Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Cet article explique comment optimiser la gestion de la mémoire de votre cluster Apache Spark pour optimiser les performances sur Azure HDInsight.
Aperçu
Spark fonctionne en plaçant des données en mémoire. La gestion des ressources de mémoire est donc un aspect clé de l’optimisation de l’exécution des travaux Spark. Vous pouvez appliquer plusieurs techniques pour utiliser efficacement la mémoire de votre cluster.
- Privilégiez les partitions de données de petite taille, et prenez en compte la taille, les types et la distribution des données dans votre stratégie de partitionnement.
- Considérez les versions plus récentes, plus efficaces
Kryo data serialization, plutôt que la sérialisation Java par défaut. - Privilégiez l’utilisation de YARN, car il sépare
spark-submiten lot. - Surveillez et affinez les paramètres de configuration de Spark.
Pour référence, la structure de la mémoire Spark et certains des principaux paramètres mémoire de l’exécuteur sont illustrés dans l’image suivante.
Considérations relatives à la mémoire Spark
Si vous utilisez Apache Hadoop YARN, YARN contrôle la mémoire utilisée par tous les conteneurs sur chaque nœud Spark. Le diagramme suivant montre les objets clés et leurs relations.
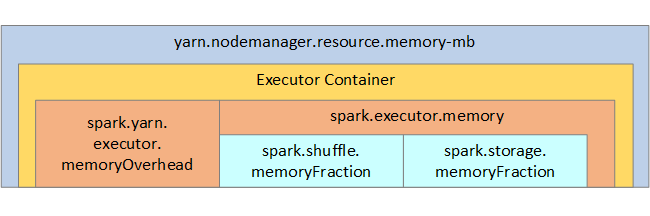
Pour éviter les messages « Mémoire insuffisante », essayez les solutions suivantes :
- Passez en revue les lectures aléatoires de gestion DAG. Réduisez par la réduction côté mappage, prépartitionnez (ou compartimentez) les données sources, optimisez les lectures aléatoires uniques, et réduisez la quantité de données envoyées.
- Il est préférable de choisir
ReduceByKeyavec sa limite de mémoire fixe àGroupByKey, qui fournit des agrégations, des fenêtres et d'autres fonctions, mais possède une limite de mémoire non bornée. - Privilégiez
TreeReduce, qui effectue plus de travail sur les partitions ou les exécuteurs, àReduce, qui effectue tout le travail sur le pilote. - Utilisez des DataFrames plutôt que les objets RDD de niveau inférieur.
- Créez des ComplexTypes qui encapsulent des actions, telles que « N premiers », différentes agrégations ou opérations de fenêtrage.
Pour obtenir des étapes de dépannage supplémentaires, consultez les exceptions OutOfMemoryError pour Apache Spark dans Azure HDInsight.