Démarrage rapide : Reconnaître les intentions avec le service Speech et LUIS
Important
LUIS sera mis hors service le 1er octobre 2025. Depuis le 1er avril 2023, vous ne pouvez pas créer de nouvelles ressources LUIS. Nous vous recommandons de migrer vos applications LUIS vers la compréhension du langage courant pour tirer parti de la prise en charge continue des produits et des fonctionnalités multilingues.
La compréhension du langage courant (CLU) est disponible pour C# et C++ avec le kit de développement logiciel (SDK) Speech version 1.25 ou ultérieure. Consultez le guide de démarrage rapide pour reconnaître les intentions avec le kit de développement logiciel (SDK) Speech et la compréhension du langage courant CLU.
Documentation de référence | Package (NuGet) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous allez utiliser le kit SDK Speech et le service Language Understanding (LUIS) pour reconnaître des intentions dans des données audio capturées à partir d’un microphone. Plus précisément, vous allez utiliser le SDK Speech pour capturer la voix et un domaine prédéfini à partir de LUIS de façon à identifier les intentions à des fins domotiques, comme allumer et éteindre une lumière.
Prérequis
- Abonnement Azure - En créer un gratuitement
- Créez une ressource de langue dans le portail Azure. Vous pouvez utiliser le niveau tarifaire Gratuit (
F0) pour tester le service, puis passer par la suite à un niveau payant pour la production. Vous n’avez pas besoin de ressource Speech cette fois-ci. - Obtenez la clé de langage et la région. Une fois votre ressource de langue déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Créer une application LUIS pour la reconnaissance de l’intention
Pour terminer le démarrage rapide de reconnaissance de l’intention, vous devez créer un compte LUIS et un projet à partir de la préversion du portail LUIS. Ce guide de démarrage rapide nécessite un abonnement LUIS dans une région où la reconnaissance d’intention est disponible. Il n’est pas nécessaire de disposer d’un abonnement au service Speech.
La première chose à faire est de créer un compte et une application LUIS à partir de la préversion du portail LUIS. L’application LUIS que vous créez utilisera un domaine prédéfini pour la domotique, qui fournit des intentions, des entités et des exemples d’énoncés. À la fin du processus, vous disposerez d’un point de terminaison LUIS s’exécutant dans le cloud et que vous pourrez appeler à l’aide du kit SDK Speech.
Pour créer votre application LUIS, suivez ces instructions :
Quand vous aurez terminé, vous aurez besoin de quatre éléments :
- Effectuer une republication avec Préparation vocale activé
- Votre clé primaire LUIS
- Votre localisation LUIS
- Votre ID d’application LUIS
Voici comment vous pouvez trouver ces informations sur la préversion du portail LUI :
À partir du portail LUIS en préversion, sélectionnez votre application, puis sélectionnez le bouton Publier.
Sélectionnez l’emplacement de production. Si vous utilisez
en-US, sélectionnez Modifier les paramètres, puis passez l’option Préparation vocale à la position Activé. Cliquez ensuite sur le bouton Publier.Important
La Préparation vocale est vivement recommandée, car elle améliore la précision de la reconnaissance vocale.
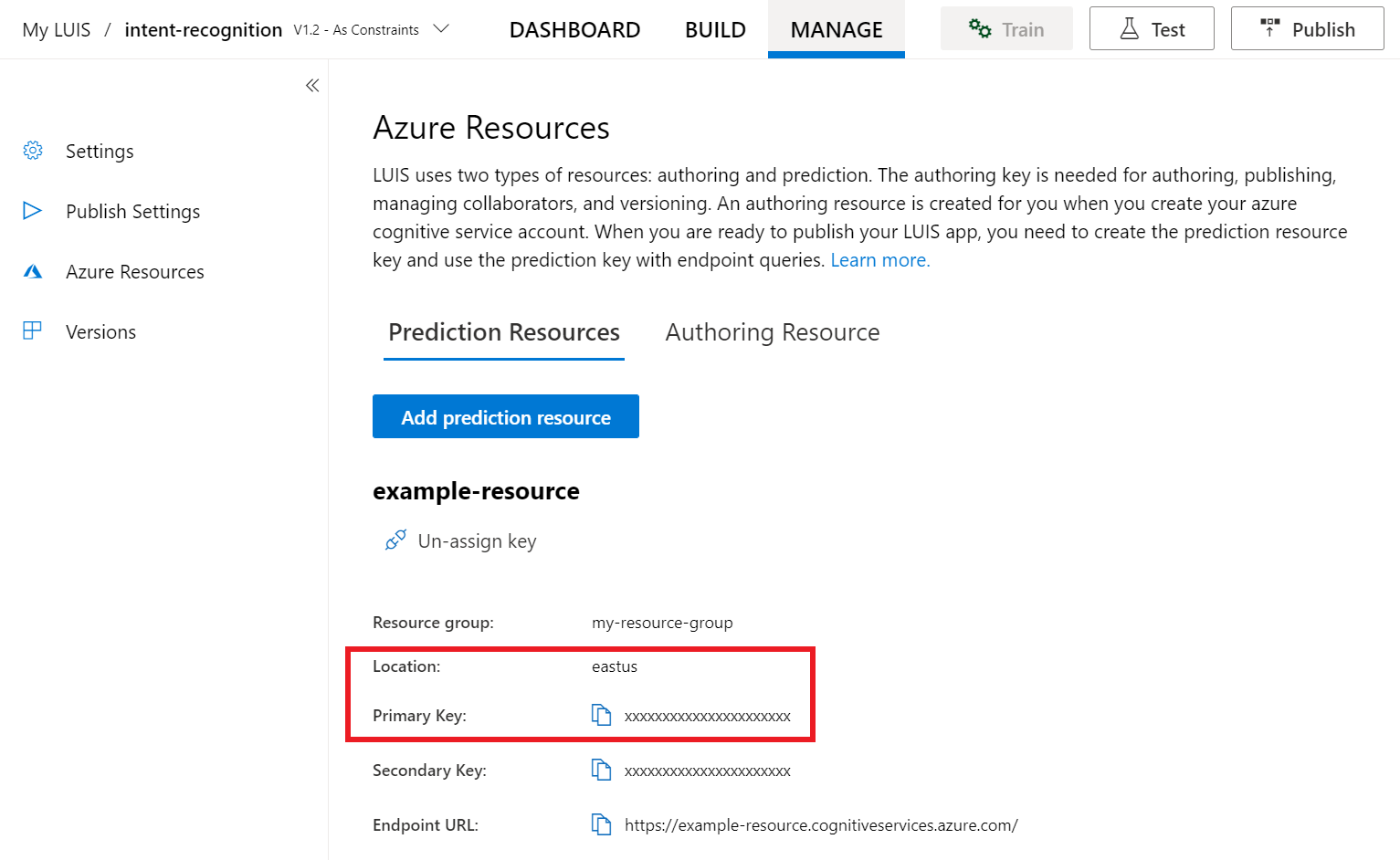
À partir de la préversion du portail LUIS, sélectionnez Manage (Gérer), puis sélectionnez Azure Resources (Ressources Azure). Sur cette page, vous trouverez votre clé LUIS ainsi que le lieu (parfois appelé région) correspondant à votre ressource de prédiction LUIS.
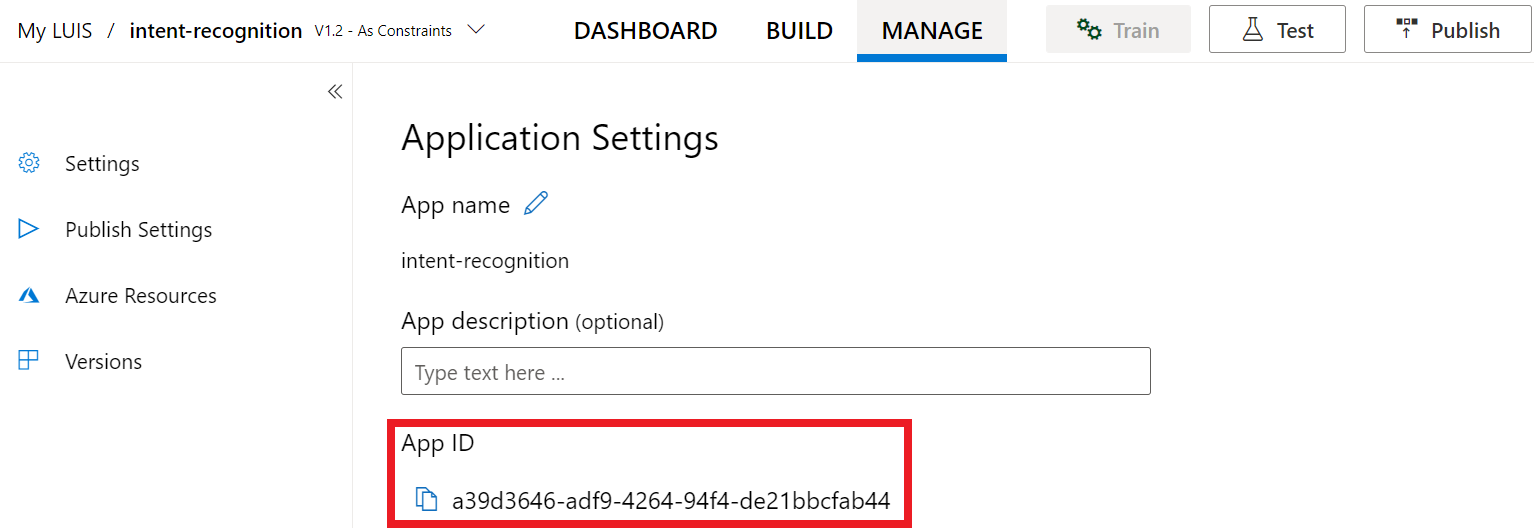
Après vous être procuré la clé et la localisation, vous aurez besoin de l’ID d’application. Sélectionnez Paramètres. L’ID d’application est disponible sur cette page.
Ouvrez votre projet dans Visual Studio.
Ensuite, ouvrez votre projet dans Visual Studio.
- Lancez Visual Studio 2019.
- Chargez votre projet et ouvrez
Program.cs.
Commencer avec du code réutilisable
Nous allons ajouter du code qui servira de squelette à notre projet Notez que vous avez créé une méthode asynchrone appelée RecognizeIntentAsync().
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
Créer une configuration Speech
Pour pouvoir initialiser un objet IntentRecognizer, vous devez au préalable créer une configuration qui utilise la clé et la localisation de votre ressource de prédiction LUIS.
Important
Votre clé de démarrage et vos clés de création ne fonctionneront pas. Vous devez utiliser la clé de prédiction et la localisation que vous avez créés précédemment. Pour plus d’informations, consultez Créer une application LUIS pour la reconnaissance de l’intention.
Insérez ce code dans la méthode RecognizeIntentAsync(). Veillez à mettre à jour ces valeurs :
- Remplacez
"YourLanguageUnderstandingSubscriptionKey"par votre clé de prédiction LUIS. - Remplacez
"YourLanguageUnderstandingServiceRegion"par votre localisation LUIS. Utilisez l’identificateur Région de la région.
Conseil
Si vous avez besoin d’aide pour trouver ces valeurs, consultez Créer une application LUIS pour la reconnaissance de l’intention.
Important
N’oubliez pas de supprimer la clé de votre code une fois que vous avez terminé, et ne la postez jamais publiquement. Pour la production, utilisez un moyen sécurisé de stocker et d’accéder à vos informations d’identification comme Azure Key Vault. Pour plus d’informations, consultez l’article sur la sécurité d’Azure AI services.
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
Cet exemple utilise la méthode FromSubscription() pour générer la SpeechConfig. Pour obtenir la liste complète des méthodes disponibles, consultez la rubrique Classe SpeechConfig.
Le SDK Speech reconnaît par défaut l’utilisation de la langue en-US. Consultez Comment effectuer la reconnaissance vocale pour plus d’informations sur le choix de la langue source.
Initialiser IntentRecognizer
Créons maintenant un IntentRecognizer. Cet objet est créé à l’intérieur d’une instruction using pour garantir la bonne libération des ressources non managées. Insérez ce code dans la méthode RecognizeIntentAsync(), juste en dessous de votre configuration Speech.
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
}
Ajouter un LanguageUnderstandingModel et des intentions
Vous devez associer un LanguageUnderstandingModel au module de reconnaissance de l’intention et ajouter les intentions que vous souhaitez reconnaître. Nous allons utiliser les intentions du domaine prédéfini pour la domotique. Insérez ce code dans l’instruction using de la section précédente. Veillez à remplacer "YourLanguageUnderstandingAppId" par votre ID d’application LUIS.
Conseil
Si vous avez besoin d’aide pour trouver cette valeur, consultez Créer une application LUIS pour la reconnaissance de l’intention.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
Cet exemple utilise la fonction AddIntent() pour ajouter des intentions individuellement. Si vous souhaitez ajouter toutes les intentions d’un modèle, utilisez AddAllIntents(model) et transmettez le modèle.
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode RecognizeOnceAsync(). Cette méthode permet au service Speech de savoir que vous envoyez une seule expression pour reconnaissance, et d’arrêter la reconnaissance une fois que l’expression a été identifiée.
À l’intérieur de l’instruction using, ajoutez ce code sous votre modèle.
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
Afficher les résultats de la reconnaissance (ou les erreurs)
Lorsque le résultat de la reconnaissance est retourné par le service de reconnaissance vocale, vous pouvez effectuer une opération avec celui-ci. Nous allons faire simple et imprimer les résultats dans la console.
À l’intérieur de l’instruction using, sous RecognizeOnceAsync(), ajoutez ce code :
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
Vérifier votre code
À ce stade, votre code doit ressembler à ceci :
Notes
Nous avons ajouté des commentaires à cette version.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default language is "en-us".
// <create_speech_configuration>
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer_1>
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
// </create_intent_recognizer_1>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.AddAllIntents(model);
// <recognize_intent>
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
// </recognize_intent>
// <print_results>
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
// </print_results>
// <create_intent_recognizer_2>
}
// </create_intent_recognizer_2>
// <skeleton_2>
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
// </skeleton_2>
Générer et exécuter votre application
Vous êtes maintenant prêt à créer votre application et à tester la reconnaissance vocale à l’aide du service de reconnaissance vocale.
- Compiler le code : à partir de la barre de menus de Visual Studio, choisissez Générer>Générer la solution.
- Démarrer votre application : dans la barre de menus, choisissez Déboguer>Démarrer le débogage, ou appuyez sur F5.
- Démarrer la reconnaissance : vous êtes invité à prononcer une phrase. Celle-ci est envoyée au service de reconnaissance vocale, transcrite sous forme de texte, puis affichée sur la console.
Documentation de référence | Package (NuGet) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous allez utiliser le kit SDK Speech et le service Language Understanding (LUIS) pour reconnaître des intentions dans des données audio capturées à partir d’un microphone. Plus précisément, vous allez utiliser le SDK Speech pour capturer la voix et un domaine prédéfini à partir de LUIS de façon à identifier les intentions à des fins domotiques, comme allumer et éteindre une lumière.
Prérequis
- Abonnement Azure - En créer un gratuitement
- Créez une ressource de langue dans le portail Azure. Vous pouvez utiliser le niveau tarifaire Gratuit (
F0) pour tester le service, puis passer par la suite à un niveau payant pour la production. Vous n’avez pas besoin de ressource Speech cette fois-ci. - Obtenez la clé de langage et la région. Une fois votre ressource de langue déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Créer une application LUIS pour la reconnaissance de l’intention
Pour terminer le démarrage rapide de reconnaissance de l’intention, vous devez créer un compte LUIS et un projet à partir de la préversion du portail LUIS. Ce guide de démarrage rapide nécessite un abonnement LUIS dans une région où la reconnaissance d’intention est disponible. Il n’est pas nécessaire de disposer d’un abonnement au service Speech.
La première chose à faire est de créer un compte et une application LUIS à partir de la préversion du portail LUIS. L’application LUIS que vous créez utilisera un domaine prédéfini pour la domotique, qui fournit des intentions, des entités et des exemples d’énoncés. À la fin du processus, vous disposerez d’un point de terminaison LUIS s’exécutant dans le cloud et que vous pourrez appeler à l’aide du kit SDK Speech.
Pour créer votre application LUIS, suivez ces instructions :
Quand vous aurez terminé, vous aurez besoin de quatre éléments :
- Effectuer une republication avec Préparation vocale activé
- Votre clé primaire LUIS
- Votre localisation LUIS
- Votre ID d’application LUIS
Voici comment vous pouvez trouver ces informations sur la préversion du portail LUI :
À partir du portail LUIS en préversion, sélectionnez votre application, puis sélectionnez le bouton Publier.
Sélectionnez l’emplacement de production. Si vous utilisez
en-US, sélectionnez Modifier les paramètres, puis passez l’option Préparation vocale à la position Activé. Cliquez ensuite sur le bouton Publier.Important
La Préparation vocale est vivement recommandée, car elle améliore la précision de la reconnaissance vocale.
À partir de la préversion du portail LUIS, sélectionnez Manage (Gérer), puis sélectionnez Azure Resources (Ressources Azure). Sur cette page, vous trouverez votre clé LUIS ainsi que le lieu (parfois appelé région) correspondant à votre ressource de prédiction LUIS.
Après vous être procuré la clé et la localisation, vous aurez besoin de l’ID d’application. Sélectionnez Paramètres. L’ID d’application est disponible sur cette page.
Ouvrez votre projet dans Visual Studio.
Ensuite, ouvrez votre projet dans Visual Studio.
- Lancez Visual Studio 2019.
- Chargez votre projet et ouvrez
helloworld.cpp.
Commencer avec du code réutilisable
Nous allons ajouter du code qui servira de squelette à notre projet Notez que vous avez créé une méthode asynchrone appelée recognizeIntent().
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
Créer une configuration Speech
Pour pouvoir initialiser un objet IntentRecognizer, vous devez au préalable créer une configuration qui utilise la clé et la localisation de votre ressource de prédiction LUIS.
Important
Votre clé de démarrage et vos clés de création ne fonctionneront pas. Vous devez utiliser la clé de prédiction et la localisation que vous avez créés précédemment. Pour plus d’informations, consultez Créer une application LUIS pour la reconnaissance de l’intention.
Insérez ce code dans la méthode recognizeIntent(). Veillez à mettre à jour ces valeurs :
- Remplacez
"YourLanguageUnderstandingSubscriptionKey"par votre clé de prédiction LUIS. - Remplacez
"YourLanguageUnderstandingServiceRegion"par votre localisation LUIS. Utilisez l’identificateur Région de la région.
Conseil
Si vous avez besoin d’aide pour trouver ces valeurs, consultez Créer une application LUIS pour la reconnaissance de l’intention.
Important
N’oubliez pas de supprimer la clé de votre code une fois que vous avez terminé, et ne la postez jamais publiquement. Pour la production, utilisez un moyen sécurisé de stocker et d’accéder à vos informations d’identification comme Azure Key Vault. Pour plus d’informations, consultez l’article sur la sécurité d’Azure AI services.
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
Cet exemple utilise la méthode FromSubscription() pour générer la SpeechConfig. Pour obtenir la liste complète des méthodes disponibles, consultez la rubrique Classe SpeechConfig.
Le SDK Speech reconnaît par défaut l’utilisation de la langue en-US. Consultez Comment effectuer la reconnaissance vocale pour plus d’informations sur le choix de la langue source.
Initialiser IntentRecognizer
Créons maintenant un IntentRecognizer. Insérez ce code dans la méthode recognizeIntent(), juste en dessous de votre configuration Speech.
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
Ajouter un LanguageUnderstandingModel et des intentions
Vous devez associer un LanguageUnderstandingModel au module de reconnaissance de l’intention et ajouter les intentions que vous souhaitez reconnaître. Nous allons utiliser les intentions du domaine prédéfini pour la domotique.
Insérez ce code en dessous de votre IntentRecognizer. Veillez à remplacer "YourLanguageUnderstandingAppId" par votre ID d’application LUIS.
Conseil
Si vous avez besoin d’aide pour trouver cette valeur, consultez Créer une application LUIS pour la reconnaissance de l’intention.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
Cet exemple utilise la fonction AddIntent() pour ajouter des intentions individuellement. Si vous souhaitez ajouter toutes les intentions d’un modèle, utilisez AddAllIntents(model) et transmettez le modèle.
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode RecognizeOnceAsync(). Cette méthode permet au service Speech de savoir que vous envoyez une seule expression pour reconnaissance, et d’arrêter la reconnaissance une fois que l’expression a été identifiée. Pour faire simple, nous attendons la fin des prochains retours.
Insérez ce code en dessous de votre modèle :
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
Afficher les résultats de la reconnaissance (ou les erreurs)
Lorsque le résultat de la reconnaissance est retourné par le service de reconnaissance vocale, vous pouvez effectuer une opération avec celui-ci. Nous allons faire simple et imprimer le résultat dans la console.
Insérez ce code en dessous de auto result = recognizer->RecognizeOnceAsync().get(); :
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
Vérifier votre code
À ce stade, votre code doit ressembler à ceci :
Notes
Nous avons ajouté des commentaires à cette version.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default recognition language is "en-us".
// <create_speech_configuration>
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer>
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
// </create_intent_recognizer>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer->AddAllIntents(model);
// <recognize_intent>
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
// </recognize_intent>
// <print_results>
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
// </print_results>
// <skeleton_2>
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
// </skeleton_2>
Générer et exécuter votre application
Vous êtes maintenant prêt à créer votre application et à tester la reconnaissance vocale à l’aide du service de reconnaissance vocale.
- Compiler le code : à partir de la barre de menus de Visual Studio, choisissez Générer>Générer la solution.
- Démarrer votre application : dans la barre de menus, choisissez Déboguer>Démarrer le débogage, ou appuyez sur F5.
- Démarrer la reconnaissance : vous êtes invité à prononcer une phrase. Celle-ci est envoyée au service de reconnaissance vocale, transcrite sous forme de texte, puis affichée sur la console.
Documentation de référence | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous allez utiliser le kit SDK Speech et le service Language Understanding (LUIS) pour reconnaître des intentions dans des données audio capturées à partir d’un microphone. Plus précisément, vous allez utiliser le SDK Speech pour capturer la voix et un domaine prédéfini à partir de LUIS de façon à identifier les intentions à des fins domotiques, comme allumer et éteindre une lumière.
Prérequis
- Abonnement Azure - En créer un gratuitement
- Créez une ressource de langue dans le portail Azure. Vous pouvez utiliser le niveau tarifaire Gratuit (
F0) pour tester le service, puis passer par la suite à un niveau payant pour la production. Vous n’avez pas besoin de ressource Speech cette fois-ci. - Obtenez la clé de langage et la région. Une fois votre ressource de langue déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Vous devez également installer le SDK Speech pour votre environnement de développement et créer un exemple de projet vide.
Créer une application LUIS pour la reconnaissance de l’intention
Pour terminer le démarrage rapide de reconnaissance de l’intention, vous devez créer un compte LUIS et un projet à partir de la préversion du portail LUIS. Ce guide de démarrage rapide nécessite un abonnement LUIS dans une région où la reconnaissance d’intention est disponible. Il n’est pas nécessaire de disposer d’un abonnement au service Speech.
La première chose à faire est de créer un compte et une application LUIS à partir de la préversion du portail LUIS. L’application LUIS que vous créez utilisera un domaine prédéfini pour la domotique, qui fournit des intentions, des entités et des exemples d’énoncés. À la fin du processus, vous disposerez d’un point de terminaison LUIS s’exécutant dans le cloud et que vous pourrez appeler à l’aide du kit SDK Speech.
Pour créer votre application LUIS, suivez ces instructions :
Quand vous aurez terminé, vous aurez besoin de quatre éléments :
- Effectuer une republication avec Préparation vocale activé
- Votre clé primaire LUIS
- Votre localisation LUIS
- Votre ID d’application LUIS
Voici comment vous pouvez trouver ces informations sur la préversion du portail LUI :
À partir du portail LUIS en préversion, sélectionnez votre application, puis sélectionnez le bouton Publier.
Sélectionnez l’emplacement de production. Si vous utilisez
en-US, sélectionnez Modifier les paramètres, puis passez l’option Préparation vocale à la position Activé. Cliquez ensuite sur le bouton Publier.Important
La Préparation vocale est vivement recommandée, car elle améliore la précision de la reconnaissance vocale.
À partir de la préversion du portail LUIS, sélectionnez Manage (Gérer), puis sélectionnez Azure Resources (Ressources Azure). Sur cette page, vous trouverez votre clé LUIS ainsi que le lieu (parfois appelé région) correspondant à votre ressource de prédiction LUIS.
Après vous être procuré la clé et la localisation, vous aurez besoin de l’ID d’application. Sélectionnez Paramètres. L’ID d’application est disponible sur cette page.
Ouvrir votre projet
- Ouvrez l’IDE de votre choix.
- Chargez votre projet et ouvrez
Main.java.
Commencer avec du code réutilisable
Nous allons ajouter du code qui servira de squelette à notre projet
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
Créer une configuration Speech
Pour pouvoir initialiser un objet IntentRecognizer, vous devez au préalable créer une configuration qui utilise la clé et la localisation de votre ressource de prédiction LUIS.
Insérez ce code dans le bloc try/catch dans main(). Veillez à mettre à jour ces valeurs :
- Remplacez
"YourLanguageUnderstandingSubscriptionKey"par votre clé de prédiction LUIS. - Remplacez
"YourLanguageUnderstandingServiceRegion"par votre localisation LUIS. Utilisez l’identificateur Région de la région.
Conseil
Si vous avez besoin d’aide pour trouver ces valeurs, consultez Créer une application LUIS pour la reconnaissance de l’intention.
Important
N’oubliez pas de supprimer la clé de votre code une fois que vous avez terminé, et ne la postez jamais publiquement. Pour la production, utilisez un moyen sécurisé de stocker et d’accéder à vos informations d’identification comme Azure Key Vault. Pour plus d’informations, consultez l’article sur la sécurité d’Azure AI services.
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
Cet exemple utilise la méthode FromSubscription() pour générer la SpeechConfig. Pour obtenir la liste complète des méthodes disponibles, consultez la rubrique Classe SpeechConfig.
Le SDK Speech reconnaît par défaut l’utilisation de la langue en-US. Consultez Comment effectuer la reconnaissance vocale pour plus d’informations sur le choix de la langue source.
Initialiser IntentRecognizer
Créons maintenant un IntentRecognizer. Insérez ce code juste en dessous de votre configuration Speech.
IntentRecognizer recognizer = new IntentRecognizer(config)) {
Ajouter un LanguageUnderstandingModel et des intentions
Vous devez associer un LanguageUnderstandingModel au module de reconnaissance de l’intention et ajouter les intentions que vous souhaitez reconnaître. Nous allons utiliser les intentions du domaine prédéfini pour la domotique.
Insérez ce code en dessous de votre IntentRecognizer. Veillez à remplacer "YourLanguageUnderstandingAppId" par votre ID d’application LUIS.
Conseil
Si vous avez besoin d’aide pour trouver cette valeur, consultez Créer une application LUIS pour la reconnaissance de l’intention.
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
Cet exemple utilise la fonction addIntent() pour ajouter des intentions individuellement. Si vous souhaitez ajouter toutes les intentions d’un modèle, utilisez addAllIntents(model) et transmettez le modèle.
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode recognizeOnceAsync(). Cette méthode permet au service Speech de savoir que vous envoyez une seule expression pour reconnaissance, et d’arrêter la reconnaissance une fois que l’expression a été identifiée.
Insérez ce code en dessous de votre modèle :
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
Afficher les résultats de la reconnaissance (ou les erreurs)
Lorsque le résultat de la reconnaissance est retourné par le service de reconnaissance vocale, vous pouvez effectuer une opération avec celui-ci. Nous allons faire simple et imprimer le résultat dans la console.
Insérez ce code sous votre appel à recognizeOnceAsync().
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Vérifier votre code
À ce stade, votre code doit ressembler à ceci :
Notes
Nous avons ajouté des commentaires à cette version.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
// </skeleton_1>
// <create_speech_configuration>
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
// </create_speech_configuration>
// <create_intent_recognizer>
IntentRecognizer recognizer = new IntentRecognizer(config)) {
// </create_intent_recognizer>
// <add_intents>
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.addAllIntents(model);
// <recognize_intent>
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
// </recognize_intent>
// <print_result>
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
// </print_result>
// <skeleton_2>
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
// </skeleton_2>
Générer et exécuter votre application
Appuyez sur F11 ou sélectionnez Run (Exécuter)>Debug (Déboguer). Les 15 secondes suivantes de saisie vocale provenant de votre microphone seront reconnues et enregistrées dans la fenêtre console.
Documentation de référence | Package (npm) | Exemples supplémentaires sur GitHub | Code source de la bibliothèque
Dans ce guide de démarrage rapide, vous allez utiliser le kit SDK Speech et le service Language Understanding (LUIS) pour reconnaître des intentions dans des données audio capturées à partir d’un microphone. Plus précisément, vous allez utiliser le SDK Speech pour capturer la voix et un domaine prédéfini à partir de LUIS de façon à identifier les intentions à des fins domotiques, comme allumer et éteindre une lumière.
Prérequis
- Abonnement Azure - En créer un gratuitement
- Créez une ressource de langue dans le portail Azure. Vous pouvez utiliser le niveau tarifaire Gratuit (
F0) pour tester le service, puis passer par la suite à un niveau payant pour la production. Vous n’avez pas besoin de ressource Speech cette fois-ci. - Obtenez la clé de langage et la région. Une fois votre ressource de langue déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Vous devez également installer le SDK Speech pour votre environnement de développement et créer un exemple de projet vide.
Créer une application LUIS pour la reconnaissance de l’intention
Pour terminer le démarrage rapide de reconnaissance de l’intention, vous devez créer un compte LUIS et un projet à partir de la préversion du portail LUIS. Ce guide de démarrage rapide nécessite un abonnement LUIS dans une région où la reconnaissance d’intention est disponible. Il n’est pas nécessaire de disposer d’un abonnement au service Speech.
La première chose à faire est de créer un compte et une application LUIS à partir de la préversion du portail LUIS. L’application LUIS que vous créez utilisera un domaine prédéfini pour la domotique, qui fournit des intentions, des entités et des exemples d’énoncés. À la fin du processus, vous disposerez d’un point de terminaison LUIS s’exécutant dans le cloud et que vous pourrez appeler à l’aide du kit SDK Speech.
Pour créer votre application LUIS, suivez ces instructions :
Quand vous aurez terminé, vous aurez besoin de quatre éléments :
- Effectuer une republication avec Préparation vocale activé
- Votre clé primaire LUIS
- Votre localisation LUIS
- Votre ID d’application LUIS
Voici comment vous pouvez trouver ces informations sur la préversion du portail LUI :
À partir du portail LUIS en préversion, sélectionnez votre application, puis sélectionnez le bouton Publier.
Sélectionnez l’emplacement de production. Si vous utilisez
en-US, sélectionnez Modifier les paramètres, puis passez l’option Préparation vocale à la position Activé. Cliquez ensuite sur le bouton Publier.Important
La Préparation vocale est vivement recommandée, car elle améliore la précision de la reconnaissance vocale.
À partir de la préversion du portail LUIS, sélectionnez Manage (Gérer), puis sélectionnez Azure Resources (Ressources Azure). Sur cette page, vous trouverez votre clé LUIS ainsi que le lieu (parfois appelé région) correspondant à votre ressource de prédiction LUIS.
Après vous être procuré la clé et la localisation, vous aurez besoin de l’ID d’application. Sélectionnez Paramètres. L’ID d’application est disponible sur cette page.
Commencer avec du code réutilisable
Nous allons ajouter du code qui servira de squelette à notre projet
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Azure AI Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
</body>
</html>
Ajouter des éléments d’interface utilisateur
Nous allons maintenant ajouter une interface utilisateur de base pour les zones d’entrée, faire référence au JavaScript du Kit de développement logiciel (SDK) Speech et récupérer un jeton d’autorisation, le cas échéant.
Important
N’oubliez pas de supprimer la clé de votre code une fois que vous avez terminé, et ne la postez jamais publiquement. Pour la production, utilisez un moyen sécurisé de stocker et d’accéder à vos informations d’identification comme Azure Key Vault. Pour plus d’informations, consultez l’article sur la sécurité d’Azure AI services.
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Azure AI Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://learn.microsoft.com/azure/ai-services/speech-service/overview" target="_blank">Subscription</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">Region</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">Application ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>
<script>
// Note: Replace the URL with a valid endpoint to retrieve
// authorization tokens for your subscription.
var authorizationEndpoint = "token.php";
function RequestAuthorizationToken() {
if (authorizationEndpoint) {
var a = new XMLHttpRequest();
a.open("GET", authorizationEndpoint);
a.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
a.send("");
a.onload = function() {
var token = JSON.parse(atob(this.responseText.split(".")[1]));
serviceRegion.value = token.region;
authorizationToken = this.responseText;
subscriptionKey.disabled = true;
subscriptionKey.value = "using authorization token (hit F5 to refresh)";
console.log("Got an authorization token: " + token);
}
}
}
</script>
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key, region, and appId for LUIS services.
var subscriptionKey, serviceRegion, appId;
var authorizationToken;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function") {
RequestAuthorizationToken();
}
}
});
</script>
Créer une configuration Speech
Avant de pouvoir initialiser un objet SpeechRecognizer, vous devez créer une configuration qui utilise votre clé d’abonnement et la région de votre abonnement. Insérez ce code dans la méthode startRecognizeOnceAsyncButton.addEventListener().
Notes
Le SDK Speech reconnaît par défaut l’utilisation de la langue en-US. Consultez Comment effectuer la reconnaissance vocale pour plus d’informations sur le choix de la langue source.
// if we got an authorization token, use the token. Otherwise use the provided subscription key
var speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(authorizationToken, serviceRegion.value);
} else {
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Azure AI Speech subscription key!");
return;
}
startIntentRecognizeAsyncButton.disabled = false;
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
}
speechConfig.speechRecognitionLanguage = "en-US";
Créer une configuration audio
À présent, vous devez créer un objet AudioConfig qui pointe vers votre appareil d’entrée. Insérez ce code dans la méthode startIntentRecognizeAsyncButton.addEventListener(), juste en dessous de votre configuration Speech.
var audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
Initialiser IntentRecognizer
À présent, créons l’objet IntentRecognizer à l’aide des objets SpeechConfig et AudioConfig créés précédemment. Insérez ce code dans la méthode startIntentRecognizeAsyncButton.addEventListener().
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
Ajouter un LanguageUnderstandingModel et des intentions
Vous devez associer un LanguageUnderstandingModel au module de reconnaissance de l’intention et ajouter les intentions que vous souhaitez reconnaître. Nous allons utiliser les intentions du domaine prédéfini pour la domotique.
Insérez ce code en dessous de votre IntentRecognizer. Veillez à remplacer "YourLanguageUnderstandingAppId" par votre ID d’application LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
Notes
Le kit SDK Speech prend en charge les points de terminaison LUIS v2.0 uniquement. Vous devez modifier manuellement l’URL de point de terminaison v3.0 trouvée dans l’exemple de champ de requête pour utiliser un modèle d’URL v2.0. Les points de terminaison LUIS v2.0 suivent toujours l’un de ces deux modèles :
https://{AzureResourceName}.cognitiveservices.azure.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=https://{Region}.api.cognitive.microsoft.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode recognizeOnceAsync(). Cette méthode permet au service Speech de savoir que vous envoyez une seule expression pour reconnaissance, et d’arrêter la reconnaissance une fois que l’expression a été identifiée.
Insérez ce code sous l’ajout du modèle :
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
Vérifier votre code
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Cognitive Services Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="warning">
<h1 style="font-weight:500;">Speech Recognition Speech SDK not found (microsoft.cognitiveservices.speech.sdk.bundle.js missing).</h1>
</div>
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Cognitive Services Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstarts/intent-recognition?pivots=programming-language-csharp#create-a-luis-app-for-intent-recognition" target="_blank">LUIS Primary Key</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">LUIS Location</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">LUIS App ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script src="https://aka.ms/csspeech/jsbrowserpackageraw"></script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key and region for speech services.
var subscriptionKey, serviceRegion, appId;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
let audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Cognitive Services Speech subscription key!");
startIntentRecognizeAsyncButton.disabled = false;
return;
}
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
speechConfig.speechRecognitionLanguage = "en-US";
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
// Set up a Language Understanding Model from Language Understanding Intelligent Service (LUIS).
// See https://www.luis.ai/home for more information on LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
}
});
</script>
</body>
</html>
Créer la source du jeton (facultatif)
Si vous souhaitez héberger la page web sur un serveur web, vous avez la possibilité de fournir une source de jeton pour votre application de démonstration. De cette façon, votre clé d’abonnement ne quitte jamais le serveur et vous permet d’utiliser les fonctionnalités de reconnaissance vocale sans avoir à entrer de code d’autorisation.
Créez un nouveau fichier appelé token.php. Dans cet exemple, nous supposons que votre serveur web prend en charge le langage de script PHP avec curl activé. Entrez le code suivant :
<?php
header('Access-Control-Allow-Origin: ' . $_SERVER['SERVER_NAME']);
// Replace with your own subscription key and service region (e.g., "westus").
$subscriptionKey = 'YourSubscriptionKey';
$region = 'YourServiceRegion';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://' . $region . '.api.cognitive.microsoft.com/sts/v1.0/issueToken');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, '{}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json', 'Ocp-Apim-Subscription-Key: ' . $subscriptionKey));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
echo curl_exec($ch);
?>
Notes
Les jetons d’autorisation ont une durée de vie limitée. Cet exemple simplifié ne montre pas comment actualiser automatiquement les jetons d’autorisation. En tant qu’utilisateur, vous pouvez recharger manuellement la page ou appuyer sur F5 pour l’actualiser.
Générer et exécuter l’exemple localement
Pour lancer l’application, double-cliquez sur le fichier index.html ou ouvrez-le dans votre navigateur web de votre choix. Il présente une interface graphique utilisateur simple qui vous permet d’entrer votre clé LUIS, votre région LUIS et votre ID d’application LUIS. Une fois ces champs renseignés, vous pouvez cliquer sur le bouton approprié pour déclencher une reconnaissance à l’aide du microphone.
Notes
Cette méthode ne fonctionne pas sur le navigateur Safari. Sur Safari, l’exemple de page web doit être hébergé sur un serveur web ; Safari n’autorise pas les sites web chargés depuis un fichier local à utiliser le microphone.
Générer et exécuter l’exemple via un serveur web
Pour lancer l’application, ouvrez le navigateur web de votre choix, accédez à l’URL publique où est hébergé le dossier, entrez votre région LUIS ainsi que votre ID d’application LUIS, puis déclenchez la reconnaissance à l’aide du microphone. Vous obtiendrez un jeton de votre source de jeton, si cette option est configurée, et commencerez à reconnaître les commandes vocales.
Documentation de référence | Package (PyPi) | Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous allez utiliser le kit SDK Speech et le service Language Understanding (LUIS) pour reconnaître des intentions dans des données audio capturées à partir d’un microphone. Plus précisément, vous allez utiliser le SDK Speech pour capturer la voix et un domaine prédéfini à partir de LUIS de façon à identifier les intentions à des fins domotiques, comme allumer et éteindre une lumière.
Prérequis
- Abonnement Azure - En créer un gratuitement
- Créez une ressource de langue dans le portail Azure. Vous pouvez utiliser le niveau tarifaire Gratuit (
F0) pour tester le service, puis passer par la suite à un niveau payant pour la production. Vous n’avez pas besoin de ressource Speech cette fois-ci. - Obtenez la clé de langage et la région. Une fois votre ressource de langue déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés.
Vous devez également installer le SDK Speech pour votre environnement de développement et créer un exemple de projet vide.
Créer une application LUIS pour la reconnaissance de l’intention
Pour terminer le démarrage rapide de reconnaissance de l’intention, vous devez créer un compte LUIS et un projet à partir de la préversion du portail LUIS. Ce guide de démarrage rapide nécessite un abonnement LUIS dans une région où la reconnaissance d’intention est disponible. Il n’est pas nécessaire de disposer d’un abonnement au service Speech.
La première chose à faire est de créer un compte et une application LUIS à partir de la préversion du portail LUIS. L’application LUIS que vous créez utilisera un domaine prédéfini pour la domotique, qui fournit des intentions, des entités et des exemples d’énoncés. À la fin du processus, vous disposerez d’un point de terminaison LUIS s’exécutant dans le cloud et que vous pourrez appeler à l’aide du kit SDK Speech.
Pour créer votre application LUIS, suivez ces instructions :
Quand vous aurez terminé, vous aurez besoin de quatre éléments :
- Effectuer une republication avec Préparation vocale activé
- Votre clé primaire LUIS
- Votre localisation LUIS
- Votre ID d’application LUIS
Voici comment vous pouvez trouver ces informations sur la préversion du portail LUI :
À partir du portail LUIS en préversion, sélectionnez votre application, puis sélectionnez le bouton Publier.
Sélectionnez l’emplacement de production. Si vous utilisez
en-US, sélectionnez Modifier les paramètres, puis passez l’option Préparation vocale à la position Activé. Cliquez ensuite sur le bouton Publier.Important
La Préparation vocale est vivement recommandée, car elle améliore la précision de la reconnaissance vocale.
À partir de la préversion du portail LUIS, sélectionnez Manage (Gérer), puis sélectionnez Azure Resources (Ressources Azure). Sur cette page, vous trouverez votre clé LUIS ainsi que le lieu (parfois appelé région) correspondant à votre ressource de prédiction LUIS.
Après vous être procuré la clé et la localisation, vous aurez besoin de l’ID d’application. Sélectionnez Paramètres. L’ID d’application est disponible sur cette page.
Ouvrir votre projet
- Ouvrez l’IDE de votre choix.
- Créez un projet ainsi qu’un fichier sous le nom
quickstart.py, puis ouvrez-le.
Commencer avec du code réutilisable
Nous allons ajouter du code qui servira de squelette à notre projet
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
Créer une configuration Speech
Pour pouvoir initialiser un objet IntentRecognizer, vous devez au préalable créer une configuration qui utilise la clé et la localisation de votre ressource de prédiction LUIS.
Insérez ce code dans quickstart.py. Veillez à mettre à jour ces valeurs :
- Remplacez
"YourLanguageUnderstandingSubscriptionKey"par votre clé de prédiction LUIS. - Remplacez
"YourLanguageUnderstandingServiceRegion"par votre localisation LUIS. Utilisez l’identificateur Région de la région.
Conseil
Si vous avez besoin d’aide pour trouver ces valeurs, consultez Créer une application LUIS pour la reconnaissance de l’intention.
Important
N’oubliez pas de supprimer la clé de votre code une fois que vous avez terminé, et ne la postez jamais publiquement. Pour la production, utilisez un moyen sécurisé de stocker et d’accéder à vos informations d’identification comme Azure Key Vault. Pour plus d’informations, consultez l’article sur la sécurité d’Azure AI services.
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
Cet exemple construit l’objet SpeechConfig à l’aide de la clé et de la région LUIS. Pour obtenir la liste complète des méthodes disponibles, consultez la rubrique Classe SpeechConfig.
Le SDK Speech reconnaît par défaut l’utilisation de la langue en-US. Consultez Comment effectuer la reconnaissance vocale pour plus d’informations sur le choix de la langue source.
Initialiser IntentRecognizer
Créons maintenant un IntentRecognizer. Insérez ce code juste en dessous de votre configuration Speech.
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
Ajouter un LanguageUnderstandingModel et des intentions
Vous devez associer un LanguageUnderstandingModel au module de reconnaissance de l’intention et ajouter les intentions que vous souhaitez reconnaître. Nous allons utiliser les intentions du domaine prédéfini pour la domotique.
Insérez ce code en dessous de votre IntentRecognizer. Veillez à remplacer "YourLanguageUnderstandingAppId" par votre ID d’application LUIS.
Conseil
Si vous avez besoin d’aide pour trouver cette valeur, consultez Créer une application LUIS pour la reconnaissance de l’intention.
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
Cet exemple utilise la fonction add_intents() pour ajouter une liste d’intentions définies explicitement. Si vous souhaitez ajouter toutes les intentions d’un modèle, utilisez add_all_intents(model) et transmettez le modèle.
Reconnaître une intention
À partir de l’objet IntentRecognizer, vous devez appeler la méthode recognize_once(). Cette méthode permet au service Speech de savoir que vous envoyez une seule expression pour reconnaissance, et d’arrêter la reconnaissance une fois que l’expression a été identifiée.
Insérez ce code sous votre modèle.
intent_result = intent_recognizer.recognize_once()
Afficher les résultats de la reconnaissance (ou les erreurs)
Lorsque le résultat de la reconnaissance est retourné par le service de reconnaissance vocale, vous pouvez effectuer une opération avec celui-ci. Nous allons faire simple et imprimer le résultat dans la console.
Sous votre appel à recognize_once(), ajoutez ce code.
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
Vérifier votre code
À ce stade, votre code doit ressembler à ceci.
Notes
Nous avons ajouté des commentaires à cette version.
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
# <skeleton>
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
# </skeleton>
"""performs one-shot intent recognition from input from the default microphone"""
# <create_speech_configuration>
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
# </create_speech_configuration>
# <create_intent_recognizer>
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
# </create_intent_recognizer>
# <add_intents>
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
# </add_intents>
# To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
# intent_recognizer.add_all_intents(model)
# Starts intent recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of about 30
# seconds of audio is processed. It returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
# <recognize_intent>
intent_result = intent_recognizer.recognize_once()
# </recognize_intent>
# <print_results>
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
# </print_results>
Générer et exécuter votre application
Exécutez l’exemple à partir de la console ou dans votre IDE :
python quickstart.py
Les 15 secondes suivantes de saisie vocale provenant de votre microphone seront reconnues et enregistrées dans la fenêtre console.
Documentation de référence | Package (Go) | Exemples supplémentaires sur GitHub
Le SDK Speech pour Go ne prend pas en charge la reconnaissance des intentions. Sélectionnez un autre langage de programmation, ou la référence Go et des exemples liés au début de cet article.
Documentation de référence | Package (téléchargement) | Exemples supplémentaires sur GitHub
Le SDK Speech pour Objective-C prend en charge la reconnaissance de l’intention, mais nous n’avons pas encore inclus de guide ici. Sélectionnez un autre langage de programmation pour commencer et découvrir les concepts, ou consultez les informations de référence sur Objective-C et les exemples liés au début de cet article.
Documentation de référence | Package (téléchargement) | Exemples supplémentaires sur GitHub
Le SDK Speech pour Swift prend en charge la reconnaissance de l’intention, mais nous n’avons pas encore inclus de guide ici. Sélectionnez un autre langage de programmation pour commencer et découvrir les concepts, ou consultez les informations de référence sur Swift et les exemples liés au début de cet article.
Informations de référence sur l’API REST Reconnaissance vocale | Informations de référence sur l’API REST Reconnaissance vocale pour l’audio court | Exemples supplémentaires sur GitHub
Vous pouvez utiliser l’API REST pour la reconnaissance de l’intention, mais nous n’avons pas encore inclus de guide ici. Sélectionnez un autre langage de programmation pour commencer et découvrir les concepts.
L’interface de ligne de commande (CLI) Speech prend en charge la reconnaissance de l’intention, mais nous n’avons pas encore inclus de guide ici. Sélectionnez un autre langage de programmation pour commencer et découvrir les concepts, ou consultez Vue d’ensemble de l’interface CLI Speech pour plus d’informations sur l’interface CLI.