Guide de configuration du déploiement
Le ALM Accelerator for Power Platform utilise des fichiers de configuration au format JSON pour automatiser le déploiement de vos solutions. Ils définissent les références de connexion, les variables d’environnement, les autorisations, le partage d’applications canevas et la mise à jour de la propriété des composants de la solution, tels que les flux Power Automate quand les solutions sont déployées vers des environnements en aval.
Les fichiers de configuration de cet article vous permettent de configurer des éléments spécifiques à l’environnement dans lequel une solution est déployée. Les fichiers de configuration dont vous avez besoin, et donc les étapes à suivre dans cet article, dépendent des composants déployés par vos pipelines de solution. Par exemple, si votre solution ne contient que les tables et applications pilotées par modèle Dataverse et sans configuration par environnement ou données nécessaires, vous pouvez ignorer certaines de ces étapes.
Pour un exemple de fichiers de configuration et de configuration de déploiement de données, consultez les paramètres de déploiement et les paramètres de déploiement personnalisés.
Avant de commencer
Cet article est un guide étape par étape pour la configuration manuelle des fichiers de configuration de déploiement. Il fournit des détails et un contexte pour les actions qui sont effectuées par les pipelines et l’application ALM accelerator et sert de référence pour les administrateurs qui souhaitent connaître les spécificités de chaque étape du processus.
Nous vous recommandons configurer les paramètres de déploiement dans l’application ALM Accelerator, cependant.
Créer un fichier JSON des paramètres de déploiement
Lors du stockage de customDeploymentSettings.json à la racine du répertoire de configuration, la même configuration s’appliquera à tous les environnements. En supposant que vous utilisez des tâches de pipeline de transformation de fichier ou de remplacement de jeton pour stocker toutes les informations spécifiques à des environnements particuliers, vous pouvez spécifier les valeurs par environnement dans vos variables de pipeline.
Cependant, vous pouvez également créer spécifique à l’environnement customDeploymentSettings.json des dossiers. Stockez-les dans des sous-répertoires du configuration répertoire, nommé pour vos environnements. Le nom du répertoire doit correspondre à la variable de pipeline EnvironmentName lors de la configuration de votre pipeline pour environnements de validation, test, production. Si aucun paramètre de déploiement JSON et répertoire spécifique à l’environnement existe, les pipelines reviendront à la configuration à la racine du répertoire de configuration.
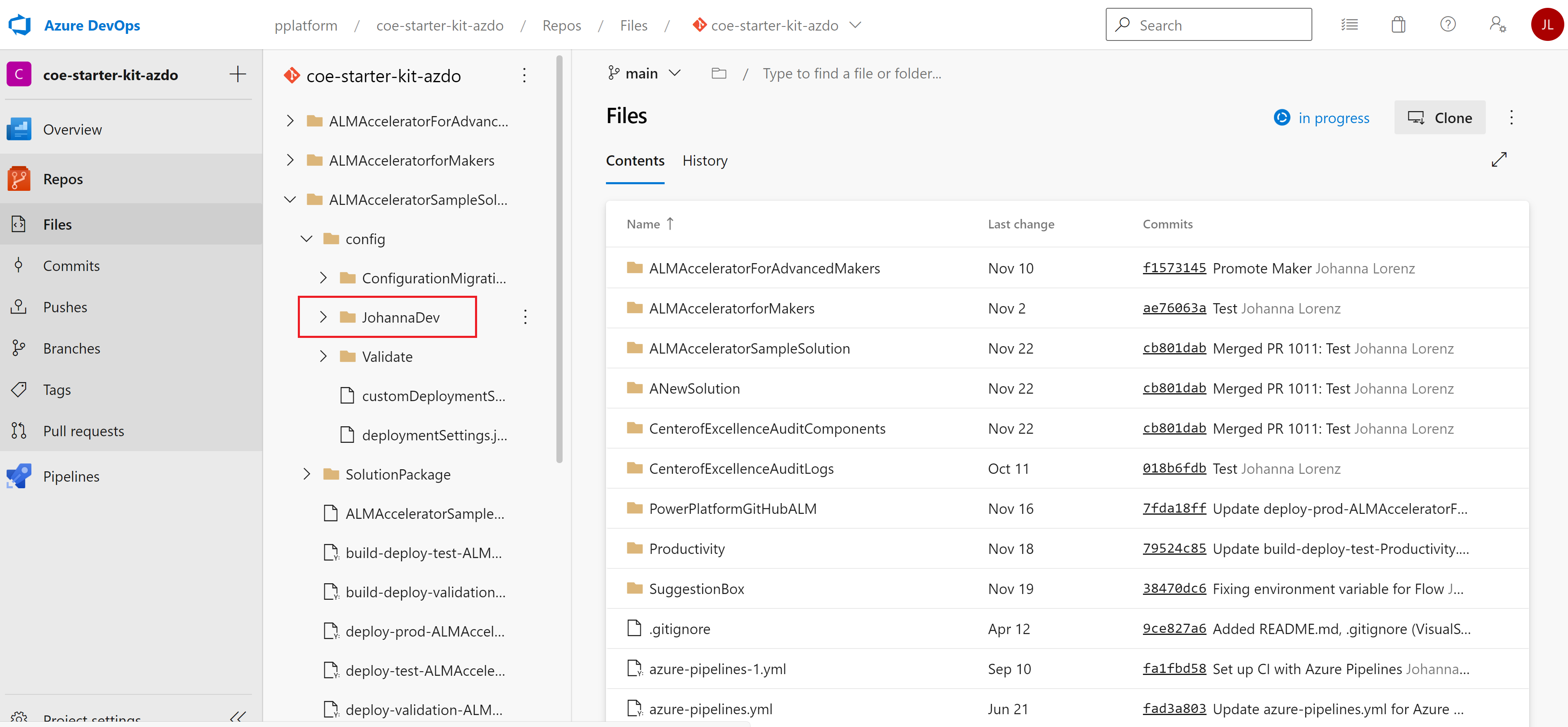
Vous pouvez également créer des fichiers de configuration spécifiques à l’utilisateur comme le JohannaDev répertoire dans l’image précédente. Les développeurs peuvent les utiliser pour choisir une configuration spécifique lorsqu’ils importent des solutions non gérées à partir du contrôle de code source.
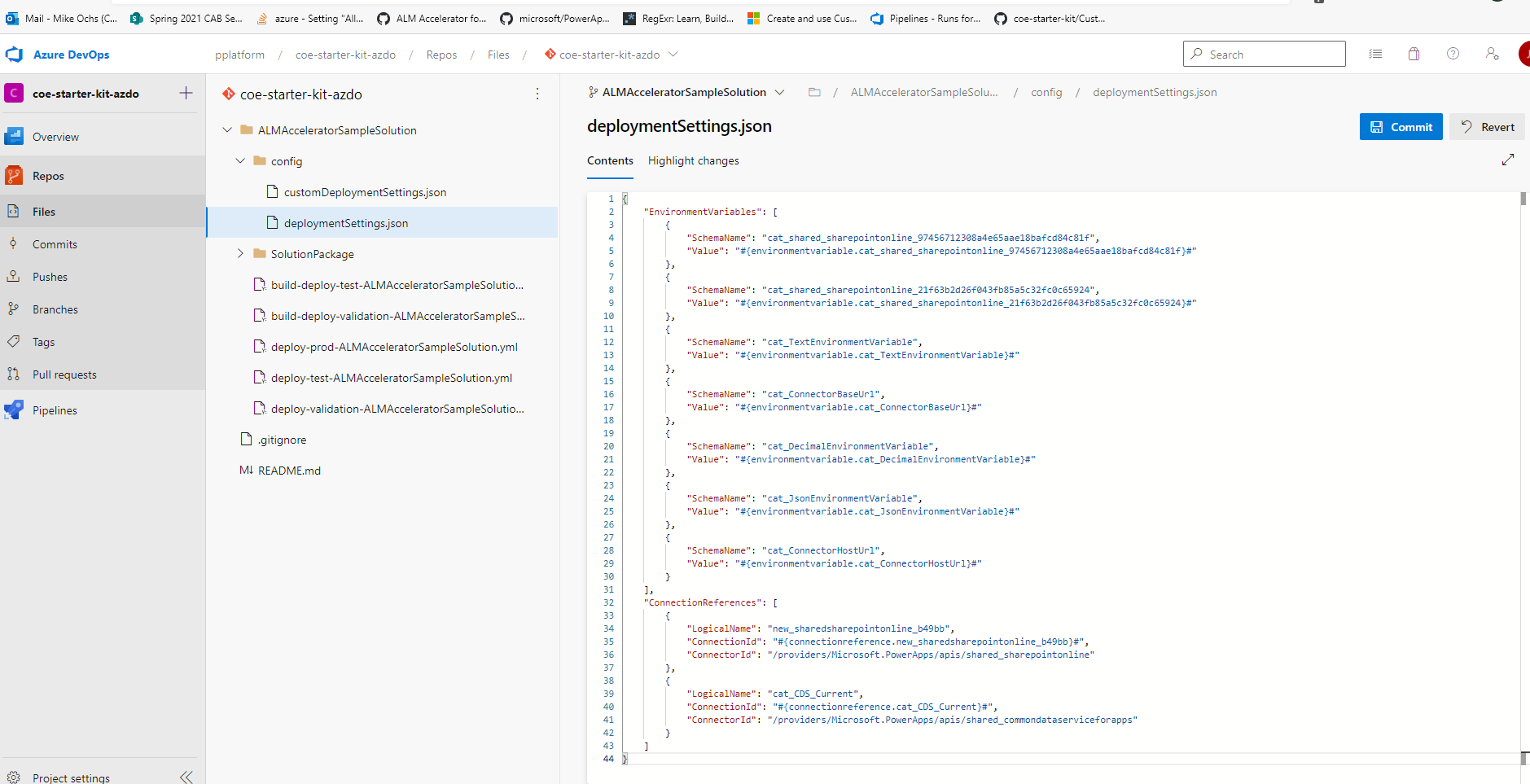
Le fichier JSON des paramètres de déploiement configure les références de connexion et les variables d’environnement.
{
"EnvironmentVariables": [
{
"SchemaName": "cat_shared_sharepointonline_97456712308a4e65aae18bafcd84c81f",
"Value": "#{environmentvariable.cat_shared_sharepointonline_97456712308a4e65aae18bafcd84c81f}#"
},
{
"SchemaName": "cat_shared_sharepointonline_21f63b2d26f043fb85a5c32fc0c65924",
"Value": "#{environmentvariable.cat_shared_sharepointonline_21f63b2d26f043fb85a5c32fc0c65924}#"
},
{
"SchemaName": "cat_TextEnvironmentVariable",
"Value": "#{environmentvariable.cat_TextEnvironmentVariable}#"
},
{
"SchemaName": "cat_ConnectorBaseUrl",
"Value": "#{environmentvariable.cat_ConnectorBaseUrl}#"
},
{
"SchemaName": "cat_DecimalEnvironmentVariable",
"Value": "#{environmentvariable.cat_DecimalEnvironmentVariable}#"
},
{
"SchemaName": "cat_JsonEnvironmentVariable",
"Value": "#{environmentvariable.cat_JsonEnvironmentVariable}#"
},
{
"SchemaName": "cat_ConnectorHostUrl",
"Value": "#{environmentvariable.cat_ConnectorHostUrl}#"
}
],
"ConnectionReferences": [
{
"LogicalName": "new_sharedsharepointonline_b49bb",
"ConnectionId": "#{connectionreference.new_sharedsharepointonline_b49bb}#",
"ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_sharepointonline"
},
{
"LogicalName": "cat_CDS_Current",
"ConnectionId": "#{connectionreference.cat_CDS_Current}#",
"ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_commondataserviceforapps"
}
]
}
Copiez l’exemple de code JSON précédent dans un nouveau fichier appelé deploymentSettings.json.
Enregistrez le fichier dans le dossier config dans Git.
Créer un fichier JSON de référence de connexion
La propriété ConnectionReferences du fichier customDeploymentConfiguration.json définit les références de connexion dans votre solution une fois la solution importée dans un environnement. ConnectionReferences permettent d’activer les flux après l’importation de la solution en fonction du propriétaire de la connexion spécifiée dans la variable.
Créez les connexions manuellement dans vos environnements cibles.
Copiez les ID des connexions.
Obtenez le nom logique de la référence de connexion à partir du composant de référence de connexion dans votre solution.
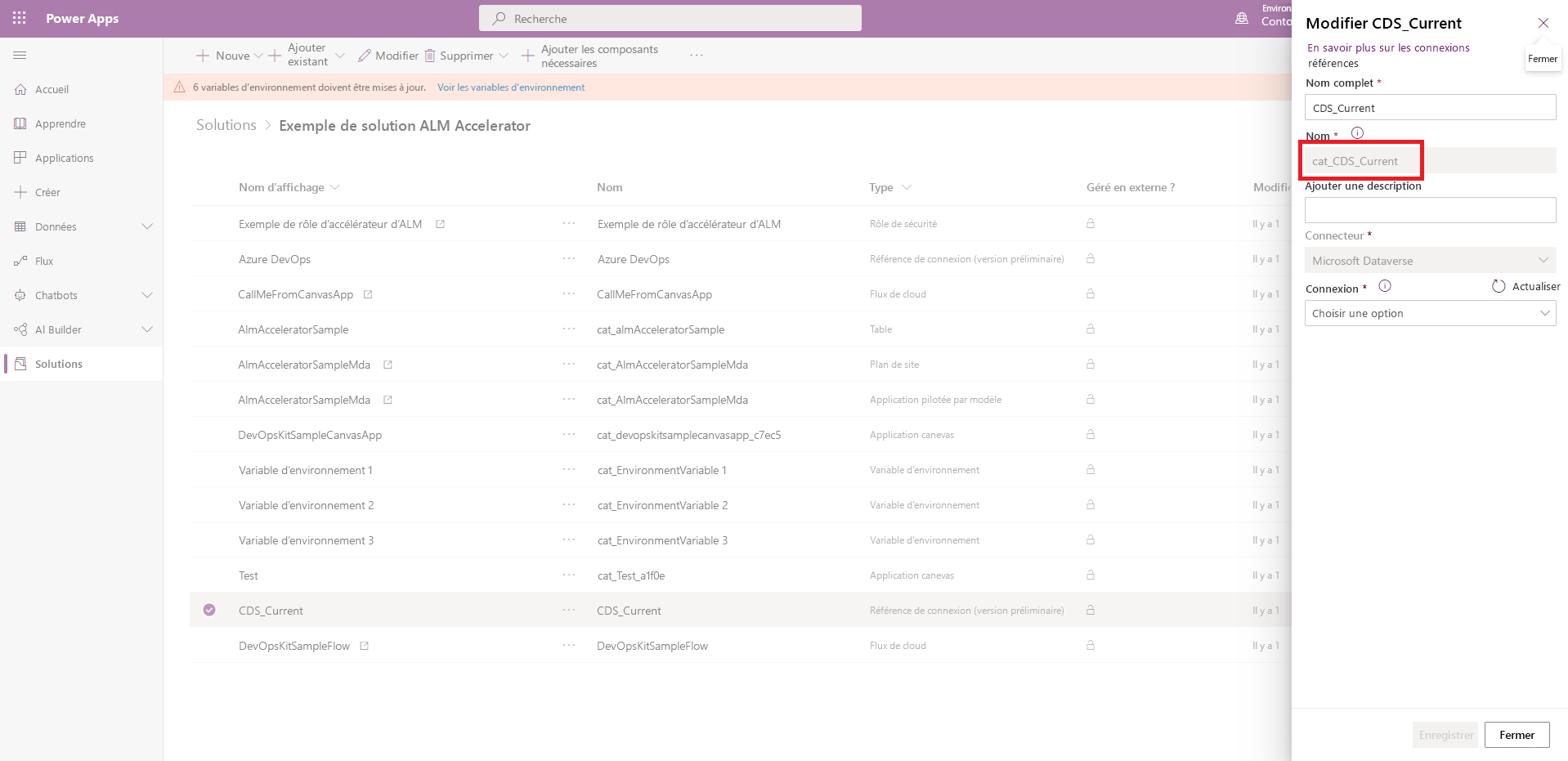
Obtenez l’ID de connexion via l’URL de la connexion après sa création. Par exemple, l’ID de la connexion ci-dessous est 9f66d1d455f3474ebf24e4fa2c04cea2, si l’URL est https://.../connections/shared_commondataservice/9f66d1d455f3474ebf24e4fa2c04cea2/details.
Modifiez le fichier customDeploymentSettings.json et collez les ID dans la propriété
ConnectionReferences, comme dans l’exemple de code suivant :"ConnectionReferences": [ { "LogicalName": "new_sharedsharepointonline_b49bb", "ConnectionId": "#{connectionreference.new_sharedsharepointonline_b49bb}#", "ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_sharepointonline" }, { "LogicalName": "cat_CDS_Current", "ConnectionId": "#{connectionreference.cat_CDS_Current}#", "ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_commondataserviceforapps" } ]Si vous utilisez l’extension "Remplacer les jetons" et que vous ajoutez des jetons dans votre configuration comme dans l’exemple précédent, ouvrez le pipeline de votre solution, puis sélectionnez Modifier>Variables.
Dans l’écran Variables de pipeline, créez la connexion <connection_reference_logicalname>. Dans cet exemple, la variable de pipeline est nommée
connection.cat_CDS_Current.Définissez la valeur sur l’ID de connexion que vous avez trouvé précédemment.
Pour vous assurer que la valeur n’est pas enregistrée en texte brut, sélectionnez Garder cette valeur secrète.
Le cas échéant, répétez les étapes ci-dessus pour chaque solution et pipeline que vous créez.
Créer la variable d’environnement JSON dans le fichier de configuration du déploiement
La propriété EnvironmentVariables du fichier customDeploymentConfiguration.json définit les variables d’environnement Dataverse dans votre solution une fois la solution importée dans un environnement.
Important
Lors de l’exportation des solutions contrôlée par la source des solutions, les valeurs des variables d’environnement sont exportées avec la solution. Cela peut constituer un risque pour la sécurité lorsque les variables d’environnement contiennent des informations sensibles. Nous vous recommandons de ne pas stocker d’informations sensibles dans des variables d’environnement. Une façon de vous assurer que vos valeurs de variable d’environnement ne sont pas contrôlées par la source consiste à créer une solution spécifiquement pour les valeurs de variable d’environnement dans vos environnements de développement et à définir leurs valeurs dans cette solution. Cela empêche les valeurs d’être exportées avec la solution et d’être stockées dans le contrôle de code source.
Copiez le nom de schéma de la variable d’environnement à partir du composant de variable d’environnement dans votre solution.
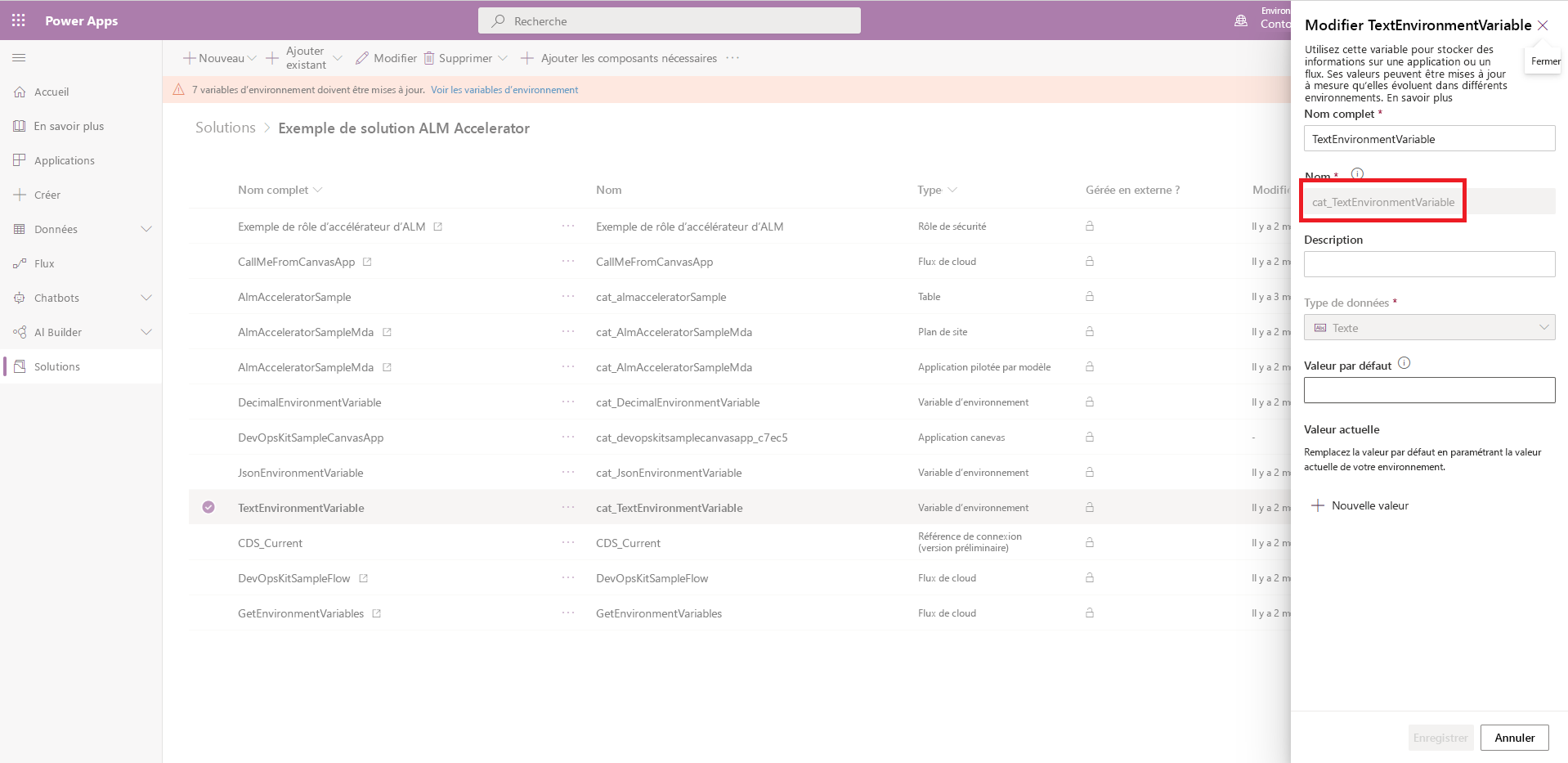
Modifiez le fichier customDeploymentSettings.json et collez le nom dans la propriété
EnvironmentVariables, comme dans l’exemple de code suivant :{ "EnvironmentVariables": [ { "SchemaName": "cat_TextEnvironmentVariable", "Value": "#{variable.cat_TextEnvironmentVariable}#" }, { "SchemaName": "cat_DecimalEnvironmentVariable", "Value": "#{variable.cat_DecimalEnvironmentVariable}#" }, { "SchemaName": "cat_JsonEnvironmentVariable", "Value": "{\"name\":\"#{variable.cat_JsonEnvironmentVariable.name}#\"}" } ] }Si vous utilisez l’extension "Remplacer les jetons" et que vous ajoutez des jetons dans votre configuration comme dans l’exemple précédent, ouvrez le pipeline de votre solution, puis sélectionnez Modifier>Variables.
Sur l’écran Variables de pipeline, créez une variable de pipeline pour chaque jeton de votre configuration, par exemple variable.cat_TextEnvironmentVariable.
Définissez la valeur comme valeur de variable d’environnement pour cet environnement.
Pour vous assurer que la valeur n’est pas enregistrée en texte brut, sélectionnez Garder cette valeur secrète.
Le cas échéant, répétez les étapes ci-dessus pour chaque solution et pipeline que vous créez.
Créer d’un fichier JSON des paramètres de déploiement personnalisés
Le fichier JSON de paramètres de déploiement personnalisé contient les paramètres pour activer les flux au nom d’un utilisateur, spécifier la propriété des flux, partager des applications de canevas avec les groupes Microsoft Entra et la création d’équipes de groupe Dataverse après déploiement.
{
"ActivateFlowConfiguration": [
{
"solutionComponentName": "DevOpsKitSampleFlow",
"solutionComponentUniqueName": "0a43b549-50ed-ea11-a815-000d3af3a7c4",
"activateAsUser": "#{activateflow.activateas.DevOpsKitSampleFlow}#"
},
{
"solutionComponentName": "CallMeFromCanvasApp",
"solutionComponentUniqueName": "71cc728c-2487-eb11-a812-000d3a8fe6a3",
"activateAsUser": "#{activateflow.activateas.CallMeFromCanvasApp}#"
},
{
"solutionComponentName": "GetEnvironmentVariables",
"solutionComponentUniqueName": "d2f7f0e2-a1a9-eb11-b1ac-000d3a53c3c2",
"activateAsUser": "#{activateflow.activateas.GetEnvironmentVariables}#"
}
],
"SolutionComponentOwnershipConfiguration": [
{
"solutionComponentType": 29,
"solutionComponentName": "DevOpsKitSampleFlow",
"solutionComponentUniqueName": "0a43b549-50ed-ea11-a815-000d3af3a7c4",
"ownerEmail": "#{owner.ownerEmail.DevOpsKitSampleFlow}#"
},
{
"solutionComponentType": 29,
"solutionComponentName": "CallMeFromCanvasApp",
"solutionComponentUniqueName": "71cc728c-2487-eb11-a812-000d3a8fe6a3",
"ownerEmail": "#{owner.ownerEmail.CallMeFromCanvasApp}#"
},
{
"solutionComponentType": 29,
"solutionComponentName": "GetEnvironmentVariables",
"solutionComponentUniqueName": "d2f7f0e2-a1a9-eb11-b1ac-000d3a53c3c2",
"ownerEmail": "#{owner.ownerEmail.GetEnvironmentVariables}#"
}
],
"AadGroupCanvasConfiguration": [
{
"aadGroupId": "#{canvasshare.aadGroupId.DevOpsKitSampleCanvasApp}#",
"canvasNameInSolution": "cat_devopskitsamplecanvasapp_c7ec5",
"canvasDisplayName": "DevOpsKitSampleCanvasApp",
"roleName": "#{canvasshare.roleName.DevOpsKitSampleCanvasApp}#"
}
],
"AadGroupTeamConfiguration": [
{
"aadGroupTeamName": "Sample Group Team Name",
"aadSecurityGroupId": "#{team.samplegroupteamname.aadSecurityGroupId}#",
"dataverseSecurityRoleNames": [
"#{team.samplegroupteamname.role}#"
]
}
]
}
Copiez l’exemple de code JSON précédent dans un nouveau fichier appelé customDeploymentSettings.json.
Enregistrez le fichier dans le dossier config dans Git.
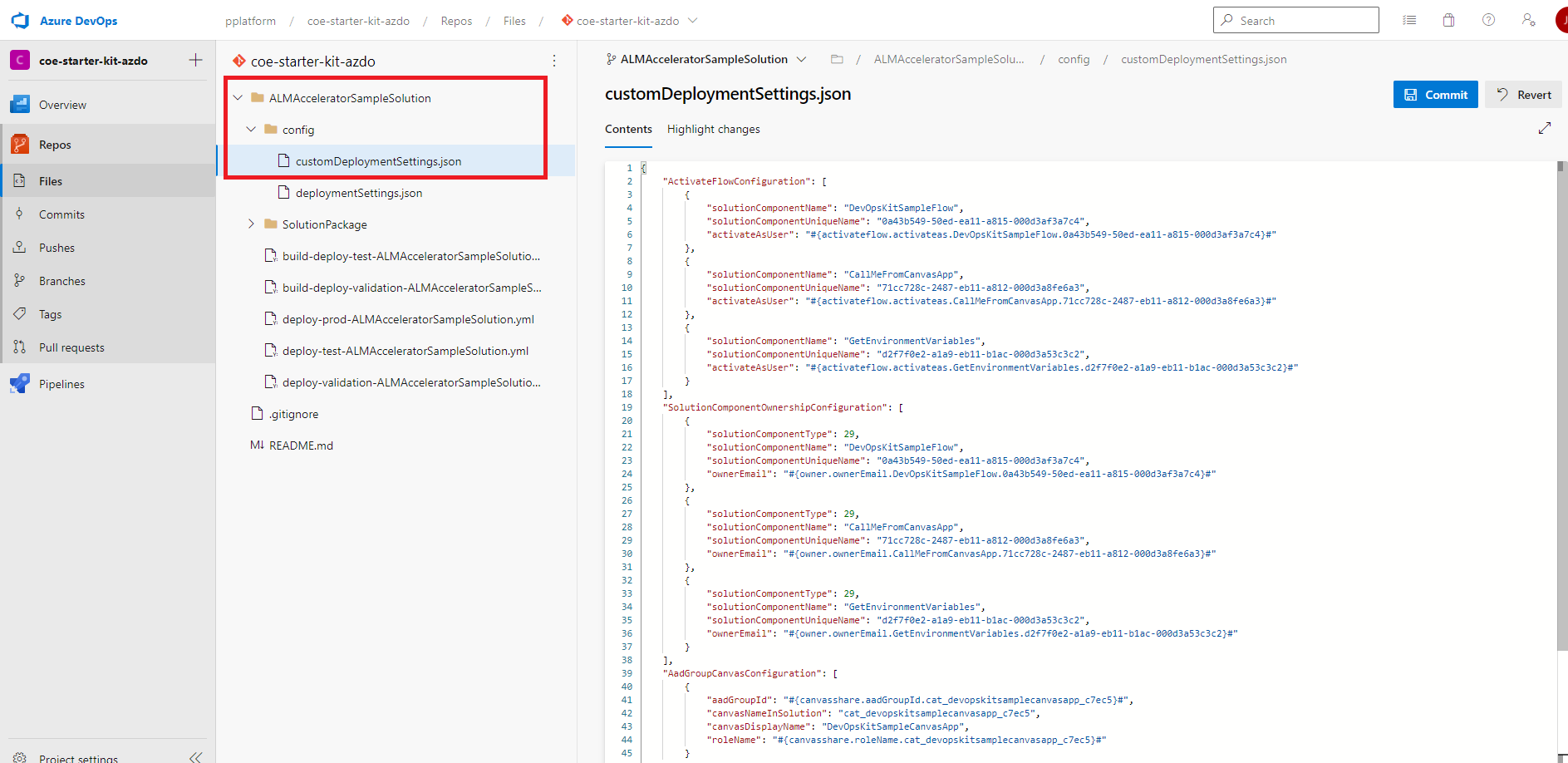
Créer la variable d’environnement JSON par défaut dans le fichier de configuration du déploiement personnalisé
La propriété DefaultEnvironmentVariables dans customDeploymentConfiguration.json est utilisée dans le pipeline d’exportation pour définir les variables d’environnement Dataverse par défaut dans votre solution lorsque la solution est exportée et stockée dans le contrôle de code source.
Note
Les paramètres de variables d’environnement par défaut s’appliquent uniquement si le pipeline d’exportation est configuré avec la variable de pipeline VerifyDefaultEnvironmentVariableValues = True.
Copiez le nom de schéma de la variable d’environnement à partir du composant de variable d’environnement dans votre solution.
Modifiez le fichier customDeploymentSettings.json et collez le nom dans la propriété
DefaultEnvironmentVariables, comme dans l’exemple de code suivant :{ "DefaultEnvironmentVariables": [ [ "cat_TextEnvironmentVariable", "#{defaultvariable.cat_TextEnvironmentVariable}#" ], [ "cat_DecimalEnvironmentVariable", "#{defaultvariable.cat_DecimalEnvironmentVariable}#" ], [ "cat_jsonEnvironmentVariable", "{\"name\":\"#{defaultvariable.cat_jsonEnvironmentVariable.name}#\"}" ] ] }Si vous utilisez l’extension "Remplacer les jetons" et que vous ajoutez des jetons dans votre configuration comme dans l’exemple précédent, ouvrez le pipeline de votre solution, puis sélectionnez Modifier>Variables.
Sur l’écran Variables de pipeline, créez une variable de pipeline pour chaque jeton de votre configuration, par exemple defaultvariable.cat_TextEnvironmentVariable.
Le cas échéant, répétez les étapes ci-dessus pour chaque solution et pipeline que vous créez.
Créer un fichier JSON de configuration du canevas de groupe Microsoft Entra
La propriété AadGroupCanvasConfiguration dans le fichier customDeploymentConfiguration.json partager des applications de canevas dans votre solution avec des groupes Microsoft Entra après l’importation de la solution dans un environnement.
Copiez les identifiants de l’application canevas et Microsoft Entra du groupe.
Obtient le nom de schéma de l’application canevas à partir du composant de l’application canevas dans votre solution.
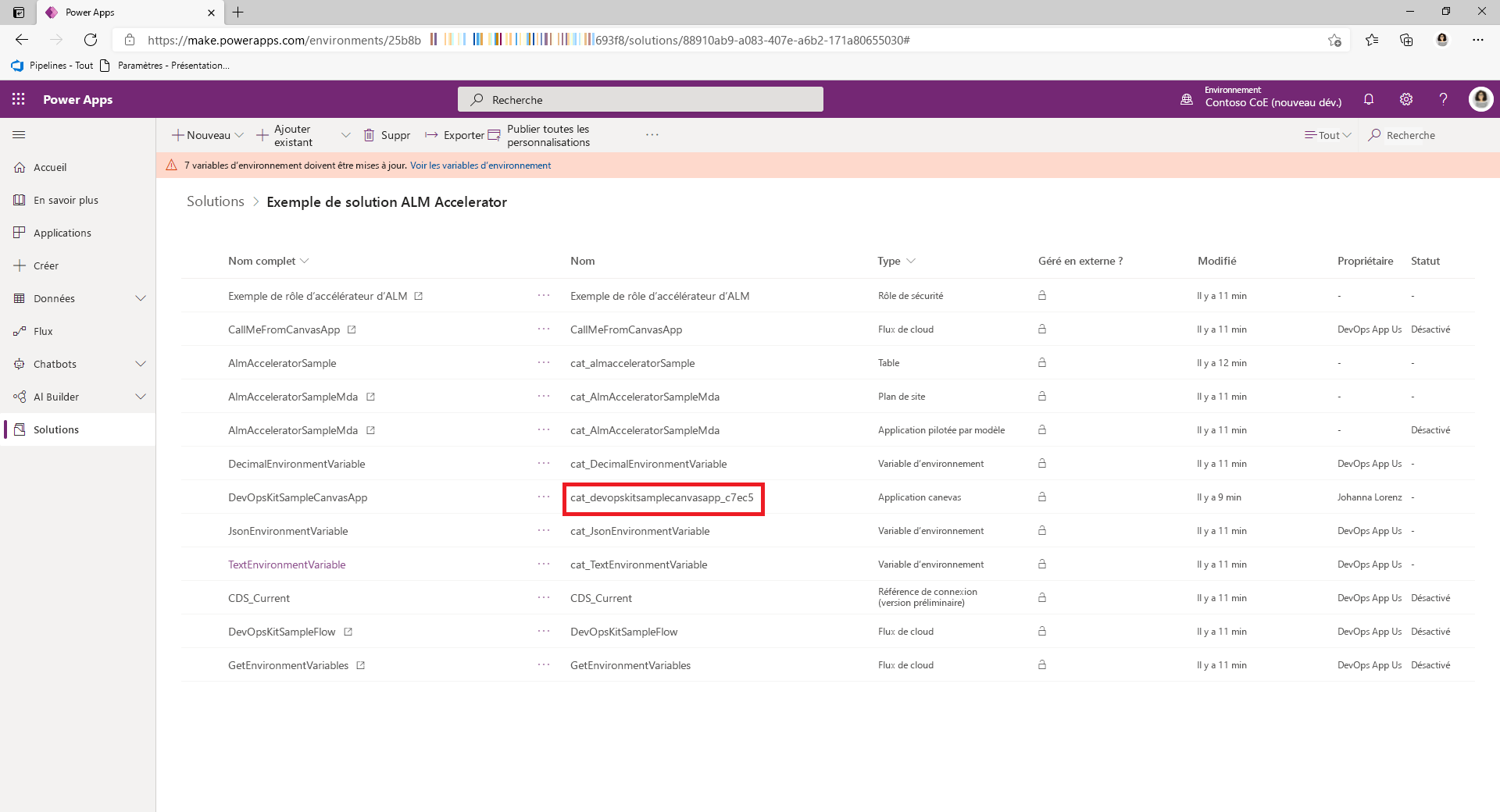
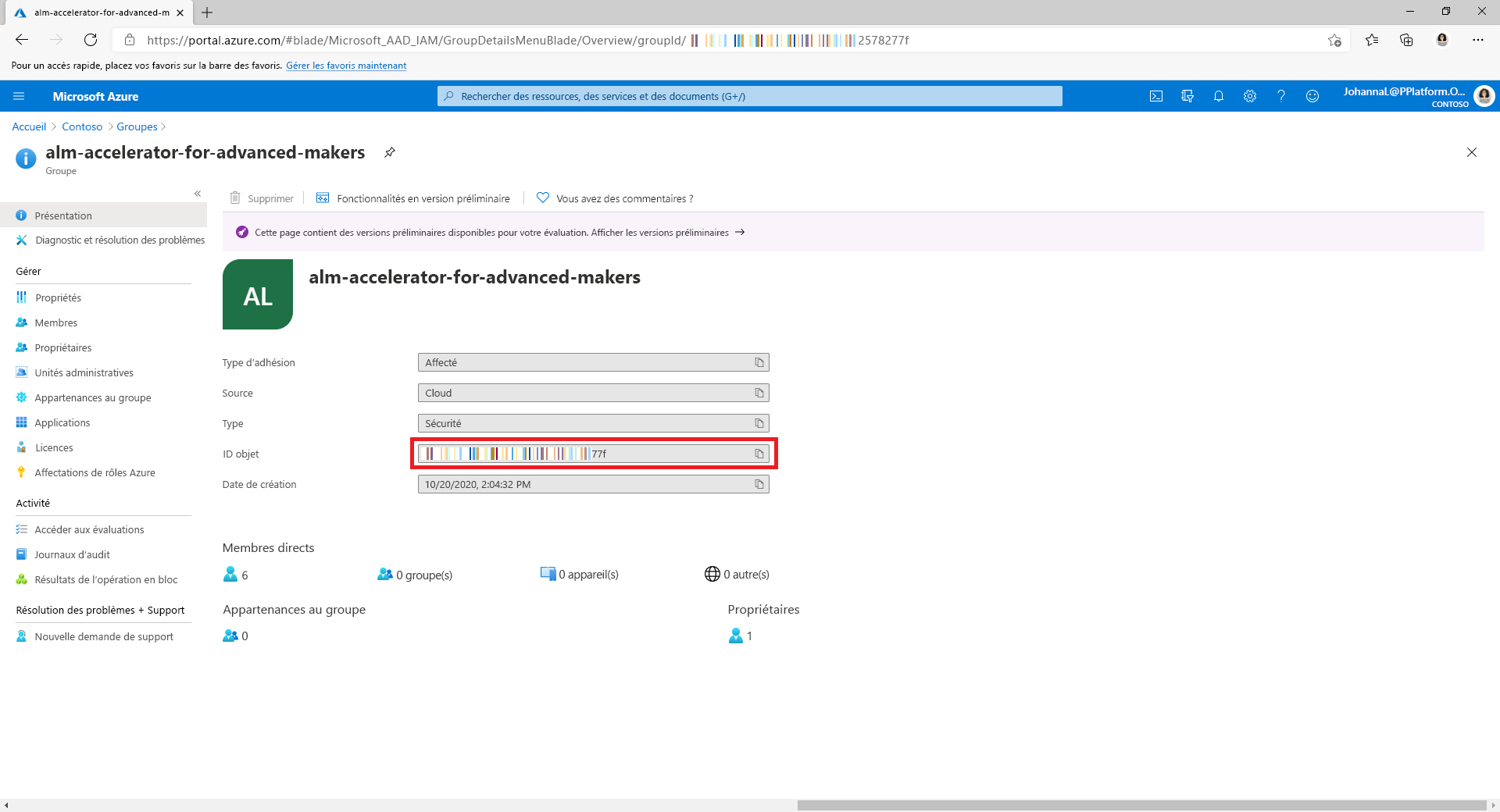
Obtient l’ID de groupe Microsoft Entra à partir de la page Groupe dans le portail Azure.
Modifiez le fichier customDeploymentSettings.json et collez les ID dans la propriété
AadGroupCanvasConfiguration, comme dans l’exemple de code suivant :{ "AadGroupCanvasConfiguration": [ { "aadGroupId": "#{canvasshare.aadGroupId}#", "canvasNameInSolution": "cat_devopskitsamplecanvasapp_c7ec5", "roleName": "#{canvasshare.roleName}#" } ] }Le
roleNamepeut êtreCanView,CanViewWithShareetCanEdit.Si vous utilisez l’extension "Remplacer les jetons" et que vous ajoutez des jetons dans votre configuration comme dans l’exemple précédent, ouvrez le pipeline de votre solution, puis sélectionnez Modifier>Variables.
Sur l’écran Variables de pipeline, créez une variable de pipeline pour chaque jeton de votre configuration, par exemple
canvasshare.aadGroupId.Définissez la valeur sur l’ID de groupe Microsoft Entra avec lequel l’application doit être partagée pour cet environnement spécifique.
Pour vous assurer que la valeur n’est pas enregistrée en texte brut, sélectionnez Garder cette valeur secrète.
Le cas échéant, répétez les étapes ci-dessus pour chaque solution et pipeline que vous créez.
Créer un fichier JSON de configuration d’équipes et de groupes Microsoft Entra
La propriété AadGroupTeamConfiguration du fichier customDeploymentConfiguration.json mappe les équipes et les rôles Dataverse vers les groupes Microsoft Entra dans votre solution une fois la solution importée dans un environnement.
Les rôles de sécurité doivent être ajoutés à votre solution s’ils ne sont pas créés manuellement dans l’environnement cible. Un ou plusieurs rôles peuvent être appliqués à une équipe. Les rôles fournissent des autorisations aux composants de solution requis par les utilisateurs du groupe.
Le nom de l’équipe Dataverse peut être une équipe existante ou une nouvelle équipe à créer dans Dataverse et mappé à un groupe Microsoft Entra après l’importation de la solution.
Les rôles Dataverse peuvent être n’importe quel rôle de sécurité dans Dataverse qui serait appliqué à l’équipe après l’importation de la solution. Les rôles doivent avoir des privilèges sur les ressources requises par la solution, telles que les tables et les processus.
Obtient l’ID de groupe Microsoft Entra à partir de la page Groupe dans le portail Azure dans la section précédente.
Modifiez le fichier customDeploymentSettings.json et collez le fichier JSON dans la propriété
AadGroupTeamConfiguration, comme dans l’exemple de code suivant :{ "AadGroupTeamConfiguration": [ { "aadGroupTeamName": "alm-accelerator-sample-solution", "aadSecurityGroupId": "#{team.aadSecurityGroupId}#", "dataverseSecurityRoleNames": [ "ALM Accelerator Sample Role" ] } ] }Si vous utilisez l’extension "Remplacer les jetons" et que vous ajoutez des jetons dans votre configuration comme dans l’exemple précédent, ouvrez le pipeline de votre solution, puis sélectionnez Modifier>Variables.
Sur l’écran Variables de pipeline, créez une variable de pipeline pour chaque jeton de votre configuration, par exemple
team.aadSecurityGroupId.Définissez la valeur sur Microsoft Entra ID de groupe à associer à l’équipe dans Dataverse.
Pour vous assurer que la valeur n’est pas enregistrée en texte brut, sélectionnez Garder cette valeur secrète.
Le cas échéant, répétez les étapes ci-dessus pour chaque solution et pipeline que vous créez.
Créer la propriété du composant de solution JSON
La propriété SolutionComponentOwnershipConfiguration dans customDeploymentConfiguration.json attribue la propriété des composants de la solution aux utilisateurs Dataverse après l’importation de la solution dans un environnement. L’attribution de la propriété est utile pour les composants tels que les flux qui appartiennent par défaut à l’utilisateur principal du service après la solution est importée par le pipeline et que les organisations souhaitent les réattribuer après l’importation.
La propriété SolutionComponentOwnershipConfiguration est aussi utilisée pour activer les flux qui n’ont aucune référence de connexion. Le flux est activé par l’utilisateur spécifié lorsqu’aucune référence de connexion n’est trouvée à utiliser pour activer le flux.
Note
Le pipeline actuel implémente uniquement la possibilité de définir la propriété des flux.
Le code de type de composant de solution est basé sur les types de composants spécifiés dans la référence de l’API Web solutioncomponent EntityType. Par exemple, un flux Power Automate est le type de composant 29. Le type de composant doit être spécifié sous la forme d’une valeur entière, sans guillemets.
Obtenez le nom unique du composant de flux Power Automate de la solution non conditionnée.
Les flux ne nécessitent pas de noms uniques lors de leur création. Le seul véritable identifiant unique pour un flux est l’ID interne que le système attribue dans une solution.
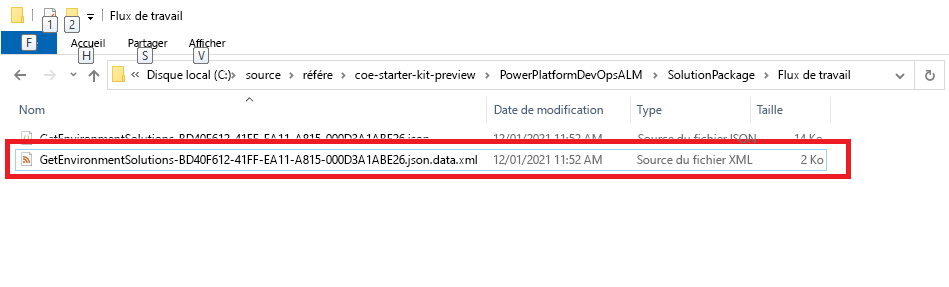
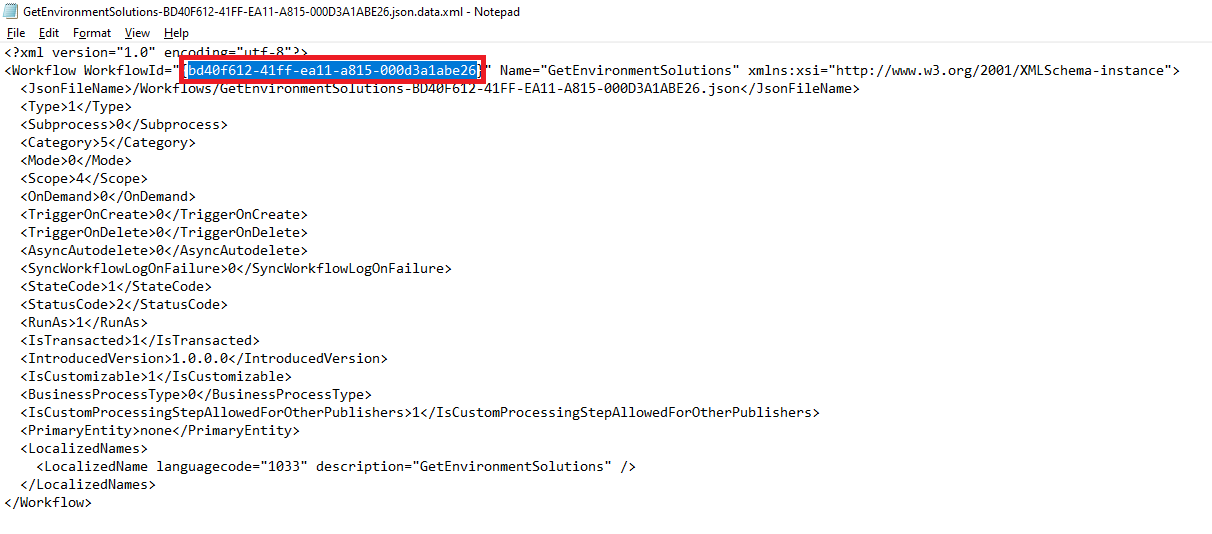
Obtenez l’adresse e-mail du propriétaire à partir de l’enregistrement de l’utilisateur dans Dataverse ou Microsoft 365.
Modifiez le fichier customDeploymentSettings.json et collez le fichier JSON dans la propriété
AadGroupTeamConfiguration, comme dans l’exemple de code suivant :{ "SolutionComponentOwnershipConfiguration": [ { "solutionComponentType": 29, "solutionComponentUniqueName": "00000000-0000-0000-0000-00000000000", "ownerEmail": "#{owner.ownerEmail}#" }, { "solutionComponentType": 29, "solutionComponentUniqueName": "00000000-0000-0000-0000-00000000000", "ownerEmail": "#{owner.ownerEmail}#" } ] }Si vous utilisez l’extension "Remplacer les jetons" et que vous ajoutez des jetons dans votre configuration comme dans l’exemple précédent, ouvrez le pipeline de votre solution, puis sélectionnez Modifier>Variables.
Sur l’écran Variables de pipeline, créez une variable de pipeline pour chaque jeton de votre configuration, par exemple
owner.ownerEmail.Définissez la valeur sur l’adresse e-mail du propriétaire du composant.
Pour vous assurer que la valeur n’est pas enregistrée en texte brut, sélectionnez Garder cette valeur secrète.
Le cas échéant, répétez les étapes ci-dessus pour chaque solution et pipeline que vous créez.
Importer des données depuis votre pipeline
Il y aura des données de configuration ou de départ que vous souhaiterez importer dans votre environnement Dataverse après le déploiement de votre solution dans l’environnement cible. Les pipelines sont configurés pour importer des données à l’aide de l’outil de migration de configuration disponible via NuGet. En savoir plus sur la gestion du résumé de la conversation.
Lors du stockage de des données de configuration à la racine du répertoire de configuration, les même données de configuration sont déployées à tous les environnements. Vous pouvez créer des fichiers de données de configuration spécifiques à l’environnement. Stockez-les dans des sous-répertoires du configuration répertoire, nommé pour vos environnements. Le nom du répertoire doit correspondre à la variable de pipeline EnvironmentName lors de la configuration de votre pipeline pour environnements de validation, test, production. Si aucune donnée de configuration et aucun répertoire spécifiques à l’environnement ne sont trouvés, les pipelines reviendront aux données de configuration à la racine du répertoire de configuration.
Clonez le référentiel Azure DevOps où votre solution doit être contrôlée par la source et où vous avez créé votre pipeline de solution YAML sur votre ordinateur local.
Si ce n’est pas encore fait, créez un répertoire nommé configuration dans le dossier de config de votre dossier de solution.

Installez l’outil Migration de la configuration. Suivez les instructions de la section Télécharger les outils à partir de NuGet.
Ouvrez l’outil Migration de configuration, sélectionnez Créer un schéma, puis Continuer.
Connectez-vous au client à partir duquel vous souhaitez exporter vos données de configuration.
Sélectionnez votre environnement.
Sélectionnez les tables et colonnes à exporter.
Cliquez sur Enregistrer et exporter. Enregistrez les données dans le chemin du répertoire config\ConfigurationMigrationData dans votre référentiel local Azure DevOps sous le dossier de la solution pour lequel les données doivent être importées.
Note
Le pipeline recherche ce dossier spécifique pour exécuter l’importation des données après l’importation de votre solution. Assurez-vous que le nom du dossier et son emplacement sont exactement comme indiqué ici.
Lorsque vous êtes invité.e à exporter les données, sélectionnez Oui.
Choisissez le même emplacement pour vos données exportées, sélectionnez Enregistrer, puis Exporter des données.
Lorsque l’exportation est terminée, décompressez les fichiers du fichier data.zip vers le répertoire ConfigurationMigrationData. Supprimez les fichiers data.zip et SampleData.xml.
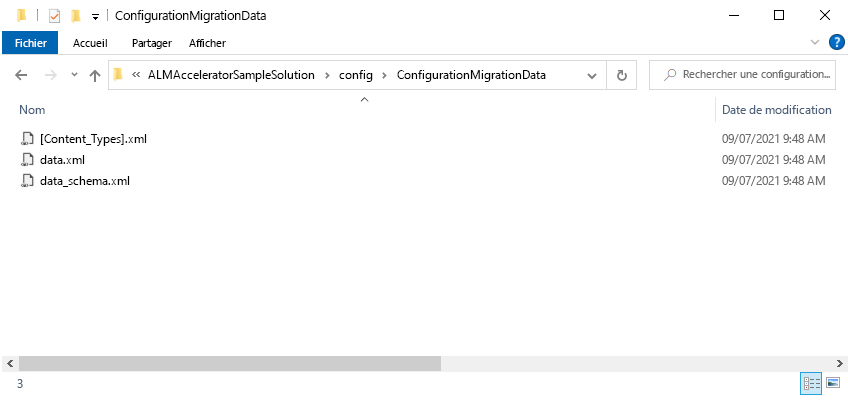
Validez les modifications avec vos données dans Azure DevOps.
Étapes suivantes
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour