Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
La version Lakebase Autoscaling est la dernière de Lakebase, avec l'évolutivité automatique, la mise à l’échelle jusqu'à zéro, la création de branches et la restauration instantanée. Pour connaître les régions prises en charge, consultez disponibilité de la région. Si vous êtes un utilisateur Lakebase Provisionné, consultez Lakebase Provisioned.
À la fin de ce guide, vous disposez d’une base de données Postgres en cours d’exécution avec des exemples de données, connectés au catalogue Unity, avec des données qui circulent entre Lakebase et Databricks lakehouse.
Étapes : (1) Créer un projet → (2) Connecter → (3) Créer une table → (4) Inscrire dans le catalogue Unity → (5) Servir des données
Étape 1 : Créer votre premier projet
Ouvrez l’application Lakebase à partir du sélecteur d’applications.
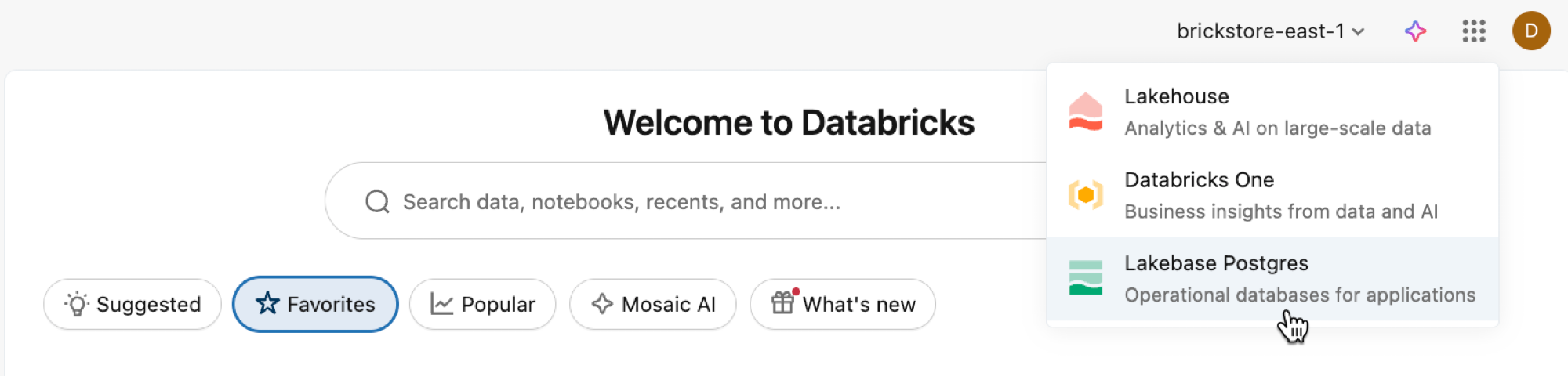
Sélectionnez Mise à l’échelle automatique pour accéder à l’interface utilisateur de mise à l’échelle automatique Lakebase.
Cliquez sur Nouveau projet. Donnez un nom à votre projet et sélectionnez votre version de Postgres. Votre projet est créé avec une branche unique production , une base de données par défaut databricks_postgres et des ressources de calcul configurées pour la branche.
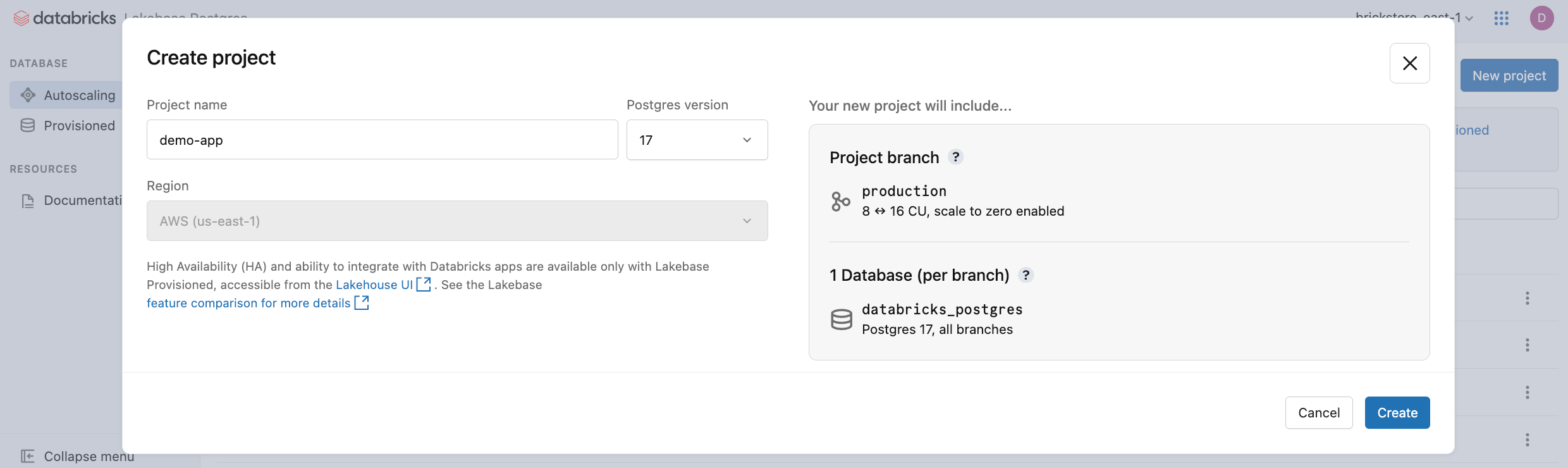
L’activation de votre calcul peut prendre quelques instants. Le calcul de la production branche est toujours activé par défaut (la mise à l’échelle à zéro est désactivée), mais vous pouvez configurer ce paramètre si nécessaire.
La région de votre projet est automatiquement définie sur votre région d’espace de travail.
En savoir plus : Créer un projet | Autoscaling | Mettre à l'échelle vers zéro
Étape 2 : Se connecter à votre base de données
Dans votre projet, sélectionnez la branche de production , puis cliquez sur Se connecter. Les chaînes de connexion fonctionnent avec n’importe quel client Postgres standard (psql, pgAdmin, DBeaver ou frameworks d’application).
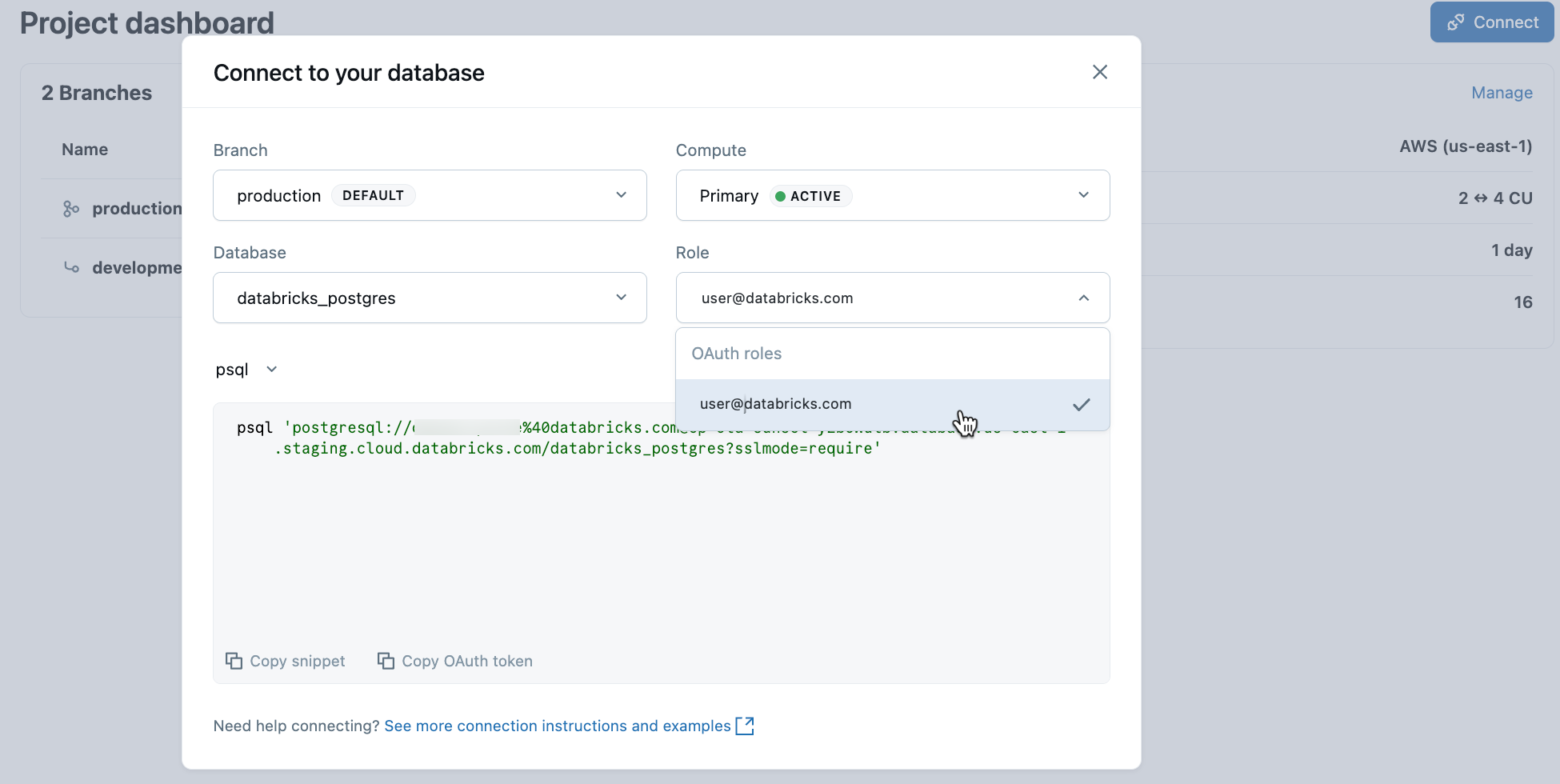
Pour vous connecter à votre identité Databricks, copiez l’extrait psql de code à partir de la boîte de dialogue de connexion et collez le jeton OAuth lorsque vous y êtes invité :
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
En savoir plus : Démarrage rapide de la connexion | | |
Étape 3 : Créer votre première table
L'éditeur SQL Lakebase est préinstallé avec des exemples SQL. Dans votre projet, sélectionnez la branche de production , ouvrez l’éditeur SQL et exécutez les instructions fournies pour créer une table et insérer des playing_with_lakebase exemples de données.
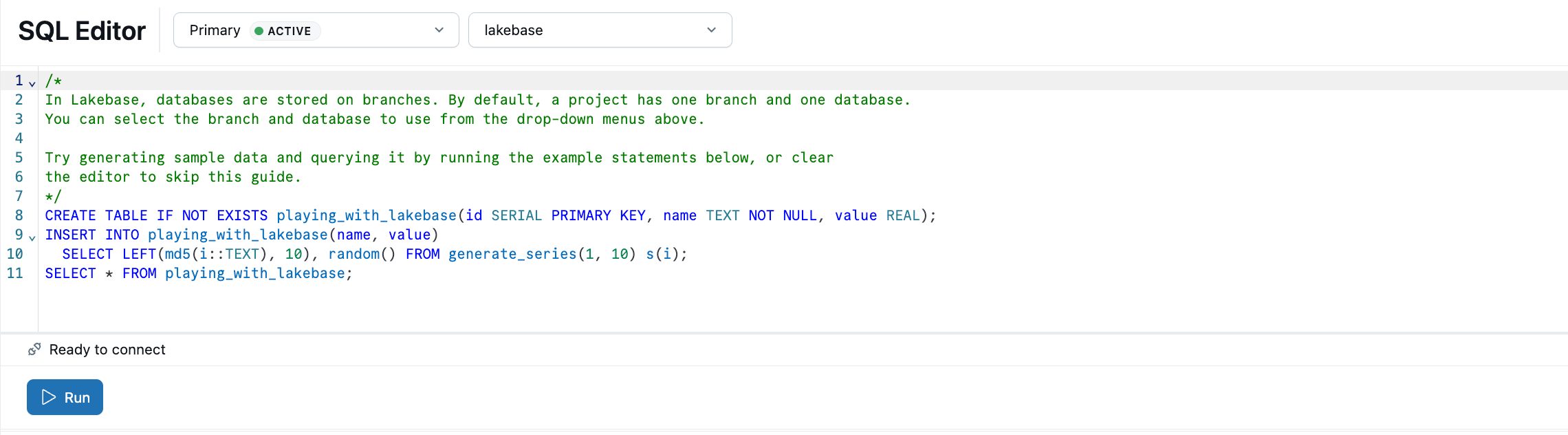
En savoir plus : Éditeur SQL | Éditeur de tables | Clients Postgres
Étape 4 : Inscrire dans le catalogue Unity
Votre base de données Lakebase est en cours d’exécution, mais elle est invisible pour le reste de la plateforme Databricks jusqu’à ce que vous l’inscrivez dans le catalogue Unity. Une fois inscrit, vous pouvez interroger des tables Lakebase à partir de Databricks SQL, joindre des données opérationnelles à l’analytique lakehouse et appliquer une gouvernance unifiée.
Dans l’Explorateur de catalogues, créez un nouveau catalogue avec Lakebase Autoscaling en tant que type, en pointant vers la branche production et la base de données databricks_postgres de votre projet.
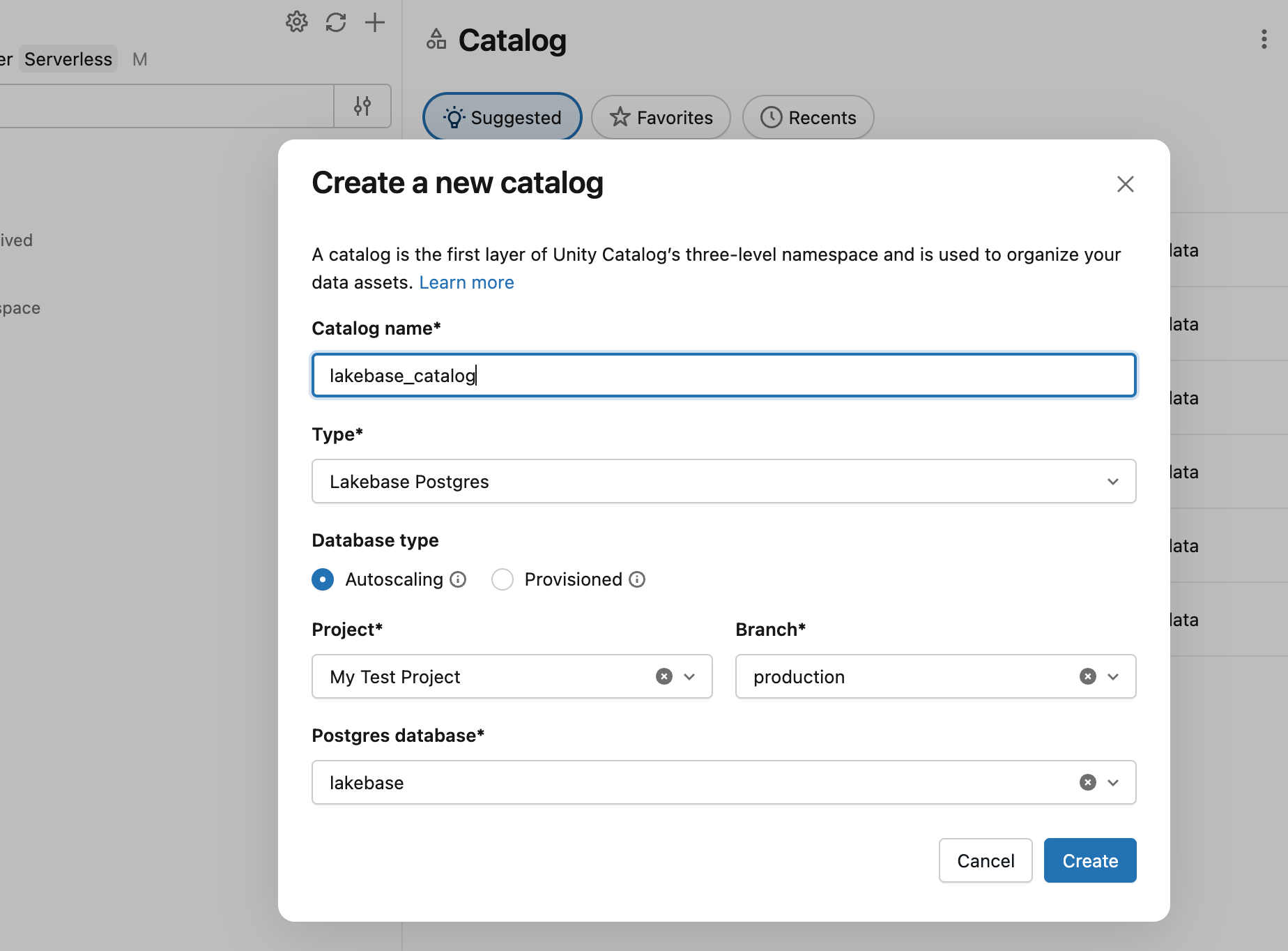
Vous pouvez maintenant interroger à partir d’un entrepôt SQL :
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
En savoir plus : Inscrire dans le catalogue Unity
Étape 5 : Servir les données lakehouse dans votre application
Les tables synchronisées apportent des données analytiques de Unity Catalog dans votre base de données Lakebase afin que les applications puissent l’interroger avec des lectures transactionnelles à faible latence. Créez un exemple de table catalogue Unity, puis synchronisez-la avec Lakebase.
Dans un entrepôt SQL ou un notebook, créez une table source :
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Synchronisez maintenant cette table dans Lakebase. Dans l’Explorateur de catalogues, créez une table synchronisée à partir de user_segments en mode Instantané, ciblant la base de données de votre projet databricks_postgres. Le mode instantané copie les données une seule fois. Pour les mises à jour continues, utilisez le mode déclenché ou continu.
Une fois la synchronisation terminée, les données sont disponibles dans Lakebase en tant que default.user_segments_synced. Interrogez-le dans l’éditeur SQL Lakebase :
SELECT * FROM "default".user_segments_synced WHERE engagement = 'high';
Note
default doit être cité, car il s’agit d’un mot clé réservé PostgreSQL. Le schéma de table synchronisé hérite du nom du schéma du catalogue Unity. Par conséquent, si votre schéma est nommé default, vous devez toujours le citer dans les requêtes. Les guillemets autour d’autres identificateurs sont facultatifs.
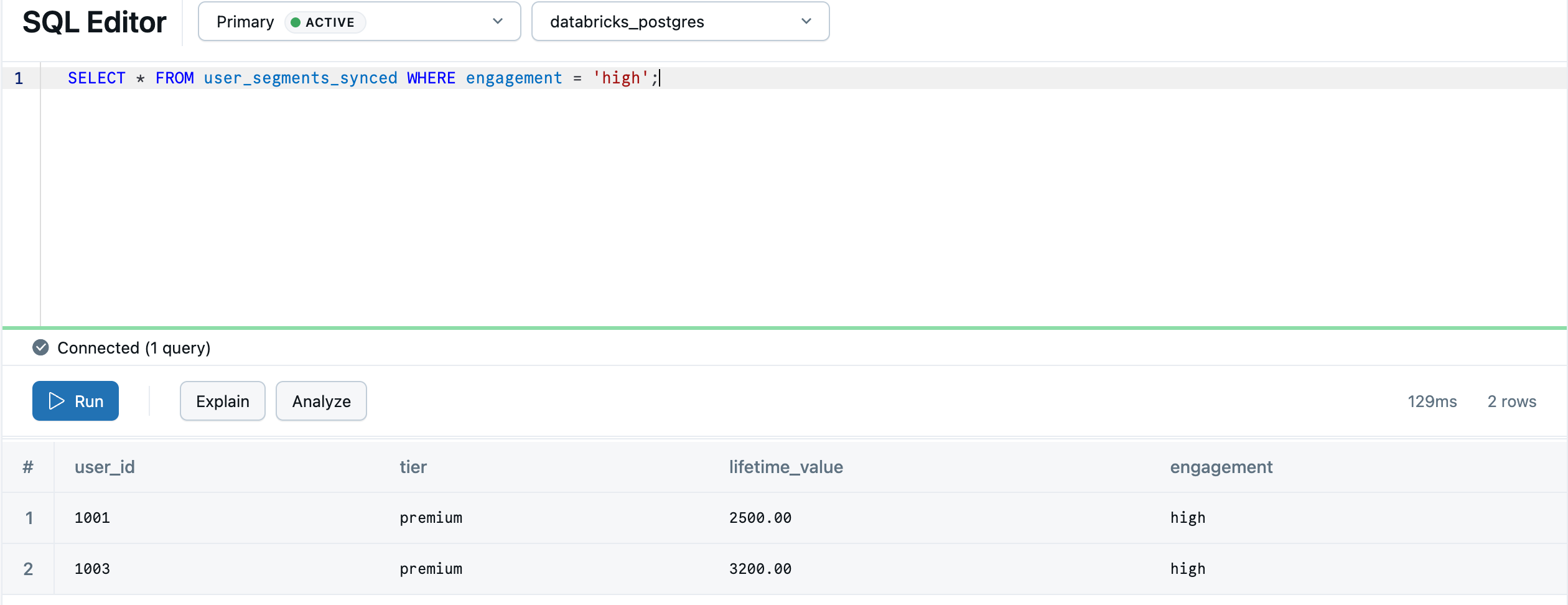
Votre analytique lakehouse est maintenant prête à servir à partir de votre base de données transactionnelle.
En savoir plus : Tables synchronisées | Modes de synchronisation | Mappage des types de données
Étapes suivantes
- Créer une application :Databricks Apps didacticiel | Applications externes
- Développer avec des branches :Didacticiel de développement basé sur des branches
- Mettez en place votre équipe :Accordez l’accès aux projets et aux bases de données
- Explorer la plateforme :Core concepts | Projects overview | All tutorials