Le modèle CQRS (Command and Query Responsibility Segregation) de séparation des responsabilités en matière de commande et de requête sépare les opérations de lecture et de mise à jour pour un magasin de données. L’implémentation de CQRS dans votre application peut optimiser ses performances, son évolutivité et sa sécurité. La flexibilité accordée par la migration vers CQRS permet d’améliorer les capacités d’évolution d’un système au fil du temps et empêche les commandes de mise à jour de provoquer des conflits de fusion au niveau du domaine.
Contexte et problème
Dans les architectures traditionnelles, le même modèle de données est utilisé pour interroger et mettre à jour une base de données. Cette approche se révèle simple et efficace pour les opérations CRUD de base. Toutefois, dans le cas des applications plus complexes, elle peut devenir plus difficile à gérer. Par exemple, côté lecture, l’application peut exécuter de nombreuses requêtes, renvoyant des objets de transfert de données de différentes formes. Le mappage d’objets peut alors devenir compliqué. Côté écriture, le modèle peut implémenter une logique métier et de validation complexe. Par conséquent, vous risquez d’obtenir un modèle excessivement complexe et surchargé.
Les charges de travail de lecture et d’écriture sont souvent asymétriques et présentent des exigences de performances et de mise à l’échelle très différentes.
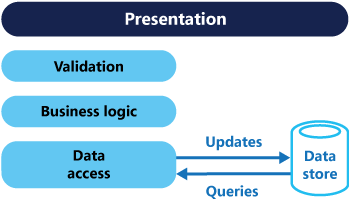
Il existe souvent une incompatibilité entre les représentations d’écriture et de lecture des données, telles que des colonnes ou propriétés supplémentaires qui doivent être mises à jour correctement même si elles ne sont pas requises dans le cadre d’une opération.
L’exécution en parallèle d’opérations sur un même jeu de données peut produire une contention de données.
L’approche traditionnelle peut avoir des conséquences négatives sur les performances en raison de la charge sur la couche d’accès aux données et le magasin de données, et la complexité des requêtes nécessaire pour récupérer des informations.
La gestion de la sécurité et des autorisations risque de se complexifier, car chaque entité est soumise à des opérations de lecture et d’écriture qui peuvent exposer des données dans le mauvais contexte.
Solution
La CQRS sépare les lectures et les écritures en différents modèles et utilise des commandes pour mettre à jour les données, et des requêtes pour lire les données.
- Les commandes doivent être basées sur des tâches au lieu d’être centrées sur les données. (« Réservation d’une chambre d’hôtel », et non pas « définir le paramètre Statut de réservation sur Réservée »). Cela peut nécessiter des modifications correspondantes au style d’interaction utilisateur. L’autre partie consiste à examiner la modification de la logique métier qui traite ces commandes pour qu’elles réussissent plus fréquemment. Une technique qui prend en charge ce procédé consiste à exécuter certaines règles de validation sur le client même avant d’envoyer la commande, éventuellement en désactivant les boutons, en expliquant pourquoi sur l’interface utilisateur (« aucune salle restante »). De cette façon, la cause des défaillances de commande côté serveur peut être réduite aux conditions de concurrence (deux utilisateurs essayant de réserver la dernière salle), et même celles-ci peuvent parfois être traitées avec plus de données et de logique (inscrire un invité sur une liste d’attente).
- Les commandes peuvent être placées dans une file d’attente pour faire l’objet d’un traitement asynchrone, au lieu d’être traitées de manière synchrone.
- Les requêtes ne modifient jamais la base de données. Une requête renvoie un objet de transfert de données qui n’encapsule aucune connaissance du domaine.
Les modèles peuvent ensuite être isolés, comme indiqué dans le schéma suivant, même si cela n’est pas une exigence absolue.
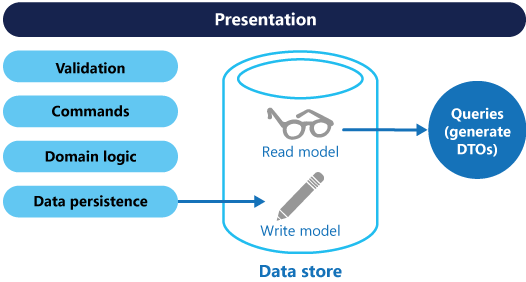
Le fait de disposer de modèles de requête et de mise à jour distincts simplifie la conception et l’implémentation. Toutefois, un inconvénient est que le code CQRS ne peut pas être généré automatiquement à partir d’un schéma de la base de données en utilisant des mécanismes de génération de modèles automatique tels que les outils O/RM (vous pourrez néanmoins créer votre personnalisation en plus du code généré).
Pour renforcer l’isolation, vous pouvez séparer physiquement les données de lecture des données d’écriture. Dans ce cas, la base de données de lecture peut utiliser son propre schéma de données optimisé pour les requêtes. Par exemple, elle peut stocker une vue matérialisée des données, afin d’éviter des jointures ou des mappages O/RM complexes. Elle peut même utiliser un autre type de magasin de données. Par exemple, il est possible que la base de données d’écriture soit relationnelle, et que la base de données de lecture soit une base de données de documents.
Si vous utilisez des bases de données de lecture et d’écriture distinctes, vous devez les garder synchronisées. En règle générale, vous obtenez ce résultat en faisant en sorte que le modèle d’écriture publie un événement chaque fois qu’il met à jour la base de données. Pour plus d’informations sur l’utilisation d’événements, consultez Style d’architecture basée sur les événements. Étant donné que les répartiteurs de messages et les bases de données ne peuvent généralement pas être inscrits dans une seule transaction distribuée, il peut s’avérer difficile de garantir la cohérence lors de la mise à jour de la base de données et de la publication des événements. Pour plus d’informations, consultez les conseils sur le traitement des messages idempotents.
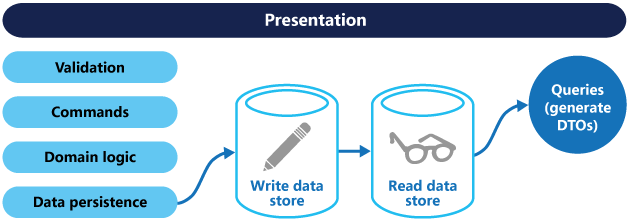
Le magasin de lecture peut être un réplica en lecture seule du magasin d’écriture, ou les magasins de lecture et d’écriture peuvent avoir une structure complètement différente. Utiliser plusieurs réplicas en lecture seule peut améliorer les performances des requêtes, en particulier dans les scénarios distribués où les réplicas en lecture seule se trouvent à proximité des instances d’application.
La séparation des magasins de lecture et d’écriture permet également de les mettre à l’échelle de façon individuelle en fonction de la charge. Par exemple, les magasins de lecture sont généralement confrontés à une charge plus importante que les magasins d’écriture.
Certaines implémentations de l’architecture CQRS utilisent le modèle d’approvisionnement en événements (ou Event Sourcing). Avec ce modèle, l’état de l’application est stocké sous la forme d’une séquence d’événements. Chaque événement représente un ensemble de modifications des données. L’état actuel est construit par la relecture des événements. Dans un contexte CQRS, l’un des avantages de l’approvisionnement en événements réside dans le fait que les mêmes événements peuvent être utilisés pour informer les autres composants, en particulier, pour avertir le modèle de lecture. Le modèle de lecture utilise les événements pour créer une capture instantanée de l’état actuel, ce qui se révèle plus efficace pour les requêtes. Toutefois, l’approvisionnement en événements complique la conception.
Voici quelques avantages de la CQRS :
- Mise à l’échelle indépendante. CQRS permet de mettre à l’échelle les charges de travail de lecture et d’écriture indépendamment, et peut contribuer à réduire les contentions de verrouillage.
- Schémas de données optimisés. Le côté lecture peut utiliser un schéma optimisé pour les requêtes, tandis que le côté écriture utilise un schéma optimisé pour les mises à jour.
- Sécurité. Il est plus facile de s’assurer que seules les entités de domaine adéquates effectuent des écritures sur les données.
- Séparation des problèmes. Le fait de séparer le côté lecture du côté écriture peut produire des modèles plus faciles à gérer et plus flexibles. La plus grande partie de la logique métier complexe est placée dans le modèle d’écriture. Le modèle de lecture peut être relativement simple.
- Requêtes simplifiées. En stockant une vue matérialisée dans la base de données de lecture, l’application peut éviter les jointures complexes lors de l’interrogation.
Considérations et problèmes d’implémentation
Voici quelques-uns des défis liés à l’implémentation de ce modèle :
Complexité : Le principe de base de CQRS est simple. Toutefois, cette architecture peut compliquer la conception d’applications, notamment si elle inclut le modèle d’approvisionnement en événements.
Messagerie. Bien que CQRS ne nécessite aucune messagerie, il est fréquent d’utiliser une messagerie pour traiter les commandes et pour publier les événements de mise à jour. Dans ce cas, l’application doit gérer les échecs de messages ou les messages en double. Consultez les conseils sur les files d’attente de priorité pour gérer les commandes ayant des priorités différentes.
Cohérence finale. Si vous séparez les bases de données de lecture et d’écriture, les données de lecture peuvent être périmées. Le magasin de modèle de lecture peut être mis à jour pour refléter les modifications du magasin de modèle d’écriture, et il peut être difficile de détecter le moment où un utilisateur a émis une requête basée sur des données de lecture périmées.
Quand utiliser le modèle CQRS
Nous vous conseillons d’utiliser la CQRS pour les scénarios suivants :
Dans les domaines de collaboration où de nombreux utilisateurs accèdent aux mêmes données en parallèle. La CQRS vous permet de définir des commandes avec suffisamment de granularité pour réduire les conflits de fusion au niveau du domaine (tous les conflits qui surviennent peuvent être fusionnés par la commande).
Les interfaces utilisateur basées sur les tâches où les utilisateurs sont guidés tout au long d’un processus complexe comme une série d’étapes ou avec des modèles de domaine complexes. Le modèle d’écriture a une pile de traitement de commandes complète avec une logique métier, une validation d’entrée et une validation métier. Le modèle d’écriture peut traiter un ensemble d’objets associés comme une unité unique pour les modifications de données (un agrégat, dans la terminologie DDD) et s’assurer que ces objets sont toujours dans un état cohérent. Le modèle de lecture n’a aucune pile de validation ou de logique métier et renvoie simplement un DTO pour une utilisation dans un modèle de vue. Le modèle de lecture est cohérent de manière éventuelle avec le modèle d’écriture.
Scénarios où les performances des lectures de données doivent être ajustées séparément des performances des écritures de données, en particulier lorsque le nombre de lectures est bien supérieur au nombre d’écritures. Dans ce scénario, vous pouvez faire évoluer le modèle de lecture, mais seulement exécuter le modèle d’écriture sur quelques instances. Un petit nombre d’instances de modèle d’écriture permet également de réduire la fréquence des conflits de fusion.
Les scénarios dans lesquels une équipe de développeurs peut se concentrer sur le modèle de domaine complexe appartenant au modèle d’écriture et dans lesquels une autre équipe peut se concentrer sur le modèle de lecture et les interfaces utilisateur.
Les scénarios dans lesquels le système doit évoluer au fil du temps et peut contenir plusieurs versions du modèle, ou dans lesquels les règles d’entreprise changent régulièrement.
L’intégration à d’autres systèmes, surtout en association avec l’approvisionnement en événements, où l’échec temporal d’un sous-système ne doit pas affecter la disponibilité des autres.
Ce modèle n’est pas recommandé quand :
Le domaine ou les règles d’entreprise sont simples.
Une interface utilisateur simple de style CRUD et les opérations d’accès aux données sont suffisantes.
Envisagez d’appliquer l’approche CQRS à des sections limitées de votre système, là où elle sera le plus utile.
Conception de la charge de travail
Un architecte doit évaluer la façon dont le modèle CQRS peut être utilisé dans la conception de leurs charges de travail pour se conformer aux objectifs et principes abordés dans les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | La séparation des opérations de lecture et d’écriture dans des charges de travail en lecture-écriture intensives permet d’optimiser les performances et la mise à l’échelle ciblées pour l’objectif spécifique de chaque opération. - PE :05 Mise à l’échelle et partitionnement - PE :08 Performance des données |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Approvisionnement en événements et modèle CQRS
Le modèle CQRS est souvent utilisé avec le modèle d’approvisionnement en événements. Les systèmes basés sur le modèle CQRS utilisent des modèles de données de lecture et d’écriture séparés, tous adaptés aux tâches appropriées et souvent situés dans des magasins distincts physiquement. Quand il est utilisé avec le Modèle d’approvisionnement en événements, le magasin d’événements est le modèle d’écriture ainsi que la source officielle d’informations. Le modèle de lecture d’un système basé sur le modèle CQRS fournit des vues matérialisées des données, généralement sous forme de vues extrêmement dénormalisées. Ces vues sont personnalisées en fonction des interfaces et affichent les exigences de l’application, ce qui permet d’optimiser les performances de requête et d’affichage.
L’utilisation du flux d’événements en tant que magasin d’écriture au lieu de données réelles à un point dans le temps évite les conflits de mise à jour d’un agrégat unique et optimise les performances et l’extensibilité. Les événements peuvent être utilisés pour générer de façon asynchrone des vues matérialisées des données qui servent à remplir le magasin de lecture.
Étant donné que le magasin d’événements est la source officielle d’informations, il est possible de supprimer les vues matérialisées et de réexécuter tous les événements passés pour créer une représentation de l’état actuel lorsque le système évolue ou lorsque le modèle de lecture doit changer. Les vues matérialisées sont en effet un cache durable en lecture seule des données.
Lorsque vous utilisez CQRS avec le modèle d’approvisionnement en événements, réfléchissez aux points suivants :
Comme avec n’importe quel système dans lequel les magasins d’écriture et de lecture sont séparés, les systèmes basés sur ce modèle ne sont plus cohérents de manière éventuelle. Il y aura un certain délai entre l’événement généré et le magasin de données mis à jour.
Le modèle ajoute un certain degré de complexité, car le code doit être créé pour initier et traiter des événements, ainsi que pour assembler ou mettre à jour les vues ou objets appropriés nécessaires par requêtes ou un modèle de lecture. La complexité du modèle CQRS lorsqu’il est utilisé avec le modèle d’approvisionnement en événements peut compliquer une implémentation réussie et nécessite une approche différente pour la conception des systèmes. Toutefois, l’approvisionnement en événements peut faciliter la modélisation du domaine et la régénération des vues ou leur création, car la nature des modifications des données est préservée.
Générer des vues matérialisées à utiliser dans le modèle de lecture ou les projections des données en réexécutant et en traitant les événements d’entités spécifiques ou de collections d’entités peut nécessiter une utilisation des ressources et un temps de traitement importants. Cela est particulièrement vrai si des valeurs d’une longue période doivent être analysées ou additionnées, car tous les événements associés doivent être examinés. Corrigez ce problème en implémentant des captures instantanées des données à des intervalles planifiés, comme un compteur indiquant le nombre total d’occurrences d’une action spécifique ou l’état actuel d’une entité.
Exemple de modèle CQRS
Le code suivant présente certains extraits d’un exemple d’implémentation CQRS qui utilise diverses définitions pour les modèles de lecture et d’écriture. Les interfaces du modèle n’imposent pas de fonctionnalités des magasins de données sous-jacents ; elles peuvent également évoluer et être ajustées de façon indépendante car elles sont séparées.
Le code suivant montre la définition du modèle de lecture.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
Le système permet aux utilisateurs d’évaluer des produits. Le code d’application effectue cette opération à l’aide de la commande RateProduct indiquée dans le code suivant.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
Le système utilise la classe ProductsCommandHandler pour gérer les commandes envoyées par l’application. En règle générale, les clients envoient des commandes au domaine via un système de messagerie comme une file d’attente. Le gestionnaire de commandes accepte ces commandes et appelle les méthodes de l’interface du domaine. La granularité de chaque commande est conçue pour réduire le risque de requêtes en conflit. Le code suivant montre une description de la classe ProductsCommandHandler.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Étapes suivantes
Les modèles et les conseils suivants peuvent être utiles quand il s’agit d’implémenter ce modèle :
Data Consistency Primer (Manuel d’introduction à la cohérence des données). Cet article explique les problèmes généralement rencontrés en raison de la cohérence éventuelle entre les magasins de données de lecture et d’écriture lors de l’utilisation du modèle CQRS et la façon dont ces problèmes peuvent être résolus.
Partitionnement des données horizontales, verticales et fonctionnelles. Cet article les meilleures pratiques pour diviser les données en partitions gérées et accessibles de façon distincte pour améliorer l’extensibilité, réduire la contention et optimiser les performances.
Le guide des modèles et pratiques CQRS Journey (Découverte de CQRS). En particulier, l’article de présentation du modèle de séparation des responsabilités pour les commandes et les requêtes explore le modèle et les situations dans lesquelles il peut vous être utile. L’article Epilogue: Lessons Learned (Épilogue : leçons apprises) vous aide à comprendre certains des problèmes liés à l’utilisation de ce modèle.
Billets de blog de Martin Fowler :
Ressources associées
Modèle d’approvisionnement en événements. Cet article décrit plus en détail la façon dont l’approvisionnement en événements peut être utilisé avec le modèle CQRS pour simplifier les tâches dans des domaines complexes tout en améliorant les performances, l’extensibilité et la réactivité. Il explique également comment proposer de la cohérence pour les données transactionnelles tout en maintenant un historique et des journaux d’audit complets qui peuvent mettre en place des actions de compensation.
Modèle de vue matérialisée. Le mode de lecture d’une implémentation CQRS peut contenir des vues matérialisées des données du modèle d’écriture, ou le modèle de lecture peut être utilisé pour générer des vues matérialisées.
Présentation sur un meilleur CQRS via des modèles d’interaction utilisateur asynchrones