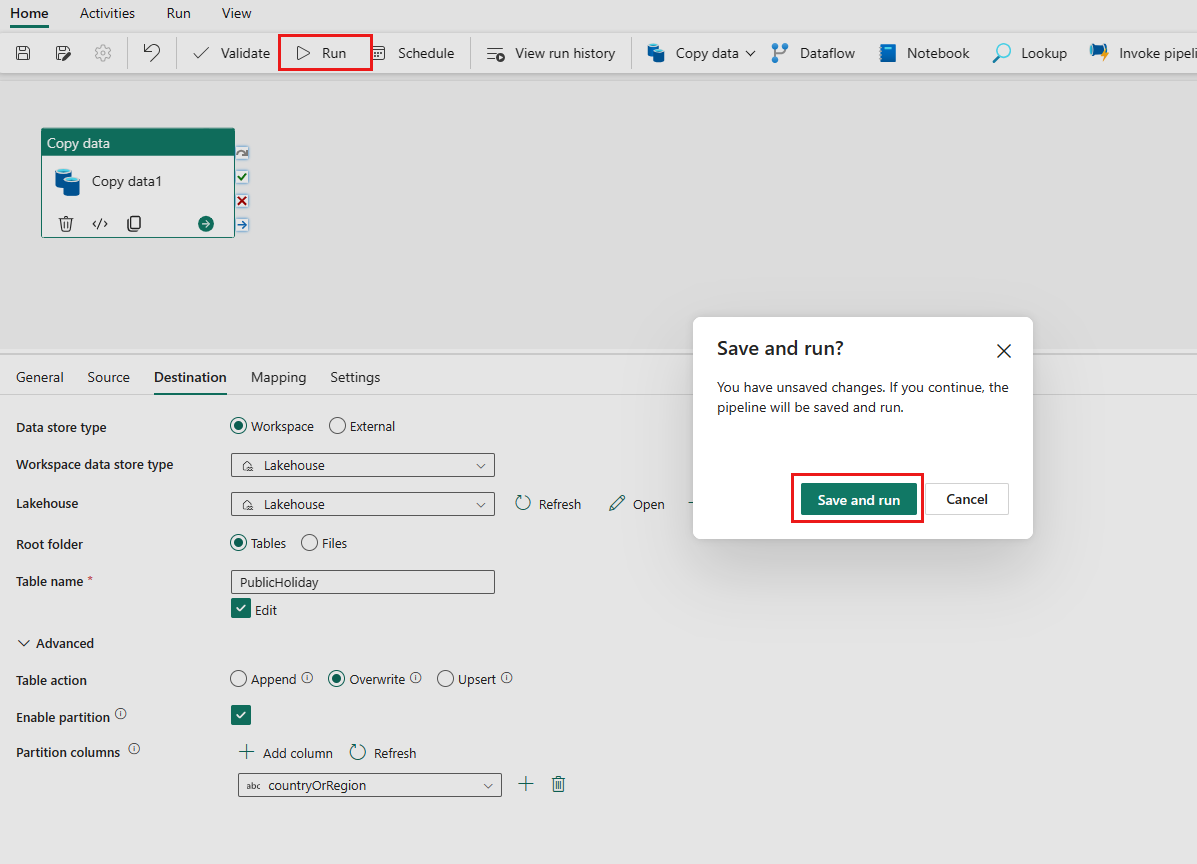
Select the Run and select Save and run to run the pipeline.
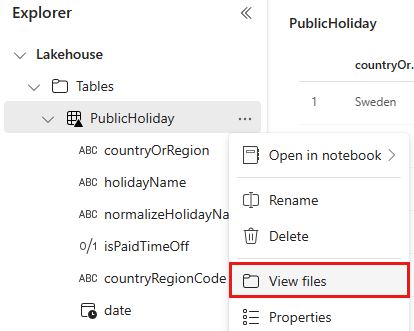
After the pipeline runs successfully, go to your Lakehouse. Find the table that you copied. Right-click the table name and select View files.
For one partition column (countryOrRegion), the table is partitioned to different folders by country or region names. The special character in column name is encoded, and you may see the file name is different from column values when you view files in Lakehouse.
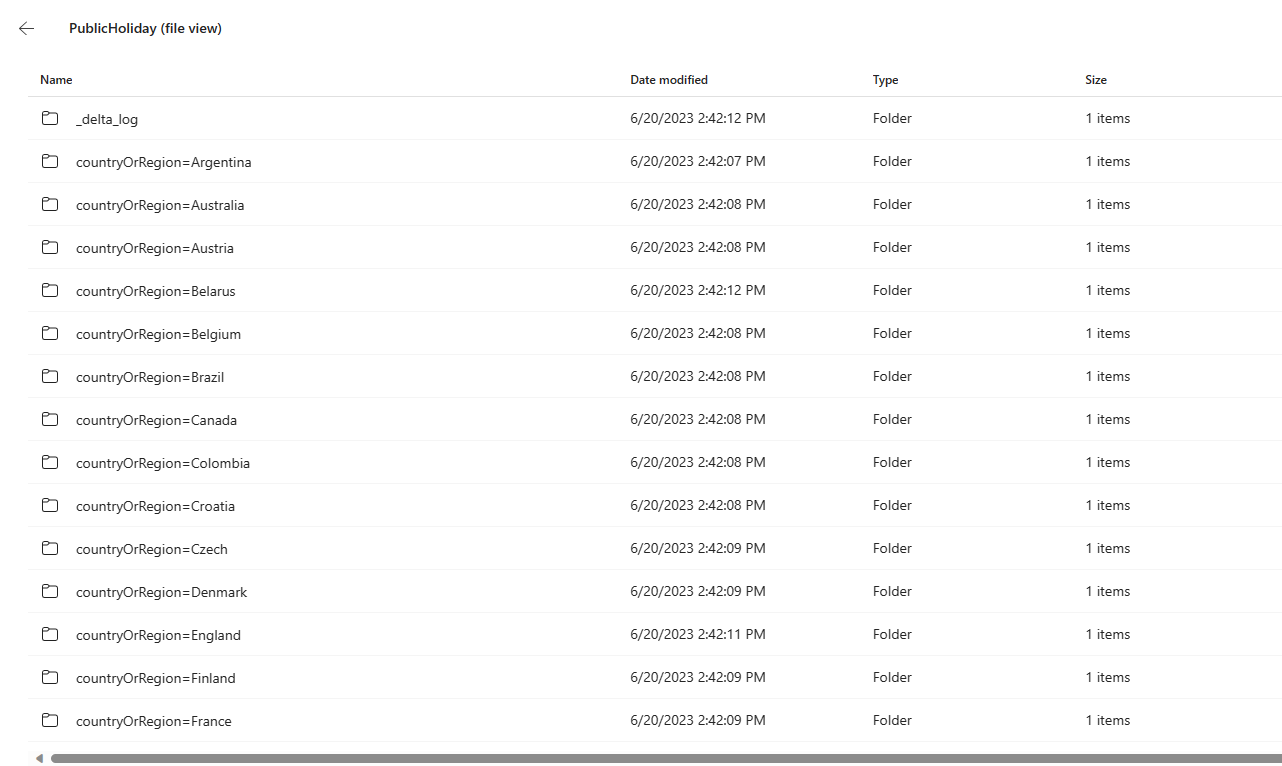
For multiple partition columns, you find the table is partitioned into different folders by country or region names.
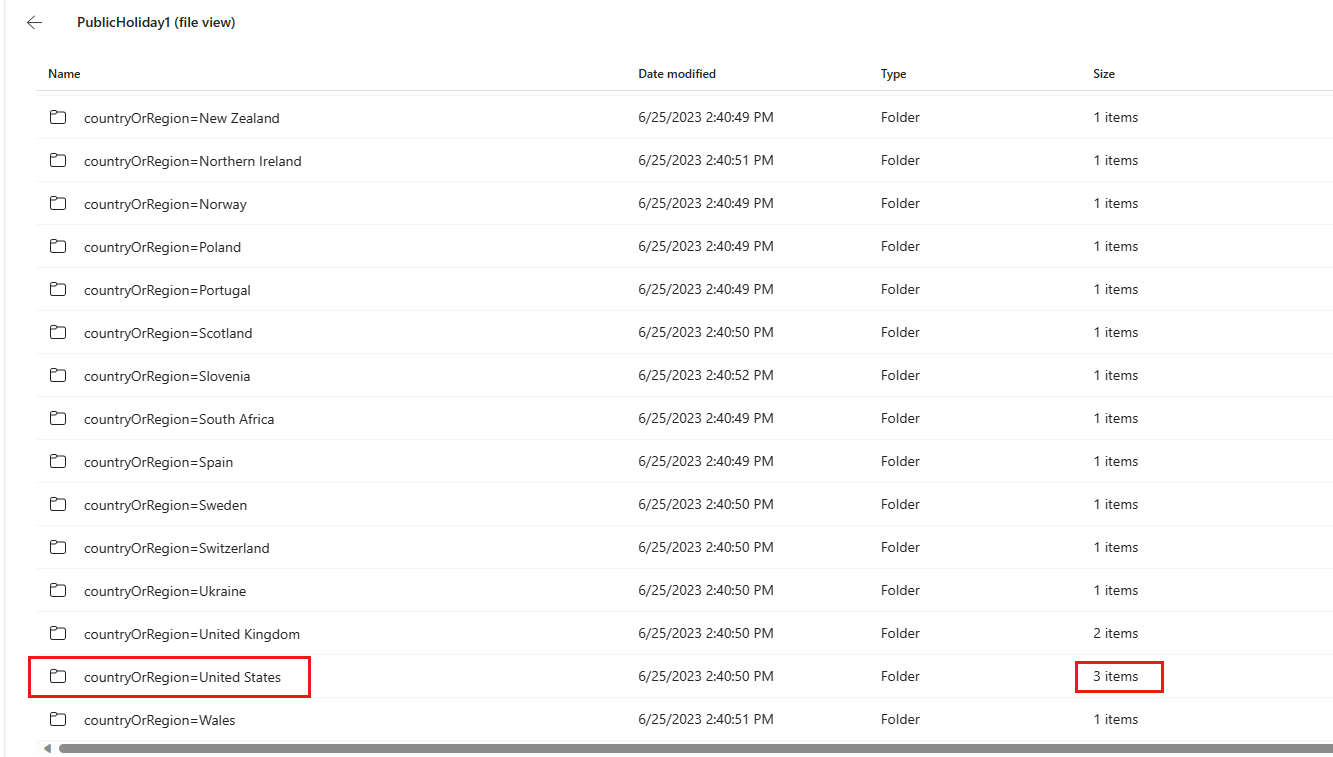
Select one folder, for example contryOrRegion=United States. The table partitioned by the country or region name is partitioned again by the added second column isPaidTimeOff’s value:
TrueorFalseor__HIVE_DEFAULT_PARTITION__(represents empty value in Sample dataset).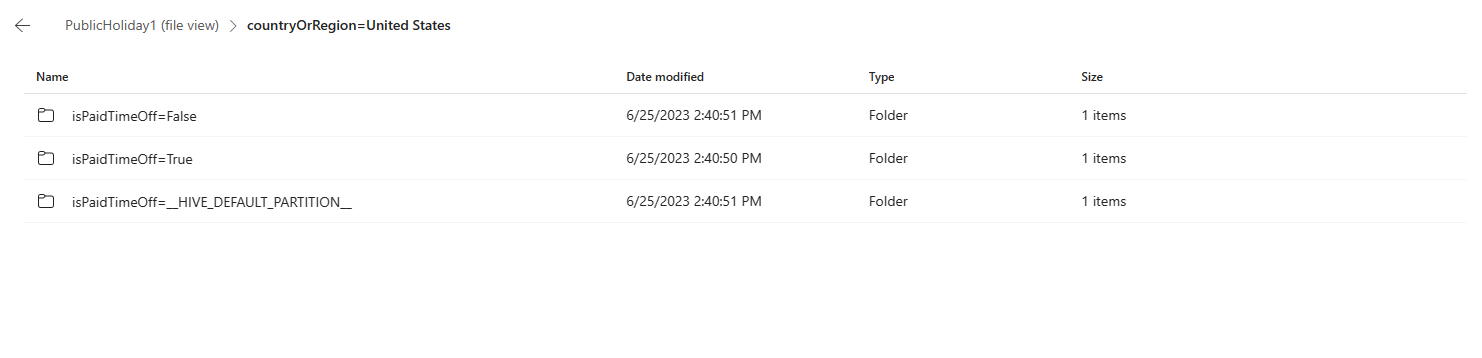
Similarly, if you add three columns to partition the table, you get the second level folder partitioned by the third column added.









Related content
Next, advance to learn more about copy from Azure Blob Storage to Lakehouse.