Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
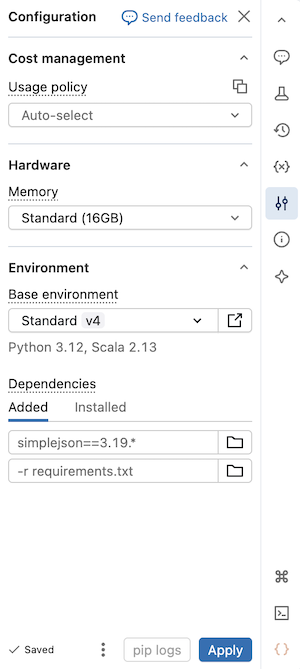
Cette page explique comment utiliser le panneau latéral Environnement d’un notebook serverless pour configurer les dépendances, les politiques d’utilisation serverless, la mémoire et l’environnement de base. Ce panneau fournit un emplacement unique pour gérer les paramètres serverless du notebook. Les paramètres configurés dans ce panneau s’appliquent uniquement lorsque le notebook est connecté au calcul serverless.
Pour développer le volet latéral Environnement , cliquez sur le bouton ![]() à droite du bloc-notes.
à droite du bloc-notes.
Utiliser AI Runtime (GPU sans serveur)
Importante
AI Runtime est disponible en préversion publique.
Suivez ces étapes pour configurer AI Runtime, alimenté par le calcul GPU serverless, sur votre notebook Databricks :
- Dans un bloc-notes, cliquez sur le menu déroulant de calcul en haut et sélectionnez GPU serverless.
- Cliquez sur
 Pour ouvrir le volet latéral Environnement .
Pour ouvrir le volet latéral Environnement . - Sélectionnez A10 dans le champ Accélérateur .
- Sous Environnement de base, sélectionnez Standard pour l’environnement par défaut ou l’IA pour l’environnement optimisé pour l’IA avec des bibliothèques Machine Learning préinstallées.
- Cliquez sur Appliquer , puis Confirmez que vous souhaitez appliquer AI Runtime à votre environnement de notebook.
Pour plus d’informations, consultez AI Runtime.
Utiliser un calcul serverless à mémoire élevée
Importante
Cette fonctionnalité est disponible en préversion publique.
Si vous rencontrez des erreurs de mémoire insuffisante dans votre notebook, vous pouvez configurer le notebook pour qu’il utilise une taille de mémoire supérieure. Ce paramètre augmente la taille de la mémoire REPL utilisée lors de l’exécution du code dans le notebook. Elle n’affecte pas la taille de mémoire de la session Spark. L’utilisation serverless avec une mémoire élevée a un taux d’émission DBU plus élevé que la mémoire standard.
Les options de mémoire disponibles sont les suivantes :
- Standard : 16 Go de mémoire totale.
- Élevé : 32 Go de mémoire totale.
Pour configurer le paramètre de mémoire du notebook :
- Dans l’interface utilisateur du bloc-notes, cliquez sur le panneau latéral Environnement
 .
. - Sous Mémoire, sélectionnez Haute mémoire.
- Cliquez sur Appliquer.
Ce paramètre s’applique également aux tâches de travail de bloc-notes, qui s’exécutent à l’aide des préférences de mémoire du bloc-notes. La mise à jour des préférences de mémoire dans le notebook affecte l’exécution du travail suivant.
Choisissez une politique d'utilisation sans serveur
Importante
Cette fonctionnalité est disponible en préversion publique.
Les politiques d’utilisation sans serveur permettent à votre organisation d’appliquer des balises personnalisées sur l’utilisation sans serveur pour une attribution granulaire de la facturation.
Si votre espace de travail utilise des stratégies d’utilisation serverless pour attribuer l’utilisation serverless, vous pouvez sélectionner la stratégie d’utilisation serverless que vous souhaitez appliquer au notebook. Si un utilisateur n’est affecté qu’à une seule stratégie d’utilisation serverless, cette stratégie est sélectionnée par défaut.
Vous pouvez sélectionner la stratégie d'utilisation sans serveur une fois que votre notebook est connecté au calcul sans serveur à l'aide du panneau latéral de l'Environnement :
- Dans l’interface utilisateur du bloc-notes, cliquez sur le panneau latéral Environnement.
- Sous Stratégie d’utilisation serverless , sélectionnez la stratégie d’utilisation serverless que vous souhaitez appliquer à votre notebook.
- Cliquez sur Appliquer.
Une fois cette configuration terminée, toutes les utilisations de notebooks héritent des balises personnalisées de la stratégie d’utilisation serverless.
Remarque
Si votre bloc-notes provient d’un référentiel Git ou n’a pas de stratégie d’utilisation serverless assignée, le système applique par défaut la dernière stratégie d’utilisation serverless que vous avez sélectionnée lorsque le bloc-notes est ensuite attaché au calcul serverless.
Sélectionner un environnement de base
Un environnement de base détermine les bibliothèques et la version d’environnement préinstallées disponibles pour votre notebook serverless. Le sélecteur d’environnement de base dans le panneau latéral Environnement fournit une interface unifiée pour sélectionner votre environnement. Pour plus d’informations sur chaque version de l’environnement, consultez les versions d’environnement serverless. Databricks recommande d’utiliser la dernière version pour obtenir les fonctionnalités de notebook les plus up-to-date.
Le sélecteur d’environnement de base inclut les options suivantes :
- Standard : environnement de base par défaut avec des bibliothèques fournies par Databricks.
- IA : environnement de base optimisé pour l’IA avec des bibliothèques Machine Learning préinstallées. Cette option s’affiche uniquement lorsqu’un accélérateur (GPU) est sélectionné.
-
Plus : Développe pour afficher des options supplémentaires :
- Versions précédentes des environnements Standard et IA.
- Personnalisé : vous permet de spécifier un environnement personnalisé à l’aide d’un fichier YAML.
- Environnements d’espace de travail : répertorie tous les environnements de base compatibles configurés pour votre espace de travail par un administrateur.
Pour sélectionner un environnement de base :
- Dans l’interface utilisateur du bloc-notes, cliquez sur le panneau latéral Environnement.
- Sous Environnement de base, sélectionnez un environnement dans le menu déroulant.
- Cliquez sur Appliquer.
Ajouter des dépendances au notebook
Étant donné que serverless ne prend pas en charge les stratégies de calcul ni les scripts init, vous devez ajouter des dépendances personnalisées à l’aide du panneau latéral Environnement . Vous pouvez ajouter des dépendances individuellement ou utiliser un environnement de base partageable pour installer plusieurs dépendances.
Pour ajouter individuellement une dépendance :
Dans l’interface utilisateur du bloc-notes, cliquez sur le panneau latéral Environnement
.Dans la section Dépendances , cliquez sur Ajouter une dépendance et entrez le chemin d’accès de la dépendance dans le champ. Vous pouvez spécifier une dépendance dans n’importe quel format valide dans un fichier requirements.txt. Les fichiers wheel de Python ou les projets Python (par exemple, le répertoire contenant un
pyproject.tomlou unsetup.py) peuvent se trouver dans des fichiers de l’espace de travail ou des volumes du catalogue Unity.- Si vous utilisez un fichier d’espace de travail, le chemin d’accès doit être absolu et commencer par
/Workspace/. - Si vous utilisez un fichier dans un volume de catalogue Unity, le chemin d’accès doit être au format suivant :
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.
- Si vous utilisez un fichier d’espace de travail, le chemin d’accès doit être absolu et commencer par
Cliquez sur Appliquer. Cela installe les dépendances dans l’environnement virtuel du notebook et redémarre le processus de Python.
Importante
N’installez pas PySpark ou toute bibliothèque qui installe PySpark en tant que dépendance sur vos notebooks serverless. Si vous l’effectuez, votre session stoppera et entraînera une erreur. Si cela se produit, supprimez la bibliothèque et réinitialisez votre environnement.
Pour afficher les dépendances installées, cliquez sur l’onglet Installé dans le volet latéral Environnements . Les journaux d’installation pip pour l’environnement de notebook sont également disponibles en cliquant sur les journaux pip en bas du panneau.
Créer une spécification d’environnement personnalisée
Vous pouvez créer et réutiliser des spécifications d’environnement personnalisées.
- Dans un notebook serverless, sélectionnez un environnement de base et ajoutez les dépendances que vous souhaitez installer.
- Cliquez sur l'icône de menu
 , qui se trouve en bas du panneau d’environnement, puis cliquez sur Exporter l’environnement.
, qui se trouve en bas du panneau d’environnement, puis cliquez sur Exporter l’environnement. - Enregistrez la spécification en tant que fichier d’espace de travail ou dans un volume de catalogue Unity.
Pour utiliser votre spécification d’environnement personnalisée dans un notebook, sélectionnez Personnalisé dans le menu déroulant Environnement de base, puis utilisez ![]() sélectionner votre fichier YAML.
sélectionner votre fichier YAML.
Créer des utilitaires communs à partager dans votre espace de travail
L’exemple suivant montre comment stocker un utilitaire commun dans un fichier d’espace de travail et l’ajouter en tant que dépendance dans votre notebook serverless :
Créez un dossier avec la structure suivante. Vérifiez que les consommateurs de votre projet disposent d’un accès approprié au chemin d’accès au fichier :
helper_utils/ ├── helpers/ │ └── __init__.py # your common functions live here ├── pyproject.tomlRemplissez
pyproject.tomlcomme suit :[project] name = "common_utils" version = "0.1.0"Ajoutez une fonction au
init.pyfichier. Par exemple:def greet(name: str) -> str: return f"Hello, {name}!"Dans l’interface utilisateur du bloc-notes, cliquez sur du volet Environment icon.Environnement.
Dans la section Dépendances, cliquez sur Ajouter une dépendance, puis entrez le chemin d’accès de votre fichier utilitaire. Par exemple :
/Workspace/helper_utils.Cliquez sur Appliquer.
Vous pouvez maintenant utiliser la fonction dans votre bloc-notes :
from helpers import greet
print(greet('world'))
Cette sortie est la suivante :
Hello, world!
Réinitialiser les dépendances d’environnement
Si votre notebook est connecté à un calcul serverless, Databricks met automatiquement en cache le contenu de l’environnement virtuel du notebook. Cela signifie que vous n’avez généralement pas besoin de réinstaller les dépendances Python spécifiées dans la Environment panneau latéral lorsque vous ouvrez un bloc-notes existant, même s’il a été déconnecté en raison de l’inactivité.
La mise en cache des environnements virtuels Python s’applique également aux tâches. Lorsqu’un travail est exécuté, toute tâche du travail qui partage le même ensemble de dépendances qu’une tâche terminée dans cette exécution est plus rapide, car les dépendances requises sont déjà disponibles.
Remarque
Si vous modifiez l’implémentation d’un package de Python personnalisé utilisé dans un travail serverless, vous devez également mettre à jour son numéro de version afin que les travaux puissent récupérer la dernière implémentation.
Pour effacer le cache d’environnement et effectuer une nouvelle installation des dépendances spécifiées dans le panneau latéral Environnement d’un bloc-notes attaché au calcul serverless, cliquez sur la flèche en regard de Appliquer , puis sur Réinitialiser les valeurs par défaut.
Si vous installez des packages qui arrêtent ou modifient le bloc-notes principal ou l’environnement Apache Spark, supprimez les packages incriminés, puis réinitialisez l’environnement. Le démarrage d’une nouvelle session n’efface pas l’intégralité du cache d’environnement.
Configurer les référentiels de package de Python par défaut
Les administrateurs d’espace de travail peuvent configurer des référentiels de package privés ou authentifiés dans les espaces de travail comme configuration pip par défaut pour les notebooks serverless et les travaux serverless. Cela permet aux utilisateurs d’installer des packages à partir de référentiels de Python internes sans définir explicitement index-url ou extra-index-url.
Pour obtenir des instructions, les administrateurs d’espace de travail peuvent se référer à Configurer les référentiels de paquets Python par défaut.
Configurer l’environnement pour les tâches de travail
Pour les types de tâches de travail tels que notebook, Python script, Python wheel, JAR ou dbt, les dépendances de bibliothèque sont héritées de la version de l’environnement serverless. Pour afficher la liste des bibliothèques installées, consultez la section des bibliothèques installées Python installées ou des bibliothèques Java et Scala installées de la version environnement que vous utilisez. Si une tâche nécessite une bibliothèque qui n’est pas installée, vous pouvez installer la bibliothèque à partir de fichiers d’espace de travail, de volumes de catalogue Unity ou de référentiels de packages publics.
Pour les carnets avec l'environnement d'un carnet existant, vous pouvez exécuter la tâche en utilisant l'environnement du carnet ou le remplacer en sélectionnant un environnement au niveau de la tâche à la place.
Importante
L'utilisation du calcul sans serveur pour les tâches JAR est en préversion publique.
Pour ajouter une bibliothèque lorsque vous créez ou modifiez une tâche de travail :
Dans le menu déroulant Environnement et bibliothèques , cliquez sur
 en regard de l’environnement par défaut ou cliquez sur + Ajouter un nouvel environnement.
en regard de l’environnement par défaut ou cliquez sur + Ajouter un nouvel environnement.
Sélectionnez la version de l’environnement dans la liste déroulante Version de l’environnement. Consultez les Versions de l’environnement serverless. Databricks recommande de choisir la dernière version pour obtenir les fonctionnalités les plus récentes.
Dans la boîte de dialogue Configurer l’environnement, cliquez sur + Ajouter une bibliothèque.
Sélectionnez le type de dépendance dans le menu déroulant sous Bibliothèques.
Dans la zone de texte Chemin d’accès au fichier, entrez le chemin d’accès à la bibliothèque.
- Pour un Python Wheel dans un fichier d’espace de travail, le chemin d’accès doit être absolu et commencer par
/Workspace/. - Pour un Python Wheel dans un volume Unity Catalog, le chemin d’accès doit être
/Volumes/<catalog>/<schema>/<volume>/<path>.whl. - Pour un fichier
requirements.txt, sélectionnez PyPi et entrez-r /path/to/requirements.txt.
- Pour un Python Wheel dans un fichier d’espace de travail, le chemin d’accès doit être absolu et commencer par
Cliquez sur Confirmer ou + Ajouter une bibliothèque pour ajouter une autre bibliothèque.
Si vous ajoutez une tâche, cliquez sur Créer une tâche. Si vous modifiez une tâche, cliquez sur Enregistrer la tâche.
Environnements de base pour les tâches de travail
Les travaux serverless prennent en charge les environnements de base personnalisés définis avec des fichiers YAML pour les tâches de Python, de roue Python et de notebook. Pour les tâches de notebook, vous pouvez sélectionner un environnement de base personnalisé dans la configuration de l’environnement du travail ou utiliser les propres paramètres d’environnement du notebook, qui prennent en charge les environnements d’espace de travail et les environnements de base personnalisés. Dans tous les cas, seules les dépendances requises pour la tâche sont installées au moment de l’exécution. Vous pouvez sélectionner un environnement de base personnalisé directement dans les paramètres d’environnement du travail. Pour créer un environnement de base personnalisé, consultez Créer une spécification d’environnement personnalisée.
Environnements de base managés dans les travaux
Importante
Cette fonctionnalité est en version bêta. Les administrateurs d’espace de travail peuvent contrôler l’accès à cette fonctionnalité à partir de la page Aperçus . Consultez les aperçus Manage Azure Databricks.
Vous pouvez sélectionner des environnements de base managés directement dans les paramètres d’environnement du travail. Cela inclut les environnements de base d’espace de travail configurés par un administrateur d’espace de travail et des environnements de base fournis par Azure Databricks, tels que Standard et AI. Il s’agit des mêmes environnements de base disponibles dans le sélecteur d’environnement de notebook. Pour plus d’informations sur la création et la gestion des environnements de base d’espace de travail, consultez Gérer les environnements de base d’espace de travail.
Les environnements de base managés sont pris en charge pour les tâches de notebook, de Python et de roue Python. Ils ne sont pas pris en charge pour les tâches JAR.
Compatibilité de l’environnement et du calcul
L’environnement de base que vous sélectionnez doit être compatible avec le type de calcul de la tâche. Par exemple, un environnement créé pour le calcul GPU n’est pas compatible avec le calcul CPU. Dans l’interface des tâches, les environnements incompatibles sont grisés dans la liste déroulante de l’environnement de base.
Lorsque vous configurez une tâche de notebook, le type de calcul (PROCESSEUR ou GPU) et l’environnement de base peuvent chacun provenir des paramètres de travail ou des paramètres du notebook.
- Si vous définissez un accélérateur matériel (GPU) au niveau du travail, vous devez également sélectionner un environnement de base au niveau du travail. Vous ne pouvez pas utiliser l’environnement du notebook avec un accélérateur au niveau du job.
- Si vous modifiez le type de calcul du notebook (par exemple, du CPU au GPU) après avoir créé un travail qui s'y réfère, les tâches existantes peuvent devenir incompatibles avec l'environnement configuré. Passez en revue les paramètres d’environnement de votre travail après avoir modifié la configuration de calcul du notebook.
- Pour les utilisateurs d’API, si l’environnement de base est défini au niveau du travail, mais que le type de calcul est hérité du notebook, la compatibilité est validée au moment de l’exécution plutôt qu’au moment de la création du travail. Si la configuration est incompatible, l’exécution échoue avec une erreur.