Didacticiel : exécuter Python sur un cluster et en tant que job en utilisant l'extension Databricks pour Visual Studio Code
Ce tutoriel vous guide dans la configuration de l'extension Databricks pour Visual Studio Code, puis dans l'exécution de Python sur un cluster Azure Databricks et en tant que tâche Azure Databricks dans votre espace de travail distant. Consultez Présentation de l’extension Databricks pour Visual Studio Code.
Spécifications
Ce didacticiel requiert que :
- Vous avez installé l’extension Databricks pour Visual Studio Code. Consultez Installer l’extension Databricks pour Visual Studio Code.
- Vous disposez d’un cluster Azure Databricks distant à utiliser. Notez le nom de votre cluster. Pour afficher vos clusters disponibles, dans la barre latérale de votre espace de travail Azure Databricks, cliquez sur Calcul. Voir Calculer.
Étape 1 : Créer un projet Databricks
Dans cette étape, vous créez un projet Databricks et configurez la connexion avec votre espace de travail Azure Databricks distant.
- Lancez Visual Studio Code, puis cliquez sur Fichier > Ouvrir le dossier et ouvrez un dossier vide sur votre ordinateur de développement local.
- Dans la barre latérale, cliquez sur l’icône du logo Databricks. Cela ouvre l’extension Databricks.
- Dans la vue Configuration, cliquez sur Créer une configuration.
- La palette de commandes pour configurer votre espace de travail Databricks s’ouvre. Pour l’hôte Databricks, entrez ou sélectionnez votre URL par espace de travail, par exemple
https://adb-1234567890123456.7.azuredatabricks.net. - Sélectionnez un profil d’authentification pour le projet. Consultez Configurer l’autorisation pour l’extension Databricks pour Visual Studio Code.
Étape 2 : Ajoutez des informations de cluster à l’extension Databricks et démarrez le cluster
Une fois l’affichage Configuration déjà ouvert, cliquez sur Sélectionner un cluster ou cliquez sur l’icône engrenage (Configurer le cluster).
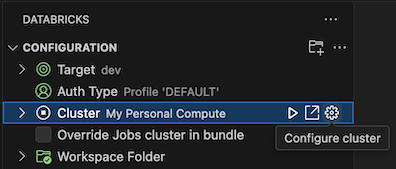
Dans la palette de commandes, sélectionnez le nom du cluster que vous avez créé précédemment.
Cliquez sur l’icône de lecture (Démarrer le cluster) si elle n’est pas déjà démarrée.
Étape 3 : Créez et exécutez du code Python
Créez un fichier de code Python local : dans la barre latérale, cliquez sur l’icône du dossier (Explorer).
Dans le menu principal, cliquez sur Fichier > Nouveau fichier et choisissez un fichier Python. Nommez le fichier demo.py, puis enregistrez-le à la racine du projet.
Ajoutez le code suivant au fichier, puis enregistrez-le. Ce code crée, puis affiche le contenu d’un DataFrame PySpark de base :
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Cliquez sur l’icône Exécuter sur Databricks en regard de la liste des onglets de l’éditeur, puis cliquez sur Charger et exécuter un fichier. La sortie apparaît dans la vue Console de débogage.
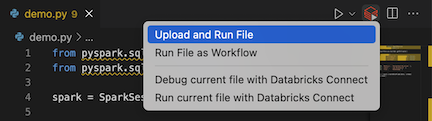
Vous pouvez également, dans la vue Explorateur, cliquez avec le bouton droit de la souris sur le fichier
demo.py, puis cliquez sur Exécuter sur Databricks>Télécharger et exécuter le fichier.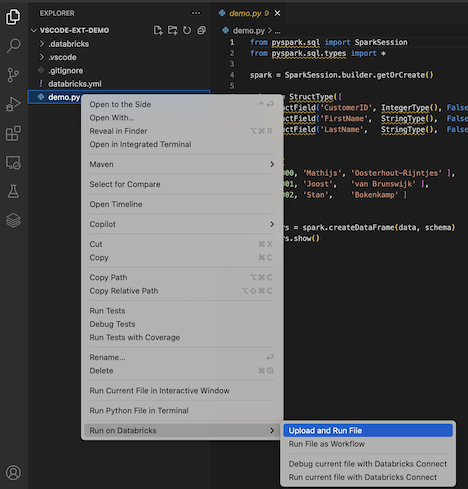
Étape 4 : Exécutez le code en tant que travail
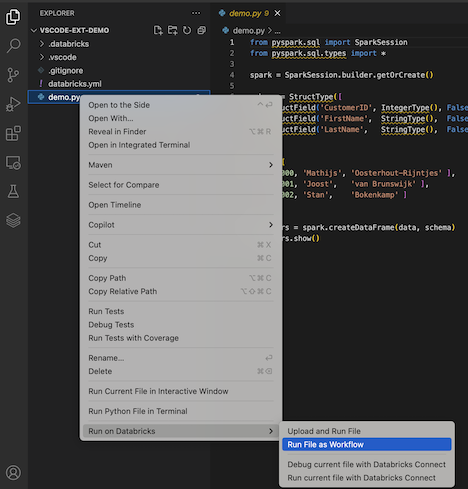
Pour exécuter demo.py en tant que travail, cliquez sur l’icône Exécuter sur Databricks en regard de la liste des onglets de l’éditeur, puis cliquez sur Exécuter un fichier en tant que flux de travail. La sortie apparaît dans un onglet d’éditeur distinct en regard de l’éditeur de fichiers demo.py.
![]()
Vous pouvez également cliquer avec le bouton droit sur le fichier demo.py dans le panneau Explorateur, puis sélectionner Exécuter sur Databricks>Exécuter le fichier en tant que flux de travail.
Étapes suivantes
Maintenant que vous avez correctement utilisé l’extension Databricks de Visual Studio Code pour charger un fichier Python local et l’exécuter à distance, vous pouvez également :
- Explorez les ressources et les variables packs de ressources Databricks à l’aide de l’interface utilisateur de l’extension. Consultez Fonctionnalités d’extension des packs de ressources Databricks.
- Exécuter ou déboguer du code Python avec Databricks Connect. Consultez Déboguer le code à l’aide de Databricks Connect pour l’extension Databricks pour Visual Studio Code.
- Exécutez un fichier ou un notebook en tant que travail Azure Databricks. Consultez Exécuter un fichier sur un cluster ou un fichier ou notebook en tant que job dans Azure Databricks à l'aide de l'extension Databricks pour Visual Studio Code.
- Exécutez des tests avec
pytest. Consultez Exécuter des tests avec pytest à l’aide de l’extension Databricks pour Visual Studio Code.