Développer du code dans les notebooks Databricks
Cette page explique comment développer du code dans des notebooks Databricks, notamment l’autocomplétion, la mise en forme automatique pour Python et SQL, la combinaison de Python et de SQL dans un notebook et le suivi de l’historique des versions du notebook.
Pour plus d’informations sur les fonctionnalités avancées disponibles avec l’éditeur, telles que l’autocomplétion, la sélection de variables, la prise en charge de plusieurs curseurs et les différences côte à côte, consultez Utiliser le notebook Databricks et l’éditeur de fichiers.
Lorsque vous utilisez le notebook ou l’éditeur de fichiers, l’Assistant Databricks est disponible pour vous aider à générer, à expliquer et à déboguer du code. Pour plus d’informations, consultez Utiliser l’Assistant Databricks.
Les notebooks Databricks intègrent également un débogueur interactif pour les notebooks Python. Voir Déboguer les notebooks.
Obtenir de l’aide sur le codage à partir de l’Assistant Databricks
L’Assistant Databricks est un assistant IA prenant en charge le contexte avec lequel vous pouvez interagir par une interface conversationnelle, ce qui vous rend plus productif dans Databricks. Vous pouvez décrire votre tâche en anglais et laisser l’Assistant générer du code Python ou des requêtes SQL, expliquer le code complexe et corriger automatiquement les erreurs. L’Assistant utilise les métadonnées Unity Catalog pour comprendre vos tables, colonnes, descriptions et ressources de données populaires au sein de votre entreprise pour fournir des réponses personnalisées.
L’Assistant Databricks peut vous aider à accomplir les tâches suivantes :
- Générer du code.
- Déboguer du code, y compris identifier et suggérer des correctifs pour les erreurs.
- Transformer et optimiser le code.
- Expliquer le code.
- Vous aider à trouver des informations pertinentes dans la documentation Azure Databricks.
Pour obtenir des informations sur l’utilisation de l’Assistant Databricks afin de vous aider à coder plus efficacement, consultez Utiliser l’Assistant Databricks. Pour obtenir des informations générales sur l’Assistant Databricks, consultez Fonctionnalités avec DatabricksIQ.
Accéder au notebook pour le modifier
Pour ouvrir un notebook, utilisez la fonction de recherche de l’espace de travail ou utilisez le navigateur de l’espace de travail pour accéder au notebook et cliquez sur son nom ou son icône.
Parcourir des données
Utilisez le navigateur de schémas pour explorer des objets Unity Catalog disponibles pour le notebook. Cliquez sur l’![]() sur le côté gauche du notebook pour ouvrir le navigateur de schémas.
sur le côté gauche du notebook pour ouvrir le navigateur de schémas.
Le bouton Pour vous affiche uniquement les tables utilisées dans la session active ou précédemment marquées comme Favoris.
Lorsque vous tapez du texte dans la zone Filtre, l’affichage change pour afficher uniquement les objets qui contiennent le texte saisi. Seuls des objets actuellement ouverts ou qui ont été ouverts dans la session active s’affichent. La zone Filtre n’effectue aucune recherche complète dans les catalogues, schémas, tables et volumes disponibles pour le notebook.
Pour ouvrir le menu Kebab ![]() , placez le curseur sur le nom de l’objet comme illustré :
, placez le curseur sur le nom de l’objet comme illustré :
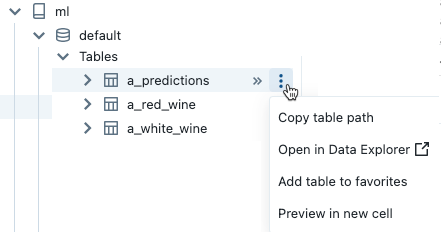
Si l’objet est une table, vous pouvez effectuer les opérations suivantes :
- Créez et exécutez automatiquement une cellule pour afficher un aperçu des données dans la table. Sélectionnez Aperçu dans une nouvelle cellule à partir du menu kebab pour la table.
- Affichez un catalogue, un schéma ou une table dans Catalog Explorer. Sélectionnez Ouvrir dans Catalog Explorer à partir du menu kebab. Un nouvel onglet s’ouvre qui montre l’objet sélectionné.
- Obtenez le chemin d’accès à un catalogue, un schéma ou une table. Sélectionnez Copier … chemin d’accès à partir du menu kebab de l’objet.
- Ajoutez une table à Favoris. Sélectionnez Ajouter aux favoris à partir du menu kebab de la table.
Si l'objet est un catalogue, un schéma ou un volume, vous pouvez copier le chemin de l'objet ou l'ouvrir dans l’Explorateur de catalogues.
Pour insérer un nom de table ou de colonne directement dans une cellule :
- Cliquez sur votre curseur dans la cellule à l’emplacement où vous souhaitez entrer le nom.
- Déplacez votre curseur sur le nom de la table ou de colonne dans le navigateur de schémas.
- Cliquez sur la flèche double
 qui s’affiche à droite du nom de l’objet.
qui s’affiche à droite du nom de l’objet.
Raccourcis clavier
Pour afficher les raccourcis clavier, sélectionnez Aide > Raccourcis clavier. Les raccourcis clavier disponibles varient selon que le curseur se trouve dans une cellule de code (mode édition) ou non (mode commande).
Palette de commandes
Vous pouvez effectuer rapidement des actions dans le notebook en utilisant la palette de commandes. Pour ouvrir un panneau d’actions de notebook, cliquez sur  dans le coin inférieur droit de l’espace de travail ou utilisez le raccourci Cmd + Maj + P sur MacOS ou Ctrl + Maj + P sur Windows.
dans le coin inférieur droit de l’espace de travail ou utilisez le raccourci Cmd + Maj + P sur MacOS ou Ctrl + Maj + P sur Windows.
Rechercher et remplacer du texte
Pour rechercher et remplacer du texte dans un notebook, sélectionnez Modifier > Rechercher et remplacer. La correspondance actuelle est mise en surbrillance en orange et toutes les autres correspondances sont mises en surbrillance en jaune.
Pour remplacer la correspondance actuelle, cliquez sur Remplacer. Pour remplacer toutes les correspondances dans le notebook, cliquez sur Remplacer tout.
Pour vous déplacer entre les correspondances, cliquez sur les boutons Précédent et Suivant. Vous pouvez également appuyer sur Maj + entrée et sur Entrée pour accéder aux correspondances précédentes et suivantes, respectivement.
Pour fermer l’outil rechercher et remplacer, cliquez sur l’![]() ou appuyez sur Échap.
ou appuyez sur Échap.
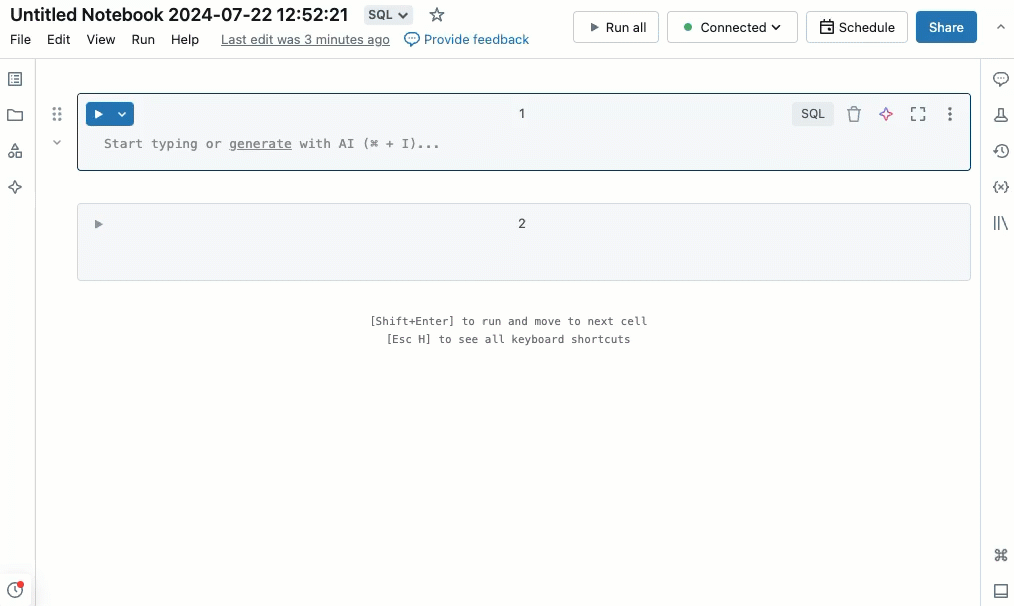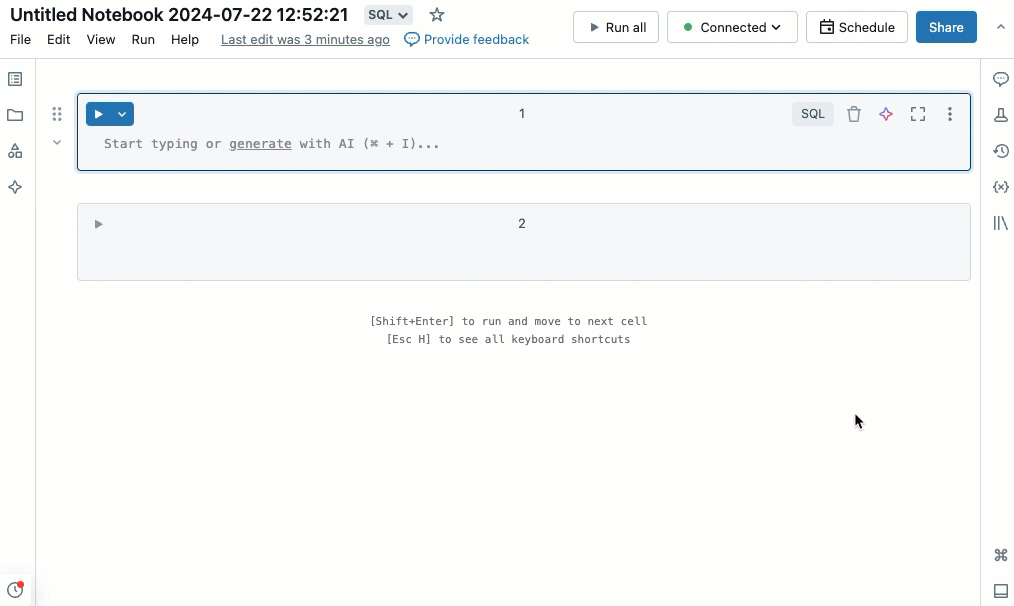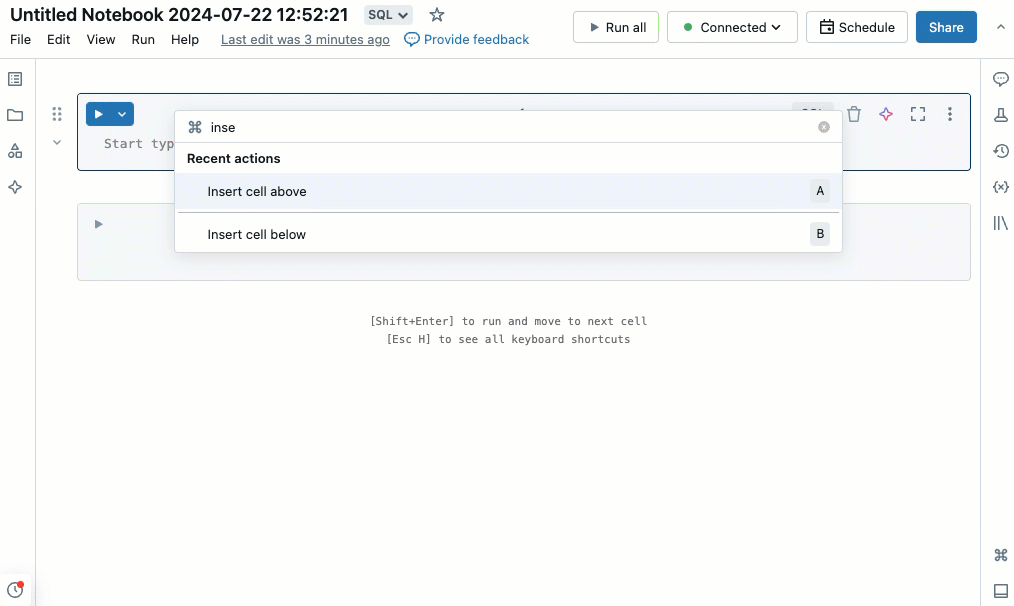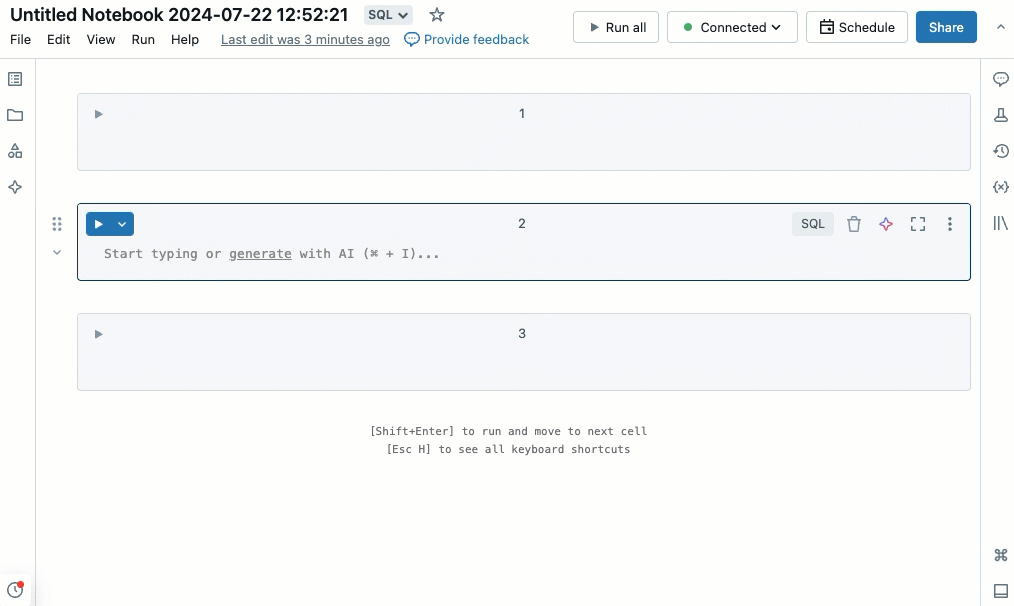
Exécuter les cellules sélectionnées
Vous pouvez exécuter une seule cellule ou une collection de cellules. Pour sélectionner une seule cellule, cliquez n’importe où dans la cellule. Pour sélectionner plusieurs cellules, maintenez la touche Command enfoncée sur MacOS ou la touche Ctrl sur Windows, puis cliquez dans la cellule en dehors de la zone de texte, comme indiqué dans la capture d’écran.
Pour exécuter le comportement sélectionné, le comportement de cette commande dépend du cluster auquel le notebook est attaché.
- Sur un cluster exécutant Databricks Runtime 13.3 LTS ou inférieur, les cellules sélectionnées sont exécutées individuellement. Si une erreur se produit dans une cellule, l’exécution se poursuit avec les cellules suivantes.
- Sur un cluster exécutant Databricks Runtime 14.0 ou ultérieur, ou sur un entrepôt SQL, les cellules sélectionnées sont exécutées en tant que lot. Toute erreur interrompt l’exécution, et vous ne pouvez pas annuler l’exécution de cellules individuelles. Vous pouvez utiliser le bouton Interrompre pour arrêter l’exécution de toutes les cellules.
Modulariser votre code
Important
Cette fonctionnalité est disponible en préversion publique.
Avec Databricks Runtime 11.3 LTS et versions ultérieures, vous pouvez créer et gérer des fichiers de code source dans l’espace de travail Azure Databricks, puis importer ces fichiers dans vos notebooks en fonction des besoins.
Pour plus d’informations sur l’utilisation des fichiers de code source, consultez Partager du code entre des notebooks Databricks et Utiliser des modules Python et R.
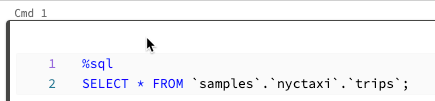
Exécuter le texte sélectionné
Vous pouvez mettre du code ou des instructions SQL en surbrillance dans une cellule de notebook et exécuter uniquement cette sélection. Cela est utile quand vous souhaitez d’effectuer une itération rapidement sur le code et les requêtes.
Mettez en surbrillance les lignes que vous souhaitez exécuter.
Sélectionnez Exécuter > Exécuter le texte sélectionné ou utilisez le raccourci clavier
Ctrl+Shift+Enter. Si aucun texte n’est mis en surbrillance, Exécuter le texte sélectionné exécute la ligne active.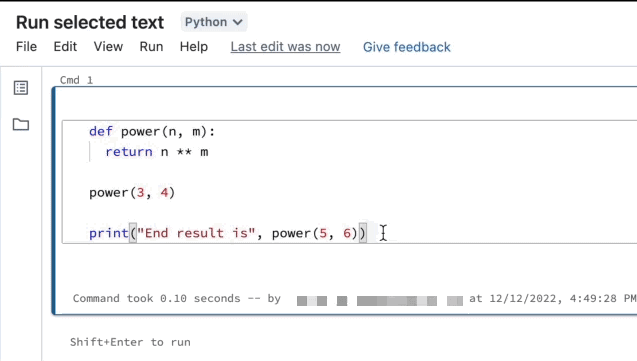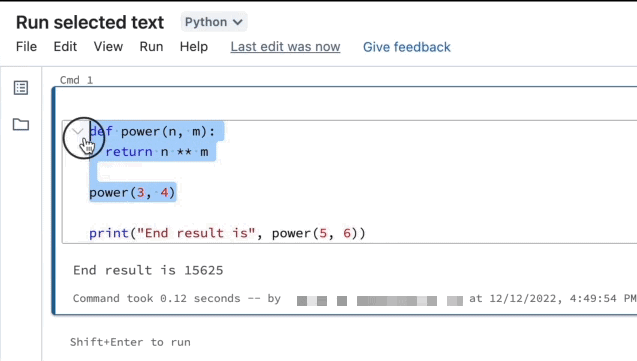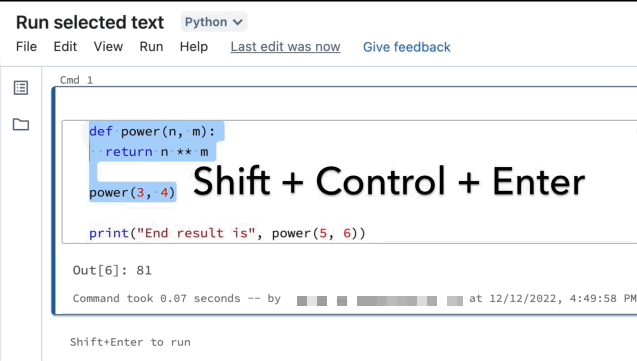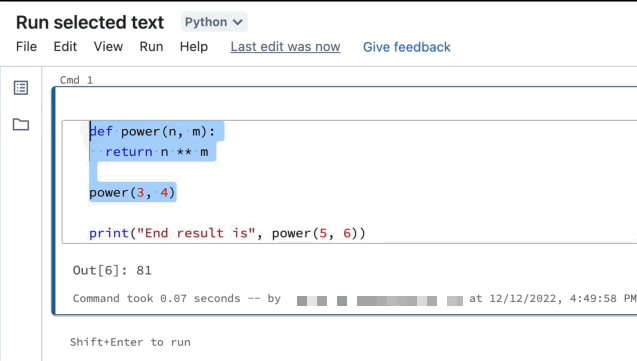
Si vous utilisez plusieurs langages dans une cellule, vous devez inclure la ligne %<language> dans la sélection.
Exécuter le texte sélectionné exécute également le code réduit, si la sélection mise en surbrillance en contient.
Les commandes de cellule spéciales comme %run, %pip et %sh sont prises en charge.
Vous ne pouvez pas utiliser Exécuter le texte sélectionné sur les cellules qui ont plusieurs onglets de sortie (c’est-à-dire les cellules dans lesquelles vous avez défini un profil de données ou une visualisation).
Mettre en forme des cellules de code
Azure Databricks fournit des outils permettant de mettre en forme le code Python et SQL rapidement et facilement dans des cellules de notebook. Ces outils réduisent l’effort de mise en forme de votre code et d’application des mêmes normes de codage dans vos notebooks.
Bibliothèque de formateur noir Python
Important
Cette fonctionnalité est disponible en préversion publique.
Azure Databricks prend en charge la mise en forme du code Python à l’aide de noir dans le notebook. Le notebook doit être attaché à un cluster avec black et des tokenize-rt packages Python installés.
Sur Databricks Runtime 11.3 LTS et versions ultérieures, Azure Databricks préinstalle black et tokenize-rt. Vous pouvez utiliser le formateur directement sans qu’il soit nécessaire d’installer ces bibliothèques.
Sur Databricks Runtime 10.4 LTS et versions ultérieures, vous devez installer black==22.3.0 et tokenize-rt==4.2.1 à partir de PyPI sur votre notebook ou cluster pour utiliser le formateur Python. Vous pouvez exécuter la commande suivante dans votre notebook :
%pip install black==22.3.0 tokenize-rt==4.2.1
ou Installer la bibliothèque sur votre cluster.
Pour plus d’informations sur l’installation des bibliothèques, consultez Gestion de l’environnement Python.
Pour les fichiers et les notebooks dans les dossiers Git de Databricks, vous pouvez configurer le formateur Python en fonction du fichier pyproject.toml. Pour utiliser cette fonctionnalité, créez un fichier pyproject.toml dans le répertoire racine du dossier Git et configurez-le en suivant le format de configuration Black. Modifiez la section [tool.black] dans le fichier. La configuration est appliquée lorsque vous mettez en forme un fichier ou un notebook dans ce dossier Git.
Guide pratique pour mettre en forme des cellules Python et SQL
Vous devez disposer de l’autorisation PEUT MODIFIER sur le notebook pour mettre en forme le code.
Azure Databricks utilise la bibliothèque Gethue/sql-formatter pour mettre en forme SQL et le formateur de code noir pour Python.
Vous pouvez déclencher l’outil de mise en forme des manières suivantes :
Mettre en forme une cellule unique
- Raccourci clavier : appuyez sur Cmd + Maj + F.
- Menu contextuel de commande :
- Mettre en forme la cellule SQL : sélectionnez Mettre en forme le code SQL dans le menu contextuel déroulant de la commande d’une cellule SQL. Cet élément de menu est visible uniquement dans les cellules de notebook SQL ou celles contenant une commande magic de langage
%sql. - Mettre en forme la cellule Python : sélectionnez Mettre en forme les cellules Python dans le menu contextuel déroulant de la commande d’une cellule Python. Cet élément de menu est visible uniquement dans les cellules de notebook Python ou celles contenant une commande magic de langage
%python.
- Mettre en forme la cellule SQL : sélectionnez Mettre en forme le code SQL dans le menu contextuel déroulant de la commande d’une cellule SQL. Cet élément de menu est visible uniquement dans les cellules de notebook SQL ou celles contenant une commande magic de langage
- Menu Modifier le notebook : sélectionnez une cellule Python ou SQL, puis sélectionnez Modifier > Mettre en forme les cellules.
Mettre en forme plusieurs cellules
Sélectionnez plusieurs cellules, puis sélectionnez Modifier > Mettre en forme les cellules. Si vous sélectionnez des cellules de plusieurs langages, seules les cellules SQL et Python sont mises en forme. Il s’agit notamment de celles qui utilisent
%sqlet%python.Mettre en forme toutes les cellules Python et SQL dans le notebook
Sélectionnez Modifier > Mettre en forme le notebook. Si votre notebook contient plusieurs langages, seules les cellules SQL et Python sont mises en forme. Il s’agit notamment de celles qui utilisent
%sqlet%python.
Limitations de la mise en forme du code
- Black applique les normes PEP 8 pour la mise en retrait à 4 espaces. La mise en retrait n’est pas configurable.
- La mise en forme de chaînes Python au sein d’une fonction UDF SQL n’est pas prise en charge. De même, la mise en forme de chaînes SQL au sein d’une fonction UDF Python n’est pas prise en charge.
Historique des versions
Les notebooks Azure Databricks conservent un historique des versions du notebook, ce qui vous permet d’afficher et de restaurer les captures instantanées précédentes du notebook. Vous pouvez effectuer les actions suivantes sur les versions : ajouter des commentaires, restaurer et supprimer des versions et effacer l’historique des versions.
Vous pouvez également synchroniser votre travail dans Databricks avec un référentiel Git distant.
Pour accéder aux versions du notebook, cliquez sur  dans la barre latérale droite. L’historique des versions du notebook s’affiche. Vous pouvez également sélectionner Fichier > Historique des versions.
dans la barre latérale droite. L’historique des versions du notebook s’affiche. Vous pouvez également sélectionner Fichier > Historique des versions.
Ajouter un commentaire
Pour ajouter un commentaire à la version la plus récente :
Cliquez sur la version.
Cliquez sur Enregistrer maintenant.
Dans la boîte de dialogue Enregistrer la version du notebook entrez un commentaire.
Cliquez sur Enregistrer. La version du notebook est enregistrée avec le commentaire saisi.
Restaurer une version
Pour restaurer une version :
Cliquez sur la version.
Cliquez sur Restaurer cette version.
Cliquez sur Confirmer. La révision sélectionnée devient la dernière version du notebook.
Supprimer une version
Pour supprimer une entrée de version :
Cliquez sur la version.
Cliquez sur l’icône de corbeille
 .
.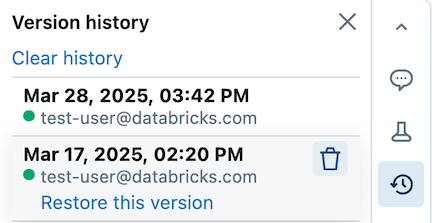
Cliquez sur Oui, effacer. La version sélectionnée est supprimée de l’historique.
Effacer l’historique des versions
L’historique des versions ne peut pas être récupéré une fois qu’il a été effacé.
Pour effacer l’historique des versions d’un notebook :
- Sélectionnez Fichier > Effacer l’historique des versions.
- Cliquez sur Oui, effacer. L’historique de révision du notebook est effacé.
Langages de code dans les notebooks
Configurer la langue par défaut
La langue par défaut du notebook apparaît à côté du nom du notebook.

Pour modifier le langage par défaut, cliquez sur le bouton langage et sélectionnez le nouveau langage dans le menu déroulant. Pour vous assurer que les commandes existantes continuent de fonctionner, les commandes de langage par défaut précédentes sont automatiquement précédées d’une commande magic de langage.
Mélanger les langages
Par défaut, les cellules utilisent le langage par défaut du notebook. Vous pouvez modifier le langage par défaut dans une cellule en cliquant sur le bouton Langage et en sélectionnant un langage dans la liste déroulante.
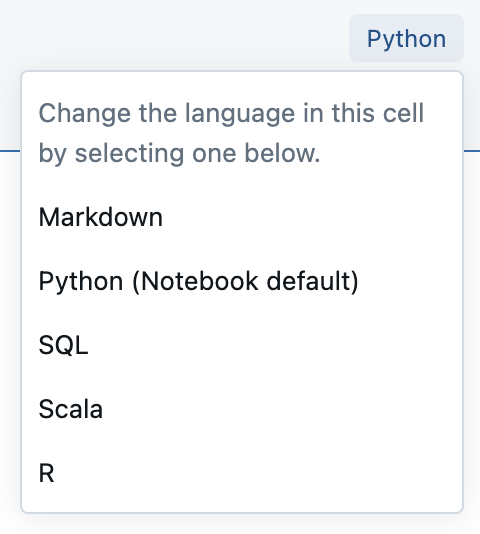
Vous pouvez également utiliser la commande magic de langage %<language> au début d’une cellule. Les commandes magic prises en charge sont les suivantes : %python, %r, %scala et %sql.
Notes
Lorsque vous appelez une commande magic de langage, la commande est distribuée à la REPL dans le contexte d’exécution du notebook. Les variables définies dans un langage (et par conséquent dans la REPL pour ce langage) ne sont pas disponibles dans la REPL d’un autre langage. Les REPLS peuvent partager l’état uniquement via des ressources externes telles que des fichiers dans DBFS ou des objets dans le stockage d’objets.
Les notebooks prennent également en charge quelques commandes magiques auxiliaires :
%sh: vous permet d’exécuter du code Shell dans votre notebook. Pour faire échouer la cellule si la commande de l’interpréteur de commandes a un état de sortie différent de zéro, ajoutez l’option-e. Cette commande s’exécute uniquement sur le pilote Apache Spark, et non sur les threads de travail. Pour exécuter une commande d’interpréteur de commandes sur tous les nœuds, utilisez un script init.%fs: vous permet d’utiliser les commandes du système de fichiersdbutils. Par exemple, pour exécuter la commandedbutils.fs.lspour répertorier les fichiers, vous pouvez spécifier%fs lsà la place. Pour plus d’informations, consultez Travailler avec les fichiers sur Azure Databricks.%md: vous permet d’inclure différents types de documentation, notamment du texte, des images, des formules mathématiques et des équations. Voir la section suivante.
Mise en surbrillance de la syntaxe SQL et autocomplétion dans les commandes Python
La coloration syntaxique et l’autocomplétion SQL sont disponibles lorsque vous utilisez SQL dans une commande Python, comme dans une commande spark.sql.
Explorer les résultats des cellules SQL
Dans un notebook Databricks, les résultats d’une cellule de langage SQL sont automatiquement mis à disposition en tant que DataFrame implicite affecté à la variable _sqldf. Vous pouvez ensuite utiliser cette variable dans toutes les cellules Python et SQL que vous exécutez par la suite, quelle que soit leur position dans le notebook.
Remarque
Cette fonctionnalité présente les limitations suivantes :
- La
_sqldfvariable n’est pas disponible dans les notebooks qui utilisent un entrepôt SQL pour le calcul. - L’utilisation
_sqldfdans les cellules Python suivantes est prise en charge dans Databricks Runtime 13.3 et versions ultérieures. - L’utilisation
_sqldfdans les cellules SQL suivantes n’est prise en charge que sur Databricks Runtime 14.3 et versions ultérieures. - Si la requête utilise les mots clés
CACHE TABLEouUNCACHE TABLEque la_sqldfvariable n’est pas disponible.
La capture d’écran ci-dessous montre comment _sqldf utiliser les cellules Python et SQL suivantes :
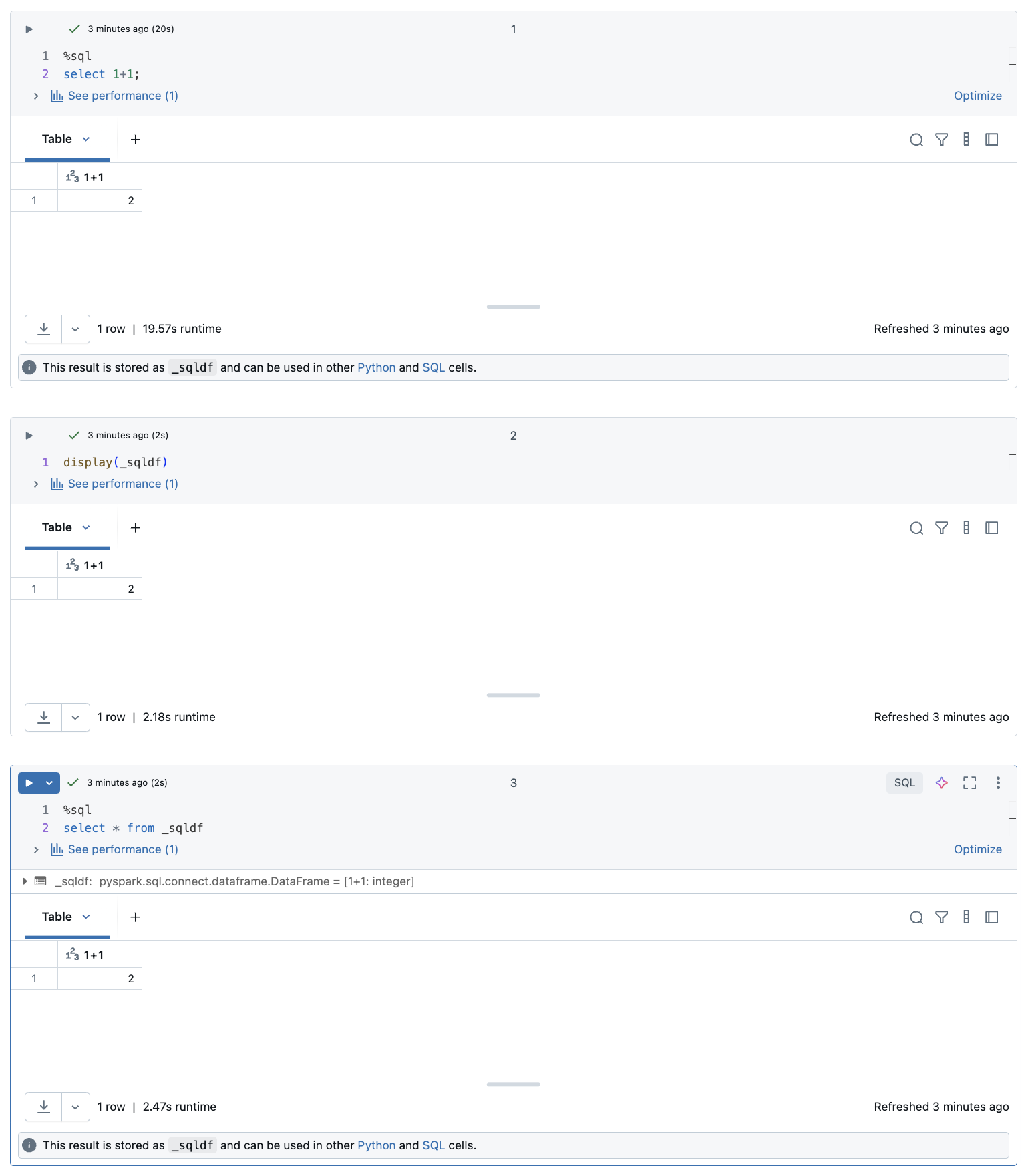
Important
La variable _sqldf est réaffectée chaque fois qu’une cellule SQL est exécutée. Pour éviter de perdre la référence à un résultat dataFrame spécifique, affectez-le à un nouveau nom de variable avant d’exécuter la cellule SQL suivante :
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Exécuter des cellules SQL en parallèle
Lorsqu’une commande est en cours d’exécution et que votre notebook est attaché à un cluster interactif, vous pouvez exécuter une cellule SQL simultanément avec la commande active. La cellule SQL est exécutée dans une nouvelle session parallèle.
Pour exécuter une cellule en parallèle :
Cliquez sur Exécuter maintenant. La cellule est immédiatement exécutée.

Étant donné que la cellule est exécutée dans une nouvelle session, les vues temporaires, les UDF et le DataFrame Python implicite (_sqldf) ne sont pas pris en charge pour les cellules exécutées en parallèle. En outre, les noms de catalogue et de base de données par défaut sont utilisés pendant l’exécution parallèle. Si votre code fait référence à une table dans un autre catalogue ou une autre base de données, vous devez spécifier le nom de la table à l’aide d’un espace de noms à trois niveaux (catalog.schema.table).
Exécuter des cellules SQL sur un entrepôt SQL
Vous pouvez exécuter des commandes SQL dans un notebook Databricks dans un entrepôt SQL, un type de calcul optimisé pour l’analytique SQL. Consultez l’article Utiliser un notebook avec un entrepôt SQL.
Afficher les images
Azure Databricks prend en charge l’affichage d’images dans les cellules Markdown. Vous pouvez afficher des images stockées dans l’espace de travail, les volumes ou le FileStore.
Afficher les images stockées dans l’espace de travail
Vous pouvez utiliser des chemins d’accès absolus ou des chemins d’accès relatifs pour afficher des images stockées dans l’espace de travail. Pour afficher une image stockée dans l’espace de travail, utilisez la syntaxe suivante :
%md


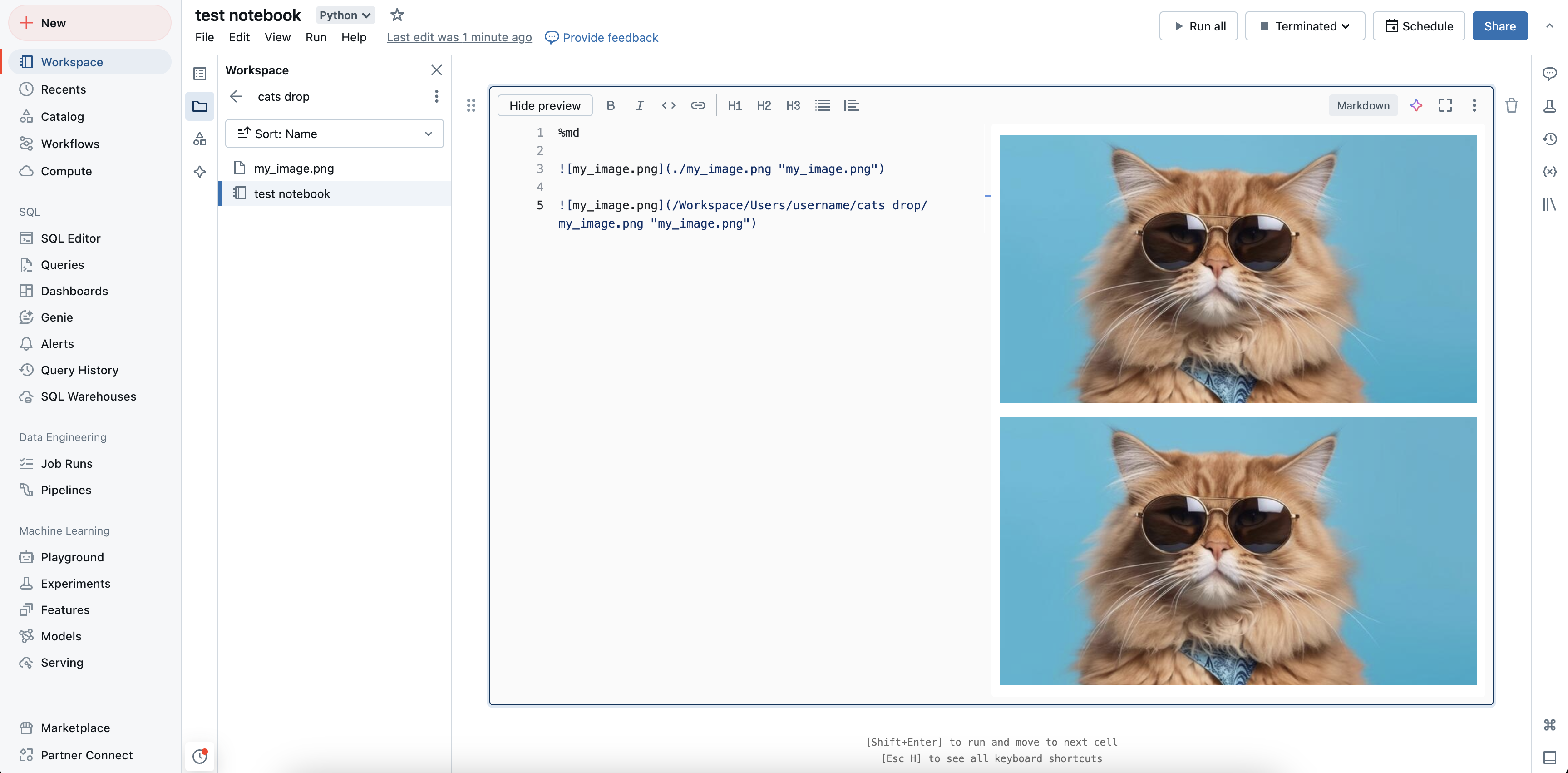
Afficher des images stockées dans des volumes
Vous pouvez utiliser des chemins d’accès absolus pour afficher des images stockées dans des volumes. Pour afficher une image stockée dans les volumes, utilisez la syntaxe suivante :
%md

Afficher les images stockées dans le FileStore
Pour afficher les images stockées dans le FileStore, utilisez la syntaxe suivante :
%md

Supposons, par exemple, que vous disposez du fichier image du logo Databricks dans le FileStore :
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
Lorsque vous incluez le code suivant dans une cellule Markdown :

L’image est rendue dans la cellule :

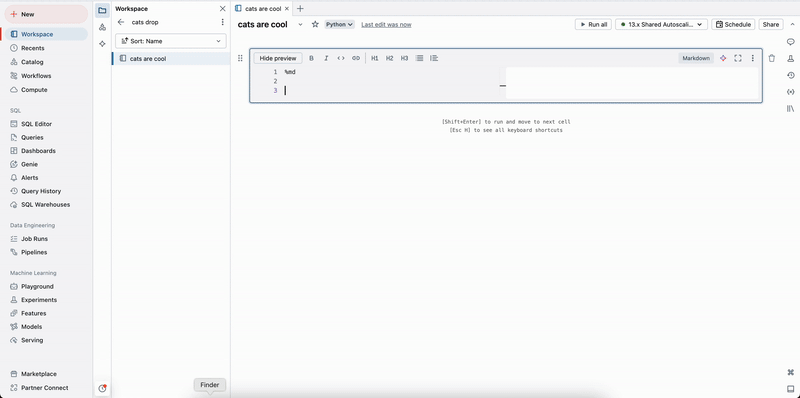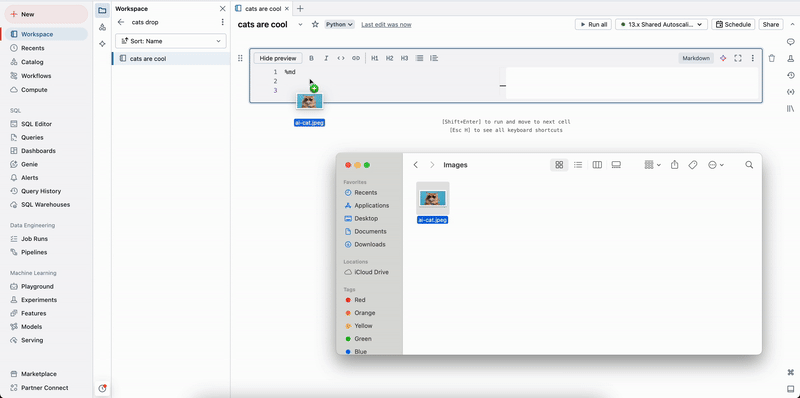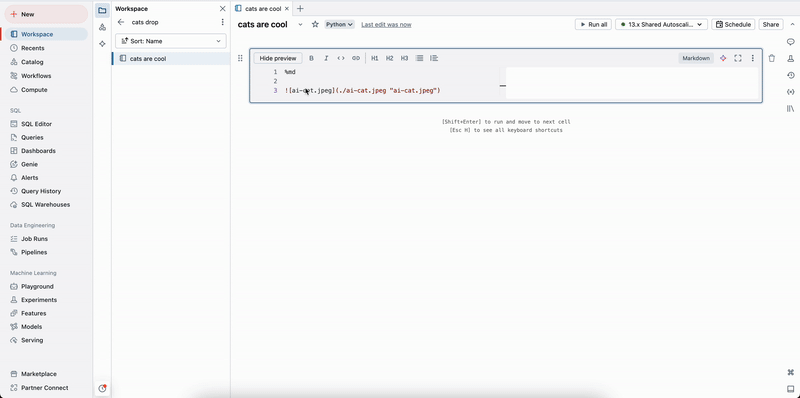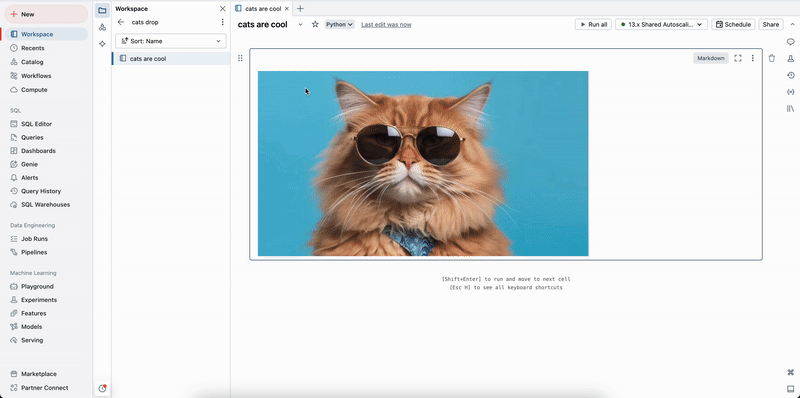
Glisser-déposer des images
Vous pouvez faire glisser et déposer des images de votre système de fichiers local dans des cellules Markdown. L’image est chargée dans l’annuaire de l’espace de travail actif et affichée dans la cellule.
Afficher les équations mathématiques
Les notebooks prennent en charge KaTeX pour l’affichage des formules mathématiques et des équations. Par exemple,
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
devient :
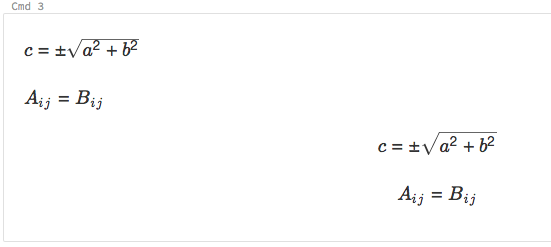
and
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
devient :
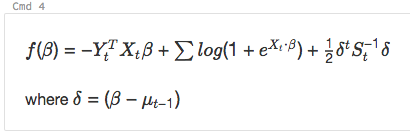
Inclure du code HTML
Vous pouvez inclure du code HTML dans un notebook à l’aide de la fonction displayHTML. Pour obtenir un exemple de la procédure à suivre, consultez HTML, D3 et SVG dans les notebooks.
Notes
L’iframe displayHTML est traité à partir du domaine databricksusercontent.com et le bac à sable (sandbox) de l’iframe comprend l’attribut allow-same-origin. databricksusercontent.com doit être accessible à partir de votre navigateur. S’il est bloqué par votre réseau d’entreprise, il doit être ajouter dans une liste verte.
Lier à d’autres notebooks
Vous pouvez créer un lien vers d’autres notebooks ou dossiers dans des cellules Markdown en utilisant des chemins d’accès relatifs. Spécifiez l’attribut href d’une balise d’ancrage en tant que chemin d’accès relatif, en commençant par un $, puis suivez le même modèle que dans les systèmes de fichiers Unix :
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>