Migrer votre cluster pour prendre en charge plusieurs zones de disponibilité (préversion)
De nombreuses régions Azure fournissent des zones de disponibilité, qui sont des groupes séparés de centres de données au sein d’une région. Les zones de disponibilité sont suffisamment proches pour disposer de connexions à faible latence à d’autres zones de disponibilité. Ils sont connectés par un réseau hautes performances avec une latence aller-retour de moins de 2 ms. Toutefois, les zones de disponibilité sont assez éloignées pour réduire la probabilité que plusieurs personnes soient affectées par des pannes locales ou des conditions météorologiques. Les zones de disponibilité disposent d’une alimentation, d’un système de refroidissement et d’une infrastructure réseau indépendants. Ils sont conçus de sorte que, si une zone subit une panne, les services régionaux, la capacité et la haute disponibilité soient pris en charge par les zones restantes. Pour plus d’informations, consultez Azure Zones de disponibilité.
Les clusters Azure Data Explorer peuvent être configurés pour utiliser des zones de disponibilité dans les régions prises en charge. En utilisant des zones de disponibilité, un cluster peut mieux résister à l’échec d’un seul centre de données dans une région pour prendre en charge les scénarios de continuité d’activité.
Vous pouvez configurer des zones de disponibilité lors de la création d’un cluster dans le Portail Azure ou par programmation à l’aide de l’une des méthodes suivantes :
- API REST
- Kit de développement logiciel (SDK) C#
- Kit de développement logiciel (SDK) Python
- PowerShell
- Modèle ARM
Important
- Une fois qu’un cluster est configuré avec des zones de disponibilité, vous ne pouvez pas modifier le cluster pour ne pas utiliser de zones de disponibilité.
- Plusieurs zones ne sont pas prises en charge dans toutes les régions. Par conséquent, les clusters situés dans ces régions ne peuvent pas être configurés pour utiliser des zones de disponibilité.
- L’utilisation de zones de disponibilité entraîne des coûts supplémentaires.
Remarque
- Avant de continuer, veillez à vous familiariser avec le processus de migration et les considérations.
- Vous pouvez également utiliser ces étapes pour modifier les zones d’un cluster existant qui utilise des zones de disponibilité.
Cet article porte sur les points suivants :
Prérequis
Vérifiez que votre cluster se trouve dans une région où la migration vers plusieurs zones de disponibilité est prise en charge. Pour plus d’informations, consultez Régions prises en charge.
Pour migrer un cluster pour prendre en charge les zones de disponibilité, vous avez besoin d’un cluster qui a été déployé sans aucune zone de disponibilité.
Pour modifier les zones d’un cluster, vous avez besoin d’un cluster configuré avec des zones de disponibilité.
Pour l’API REST, familiarisez-vous avec gérer les ressources Azure à l’aide de l’API REST.
Pour obtenir d’autres méthodes programmatiques, consultez Conditions préalables.
Régions prises en charge
La migration vers plusieurs zones de disponibilité est limitée aux régions qui n’ont pas de restrictions de capacité. Les régions suivantes sont actuellement prises en charge :
- Australie Est
- Centre du Canada
- Chine Nord 3
- Inde Centre
- Europe Nord
- Norvège Est
- Afrique du Sud Nord
- Suède Centre
- Émirats arabes unis Nord
- Sud du Royaume-Uni
Obtenir la liste des zones de disponibilité pour la région de votre cluster
Vous pouvez obtenir la liste des zones de disponibilité de votre cluster de différentes manières :
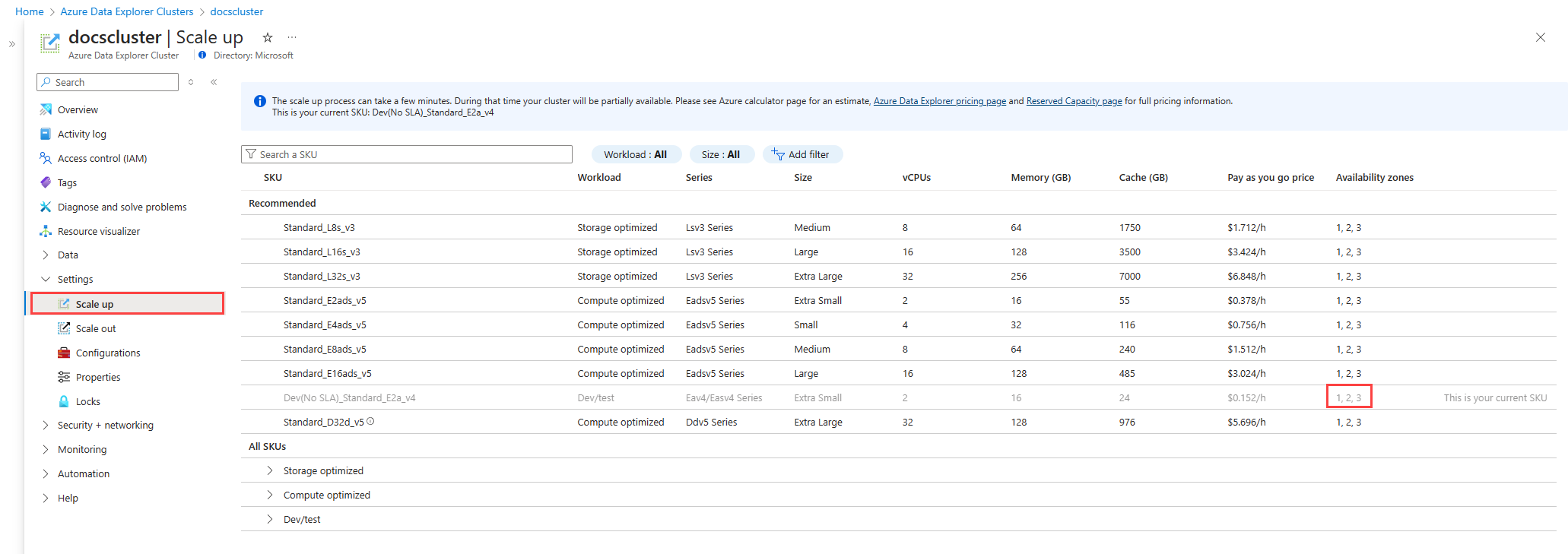
Dans le Portail Azure, accédez à la page Vue d’ensemble de votre cluster.
Sous Paramètres, sélectionnez Scale-up.
Dans la ligne de votre cluster, les zones de disponibilité sont répertoriées dans la colonne Zones de disponibilité.

Configurer votre cluster pour prendre en charge les zones de disponibilité
Pour ajouter des zones de disponibilité à un cluster existant, vous devez mettre à jour l’attribut de cluster zones avec une liste des zones de disponibilité cibles. Suivez les instructions de votre méthode préférée, à l’aide des informations contenues dans le tableau suivant :
| Paramètre | Valeur |
|---|---|
subscriptionId |
ID d’abonnement du cluster |
resourceGroupName |
Nom du groupe de ressources du cluster |
clusterName |
Nom du cluster |
apiVersion |
2023-05-02 ou ultérieur |
Important
La modification des zones de disponibilité d’un cluster existant modifie uniquement les zones de disponibilité pour le calcul. Le stockage persistant n’est pas modifié.
Suivez les instructions sur le déploiement d’un modèle.
Effectuez l’appel de l’API REST au point de terminaison suivant où vous remplacez les paramètres par vos valeurs :
PUT https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Kusto/clusters/{clusterName}?api-version={apiVersion}Spécifiez vos zones de disponibilité dans le corps de la requête. Par exemple, pour configurer le cluster pour utiliser les zones de disponibilité 1, 2 et 3, définissez le corps comme suit :
{ "zones": [ "{zone1}", "{zone2}", "{zone3}" ] }
Pendant la migration, le message suivant s’affiche dans la Portail Azure, dans la page de vue d’ensemble du cluster. Le message est supprimé une fois la migration terminée.
Le changement de zonalité pour le stockage de ce cluster est en cours. L’heure de mise à jour peut varier en fonction de la quantité de données.
Architecture des clusters avec zones de disponibilité
Lorsque les zones de disponibilité sont configurées, les ressources d’un cluster sont déployées comme suit :
Couche de calcul : Azure Data Explorer est une plateforme de calcul distribuée qui a deux nœuds ou plus. Si les zones de disponibilité sont configurées, les nœuds de calcul sont répartis entre la zone de disponibilité définie pour une résilience intrarégion maximale. Une défaillance de zone peut dégrader les performances du cluster jusqu’à ce que les ressources de calcul ayant échoué soient redéployées dans les zones survivantes. Nous vous recommandons de configurer les zones disponibles maximales dans une région.
Remarque
- Dans certains cas, en raison des limitations de capacité de calcul, seules les zones de disponibilité partielles seront disponibles pour la couche de calcul.
- La couche de calcul d’un cluster implémente une approche optimale pour répartir uniformément les instances entre les zones sélectionnées.
Couche de stockage persistant : les clusters utilisent Stockage Azure comme couche de persistance durable. Si les zones de disponibilité sont configurées, ZRS est activé, plaçant les réplicas de stockage dans les trois zones de disponibilité pour une résilience intra-région maximale.
Remarque
- ZRS entraîne un coût supplémentaire.
- Lorsque les zones de disponibilité ne sont pas configurées, les ressources de stockage sont déployées avec le paramètre par défaut de l’Stockage localement redondant (LRS), le placement de tous les 3 réplicas est une seule zone.
Processus de migration
Lorsqu’un cluster existant déployé sans zones de disponibilité est configuré pour prendre en charge les zones de disponibilité, les étapes suivantes s’effectuent dans le cadre du processus de migration :
Le calcul est distribué dans les zones de disponibilité définies
Le processus de redistribution des ressources de calcul implique une phase de préparation dans laquelle le cache des ressources de calcul zonales est réchauffé. Pendant la phase de préparation, les ressources de calcul du cluster existant continuent de fonctionner, ce qui garantit un service ininterrompu. Cette phase de préparation peut prendre jusqu’à des dizaines de minutes. La transition vers les nouvelles ressources de calcul ne se produit qu’une fois qu’elle est entièrement préparée et opérationnelle. Cette approche de traitement parallèle garantit une expérience relativement fluide, avec seulement une interruption de service minimale pendant le processus de basculement, généralement d’une à trois minutes. Toutefois, il est important de noter que les performances des requêtes peuvent être affectées pendant la migration de la référence SKU. Le degré d’impact peut varier en fonction des modèles d’utilisation spécifiques.
Les données de stockage persistantes historiques sont migrées vers ZRS
Le processus de migration dépend de la prise en charge régionale de la transition du stockage LRS vers le stockage ZRS, ainsi que de la capacité des comptes de stockage disponibles dans les zones sélectionnées. Le transfert de données historiques peut être un processus fastidieux, pouvant prendre plusieurs heures ou même s’étendre sur plusieurs semaines.
Toutes les nouvelles données sont écrites dans ZRS
Une fois la demande de migration vers les zones de disponibilité lancée, toutes les nouvelles données sont répliquées et stockées dans la configuration ZRS.
Remarque
- Après la demande de migration, il peut y avoir un délai allant jusqu’à plusieurs minutes avant que toutes les nouvelles données ne commencent à être écrites dans la configuration ZRS.
- Si un cluster a une ingestion de streaming, le recyclage des nouvelles données à écrire en tant que données ZRS peut prendre jusqu’à 30 jours.
À propos de l’installation
La demande de migration vers des zones de disponibilité peut ne pas réussir en raison de contraintes de capacité. Pour une migration réussie, il doit y avoir suffisamment de capacité de calcul et de stockage pour prendre en charge la migration. S’il existe des limitations de capacité, vous obtenez un message d’erreur indiquant le problème.
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour