Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article fournit des solutions aux problèmes courants que vous pouvez rencontrer lorsque vous utilisez le EventProcessorClient type. Si vous recherchez des solutions à d’autres problèmes courants que vous pouvez rencontrer lorsque vous utilisez Azure Event Hubs, consultez Résoudre les problèmes liés à Azure Event Hubs.
Échecs de condition préalable 412 lors de l’utilisation d’un processeur d’événements
Les erreurs de condition préalable 412 se produisent lorsque le client tente de prendre ou de renouveler la propriété d’une partition, mais que la version locale de l’enregistrement de propriété est obsolète. Ce problème se produit quand une autre instance de processeur vole la propriété de partition. Pour plus d'informations, voir la section suivante.
La propriété de partition est fréquemment modifiée
Lorsque le nombre d’instances EventProcessorClient change (autrement dit, sont ajoutées ou supprimées), les instances en cours d’exécution tentent d’équilibrer la charge des partitions entre elles. Pendant quelques minutes après que le nombre de processeurs change, les partitions sont censées changer de propriétaire. Une fois qu’elle est équilibrée, la propriété de partition doit être stable. Elle doit changer très rarement. Si la propriété de partition change fréquemment lorsque le nombre de processeurs est constant, il indique probablement un problème. Nous vous recommandons de signaler le problème sur GitHub en y joignant les journaux d’activité et en le reproduisant.
La propriété de la partition est déterminée par l'intermédiaire des enregistrements de propriété dans le CheckpointStore. À chaque intervalle d'équilibrage de charge, le EventProcessorClient effectuera les tâches suivantes :
- Récupérez les derniers enregistrements de propriété.
- Vérifiez les enregistrements pour voir quels enregistrements n’ont pas mis à jour leur horodatage dans l’intervalle d’expiration de propriété de la partition. Seuls les enregistrements correspondant à ces critères sont pris en compte.
- S'il existe des partitions sans propriétaire et que la charge n'est pas équilibrée entre les instances de
EventProcessorClient, le client du processeur d'événements tente de s'approprier une partition. - Mettez à jour l'enregistrement de propriété des partitions qu'il possède et qui ont un lien actif avec cette partition.
Vous pouvez configurer les intervalles d'équilibrage de charge et d'expiration de propriété lorsque vous créez le EventProcessorClient via le EventProcessorClientBuilder, comme décrit dans la liste suivante :
- La méthode loadBalancingUpdateInterval(Duration) indique la fréquence à laquelle le cycle d’équilibrage de charge s’exécute.
- La méthode partitionOwnershipExpirationInterval(Duration) indique le temps minimum écoulé depuis la mise à jour de l’enregistrement de propriété avant que le processeur ne considère une partition comme non détenue.
Par exemple, si un enregistrement de propriété a été mis à jour à 9 h 30 et partitionOwnershipExpirationInterval est de 2 minutes. Lorsqu’un cycle de répartition de charge se produit et qu’il remarque que l’enregistrement de propriété n’a pas été mis à jour au cours des 2 dernières minutes ou avant 9 h 32, il considère la partition comme non détenue.
Si une erreur survient dans l’un des consommateurs de partition, le système fermera le consommateur correspondant. Toutefois, il n’essaiera pas de le récupérer avant le prochain cycle d’équilibrage de charge.
« ...le récepteur actuel “<RECEIVER_NAME>” dont l’époque est '0' se déconnecte »
Le message d’erreur entier ressemble à la sortie suivante :
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
Cette erreur est attendue lorsque l’équilibrage de charge se produit une fois EventProcessorClient les instances ajoutées ou supprimées. L’équilibrage de charge est un processus continu. Lorsque vous utilisez le BlobCheckpointStore avec votre consommateur, environ toutes les 30 secondes (par défaut), le consommateur vérifie quels consommateurs ont une attribution pour chaque partition, puis applique une logique pour déterminer s'il doit « voler » une partition d'un autre consommateur. Le mécanisme de service utilisé pour affirmer la propriété exclusive sur une partition est connu sous le nom de Epoch.
Toutefois, si aucune instance n’est ajoutée ou supprimée, il existe un problème sous-jacent qui doit être résolu. Pour plus d’informations, consultez la section Modification fréquente de la propriété de partition et classement des problèmes GitHub.
Utilisation élevée du processeur
L’utilisation élevée du processeur est généralement due au fait qu’une instance possède trop de partitions. Nous vous recommandons de ne pas dépasser trois partitions pour chaque cœur de processeur. Il est préférable de commencer par 1,5 partitions pour chaque cœur de processeur, puis de tester en augmentant le nombre de partitions détenues.
Mémoire insuffisante et choix de la taille du tas
Le problème de mémoire insuffisante (OOM) peut se produire si le tas de mémoire maximal actuel pour la JVM est insuffisant pour exécuter l’application. Vous pouvez mesurer l’exigence du tas de l’application. Ensuite, en fonction du résultat, dimensionner le tas en définissant la mémoire maximale maximale appropriée à l’aide de l’option -Xmx JVM.
Vous ne devez pas spécifier -Xmx comme valeur supérieure à la mémoire disponible ou limite définie pour l’hôte (la machine virtuelle ou le conteneur), par exemple la mémoire demandée dans la configuration du conteneur. Vous devez allouer suffisamment de mémoire à l’hôte pour prendre en charge le tas Java.
Les étapes suivantes décrivent une manière classique de mesurer la valeur maximale du tas Java :
Exécutez l’application dans un environnement proche de la production, où l’application envoie, reçoit et traite des événements sous la charge maximale attendue en production.
Attendez que l’application atteigne un état stable. À ce stade, l’application et la machine virtuelle JVM auraient chargé tous les objets de domaine, types de classes, instances statiques, pools d’objets (TCP, pools de connexions de base de données), etc.
En régime permanent, la collection du tas présente un modèle stable en dents de scie, comme le montre la capture d’écran suivante :
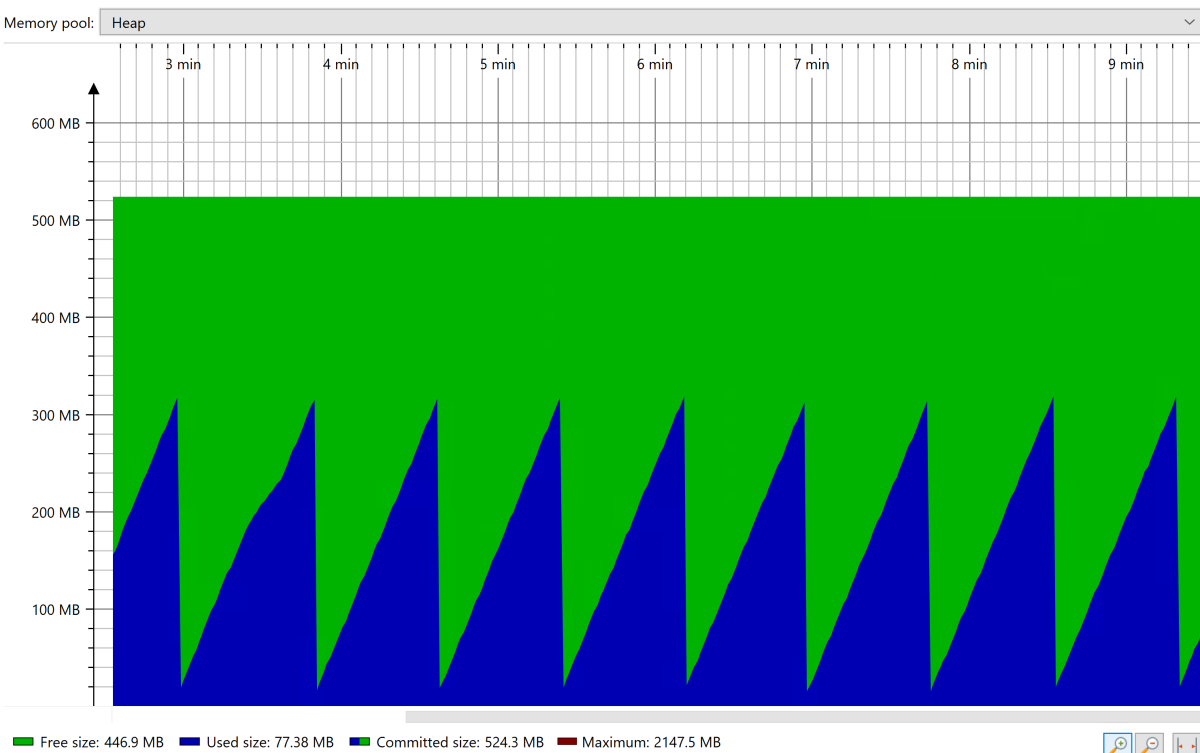
Une fois que l'application est stabilisée, forcez une GC à l’aide d’outils tels que JConsole. Observez la mémoire occupée après la GC complète. Souhaitez-vous redimensionner le tas de manière à ce que seuls 30 % soient occupés après la GC complète ? Vous pouvez utiliser cette valeur pour définir la taille maximale du tas en utilisant
-Xmx.

Si vous êtes sur le conteneur, alors redimensionnez le conteneur pour qu’il dispose d’une mémoire supplémentaire d’environs1 Go pour les besoins de mémoire non associée au tas de l’instance JVM.
Le client processeur cesse de recevoir
Le client du processeur fonctionne souvent en continu dans une application hôte pendant plusieurs jours d'affilée. Parfois, il remarque que EventProcessorClient ne traite pas une ou plusieurs partitions. En règle générale, il n’y a pas suffisamment d’informations pour déterminer la raison pour laquelle l’exception s’est produite. L’arrêt EventProcessorClient est le symptôme d’une cause sous-jacente (autrement dit, la condition de concurrence) qui s’est produite lors de la tentative de récupération à partir d’une erreur temporaire. Pour plus d’informations, consultez Le dépôt de problèmes GitHub.
Dupliquer EventData reçu lorsque le processeur est redémarré
Les services EventProcessorClient et Event Hubs garantissent une livraison au moins une fois. Vous pouvez ajouter des métadonnées pour discerner les événements en double. Pour plus d’informations, consultez Azure Event Hubs garantit-il une livraison au moins une fois sur Stack Overflow. Si vous avez besoin d’une livraison une seule fois , vous devez prendre en compte Service Bus, qui attend un accusé de réception du client. Pour une comparaison des services de messagerie, consultez Choisir entre les services de messagerie Azure.
Le client consommateur de bas niveau cesse de recevoir
EventHubConsumerAsyncClient est un client consommateur de bas niveau fourni par la bibliothèque Event Hubs, conçu pour les utilisateurs avancés qui ont besoin d’un meilleur contrôle et d’une plus grande flexibilité sur leurs applications réactives. Ce client offre une interface de bas niveau, permettant aux utilisateurs de gérer la rétropression, le threading et la récupération au sein de la chaîne Reactor. Contrairement à EventProcessorClient, EventHubConsumerAsyncClient n’inclut pas de mécanismes de récupération automatique pour toutes les causes terminales. Par conséquent, les utilisateurs doivent gérer les événements terminal et sélectionner les opérateurs de réacteur appropriés pour implémenter des stratégies de récupération.
La EventHubConsumerAsyncClient::receiveFromPartition méthode émet une erreur de terminal lorsque la connexion rencontre une erreur non retenable ou lorsqu’une série de tentatives de récupération de connexion échouent consécutivement, ce qui épuise la limite maximale de nouvelles tentatives. Bien que le récepteur de bas niveau tente de récupérer à partir d’erreurs temporaires, les utilisateurs du client consommateur sont censés gérer les événements terminaux. Si l’on souhaite une réception continue des événements, l’application doit adapter la chaîne Reactor pour créer un nouveau client consommateur lors d’un événement terminal.
Migrer de l'ancienne vers une nouvelle bibliothèque cliente
Le guide de migration comprend des étapes sur la migration à partir du client hérité et la migration de points de contrôle hérités.
Étapes suivantes
Si les conseils de dépannage de cet article ne permettent pas de résoudre les problèmes liés à l'utilisation des bibliothèques clientes Azure SDK for Java, nous vous recommandons de déposer un problème dans le référentiel GitHub Azure SDK for Java.