Gérer espaces de stockage direct dans VMM
Cet article fournit une vue d’ensemble de espaces de stockage direct (S2D) et de la façon dont il est déployé dans l’infrastructure System Center - Virtual Machine Manager (VMM).
espaces de stockage direct (S2D) a été introduit dans Windows Server 2016. Il regroupe les lecteurs de stockage physique dans des pools de stockage virtuel pour fournir un stockage virtualisé. Avec le stockage virtualisé, vous pouvez :
- Gérez plusieurs sources de stockage physique en tant qu’entité virtuelle unique.
- Obtenez un stockage peu coûteux, avec et sans périphériques de stockage externes.
- Rassemblez différents types de stockage dans un pool de stockage virtuel unique.
- Provisionnez facilement le stockage et développez le stockage virtualisé à la demande en ajoutant de nouveaux lecteurs.
Remarque
VMM 2019 UR3 et versions ultérieures prend en charge l’infrastructure Hyper Convergd Azure Stack (HCI, version 20H2).
Remarque
VMM 2022 prend en charge l’infrastructure hyperconvergée Azure Stack (HCI, versions 20H2 et 21H2).
Comment cela fonctionne-t-il ?
S2D crée des pools de stockage à partir du stockage attaché à des nœuds spécifiques dans un cluster Windows Server. Le stockage peut être interne sur le nœud ou les périphériques de disque directement attachés à un seul nœud. Les lecteurs de stockage pris en charge incluent NVMe, SSD connecté via SATA ou SAS et HDD. Plus d’informations
- Lorsque vous activez S2D sur un cluster Windows Server, S2D détecte automatiquement le stockage éligible et l’ajoute à un pool de stockage pour le cluster.
- S2D crée également un cache de stockage côté serveur intégré pour optimiser les performances. Les lecteurs les plus rapides sont utilisés pour la mise en cache et les lecteurs restants pour la capacité. En savoir plus sur le cache.
- Vous créez des volumes à partir d’un pool de stockage. La création d’un volume crée le disque virtuel (espace de stockage), les partitions et les met en forme, l’ajoute au cluster et le convertit en volume partagé de cluster (CSV).
- Vous configurez différents niveaux de tolérance de panne pour un volume afin de spécifier la façon dont les disques virtuels sont répartis entre les disques physiques du pool, à l’aide de SMB 3.0. Vous pouvez configurer un volume sans résilience ni avec une résilience miroir ou de parité. Plus d’informations
Déploiement convergé et non convergé
Un cluster exécutant S2D peut être déployé de deux façons :
- Déploiement hyperconvergé : le calcul Hyper-V et le stockage S2D s’exécutent dans le même cluster, sans séparation entre eux. Cela fournit une mise à l’échelle simultanée des ressources de calcul et de stockage.
- Déploiement désagrégé : les ressources de calcul s’exécutent sur un cluster Hyper-V. Le stockage S2D s’exécute sur un autre cluster. Vous mettez à l’échelle les clusters séparément pour une gestion affinée.
Déploiement hyperconvergé
Voici une illustration pour le déploiement hyperconvergé
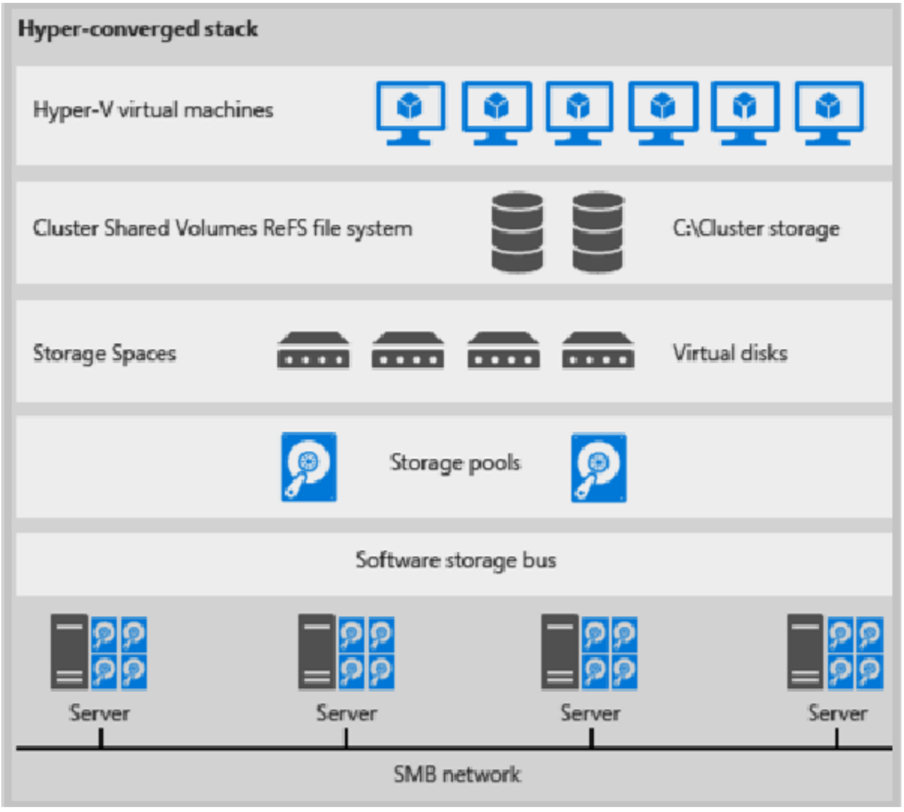
Figure 1 : Déploiement hyperconvergé
- Les fichiers de machine virtuelle sont stockés sur les VMV locaux.
- Les partages de fichiers et SMB ne sont pas utilisés.
- Une fois les volumes CSV S2D disponibles, vous les approvisionnez comme vous le feriez pour tout autre déploiement Hyper-V.
- Vous mettez à l’échelle le cluster de calcul Hyper-V avec son stockage S2D.
Déploiement désagrégé
Voici une illustration du déploiement désagrégé
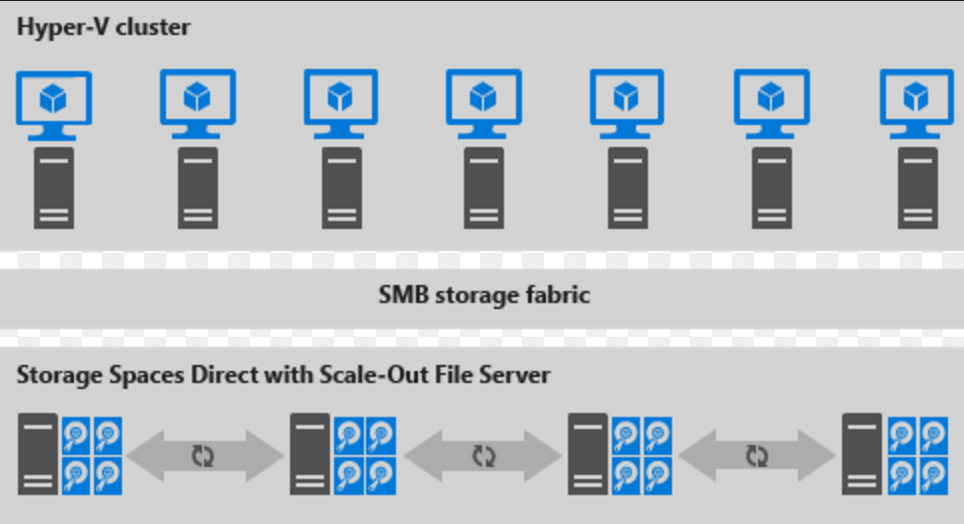
Figure 2 : Déploiement désagrégé
- Les partages de fichiers sont créés sur les CSV S2D.
- Les machines virtuelles Hyper-V sont configurées pour stocker leurs fichiers sur le serveur de fichiers avec montée en puissance parallèle (SOFS) et accessibles à l’aide de SMB 3.0.
- Vous mettez à l’échelle les clusters Hyper-V et SOFS séparément pour une gestion affinée. Par exemple, les nœuds de calcul peuvent être presque pleins pour de nombreuses machines virtuelles, mais les nœuds de stockage peuvent avoir une capacité de disque et d’E/S par seconde excédentaires ; vous ajoutez donc uniquement des nœuds de calcul supplémentaires.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour