Mise à l’échelle de manière élastique d’un compte Azure Cosmos DB for Apache Cassandra
S’APPLIQUE À : ![]() Cassandra
Cassandra
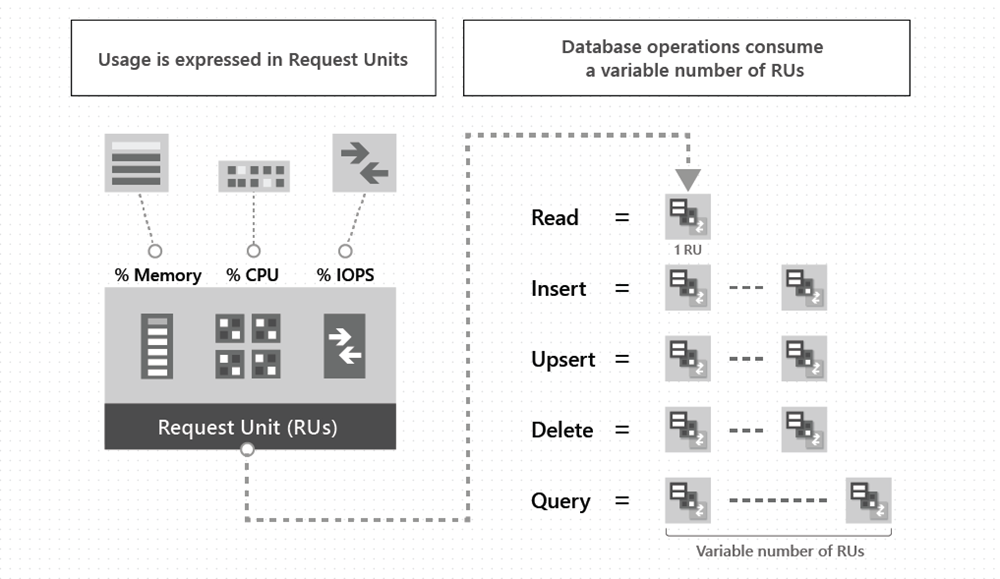
Il existe diverses options pour explorer la nature élastique d’Azure Cosmos DB for Apache Cassandra. Pour comprendre comment mettre à l’échelle efficacement dans Azure Cosmos DB, il est important de comprendre comment approvisionner la quantité appropriée d’unités de requête (RU/s) pour tenir compte des exigences de performances de votre système. Pour en savoir plus sur les unités de requête, consultez l’article relatif aux unités de requête.
Pour l’API pour Cassandra, vous pouvez récupérer les frais de l’unité de requête pour les requêtes individuelles en utilisant les SDK .NET et Java. Cette méthode est utile pour déterminer la quantité d’unités de requête que vous devrez provisionner dans le service.
Gestion de la limitation du débit (erreurs 429)
Azure Cosmos DB renvoie des erreurs de débit limité (429) si les clients consomment plus de ressources (RU/s) que la quantité que vous avez approvisionnée. L’API pour Cassandra dans Azure Cosmos DB traduit ces exceptions en erreurs surchargées sur le protocole natif Cassandra.
Si votre système n’est pas sensible à la latence, il peut suffire de gérer la limitation de débit à l’aide de nouvelles tentatives. Consultez les exemples de code Java pour la version 3 et la version 4 des pilotes Java Apache Cassandra pour savoir comment gérer la limitation du débit en toute transparence. Ces exemples mettent en place une version personnalisée de la stratégie de nouvelles tentatives Cassandra par défaut dans Java. Vous pouvez également utiliser l’extension Spark pour gérer la limitation du débit. Quand vous utilisez Spark, veillez à suivre nos conseils sur l’optimisation de la configuration du débit du connecteur Spark.
Gérer la mise à l’échelle
Si vous avez besoin de réduire la latence, il existe un éventail d’options pour gérer la mise à l’échelle et approvisionner le débit (RUs) dans l’API pour Cassandra :
- Manuellement à l’aide du Portail Azure
- Par programmation à l’aide des fonctionnalités du plan de contrôle
- Par programmation à l’aide de commandes CQL avec un Kit de développement logiciel (SDK) spécifique
- Dynamiquement à l’aide de la mise à l’échelle automatique
Les sections suivantes expliquent les avantages et les inconvénients de chaque approche. Vous pouvez ensuite décider de la meilleure stratégie pour équilibrer les besoins de mise à l’échelle de votre système, le coût global et les besoins d’efficacité de votre solution.
Utiliser le portail Azure
Vous pouvez mettre à l’échelle les ressources dans un compte Azure Cosmos DB for Apache Cassandra à l’aide du Portail Azure. Pour plus d’informations, consultez l’article Approvisionner le débit sur les conteneurs et les bases de données. Cet article explique les avantages relatifs du paramétrage du débit au niveau de la base de données ou du conteneur dans le Portail Azure. Les termes « base de données » et « conteneur » mentionnés dans ces articles sont mappés respectivement à « keyspace » et « table » pour l’API pour Cassandra.
L’avantage de cette méthode est qu’il s’agit d’une méthode clé en main simple pour gérer la capacité de débit sur la base de données. Toutefois, l’inconvénient est que, dans de nombreux cas, votre approche de mise à l’échelle peut exiger que certains niveaux d’automatisation soient à la fois rentables et élevés. Les sections suivantes expliquent les scénarios et les méthodes appropriés.
Utiliser le plan de contrôle
L’API d’Azure Cosmos DB pour Cassandra offre la possibilité d’ajuster le débit par programmation à l’aide de nos diverses fonctionnalités de plan de contrôle. Pour obtenir des conseils et des exemples, consultez les articles relatifs à Azure Resource Manager, PowerShell et Azure CLI.
L’avantage de cette méthode est que vous pouvez automatiser l’augmentation ou la diminution des ressources en fonction d’une minuterie pour tenir compte des pics d’activité ou des périodes de faible activité. Jetez un coup d’œil à notre exemple ici pour savoir comment y parvenir à l’aide d’Azure Functions et de PowerShell.
L’inconvénient de cette approche est que vous ne pouvez pas répondre à des besoins de mise à l’échelle fluctuants imprévisibles en temps réel. Au lieu de cela, vous devrez peut-être tirer parti du contexte de l’application dans votre système, au niveau du client ou du Kit de développement logiciel (SDK), ou à l’aide de la mise à l’échelle automatique.
Utiliser des requêtes CQL avec un Kit de développement logiciel (SDK) spécifique
Vous pouvez mettre le système à l’échelle dynamiquement avec du code en exécutant les commandes CQL ALTER pour la base de données ou le conteneur donné.
L’avantage de cette approche est qu’elle vous permet de répondre aux besoins de mise à l’échelle de façon dynamique et de manière personnalisée et adaptée à votre application. Avec cette approche, vous pouvez toujours tirer parti des frais et tarifs de RU/s Standard. Si les besoins de mise à l’échelle de votre système sont prévisibles pour la plupart (environ 70 % ou plus), l’utilisation du Kit de développement logiciel (SDK) avec CQL peut être une méthode de mise à l’échelle automatique plus économique que l’utilisation de la mise à l’échelle automatique. L’inconvénient de cette approche est qu’elle peut être assez complexe d’implémenter de nouvelles tentatives alors que la limitation du débit peut augmenter la latence.
Utiliser le débit approvisionné en mode de mise à l’échelle automatique
En plus de la façon standard (manuelle) ou par programmation d’approvisionner le débit, vous pouvez également configurer des conteneurs Azure Cosmos DB avec le débit approvisionné en mode de mise à l’échelle automatique. La mise à l’échelle automatique s’adapte automatiquement et instantanément à vos besoins en matière de consommation dans les limites RU spécifiées, sans compromettre les SLA. Pour en savoir plus, consultez l’article Créer des conteneurs et des bases de données Azure Cosmos DB en mise à l’échelle automatique.
L’avantage de cette approche est qu’il s’agit du moyen le plus simple de gérer les besoins de mise à l’échelle dans votre système. Elle n’appliquera pas de limitation du débit dans les plages RU configurées. L’inconvénient est que, si les besoins en matière de mise à l’échelle dans votre système sont prévisibles, la mise à l’échelle automatique peut être un moyen plus onéreux de gérer vos besoins de mise à l’échelle que d’utiliser les approches du plan de contrôle ou du Kit de développement logiciel (SDK) mentionnées ci-dessus.
Pour définir ou modifier le débit maximal (unités de requête) pour la mise à l’échelle automatique à l’aide de CQL, utilisez la commande suivante (en remplaçant l’espace de noms/le nom de la table en conséquence) :
# to set max throughput (RUs) for autoscale at keyspace level:
create keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at keyspace level:
alter keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=4000;
# to set max throughput (RUs) for autoscale at table level:
create table <keyspace name>.<table name> (pk int PRIMARY KEY, ck int) WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at table level:
alter table <keyspace name>.<table name> WITH cosmosdb_autoscale_max_throughput=4000;
Étapes suivantes
- Prise en main de la création d’un compte API pour Cassandra, d’une base de données et d’une table à l’aide d’une application Java
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour