Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Générez un agent IA et déployez-le à l’aide de Databricks Apps. Databricks Apps vous donne un contrôle total sur le code de l’agent, la configuration du serveur et le flux de travail de déploiement. Cette approche est idéale lorsque vous avez besoin d’un comportement de serveur personnalisé, d’un contrôle de version git ou d’un développement IDE local.
Spécifications
Activez Databricks Apps dans votre espace de travail. Consultez Configurer votre espace de travail Databricks Apps et votre environnement de développement.
Étape 1. Cloner le modèle d’application agent
Commencez à utiliser un modèle d’agent prédéfini à partir du référentiel de modèles d’application Databricks.
Ce tutoriel utilise le agent-openai-agents-sdk modèle, qui inclut :
- Un agent créé à l’aide du Kit de développement logiciel (SDK) de l’agent OpenAI
- Code de démarrage pour une application agent avec une API REST conversationnelle et une interface utilisateur de conversation interactive
- Code permettant d’évaluer l’agent à l’aide de MLflow
Choisissez l’un des chemins d’accès suivants pour configurer le modèle :
Interface utilisateur de l’espace de travail
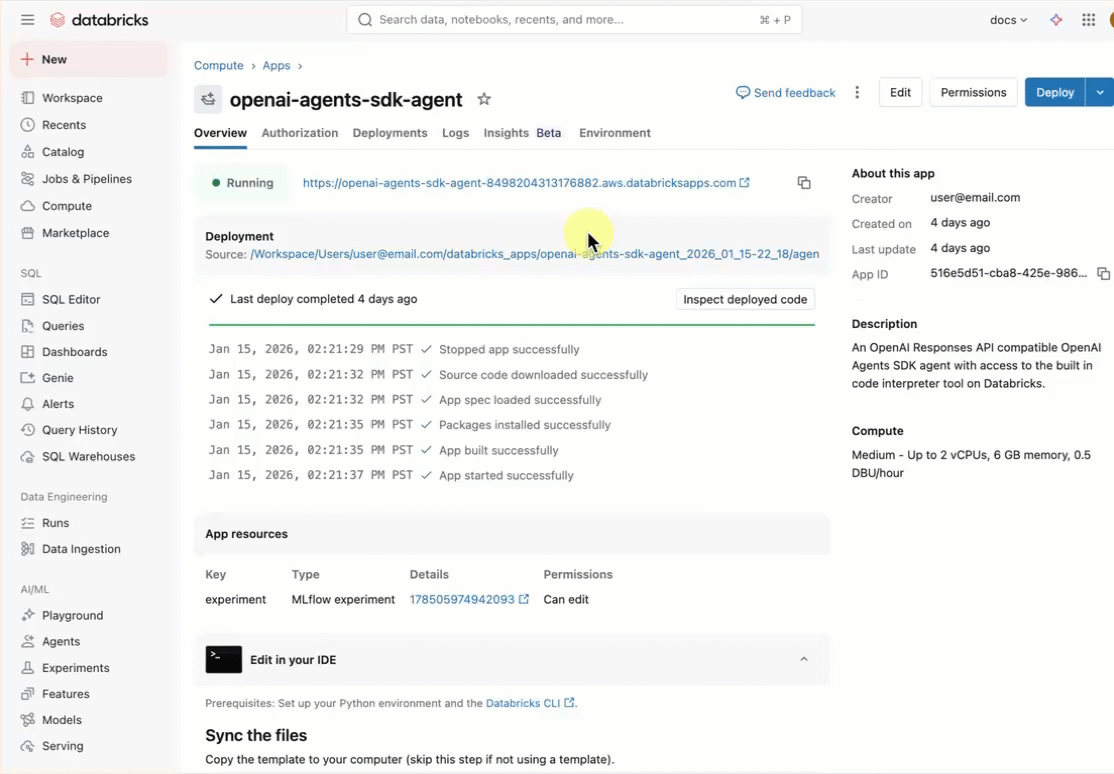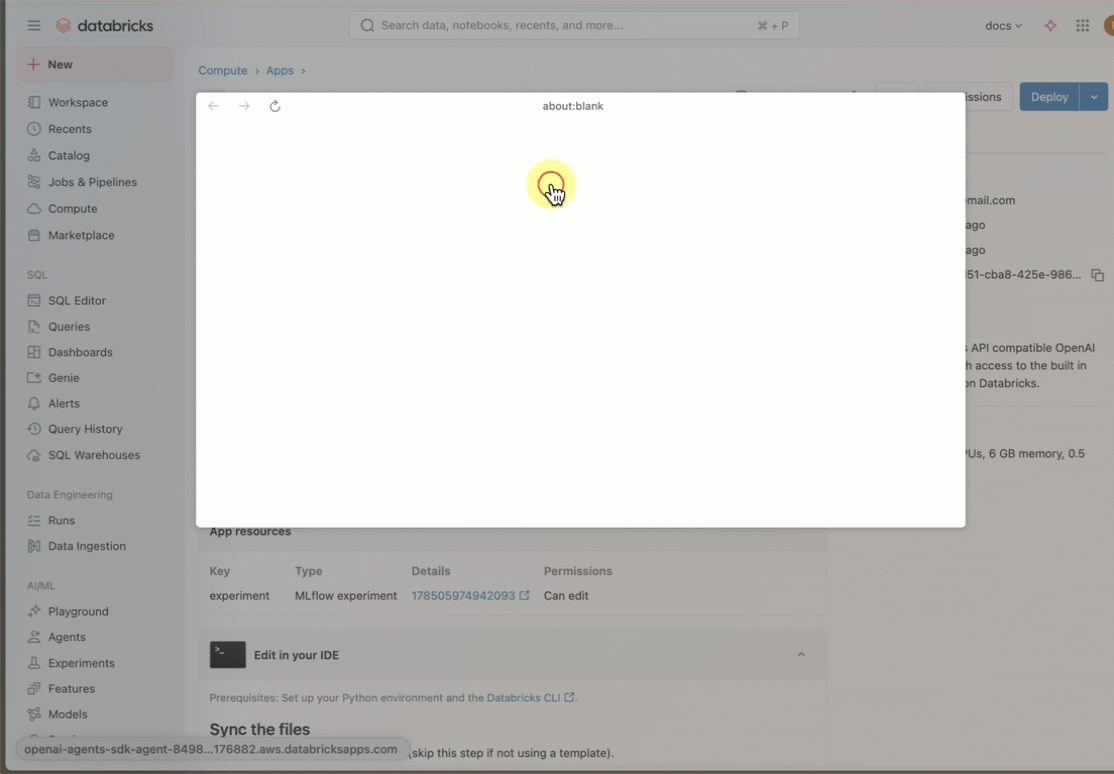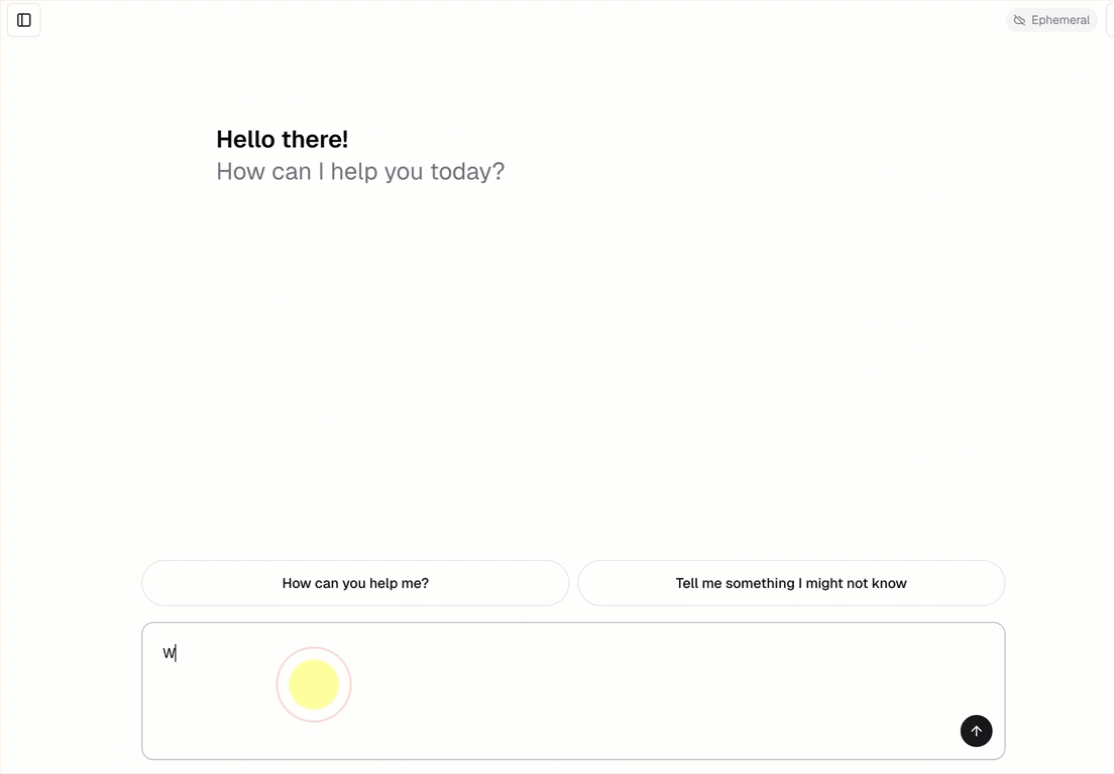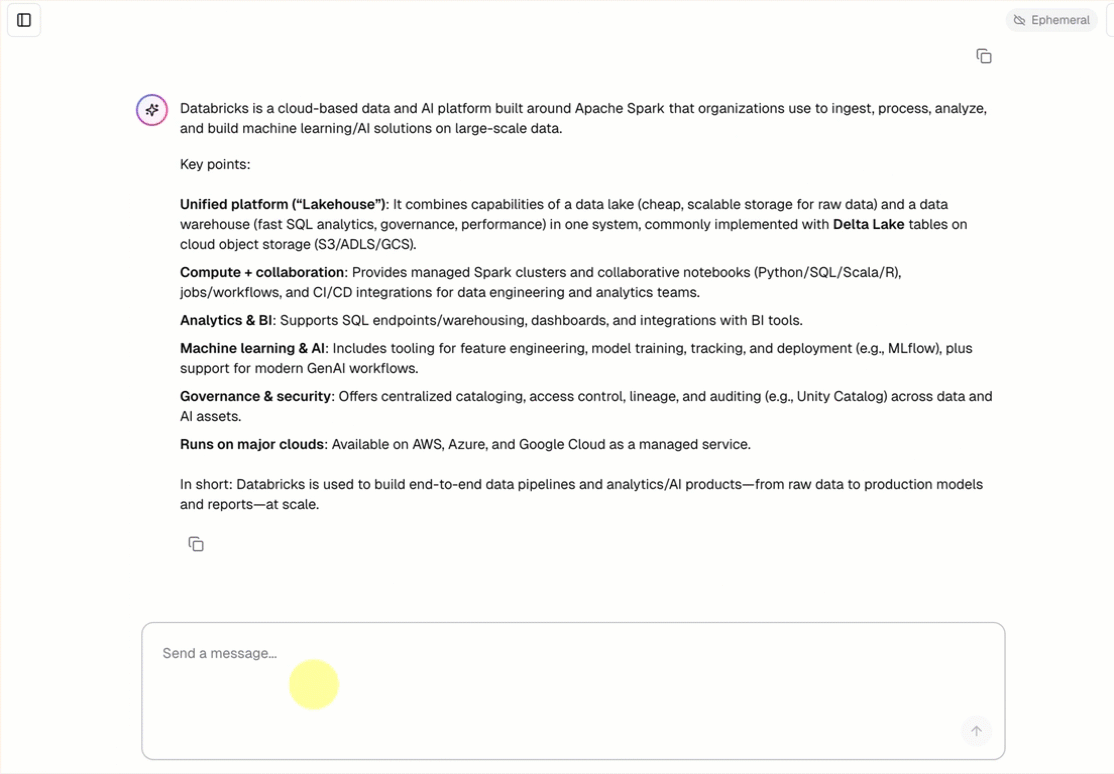
Installez le modèle d’application à l’aide de l’interface utilisateur de l’espace de travail. Cela installe l’application et la déploie sur une ressource de calcul dans votre espace de travail. Vous pouvez ensuite synchroniser les fichiers d’application avec votre environnement local pour poursuivre le développement.
Dans votre espace de travail Databricks, cliquez sur + Nouvelle>application.
Cliquez sur Agents>Agents - Kit de développement logiciel (SDK) des agents OpenAI.
Créez une expérience MLflow avec le nom
openai-agents-templateet terminez le reste de la configuration pour installer le modèle.Après avoir créé l’application, cliquez sur l’URL de l’application pour ouvrir l’interface utilisateur de conversation.
Après avoir créé l’application, téléchargez le code source sur votre ordinateur local pour le personnaliser :
Copiez la première commande sous Synchroniser les fichiers
Dans un terminal local, exécutez la commande copiée.
Cloner à partir de GitHub
Pour commencer à partir d’un environnement local, clonez le référentiel de modèles d’agent et ouvrez le agent-openai-agents-sdk répertoire :
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Étape 2. Comprendre l’application de l’agent
Le modèle d’agent illustre une architecture prête pour la production avec ces composants clés. Ouvrez les sections suivantes pour plus d’informations sur chaque composant :

Ouvrez les sections suivantes pour plus d’informations sur chaque composant :
 MLflow AgentServer
MLflow AgentServer
Serveur FastAPI asynchrone qui gère les demandes d’agent avec le suivi et l’observabilité intégrés.
AgentServer fournit le point de terminaison pour interroger votre agent et gère automatiquement le /invocations routage des demandes, la journalisation et la gestion des erreurs.

ResponsesAgent Interface
Databricks recommande MLflow ResponsesAgent de générer des agents.
ResponsesAgent vous permet de créer des agents avec n’importe quelle infrastructure tierce, puis de l’intégrer à des fonctionnalités d’IA Databricks pour des fonctionnalités de journalisation, de suivi, d’évaluation, de déploiement et de supervision robustes.

Pour savoir comment créer un ResponsesAgent, consultez les exemples de la documentation MLflow - ResponsesAgent for Model Serving.
ResponsesAgent offre les avantages suivants :
Fonctionnalités avancées de l’agent
- Prise en charge multi-agent
- Sortie de streaming : transmettez la sortie par blocs plus petits.
- Historique complet des messages appelant les outils : retournez plusieurs messages, y compris les messages d’appel intermédiaires, pour améliorer la qualité et la gestion des conversations.
- Support pour la confirmation des invocations d’outils
- Prise en charge des outils fonctionnant sur une longue période
Développement, déploiement et supervision simplifiés
-
Créer des agents à l’aide de n’importe quel cadre : encapsulez n’importe quel agent existant à l’aide de l’interface
ResponsesAgentpour obtenir une compatibilité immédiate avec AI Playground, Agent Evaluation et Agent Monitoring. - Interfaces de développement typées: écrire du code d'agent à l’aide de classes Python typées, en bénéficiant de l’auto-complétion de l’IDE et du notebook.
- Suivi automatique : MLflow agrège automatiquement les réponses diffusées en continu dans les traces pour faciliter l’évaluation et l’affichage.
-
Compatible avec le schéma OpenAI : consultez OpenAI
Responses: Réponses et ChatCompletion.
-
Créer des agents à l’aide de n’importe quel cadre : encapsulez n’importe quel agent existant à l’aide de l’interface
 Kit de développement logiciel (SDK) Des agents OpenAI
Kit de développement logiciel (SDK) Des agents OpenAI
Le modèle utilise le Kit de développement logiciel (SDK) Des agents OpenAI comme infrastructure d’agent pour la gestion des conversations et l’orchestration d’outils. Vous pouvez créer des agents à l’aide de n’importe quelle infrastructure. La clé consiste à encapsuler votre agent avec l’interface MLflow ResponsesAgent .
 Serveurs MCP (Protocole de contexte de modèle)
Serveurs MCP (Protocole de contexte de modèle)
Le modèle se connecte aux serveurs MCP Databricks pour permettre aux agents d’accéder aux outils et aux sources de données. Consultez le protocole MCP (Model Context Protocol) sur Databricks.
Créer des agents à l’aide d’assistants de codage IA
Databricks recommande d’utiliser des assistants de codage IA tels que Claude, Cursor et Copilot pour créer des agents. Utilisez les compétences de l’agent fournies, dans /.claude/skillset le AGENTS.md fichier pour aider les assistants IA à comprendre la structure du projet, les outils disponibles et les meilleures pratiques. Les agents peuvent lire automatiquement ces fichiers pour développer et déployer Databricks Apps.
Rubriques de création avancées
Réponses de diffusion en continu
Réponses de diffusion en continu
Le streaming permet aux agents d’envoyer des réponses en segments en temps réel au lieu d’attendre la réponse complète. Pour implémenter la diffusion en continu avec ResponsesAgent, émettez une série d’événements delta suivis d’un événement d’achèvement final :
-
Émettre des événements delta : envoyez plusieurs
output_text.deltaévénements avec le mêmeitem_idpour diffuser en continu des blocs de texte en temps réel. -
Terminer avec l’événement terminé : envoyez un événement final
response.output_item.doneavec le mêmeitem_idque les événements delta contenant le texte de sortie final complet.
Chaque événement delta diffuse un bloc de texte vers le client. L'événement définitif de fin contient le texte de réponse complet et indique à Databricks d'effectuer les opérations suivantes :
- Suivez le rendu de votre agent avec le suivi de MLflow
- Agréger les réponses diffusées en flux continu dans les tables d’inférence de la passerelle IA
- Afficher la sortie complète dans l’interface utilisateur AI Playground
Propagation d’erreurs de streaming
Mosaic AI propage toutes les erreurs rencontrées lors du flux en continu avec le dernier jeton sous databricks_output.error. Il incombe au client appelant de gérer correctement et de faire apparaître cette erreur.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Entrées et sorties personnalisées
Entrées et sorties personnalisées
Certains scénarios peuvent nécessiter des entrées d’agent supplémentaires, telles que client_type et session_id, ou des sorties telles que des liens sources de récupération qui ne doivent pas être inclus dans l’historique des conversations pour les interactions futures.
Pour ces scénarios, MLflow ResponsesAgent prend en charge en mode natif les champs custom_inputs et custom_outputs. Vous pouvez accéder aux entrées personnalisées via request.custom_inputs dans les exemples de cadre ci-dessus.
L’application d’évaluation de l’agent ne prend pas en charge le rendu des traces pour les agents avec des champs d’entrée supplémentaires.
Fournir custom_inputs dans l’IA Playground et consulter l’application
Si votre agent accepte des entrées supplémentaires à l’aide du custom_inputs champ, vous pouvez fournir manuellement ces entrées dans l’aire de jeu IA et l’application de révision.
Dans AI Playground ou l’application Agent Review, sélectionnez l'icône rouage
 .
.Activez custom_inputs.
Fournissez un objet JSON qui correspond au schéma d’entrée défini de votre agent.

Schémas de récupérateur personnalisés
Schémas de récupérateur personnalisés
Les agents IA utilisent couramment des récupérateurs pour rechercher et interroger des données non structurées à partir d’index de recherche vectorielle. Par exemple, les outils de récupération, consultez Connecter des agents à des données non structurées.
Tracez ces extracteurs au sein de votre agent avec des intervalles MLflow RETRIEVER pour activer les fonctionnalités de produit Databricks, notamment :
- Affichage automatique des liens vers des documents sources récupérés dans l’interface utilisateur AI Playground
- Exécution automatique du fondement de l’extraction et des jugements de pertinence dans l’évaluation des agents
Remarque
Databricks recommande d’utiliser les outils de récupération fournis par les packages Databricks AI Bridge comme databricks_langchain.VectorSearchRetrieverTool et databricks_openai.VectorSearchRetrieverTool, car ils sont déjà conformes au schéma du récupérateur MLflow. Consultez Développer localement des outils d’extraction de recherche vectorielle avec AI Bridge.
Si votre agent inclut des segments d'extracteur avec un schéma personnalisé, appelez mlflow.models.set_retriever_schema quand vous définissez votre agent dans le code. Cela mappe les colonnes de sortie de votre récupérateur aux champs attendus de MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Remarque
La colonne doc_uri est particulièrement importante lors de l’évaluation des performances du récupérateur.
doc_uri est l’identificateur principal des documents retournés par l’extracteur, ce qui vous permet de les comparer aux jeux d’évaluation de la vérité terrain. Consultez les jeux d’évaluation (MLflow 2).
Étape 3. Exécuter l’application agent localement
Configurez votre environnement local :
Installez
uv(Gestionnaire de package Python),nvm(Gestionnaire de versions de Nœud) et l’interface CLI Databricks :-
uvInstallation -
nvmInstallation - Exécutez ce qui suit pour utiliser Node 20 LTS :
nvm use 20 -
databricks CLIInstallation
-
Remplacez le répertoire par le
agent-openai-agents-sdkdossier.Exécutez les scripts de démarrage rapide fournis pour installer les dépendances, configurer votre environnement et démarrer l’application.
uv run quickstart uv run start-app
Dans un navigateur, accédez à http://localhost:8000 pour commencer à discuter avec l’agent.
Étape 4. Configurer l’authentification
Votre agent a besoin de l’authentification pour accéder aux ressources Databricks. Databricks Apps fournit deux méthodes d’authentification :
Autorisation d’application (par défaut)
L’autorisation d’application utilise un principal de service créé automatiquement par Azure Databricks pour votre application. Tous les utilisateurs partagent les mêmes autorisations.
Accordez des autorisations à l’expérience MLflow :
- Cliquez sur Modifier sur la page d’accueil de votre application.
- Accédez à l’étape Configurer .
- Dans la section Ressources de l’application , ajoutez la ressource d’expérience MLflow avec
Can Editautorisation.
Pour d’autres ressources (Recherche vectorielle, espaces Genie, points de terminaison de service), ajoutez-les de la même façon dans la section Ressources de l’application .
Pour plus d’informations, consultez l’autorisation de l’application .
Autorisation de l’utilisateur
L’autorisation utilisateur permet à votre agent d’agir avec les autorisations individuelles de chaque utilisateur. Utilisez cette option lorsque vous avez besoin d’un contrôle d’accès par utilisateur ou de pistes d’audit.
Ajoutez ce code à votre agent :
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Important: Initialiser get_user_workspace_client() à l’intérieur de vos @invoke fonctions, @stream et non pendant le démarrage de l’application. Les informations d’identification de l’utilisateur existent uniquement lors de la gestion d’une demande.
Configurer des étendues : Ajoutez des étendues d’autorisation dans l’interface utilisateur Databricks Apps pour définir les API auxquelles votre agent peut accéder pour le compte des utilisateurs.
Pour obtenir des instructions d’installation complètes, consultez l’autorisation de l’utilisateur .
Étape 5. Évaluer l’agent
Le modèle inclut le code d’évaluation de l’agent. Pour plus d’informations, consultez agent_server/evaluate_agent.py. Évaluez la pertinence et la sécurité des réponses de votre agent en exécutant ce qui suit dans un terminal :
uv run agent-evaluate
Étape 6. Déployer l’agent sur Databricks Apps
Après avoir configuré l’authentification, déployez votre agent sur Databricks. Vérifiez que l’interface CLI Databricks est installée et configurée.
Si vous avez cloné le référentiel localement, créez l’application Databricks avant de la déployer. Si vous avez créé votre application via l’interface utilisateur de l’espace de travail, ignorez cette étape, car l’application et l’expérience MLflow sont déjà configurées.
databricks apps create agent-openai-agents-sdkSynchronisez les fichiers locaux avec votre espace de travail. Consultez Déployer l’application.
DATABRICKS_USERNAME=$(databricks current-user me | jq -r .userName) databricks sync . "/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk"Déployez votre application Databricks.
databricks apps deploy agent-openai-agents-sdk --source-code-path /Workspace/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk
Pour les futures mises à jour de l’agent, synchronisez et redéployez votre agent.
Étape 7. Interroger l’agent déployé
Les utilisateurs interrogent votre agent déployé à l’aide de jetons OAuth. Les jetons d’accès personnels (PAT) ne sont pas pris en charge pour Databricks Apps.
Générez un jeton OAuth à l’aide de l’interface CLI Databricks :
databricks auth login --host <https://host.databricks.com>
databricks auth token
Utilisez le jeton pour interroger l’agent :
curl -X POST <app-url.databricksapps.com>/invocations \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Limites
Seules les tailles de calcul moyennes et volumineuses sont prises en charge. Consultez Configurer la taille de calcul d’une application Databricks.