Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Une table de diffusion en continu est une table Delta qui prend en charge la diffusion en continu ou le traitement incrémentiel des données. Une table de streaming peut être ciblée par un ou plusieurs flux dans un pipeline.
Les tables de diffusion en continu constituent un bon choix pour l’ingestion des données pour les raisons suivantes :
- Chaque ligne d'entrée est traitée une seule fois, ce qui correspond à la grande majorité des charges de travail d'ingestion (c'est-à-dire, en ajoutant ou en mettant à jour des lignes dans une table).
- Elles peuvent gérer de grands volumes de données d’ajout uniquement.
Les tables de streaming sont également un bon choix pour les transformations de diffusion en continu à faible latence, car elles peuvent raisonner sur les lignes et les fenêtres de temps, gérer des volumes élevés de données et fournir un traitement à faible latence.
Le diagramme suivant montre comment les flux lisent à partir de sources de diffusion en continu et écrivent de façon incrémentielle dans une table de diffusion en continu au sein d’un pipeline.
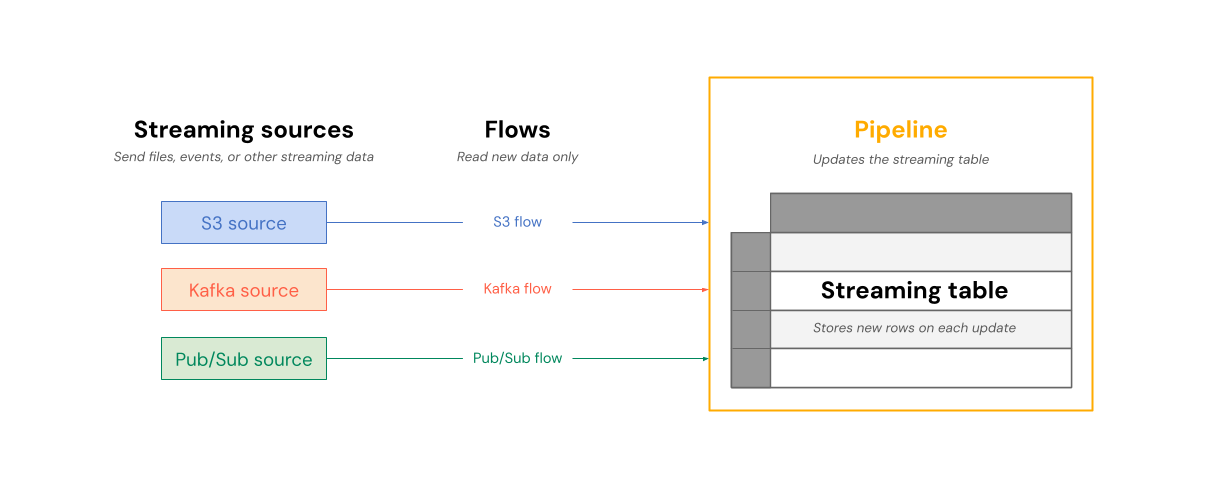
Sur chaque mise à jour, les flux associés à une table streaming lisent les informations modifiées dans une source de diffusion en continu et ajoutent de nouvelles informations à cette table.
Les tables de streaming sont détenues et mises à jour par un seul pipeline. Vous définissez des tables de flux explicitement dans le code source du pipeline. Les tables définies par un pipeline ne peuvent pas être modifiées ou mises à jour par un autre pipeline. Vous pouvez définir plusieurs flux à ajouter à une table de diffusion en continu unique.
Azure Databricks crée des tables internes pour prendre en charge le traitement des tables de streaming. Ces tableaux s’affichent dans system.information_schema.tables, mais ne sont pas visibles dans l’Explorateur de catalogue ou dans d’autres pages d’interface utilisateur d’espace de travail.
Note
Lorsque vous créez une table de diffusion en continu en dehors d’un pipeline à l’aide de Databricks SQL, Azure Databricks crée un pipeline utilisé pour mettre à jour la table. Vous pouvez voir le pipeline en sélectionnant Tâches & Pipelines dans le volet de navigation à gauche de votre espace de travail. Vous pouvez ajouter la colonne de type pipeline à votre affichage. Les tables de streaming définies dans un pipeline ont un type ETL. Les tables de diffusion en continu créées dans Databricks SQL ont un type MV/ST.
Pour plus d’informations sur les flux, consultez Charger et traiter des données de manière incrémentielle avec les flux de pipelines déclaratifs Spark Lakeflow.
Tables de streaming pour l'ingestion
Les tables de streaming sont conçues pour les sources de données à ajout unique et traitent les données une seule fois. Cela les rend bien adaptés aux charges de travail d’ingestion où les données arrivent en continu et doivent être capturées de manière fiable sans retraiter les enregistrements existants. Azure Databricks prend en charge l’ingestion de données à partir de stockage cloud et de bus de messages en continu.
Ingérer des fichiers à partir du stockage cloud
Vous pouvez utiliser une table de diffusion en continu pour ingérer de nouveaux fichiers à partir du stockage cloud. Ces exemples utilisent le chargeur automatique pour traiter de façon incrémentielle les nouveaux fichiers à mesure qu’ils arrivent.
Python
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Pour créer une table streaming, la définition du jeu de données doit être un type de flux. Lorsque vous utilisez la spark.readStream fonction dans une définition de jeu de données, elle retourne un jeu de données de streaming.
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Les tables de streaming nécessitent des jeux de données de streaming. Le STREAM mot clé avant read_files indique à la requête de traiter le jeu de données en tant que flux.
Ingérer des messages de diffusion en continu
Vous pouvez également utiliser des tables de streaming pour ingérer des données à partir de bus de messages. L’exemple suivant montre comment créer une table de diffusion en continu qui lit à partir d’une rubrique Pub/Sub.
Python
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks recommande d’utiliser des secrets lors de la définition des options d’autorisation. Consultez Configurer l’accès à Pub/Sub pour toutes les options d’authentification.
Pour plus d’informations sur le chargement de données dans la table de diffusion en continu, consultez Charger des données dans des pipelines.
Le diagramme suivant illustre le fonctionnement des tables de diffusion en continu d’ajout uniquement.
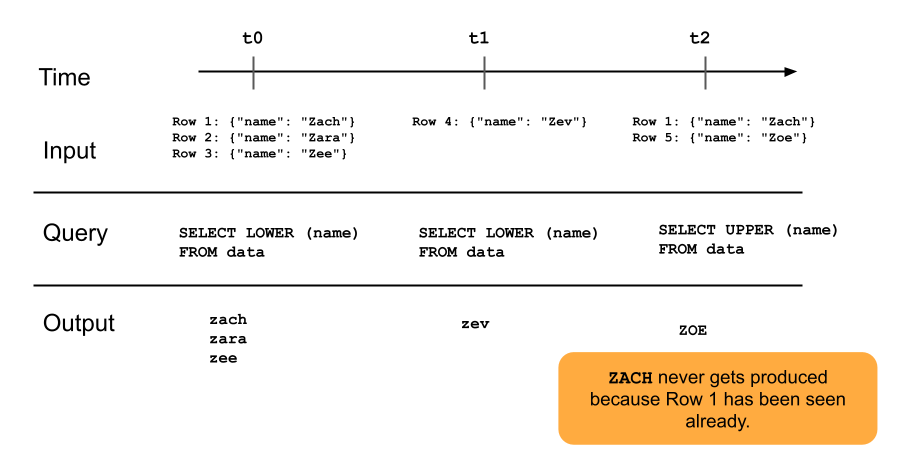
Une ligne qui a déjà été ajoutée à une table en streaming ne sera pas réinterrogée avec les mises à jour ultérieures du pipeline. Si vous modifiez la requête (par exemple, de SELECT LOWER (name) à SELECT UPPER (name)), les lignes existantes ne sont pas mises à jour en majuscules, mais les nouvelles lignes seront en majuscules. Vous pouvez déclencher une actualisation complète pour requêter à nouveau toutes les données précédentes de la table source afin de mettre à jour toutes les lignes de la table de streaming.
Tables de streaming et diffusion à faible latence
Les tables de diffusion en continu sont conçues pour une diffusion en continu à faible latence via un état limité. Les tables de diffusion en continu utilisent la gestion des points de contrôle, ce qui les rend bien adaptées à la diffusion en continu à faible latence. Toutefois, elles attendent des flux qui sont naturellement délimités ou délimités avec un filigrane.
Un flux naturellement limité est produit par une source de données de diffusion en continu qui a un début et une fin bien définis. Un exemple de flux naturellement limité lit les données à partir d’un répertoire de fichiers où aucun nouveau fichier n’est ajouté après un lot initial de fichiers placé. Le flux est considéré comme limité, car le nombre de fichiers est fini et le flux se termine une fois que tous les fichiers ont été traités.
Vous pouvez également utiliser un filigrane pour lier un flux. Un filigrane dans Structured Streaming est un mécanisme qui permet de gérer les données tardives en spécifiant la durée pendant laquelle le système doit attendre les événements retardés avant de considérer la fenêtre de temps comme terminée. Un flux non limité qui n’a pas de marqueur peut entraîner l’échec d’un pipeline en raison de la pression de la mémoire.
Pour plus d’informations sur le traitement de flux avec état, consultez Optimiser le traitement de flux avec état grâce aux filigranes.
Jointures d’instantané de flux
Les jointures de flux instantané connectent un jeu de données de streaming à une table de dimension qui est figée au début du flux. Étant donné que la table de dimension est traitée comme fixe à ce stade dans le temps, toutes les modifications apportées après le démarrage du flux ne sont pas reflétées dans la jointure. Cela est acceptable lorsque de petites différences n’ont pas d’importance, par exemple, lorsque le nombre de transactions est de plusieurs ordres de grandeur supérieur au nombre de clients.
L’exemple de code suivant joint une table de dimension avec deux lignes appelées customers avec un jeu de données toujours croissant, transactions. Il matérialise une jointure entre ces deux jeux de données dans une table appelée sales_report. Si un processus externe met à jour la table clients en ajoutant une nouvelle ligne (customer_id=3, name=Zoya), cette nouvelle ligne ne sera pas présente dans la jointure, puisque la table de dimension statique a été enregistrée au moment où les flux ont démarré.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
Limitations de la table de diffusion en continu
Les tables de diffusion en continu présentent les limitations suivantes :
-
Évolution limitée : Vous pouvez modifier la requête sans recomputer l’ensemble du jeu de données. Sans actualisation complète, une table streaming ne voit chaque ligne qu’une seule fois, de sorte que différentes requêtes auront traité différentes lignes. Par exemple, si vous ajoutez
UPPER()un champ dans la requête, seules les lignes traitées après la modification seront en majuscules. Cela signifie que vous devez connaître toutes les versions précédentes de la requête qui s’exécutent sur votre jeu de données. Pour retraiter les lignes existantes qui ont été traitées avant la modification, une actualisation complète est requise. - Gestion de l’état : Les tables en streaming sont à basse latence et nécessitent des flux naturellement délimités ou délimités avec un filigrane. Pour plus d’informations, consultez Optimiser le traitement d'état à l'aide de filigranes.
- Les jointures ne sont pas recalculées : Les jointures dans les tables de flux ne sont pas recalculées quand les dimensions changent. Cette caractéristique peut être adaptée aux scénarios « rapides mais incorrects ». Si vous souhaitez que votre vue soit toujours correcte, vous pouvez utiliser une vue matérialisée. Les vues matérialisées sont toujours correctes, car elles recompilent automatiquement les jointures lorsque les dimensions changent. Pour plus d’informations, consultez Vues matérialisées.