Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
Cette fonctionnalité est disponible en préversion publique.
Cette page présente Genie Code pour le développement de pipelines, un agent de données IA disponible en sélectionnant le mode Agent dans Genie Code. Conçu spécifiquement pour les pipelines déclaratifs Spark Lakeflow (SDP) et l’éditeur de pipelines Lakeflow, il explore les données, génère et exécute du code de pipeline et corrige les erreurs, à partir d’une seule invite.
Qu’est-ce que Genie Code pour le développement de pipelines ?
Genie Code en mode Agent est un partenaire autonome qui peut automatiser des flux de travail d’ingénierie de données en plusieurs étapes dans SDP et l’éditeur de pipelines Lakeflow.
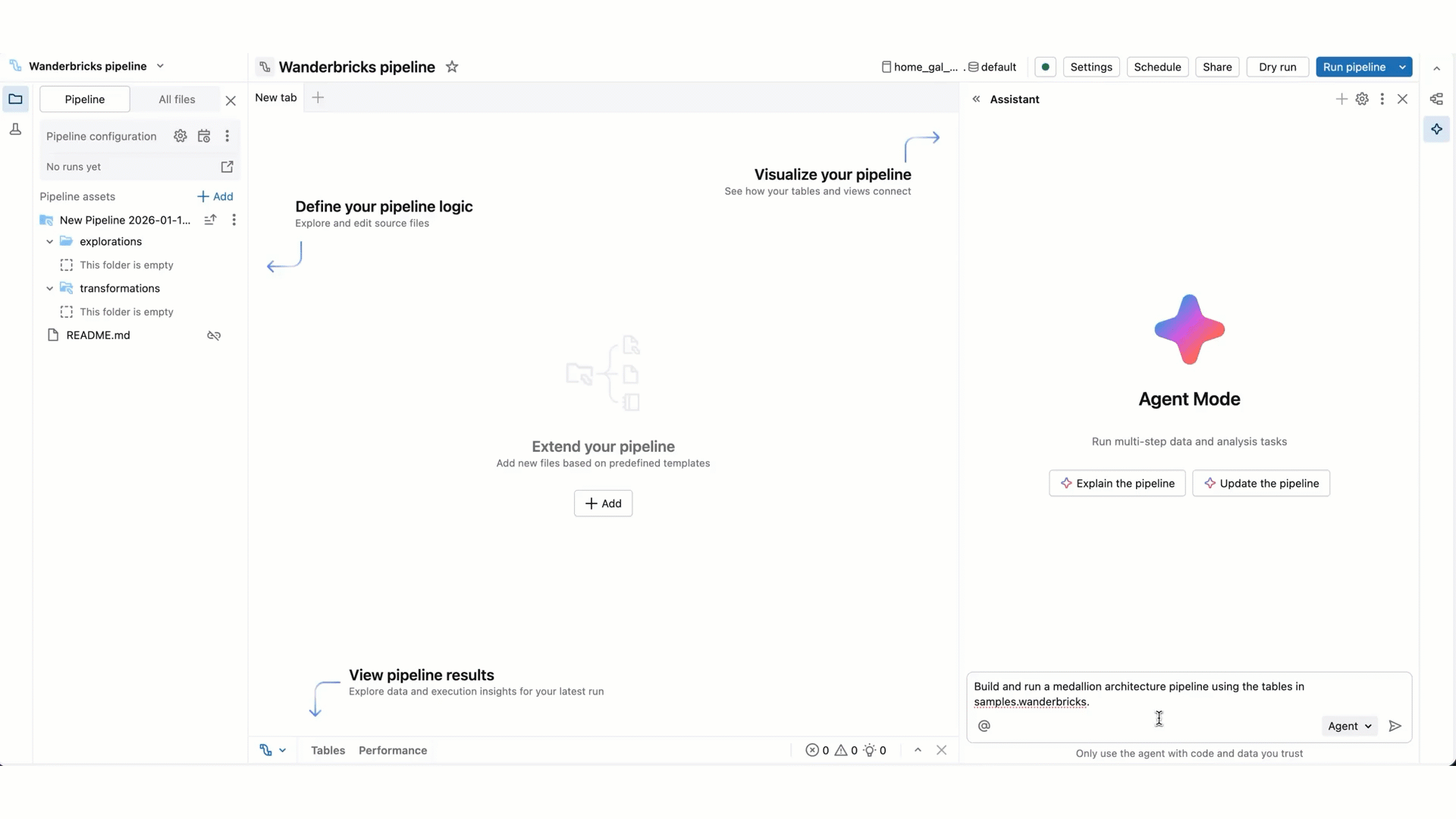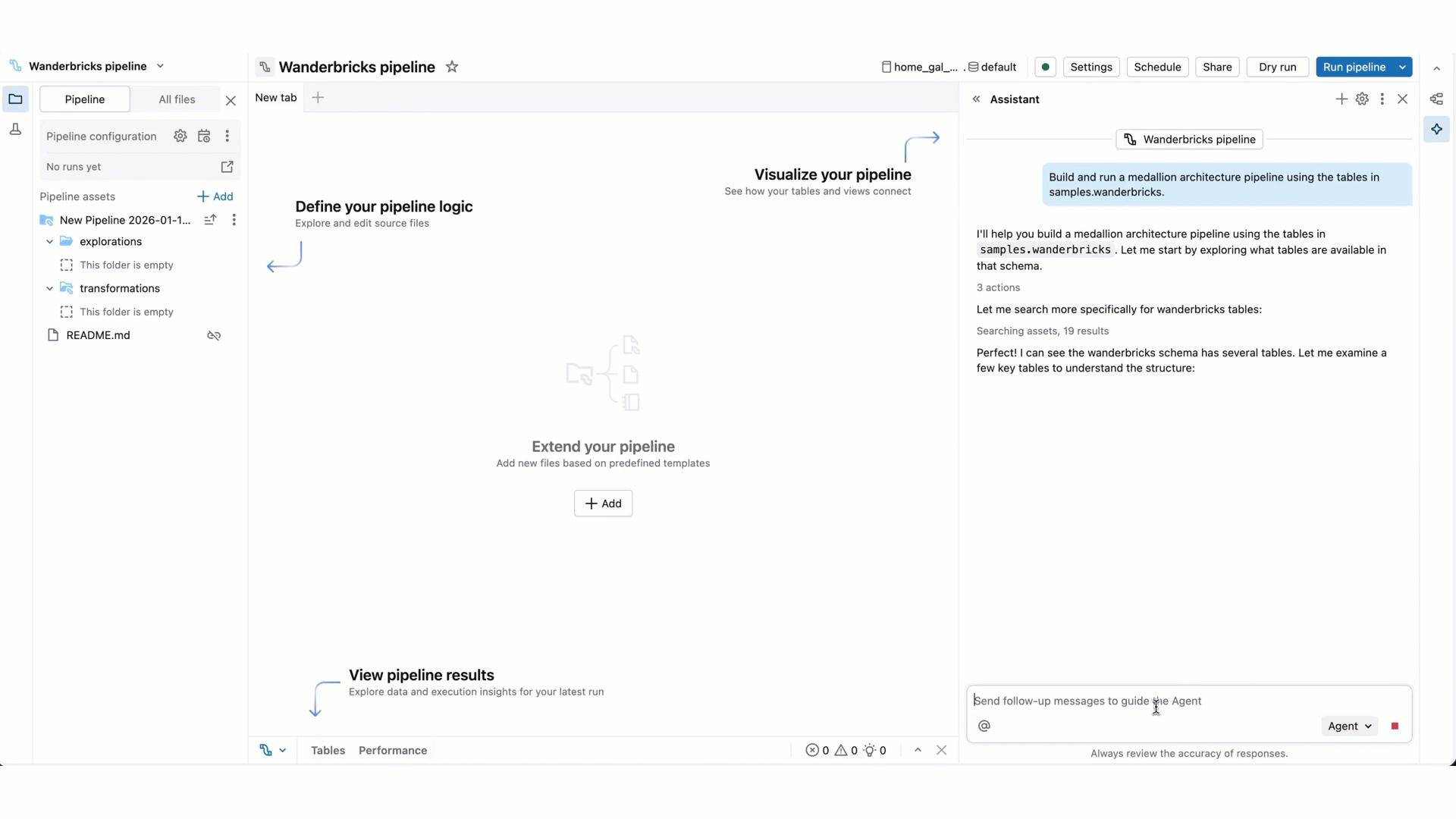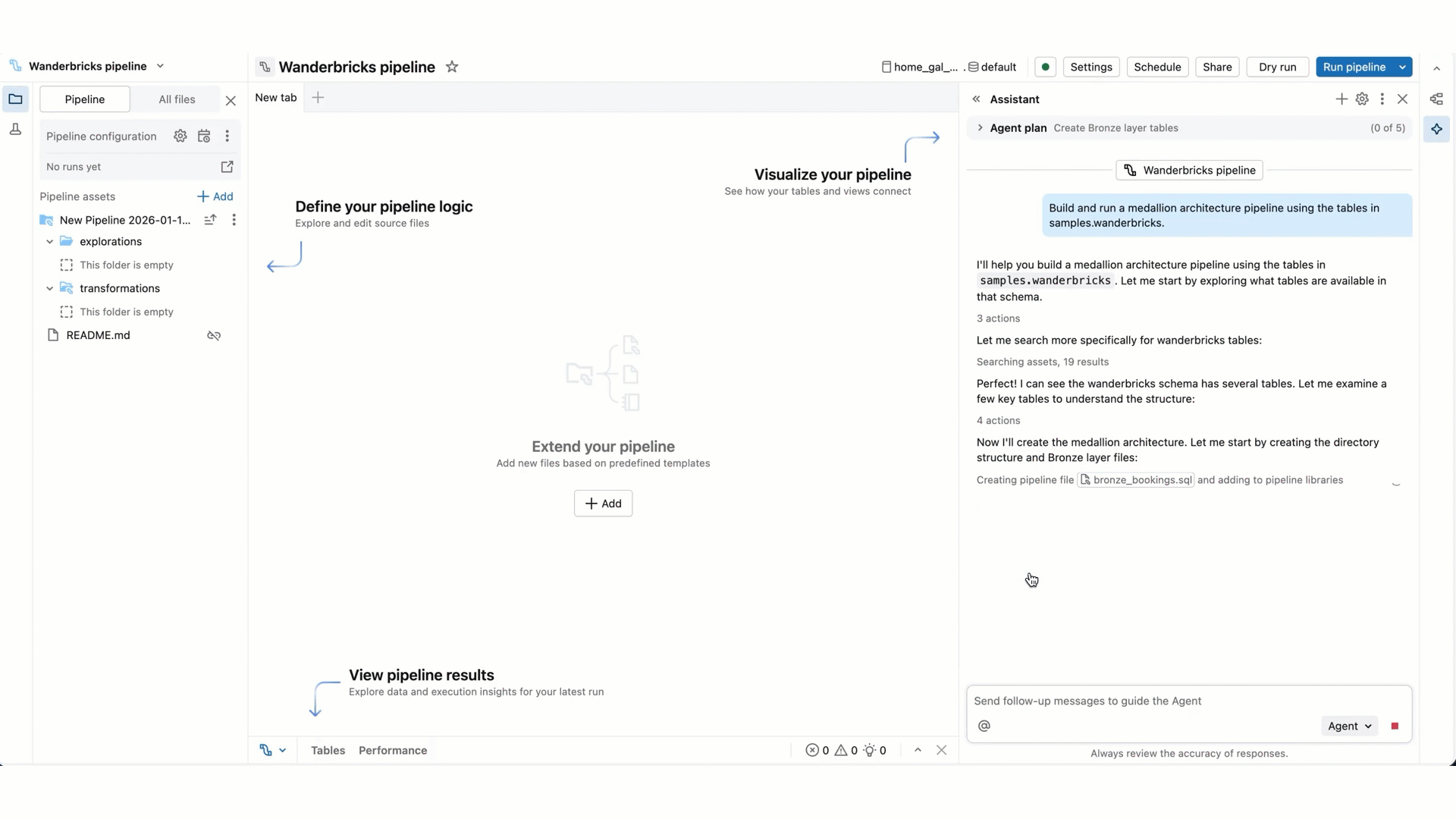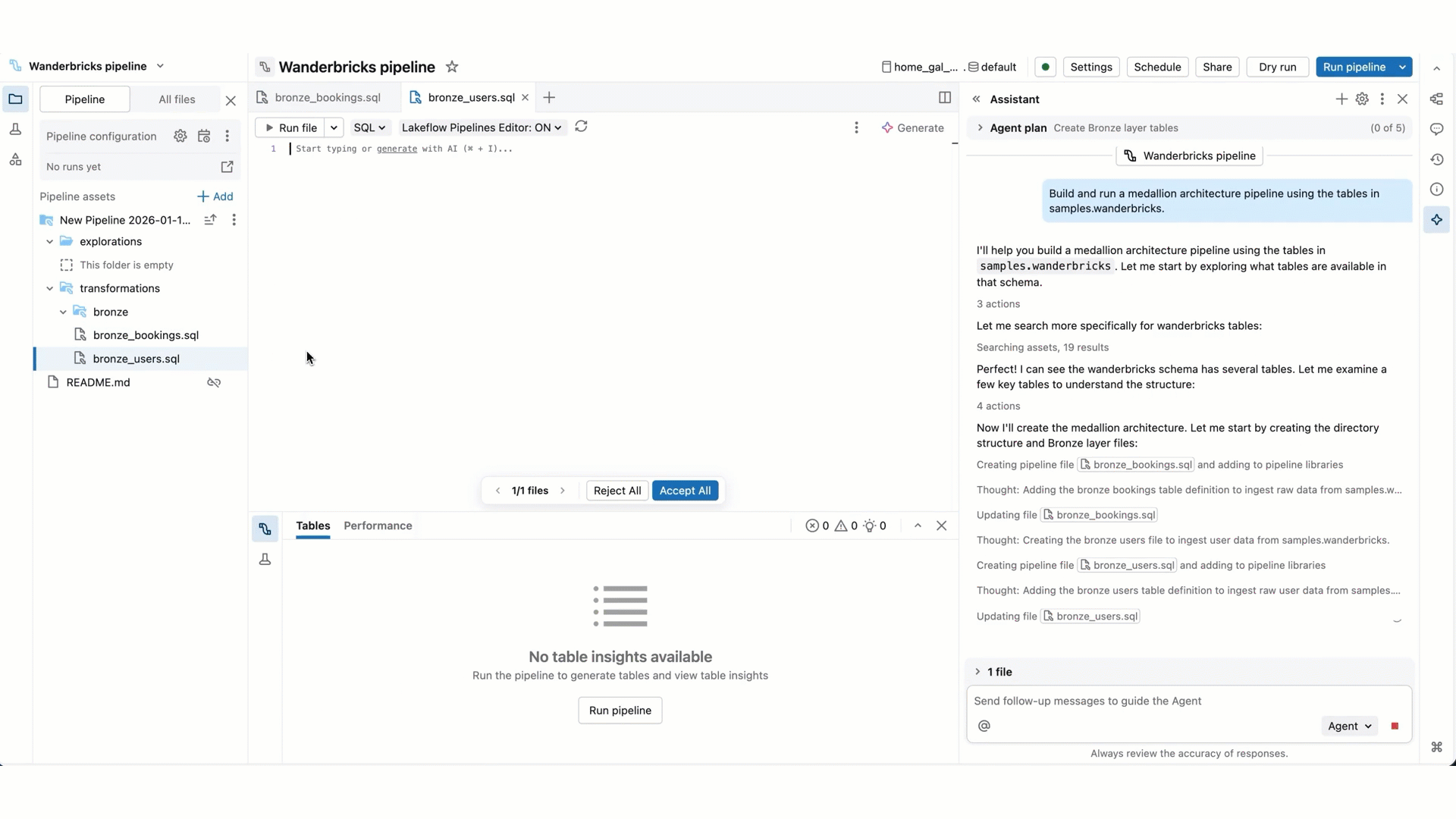
Par rapport au mode conversation de Génie Code, le mode Agent offre des fonctionnalités étendues : planification d’une solution, récupération des ressources pertinentes, exécution de code, utilisation de sorties de pipeline pour améliorer les résultats, correction automatique des erreurs et bien plus encore.
Le code Genie en mode Agent peut planifier et générer des pipelines entiers de bout en bout à partir de zéro, ou accélérer le travail sur un pipeline existant. L’agent travaille avec vous pour approuver ses plans et confirmer ses prochaines étapes avant de continuer. Avec votre approbation, Genie Code peut utiliser des outils pour effectuer des tâches telles que la recherche de tables, la modification d’un fichier SQL ou Python fichier source, l’exécution des mises à jour de pipeline et la lecture des jeux de données de pipeline.
L’accès et les actions de Genie Code sont régies par les autorisations de l’utilisateur. Il peut uniquement accéder aux données auxquelles vous avez accès et effectuer des opérations pour lesquelles vous disposez d’autorisations.
Note
Lorsque vous activez le mode Agent dans Genie Code, Genie Code adapte ses fonctionnalités en fonction des fonctionnalités que vous utilisez actuellement dans Databricks. Par exemple, dans l’éditeur de pipelines Lakeflow, Genie Code se concentre sur les tâches d’édition de pipeline et d’ingénierie des données. Dans les notebooks et l'éditeur SQL, Genie Code facilite l'exploration et l'analyse des données. Pour plus d’informations, consultez Utiliser Genie Code pour la science des données .
Spécifications
Pour utiliser Genie Code pour l’ingénierie des données, votre espace de travail a besoin des éléments suivants :
- Les fonctionnalités d'IA propulsées par des partenaires sont activées pour le compte et l'espace de travail. Consultez les fonctionnalités d’IA optimisées par les partenaires.
- Votre espace de travail doit se trouver dans une région prise en charge. Genie Code est un service désigné qui utilise Geos pour gérer la résidence des données. Consultez la disponibilité géographique des fonctionnalités de Genie Code.
Utiliser Genie Code pour le développement de pipelines
Pour utiliser les fonctionnalités agentiques de Genie Code pour le développement de pipelines :
À partir de l’Éditeur de pipelines Lakeflow, ouvrez le volet latéral
 Avatar assistant icon.Code Génie en cliquant sur dans le coin supérieur droit de votre espace de travail.
Avatar assistant icon.Code Génie en cliquant sur dans le coin supérieur droit de votre espace de travail.Dans le coin inférieur droit, sélectionnez Agent. Cela bascule sur le mode Agent de Genie Code, ce qui vous permet d’obtenir les fonctionnalités d’ingénierie des données agentiques de Genie Code.
Entrez une invite de code Genie. Par exemple, vous pouvez lui poser des questions sur votre pipeline, par exemple « décrire ce pipeline ». Vous pouvez également lui demander d’ajouter de nouveaux jeux de données, par exemple « créer des silver_sales_data dans un nouveau fichier qui lit à partir de bronze_sales_data et nettoie les données et ajoute des attentes de qualité utiles ».
Note
Genie Code respecte les autorisations du catalogue Unity de l’utilisateur. Il peut donc accéder uniquement aux données et à la source de pipeline auxquelles vous avez accès.
À mesure que Genie Code génère sa réponse, il s’interrompt souvent pour obtenir votre entrée :
Pour des tâches plus complexes, Genie Code peut créer un plan pas à pas et poser des questions de clarification. Répondez à ses questions de clarification pour l’aider à affiner son plan.
Lorsque Genie Code doit exécuter du code ou mettre à jour un pipeline, il demande votre approbation avant de continuer. Autoriser ou refuser sa demande. Vous pouvez également sélectionner Autoriser dans ce thread (faisant référence au thread de conversation Genie Code) ou Toujours autoriser.
Important
Le code Genie en mode Agent peut générer et exécuter du code dans votre pipeline. Bien qu’il ait des garde-fous pour empêcher les actions dangereuses, il y a encore des risques. Vous devez uniquement l’utiliser avec des données approuvées, et vous devez passer en revue le code avant de l’exécuter.
À mesure que Genie Code poursuit son travail, vous pouvez être invité à sélectionner Continuer ou Rejeter. Passez en revue son travail existant, puis sélectionnez Continuer pour lui permettre de passer à ses étapes suivantes ou Rejeter pour lui indiquer d’essayer autre chose.
Pour arrêter le code Genie pendant qu’il fonctionne, cliquez sur

Genie Code peut créer de nouveaux fichiers, générer du texte, des requêtes et du code, exécuter les fichiers ou pipelines et accéder aux jeux de données de sortie pour interpréter les résultats.
Note
Pour que Genie Code poursuive son travail et effectuez les étapes suivantes, vous devez rester sur l’onglet actuel dans lequel il fonctionne.
Conseil / Astuce
Vous pouvez ajouter des instructions pour le code Genie à utiliser dans la plupart des réponses. Par exemple, si vous avez des conventions de code que vous souhaitez utiliser ou des bibliothèques préférées à utiliser, vous pouvez ajouter ces instructions à des instructions pour Génie Code. Vous pouvez également créer des compétences pour étendre Genie Code avec des fonctionnalités spécialisées pour vos tâches spécifiques au domaine. Pour plus d’informations et d’autres conseils, consultez Conseils pour améliorer les réponses au code Génie.
Capacités
En mode Agent, Genie Code peut vous aider à effectuer la plupart des tâches de développement de pipeline. Les fonctionnalités clés sont les suivantes :
- Découverte des données : Genie Code peut rechercher des tables dans l’espace de travail pour vous aider à trouver les données requises pour une tâche.
- Modifications de code de pipeline : Genie Code peut créer et modifier plusieurs fichiers à la fois. Il vous informe des fichiers qu’il modifie et affiche le différences de code dans chaque fichier. Vous pouvez donc passer en revue les modifications individuellement ou toutes ensemble à la fin.
- Exécution du pipeline : Genie Code peut exécuter des fichiers individuels, effectuer un dry-run/exécuter le pipeline, ou réaliser une actualisation complète. Lorsque Genie Code veut continuer, il demande votre confirmation avant de le faire.
- Comprendre et améliorer le comportement du pipeline : Genie Code peut inspecter les jeux de données et les sorties de pipeline pour vous aider à comprendre ce qu’un pipeline fait de bout en bout et pourquoi. Par exemple, il peut résumer les transformations, tracer la façon dont les données circulent dans des tables en aval et mettre en évidence des modifications inattendues dans les nombres de lignes ou les schémas. Lorsqu'il met en lumière des problèmes potentiels de qualité des données, Genie Code peut vous aider à analyser leurs causes et à suggérer où et comment les résoudre dans le pipeline.
Ces fonctionnalités prennent en charge les cas d’usage courants tels que :
- Création d’un nouveau pipeline : Genie Code peut vous aider à créer un pipeline d’architecture de médaillon, de l’ingestion de données, à la normalisation et au nettoyage des données, à la transformation et à l’analyse des données.
- Expliquer un pipeline : Genie Code peut analyser et expliquer un pipeline existant pour vous aider à monter rapidement en puissance.
- Résoudre les problèmes : lorsque vous rencontrez des erreurs, Genie Code peut vous aider à diagnostiquer et résoudre les problèmes, en effectuant une itération dans plusieurs fichiers jusqu’à ce que le problème soit résolu.
Examples
Essayez les suggestions suivantes pour commencer :
- « Créez et exécutez un pipeline d’architecture de médaillon pour la détection des fraudes à l’aide des tables transactions et customers dans my_catalog.my_schema. »
- Expliquez chaque étape de ce pipeline.
- Corrigez la défaillance de ce pipeline.
Étapes suivantes
- En savoir plus sur les fonctionnalités d’assistance à l’IA Databricks
- Obtenez des conseils pour améliorer les réponses de Génie Code
- Utiliser le code Genie pour la science des données, pour la découverte et l’exploration des données
- Utiliser Le code Genie pour la création de tableaux de bord
- Explorer l’éditeur de pipelines Lakeflow