Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Avec la fédération des requêtes, les requêtes sont envoyées à la base de données étrangère à l’aide d’API JDBC. La requête est exécutée à la fois dans Databricks et à l’aide du calcul distant. La fédération de requêtes est utilisée pour les sources telles que MySQL, PostgreSQL, Redshift, Teradata, etc.
Pourquoi utiliser Lakehouse Federation ?
La lakehouse met l’accent sur le stockage central des données afin de réduire la redondance et l’isolation des données. Votre organisation peut avoir de nombreux systèmes de données en production et vous souhaiterez peut-être interroger des données dans des systèmes connectés pour plusieurs raisons :
- Rapports à la demande.
- Travail de preuve de concept.
- Phase exploratoire des nouveaux pipelines ou rapports ETL.
- Prise en charge de charges de travail pendant une migration incrémentielle.
Dans chacun de ces scénarios, la fédération de requêtes vous permet dé bénéficier d’insights plus rapidement, car vous pouvez interroger les données en place et éviter un traitement ETL complexe et chronophage.
La fédération de requêtes est destinée aux cas d’usage spécifiques lorsque :
- Vous ne souhaitez pas ingérer des données dans Azure Databricks.
- Vous souhaitez que vos requêtes tirent parti du calcul dans le système de base de données externe.
- Vous souhaitez bénéficier des avantages de la gouvernance des interfaces et des données Unity Catalog, notamment le contrôle d’accès affiné, la traçabilité des données et la recherche.
Fédération des requêtes et Lakeflow Connect
La fédération de requêtes vous permet d’interroger des sources de données externes sans déplacer vos données. Databricks recommande l’ingestion à l’aide de connecteurs managés Lakeflow Connect, car ils sont mis à l’échelle pour prendre en charge des volumes de données élevés et une latence de requête inférieure. Cependant, vous souhaiterez peut-être interroger vos données sans les déplacer. Lorsque vous avez un choix entre les connecteurs d’ingestion managés et la fédération de requête, choisissez la fédération de requête pour les rapports ad hoc ou le travail de preuve de concept sur vos pipelines ETL.
Si votre source la prend en charge, les connecteurs d’ingestion basés sur des requêtes constituent une alternative légère à Lakeflow Connect par rapport aux connecteurs CDC. Ils interrogent directement la source selon une planification à l’aide d’une colonne de curseur, sans nécessiter de passerelle ou de stockage intermédiaire. Utilisez des connecteurs d’ingestion basés sur des requêtes lorsque vous avez besoin d’une ingestion périodique, mais que l’infrastructure CDC n’est pas disponible.
Vue d’ensemble de la configuration de la fédération des requêtes
Pour rendre un jeu de données disponible à des fins d’interrogation en lecture seule à l’aide de Lakehouse Federation, vous créez les éléments suivants :
- Connexion, objet sécurisable dans le catalogue Unity qui spécifie un chemin d’accès et des informations d’identification pour accéder à un système de base de données externe.
- Un catalogue étranger, objet sécurisable dans le catalogue Unity qui reflète une base de données dans un système de données externe, vous permettant d’effectuer des requêtes en lecture seule sur ce système de données dans votre espace de travail Azure Databricks, en gérant l’accès à l’aide du catalogue Unity.
Sources de données prises en charge
La fédération de requêtes prend en charge les connexions aux sources suivantes :
- MySQL
- PostgreSQL
- Teradata
- Oracle
- Amazon Redshift
- Données Salesforce 360
- Snowflake
- Microsoft SQL Server
- Azure Synapse (SQL Data Warehouse)
- Google BigQuery
- Databricks
Configuration requise pour la connexion
Conditions requises pour l’espace de travail :
- Espace de travail activé pour Unity Catalog. Les espaces de travail créés après le 9 novembre 2023 sont activés automatiquement pour unity Catalog, y compris le provisionnement automatique du metastore. Vous n’avez pas besoin de créer manuellement un metastore, sauf si votre espace de travail précède l’activation automatique et n’a pas été activé pour le catalogue Unity. Consultez l’article Activation automatique de Unity Catalog.
Voici les exigences de calcul à respecter :
- Connectivité réseau de votre ressource de calcul aux systèmes de base de données cibles. Consultez l’article Recommandations de mise en réseau pour Lakehouse Federation.
- Azure Databricks calcul doit utiliser Databricks Runtime 13.3 LTS ou ultérieur et Standard ou Dedicated mode d’accès.
- Les entrepôts SQL doivent être pro ou serverless et doivent utiliser la version 2023.40 ou ultérieure.
Autorisations requises :
- Pour créer une connexion, vous devez être un administrateur de metastore ou un utilisateur disposant du privilège
CREATE CONNECTIONsur le metastore Unity Catalog attaché à l’espace de travail. Dans les espaces de travail activés automatiquement pour le catalogue Unity, les administrateurs de l’espace de travail ont leCREATE CONNECTIONprivilège par défaut. - Pour créer un catalogue étranger, vous devez disposer de l’autorisation
CREATE CATALOGsur le metastore et être le propriétaire de la connexion ou disposer du privilègeCREATE FOREIGN CATALOGsur la connexion. Dans les espaces de travail activés automatiquement pour le catalogue Unity, les administrateurs de l’espace de travail ont leCREATE CATALOGprivilège par défaut.
Des exigences d’autorisation supplémentaires sont spécifiées dans chaque section basée sur les tâches qui suit.
Créer une connexion
Une connexion spécifie un chemin d’accès et des informations d’identification pour accéder à un système de base de données externe. Pour créer une connexion, vous pouvez utiliser l'Explorateur de catalogue ou la commande CREATE CONNECTION SQL dans un notebook Azure Databricks ou l'éditeur de requête Databricks SQL.
Note
Vous pouvez également utiliser l’API REST Databricks ou l’interface CLI Databricks pour créer une connexion. Consultez POST /api/2.1/unity-catalog/connections et Commandes Unity Catalog.
Autorisations requises : administrateur de metastore ou utilisateur disposant du privilège CREATE CONNECTION.
Explorateur de catalogues
Dans votre espace de travail Azure Databricks, cliquez sur
 Catalog.
Catalog.En haut du volet Catalogue, cliquez sur
 , puis sélectionnez Créer une connexion dans le menu.
, puis sélectionnez Créer une connexion dans le menu.Entrez un nom de connexion convivial.
Sélectionnez le Type de connexion (fournisseur de base de données, par exemple MySQL ou PostgreSQL).
(Facultatif) Ajoutez un commentaire.
Cliquez sur Suivant.
Saisissez les propriétés de connexion (par exemple les informations d’hôte, le chemin d’accès et les informations d’identification d’accès).
Chaque type de connexion nécessite des informations de connexion différentes. Consultez l’article pour votre type de connexion, répertorié dans la table des matières à gauche.
Cliquez sur Create connection (Créer la connexion).
Entrez un nom pour le catalogue étranger.
(Facultatif) Cliquez sur Tester la connexion pour vérifier qu’elle fonctionne.
Cliquez sur Créer un catalogue.
Sélectionnez les espaces de travail dans lesquels les utilisateurs peuvent accéder au catalogue que vous avez créé. Vous pouvez sélectionner Tous les espaces de travail ont l'accès, ou cliquer sur Affecter aux espaces de travail, sélectionner les espaces de travail, puis cliquer sur Attribuer.
Changez le propriétaire qui pourra gérer l'accès à tous les objets du catalogue. Commencez à taper un responsable dans la zone de texte, puis cliquez sur le responsable dans les résultats affichés.
Accordez des privilèges sur le catalogue. Cliquez sur Octroyer :
- Spécifiez les Principaux qui auront accès aux objets du catalogue. Commencez à taper un responsable dans la zone de texte, puis cliquez sur le responsable dans les résultats affichés.
- Sélectionnez les Préréglages de privilège à accorder pour chaque bénéficiaire. Tous les utilisateurs d'un compte reçoivent
BROWSEpar défaut.- Sélectionnez Lecteur de données dans le menu déroulant pour accorder des
readprivilèges sur les objets du catalogue. - Sélectionnez Éditeur de données dans le menu déroulant pour accorder
readetmodifyprivilèges sur les objets du catalogue. - Sélectionnez manuellement les privilèges à accorder.
- Sélectionnez Lecteur de données dans le menu déroulant pour accorder des
- Cliquez sur Accorder.
- Cliquez sur Suivant.
- Dans la page Métadonnées, spécifiez des paires clé-valeur pour les balises. Pour plus d’informations, consultez Appliquer des étiquettes aux objets sécurisables du catalogue Unity.
- (Facultatif) Ajoutez un commentaire.
- Cliquez sur Enregistrer.
SQL
Exécutez la commande suivante dans un notebook ou dans l’éditeur de requête SQL. Cet exemple concerne les connexions à une base de données PostgreSQL. Les options diffèrent selon le type de connexion. Consultez l’article pour votre type de connexion, répertorié dans la table des matières à gauche.
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user '<user>',
password '<password>'
);
Nous vous recommandons d’utiliser Azure Databricks secrets au lieu de chaînes en texte clair pour des valeurs sensibles telles que les informations d’identification. Par exemple:
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user secret ('<secret-scope>','<secret-key-user>'),
password secret ('<secret-scope>','<secret-key-password>')
)
Pour obtenir des informations sur la configuration des secrets, consultez l’article Gestion des secrets.
Pour en savoir plus sur la gestion des connexions existantes, consultez Gérer les connexions pour Lakehouse Federation.
Créer un catalogue étranger
Note
Si vous utilisez l’interface utilisateur pour créer une connexion à la source de données, la création du catalogue étranger est incluse et vous pouvez ignorer cette étape.
Un catalogue étranger met en miroir une base de données dans un système de données externe afin de pouvoir interroger et gérer l’accès aux données de cette base de données à l’aide de Azure Databricks et du catalogue Unity. Pour créer un catalogue étranger, vous utilisez une connexion à la source de données qui a déjà été définie.
Pour créer un catalogue étranger, vous pouvez utiliser l’Explorateur de catalogues ou la commande CREATE FOREIGN CATALOG SQL dans un notebook Azure Databricks ou l’éditeur de requête SQL. Vous pouvez également utiliser l’API catalogue Unity. Consultez Azure Databricks documentation de référence.
Les métadonnées de catalogues étrangers sont synchronisées dans Unity Catalog sur chaque interaction avec le catalogue. Pour le mappage de type de données entre Unity Catalog et la source de données, consultez la section Mappages des types de données de la documentation de chaque source de données.
Autorisations requises : autorisation CREATE CATALOG sur le metastore, et être propriétaire de la connexion ou disposer du privilège CREATE FOREIGN CATALOG sur la connexion.
Explorateur de catalogues
Dans votre espace de travail Azure Databricks, cliquez sur
Catalog pour ouvrir l’Explorateur de catalogues.En haut du volet Catalogue, cliquez sur
des données, puis sélectionnez Créer un catalogue dans le menu.Vous pouvez également accéder à Accès rapide. Cliquez ensuite sur le bouton Catalogues, puis sur Créer un catalogue.
Suivez les instructions pour créer des catalogues étrangers dans Créer des catalogues.
SQL
Exécutez la commande SQL suivante dans un notebook ou l’éditeur de requête SQL. Les éléments entre crochets sont facultatifs. Remplacez les valeurs d’espace réservé :
-
<catalog-name>: nom du catalogue dans Azure Databricks. -
<connection-name>: L'objet Connection qui indique la source de données, le chemin et les informations d’identification d’accès. -
<database-name>: nom de la base de données que vous souhaitez mettre en miroir en tant que catalogue dans Azure Databricks. Non obligatoire pour MySQL, qui utilise un espace de noms à deux couches. -
<external-catalog-name>: Databricks à Databricks uniquement : nom du catalogue dans l’espace de travail Databricks externe que vous reflétez. Consultez Créer un catalogue étranger.
CREATE FOREIGN CATALOG [IF NOT EXISTS] <catalog-name> USING CONNECTION <connection-name>
OPTIONS (database '<database-name>');
Pour en savoir plus sur la gestion et l’utilisation de catalogues étrangers, consultez Gérer et utiliser des catalogues étrangers.
Actualiser les métadonnées
Unity Catalog actualise automatiquement les métadonnées des tables étrangères au moment de la requête. Si le schéma du catalogue externe change, Unity Catalog récupère les dernières métadonnées lors de l’exécution de la requête. Ce comportement conserve le schéma actuel et est optimal pour la plupart des charges de travail.
Toutefois, Databricks recommande d’actualiser manuellement les métadonnées dans les cas suivants :
- Pour maintenir la cohérence des tables étrangères accessibles par les moteurs externes. Les chemins qui contournent Databricks Runtime ne déclenchent pas d’actualisations automatiques, ce qui peut entraîner des métadonnées obsolètes.
- Pour améliorer les performances des charges de travail où vous souhaitez éviter l’actualisation des métadonnées pendant l’exécution de la requête. L’actualisation proactive des métadonnées permet aux requêtes de s’exécuter plus rapidement à l’aide de métadonnées mises en cache. Cette approche est particulièrement utile immédiatement après la création d’un catalogue étranger, car la première requête déclenche sinon une actualisation complète.
Automatiser l’actualisation des métadonnées avec des tâches Lakeflow
Planifiez une actualisation périodique des métadonnées à l’aide d’un travail Lakeflow avec la REFRESH FOREIGN commande SQL. Par exemple:
-- Refresh an entire catalog
> REFRESH FOREIGN CATALOG some_catalog;
-- Refresh a specific schema
> REFRESH FOREIGN SCHEMA some_catalog.some_schema;
-- Refresh a specific table
> REFRESH FOREIGN TABLE some_catalog.some_schema.some_table;
Configurez le travail pour qu’il s’exécute à intervalles réguliers en fonction de la fréquence à laquelle vous prévoyez des modifications de schéma externe.
Charger des données à partir de tables étrangères avec des vues matérialisées
Databricks recommande de charger des données externes à l’aide de la fédération de requêtes lorsque vous créez des vues matérialisées. Consultez Vues matérialisées.
Lorsque vous utilisez la fédération de requêtes, les utilisateurs peuvent référencer les données fédérées comme suit :
CREATE MATERIALIZED VIEW xyz AS SELECT * FROM federated_catalog.federated_schema.federated_table;
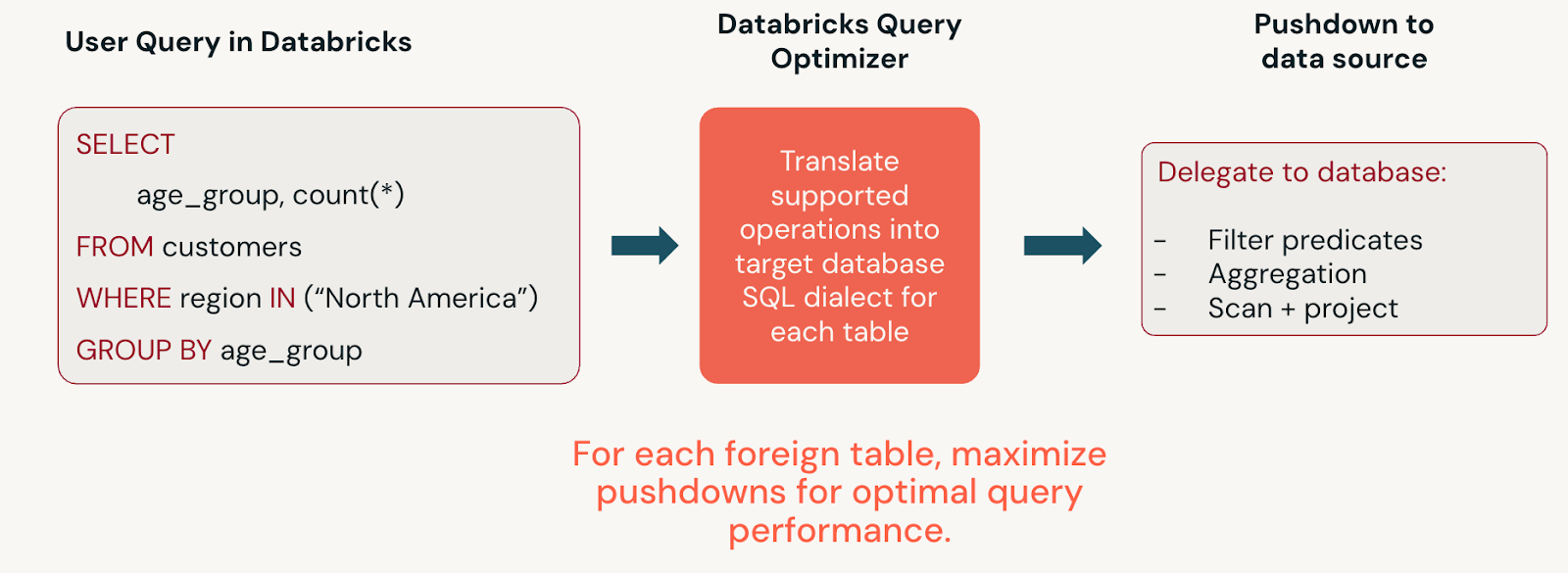
Afficher les requêtes fédérées générées par le système
La fédération de requête traduit les instructions DATAbricks SQL en instructions qui peuvent être envoyées vers le bas dans la source de données fédérée. Pour afficher l’instruction SQL générée, cliquez sur le nœud d’analyse de source de données étrangère dans la vue graphique du profil de requête ou exécutez l’instruction EXPLAIN FORMATTED SQL. Consultez la section Pushdown pris en charge de la documentation de chaque source de données pour en savoir plus.
Limitations
- Les requêtes sont en lecture seule. La seule exception est lorsque la fédération Lakehouse est utilisée pour fédérer le metastore Hive hérité d’un espace de travail (fédération de catalogue). Les tables étrangères de ce scénario sont accessibles en écriture. Voir ce que cela signifie d’écrire dans un catalogue étranger dans un metastore Hive fédéré.
- La limitation des connexions est déterminée à l’aide de la limite de requêtes simultanées Databricks SQL. Il n’existe aucune limite sur l’ensemble des entrepôts par connexion. Consultez la logique de mise en file d'attente et de mise à l’échelle automatique.
- La mise en cache des requêtes Databricks (Cache de résultats et Cache de disque) n’est pas prise en charge pour les requêtes fédérées. Cela signifie que le
use_cached_resultparamètre ne s’applique pas aux requêtes sur des sources fédérées. - Les tables et les schémas dont les noms ne sont pas valides dans Unity Catalog ne sont pas pris en charge et sont ignorés par Unity Catalog lors de la création d’un catalogue étranger. Consultez la liste des règles et limitations de nommage dans Limitations.
- Les noms de table et de schéma sont convertis en minuscules dans Unity Catalog. Si cela provoque des collisions de noms, Databricks ne peut pas garantir l’objet importé dans le catalogue étranger.
- Pour chaque table étrangère référencée, Databricks planifie une sous-requête dans le système distant pour retourner un sous-ensemble de données de cette table, puis retourne le résultat à une tâche d’exécuteur Databricks sur un seul flux. Si le jeu de résultats est trop volumineux, l’exécuteur peut manquer de mémoire.
- Le mode d’accès dédié (anciennement mode d’accès utilisateur unique) est disponible uniquement pour les utilisateurs propriétaires de la connexion.
- La fédération Lakehouse ne peut pas fédérer les tables étrangères dont les identificateurs sont sensibles à la casse pour les connexions Azure Synapse ou Redshift.
Quotas de ressources
Azure Databricks applique des quotas de ressources sur tous les objets sécurisables du catalogue Unity. Ces quotas sont répertoriés dans les limites de ressources. Les catalogues étrangers et tous les objets qu’ils comportent sont inclus dans l’utilisation totale de vos quotas.
Si vous prévoyez de dépasser ces limites de ressources, contactez votre équipe de compte Azure Databricks.
Vous pouvez surveiller l’utilisation de vos quotas à l’aide des API de quotas de ressources d’Unity Catalog. Consultez Surveiller l’utilisation de vos quotas de ressources Unity Catalog.
Ressources supplémentaires
- Requêtes fédérées (Lakehouse Federation) dans les informations de référence sur le langage SQL
- Qu’est-ce que la fédération de catalogue ?
- Fédération de metastore Hive : permettre au catalogue Unity de régir les tables inscrites dans un metastore Hive
- Connecteurs basés sur des requêtes