Utiliser Azure Toolkit for IntelliJ afin de créer des applications Apache Spark pour le cluster HDInsight
Cet article montre comment développer des applications Apache Spark sur Azure HDInsight en utilisant le plug-in Azure Toolkitpour l’IDE IntelliJ. Azure HDInsight est un service cloud d’analytique managé open source. Il vous permet d’utiliser des frameworks open source tels que Hadoop, Apache Spark, Apache Hive et Apache Kafka.
Vous pouvez utiliser le plug-in Azure Toolkit de différentes façons :
- Développer et soumettre une application Scala Spark sur un cluster HDInsight Spark.
- Accéder à vos ressources de cluster Azure HDInsight Spark.
- Développer et exécuter une application Scala Spark localement.
Dans cet article, vous apprendrez comment :
- Utiliser le plug-in Azure Toolkit for IntelliJ
- Développer des applications Apache Spark
- Envoyer une application au cluster Azure HDInsight
Prérequis
Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight. Seuls les clusters HDinsight du cloud public sont pris en charge, ce qui n’est pas le cas des autres types de clouds sécurisés (par exemple, les clouds du secteur public).
Le SDK Oracle Java. Cet article utilise la version 8.0.202 de Java.
IntelliJ IDEA. Cet article utilise IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Consultez Installation d’Azure Toolkit for IntelliJ.
Installer le plug-in Scala pour IntelliJ IDEA
Étapes à suivre pour installer le plug-in Scala :
Ouvrez IntelliJ IDEA.
Dans l’écran d’accueil, accédez à Configure>Plugins (Configurer > Plug-ins) pour ouvrir la fenêtre Plugins (Plug-ins).

Sélectionnez Install (Installer) pour le plug-in Scala proposé dans la nouvelle fenêtre.
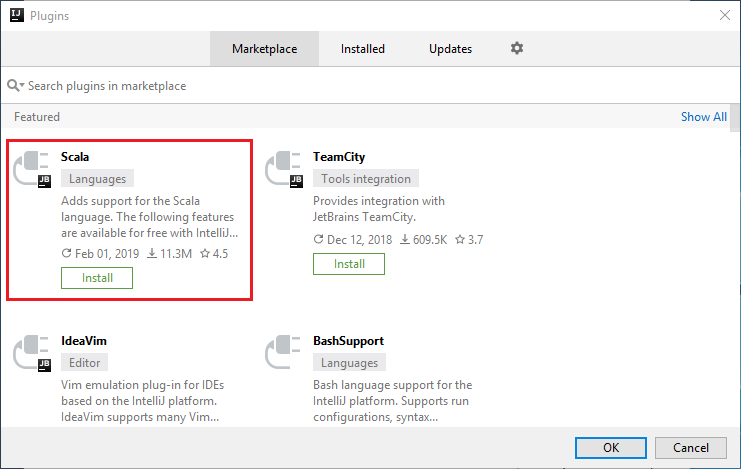
Une fois que le plug-in est bien installé, vous devez redémarrer l’IDE.
Créer une application Scala Spark pour un cluster HDInsight Spark
Démarrez IntelliJ IDEA, puis sélectionnez Create New Project (Créer un projet) pour ouvrir la fenêtre New Project (Nouveau projet).
Sélectionnez Azure Spark/HDInsight dans le volet gauche.
Sélectionnez Spark Project (Scala) [Projet Spark (Scala)] dans la fenêtre principale.
Dans la liste déroulante Build tool (Outil de build), sélectionnez l’une des options suivantes :
Maven pour la prise en charge de l’Assistant de création de projets Scala.
SBT pour gérer les dépendances et la génération du projet Scala.

Cliquez sur Suivant.
Dans la fenêtre New Project (Nouveau projet), entrez les informations suivantes :
Propriété Description Nom du projet Entrez un nom. Cet article utilise myApp.Emplacement du projet Entrez l’emplacement où enregistrer votre projet. Project SDK (SDK du projet) Ce champ peut être vide si vous utilisez IDEA pour la première fois. Sélectionnez New... (Nouveau) et accédez à votre JDK. Version de Spark L’Assistant de création intègre la version correcte des SDK Spark et Scala. Si la version du cluster Spark est antérieure à la version 2.0, sélectionnez Spark 1.x. Sinon, sélectionnez Spark 2.x. Cet exemple utilise Spark 2.3.0 (Scala 2.11.8) . 
Sélectionnez Terminer. Vous devrez peut-être patienter quelques minutes avant que le projet soit disponible.
Le projet Spark crée automatiquement un artefact. Pour afficher l’artefact, effectuez les étapes suivantes :
a. À partir de la barre de menus, accédez à File>Project Structure.
b. Dans la fenêtre Project Structure, sélectionnez Artifacts.
c. Sélectionnez Cancel (Annuler) après avoir visualisé l’artefact.

Ajoutez le code source de votre application en effectuant les étapes suivantes :
a. À partir de Project, accédez à myApp>src>main>scala.
b. Cliquez avec le bouton droit sur scala, puis accédez à New>Scala Class.
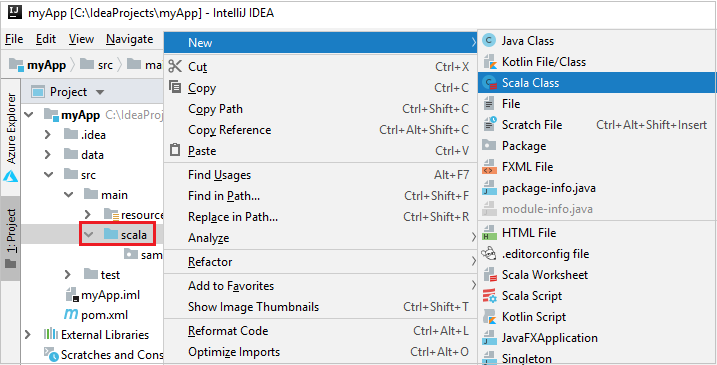
c. Dans la boîte de dialogue Create New Scala Class, indiquez un nom, sélectionnez Object dans la liste déroulante Kind (Genre), puis OK.

d. Le fichier myApp.scala s’ouvre dans la vue principale. Remplacez le code par défaut par le code ci-dessous :
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Ce code lit les données du fichier HVAC.csv (disponible sur tous les clusters HDInsight Spark), récupère les lignes qui contiennent uniquement un chiffre dans la septième colonne du fichier CSV, et écrit la sortie dans
/HVACOutsous le conteneur de stockage par défaut du cluster.
Se connecter au cluster HDInsight
L’utilisateur peut se connecter à votre abonnement Azure ou lier un cluster HDInsight. Utilisez les informations d’identification jointes au domaine ou le nom d’utilisateur/mot de passe Ambari pour vous connecter à votre cluster HDInsight.
Connectez-vous à votre abonnement Azure :
Dans la barre de menus, accédez à Affichage>Fenêtres Outil>Azure Explorer.

Dans Azure Explorer, cliquez avec le bouton droit sur le nœud Azure, puis sélectionnez Se connecter.

Dans la boîte de dialogue Connexion à Azure, choisissez Connexion à l’appareil, puis sélectionnez Connexion.

Dans la boîte de dialogue Connexion à l’appareil Azure, cliquez sur Copier et ouvrir.

Dans l’interface du navigateur, collez le code, puis cliquez sur Suivant.

Entrez vos informations d’identification Azure, puis fermez le navigateur.

Une fois que vous êtes connecté, la boîte de dialogue Sélectionner des abonnements répertorie tous les abonnements Azure associés aux informations d’identification. Sélectionnez votre abonnement, puis cliquez sur le bouton Sélectionner.

Dans Azure Explorer, développez HDInsight pour voir les clusters HDInsight Spark de vos abonnements.

Vous pouvez développer davantage un nœud de nom de cluster pour voir les ressources (par exemple, les comptes de stockage) associées au cluster.

Lier un cluster
Vous pouvez lier un cluster HDInsight avec le nom d’utilisateur managé Apache Ambari. De même, pour un cluster HDInsight joint à un domaine, vous pouvez effectuer une liaison à l’aide du domaine et du nom d’utilisateur, par exemple user1@contoso.com. Vous pouvez également lier un cluster Livy Service.
Dans la barre de menus, accédez à Affichage>Fenêtres Outil>Azure Explorer.
Dans Azure Explorer, cliquez avec le bouton droit sur le nœud HDInsight, puis sélectionnez Lier un cluster.

Les options disponibles dans la fenêtre Lier un cluster dépendent de la valeur que vous sélectionnez dans la liste déroulante Lier un type de ressource. Entrez vos valeurs, puis sélectionnez OK.
Cluster HDInsight
Propriété Valeur Lier un type de ressource Sélectionnez Cluster HDInsight dans la liste déroulante. Nom du cluster/URL Entrez un nom de cluster. Type d’authentification Conservez Authentification de base. User Name Entrez le nom d’utilisateur de cluster (la valeur par défaut est Admin). Mot de passe Entrez le mot de passe du nom d’utilisateur. 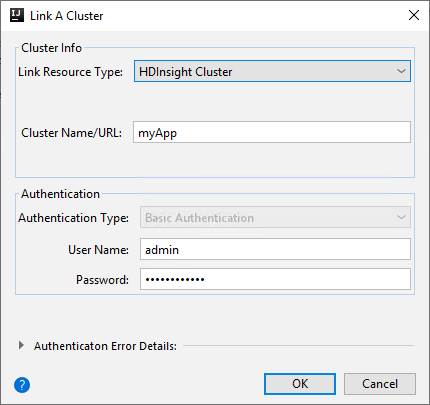
Service Livy
Propriété Valeur Lier un type de ressource Sélectionnez Livy Service dans la liste déroulante. Point de terminaison Livy Entrez le point de terminaison Livy. Nom du cluster Entrez un nom de cluster. Point de terminaison Yarn facultatif. Type d’authentification Conservez Authentification de base. User Name Entrez le nom d’utilisateur de cluster (la valeur par défaut est Admin). Mot de passe Entrez le mot de passe du nom d’utilisateur. 
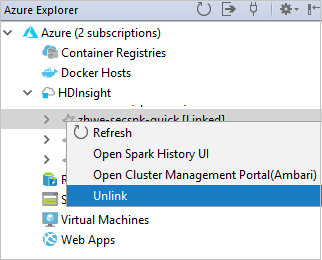
Vous pouvez voir votre cluster lié à partir du nœud HDInsight.

Vous pouvez également dissocier un cluster à partir de Azure Explorer.
Exécuter une application Scala Spark sur un cluster HDInsight Spark
Après avoir créé l’application Scala, vous pouvez l’envoyer au cluster.
Dans le projet, accédez à myApp>src>main>scala>myApp. Cliquez avec le bouton droit sur myApp, puis sélectionnez Submit Spark Application (cette option sera probablement en bas de la liste).

Dans la boîte de dialogue Submit Spark Application, sélectionnez 1. Spark on HDInsight.
Dans la fenêtre Edit configuration (Modifier la configuration), entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Spark clusters (Linux only) Sélectionnez le cluster HDInsight Spark sur lequel vous souhaitez exécuter votre application. Sélectionner un artefact à envoyer Conservez le paramètre par défaut. Main class name La valeur par défaut est la classe principale du fichier sélectionné. Vous pouvez changer la classe en sélectionnant les points de suspension ( ... ), puis en choisissant une autre classe. Configurations du travail Vous pouvez changer les clés et/ou les valeurs par défaut. Pour plus d’informations, consultez API REST Apache Livy. Arguments de ligne de commande Vous pouvez entrer des arguments séparés par un espace pour la classe main, si nécessaire. JAR référencés et fichiers référencés vous pouvez entrer les chemins des fichiers jar et des fichiers référencés, si vous en avez. Vous pouvez également parcourir les fichiers dans le système de fichiers virtuel Azure, qui ne prend en charge que le cluster ADLS Gen 2. Pour plus d'informations : Apache Spark Configuration. Consultez également Guide pratique pour charger des ressources sur un cluster. Stockage des chargements de travaux Développez pour afficher des options supplémentaires. Type de stockage Sélectionnez Utiliser l’objet blob Azure pour charger dans la liste déroulante. Compte de stockage Entrez votre compte de stockage. Clé de stockage Entrez votre clé de stockage. Conteneur de stockage Sélectionnez votre conteneur de stockage dans la liste déroulante après avoir entré les valeurs Compte de stockage et Clé de stockage. 
Sélectionnez SparkJobRun pour envoyer votre projet au cluster sélectionné. L’onglet Remote Spark Job in Cluster (Travail Spark distant dans le cluster) affiche la progression de l’exécution du travail au bas de la page. Vous pouvez arrêter l’application en cliquant sur le bouton rouge.

Déboguer des applications Apache Spark localement ou à distance sur un cluster HDInsight
Nous recommandons également un autre mode de soumission de l’application Spark au cluster. Vous pouvez définir les paramètres dans l’IDE Exécuter/déboguer des configurations. Consultez Déboguer les applications Apache Spark localement ou à distance sur un cluster HDInsight, avec Azure Toolkit for IntelliJ via SSH.
Accéder aux clusters HDInsight Spark et les gérer à l’aide du kit de ressources Azure pour IntelliJ
Vous pouvez effectuer diverses opérations à l’aide d’Azure Toolkit for IntelliJ. La plupart des opérations sont démarrées à partir d’Azure Explorer. Dans la barre de menus, accédez à Affichage>Fenêtres Outil>Azure Explorer.
Accéder à la vue des travaux
Dans Azure Explorer, accédez à HDInsight><Votre cluster>>Travaux.
Dans le volet droit, l’onglet Spark Job View (Affichage des travaux Spark) affiche toutes les applications qui ont été exécutées sur le cluster. Sélectionnez le nom de l’application pour laquelle vous souhaitez afficher plus de détails.

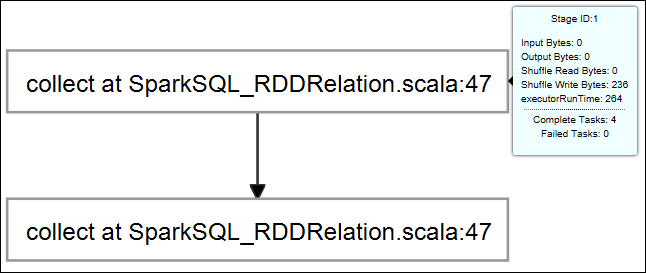
Pour afficher des informations de base sur les travaux en cours d’exécution, passez le curseur sur le graphique du travail. Pour afficher le graphique des étapes et les informations que chaque travail génère, sélectionnez un nœud sur le graphique du travail.
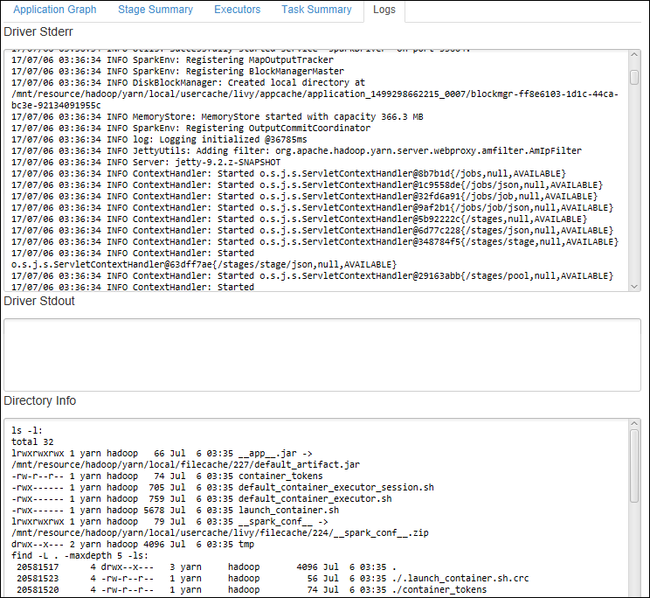
Pour afficher les journaux d’activité fréquemment utilisés tels que les journaux d’activité Driver Stderr, Driver Stdout et Directory Info, sélectionnez l’onglet Journal.
Vous pouvez afficher l’interface utilisateur de l’historique Spark et l’interface utilisateur YARN (au niveau de l’application). Sélectionnez un lien en haut de la fenêtre.
Accéder au serveur d’historique Spark
Dans Azure Explorer, développez HDInsight, cliquez avec le bouton droit sur le nom de votre cluster Spark et sélectionnez Open Spark History UI (Ouvrir l’interface utilisateur de l’historique Spark).
Lorsque vous y êtes invité, entrez les informations d’identification administrateur du cluster que vous avez spécifiées lors de la configuration de ce dernier.
Dans le tableau de bord du serveur d’historique Spark, vous pouvez utiliser le nom de l’application pour rechercher l’application que vous venez d’exécuter. Dans le code précédent, vous définissez le nom de l’application en utilisant
val conf = new SparkConf().setAppName("myApp"). Le nom de votre application Spark est myApp.
Démarrer le portail Ambari
Dans Azure Explorer, développez HDInsight, cliquez avec le bouton droit sur le nom de votre cluster Spark et sélectionnez Open Cluster Management Portal (Ambari) (Ouvrir le portail de gestion des clusters (Ambari)).
Lorsque vous y êtes invité, entrez les informations d’identification d’administrateur pour le cluster. Vous avez spécifié ces informations d’identification lors du processus de configuration des clusters.
Gérer les abonnements Azure
Par défaut, le kit de ressources Azure pour IntelliJ répertorie les clusters Spark à partir de tous vos abonnements Azure. Si nécessaire, vous pouvez spécifier les abonnements auxquelles vous souhaitez accéder.
Dans Azure Explorer, cliquez avec le bouton droit sur le nœud racine Azure, puis sélectionnez Sélectionner des abonnements.
Dans la fenêtre Sélectionner des abonnements, décochez les cases à côté des abonnements auxquels vous ne souhaitez pas accéder, puis sélectionnez Fermer.
Console Spark
Vous pouvez exécuter la console locale Spark (Scala) ou exécuter la console de sessions interactives Spark Livy (Scala).
Console locale Spark (Scala)
Veillez à respecter les prérequis WINUTILS.EXE.
Dans la barre de menus, accédez à Run>Edit Configurations... .
Dans la fenêtre Run/Debug Configurations (Exécuter/déboguer des wonfigurations), dans le volet gauche, accédez à Apache Spark on HDInsight>[Spark on HDInsight] myApp.
Dans la fenêtre principale, sélectionnez l’onglet
Locally Run.Entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Job main class (Classe principale du travail) La valeur par défaut est la classe principale du fichier sélectionné. Vous pouvez changer la classe en sélectionnant les points de suspension ( ... ), puis en choisissant une autre classe. Variables d'environnement Vérifiez que la valeur de HADOOP_HOME est correcte. WINUTILS.exe location Vérifiez que le chemin est correct. 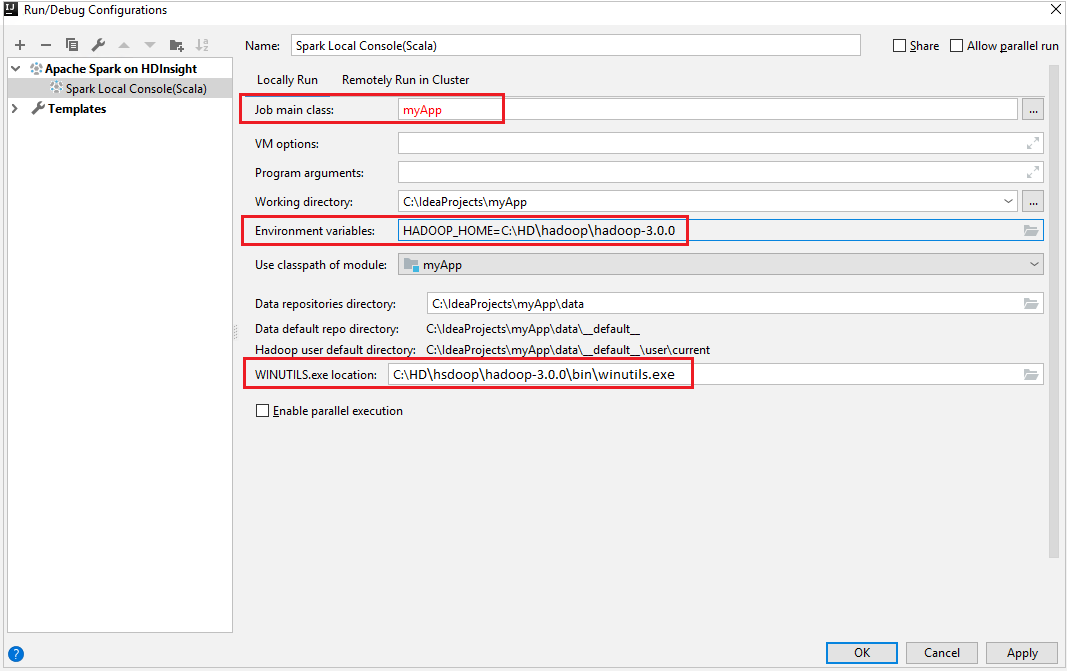
Dans le projet, accédez à myApp>src>main>scala>myApp.
Dans la barre de menus, accédez à Tools>Spark Console>Run Spark Local Console(Scala) .
Deux boîtes de dialogue peuvent s’afficher pour vous demander si vous souhaitez corriger automatiquement les dépendances. Si c’est le cas, sélectionnez Correction automatique.


La console doit ressembler à l’image ci-dessous. Dans la fenêtre de la console, tapez
sc.appName, puis appuyez sur Ctrl + Entrée. Le résultat s’affiche. Vous pouvez arrêter la console locale en cliquant sur le bouton rouge.
Console de sessions interactives Spark Livy (Scala)
Dans la barre de menus, accédez à Run>Edit Configurations... .
Dans la fenêtre Run/Debug Configurations (Exécuter/déboguer des wonfigurations), dans le volet gauche, accédez à Apache Spark on HDInsight>[Spark on HDInsight] myApp.
Dans la fenêtre principale, sélectionnez l’onglet
Remotely Run in Cluster.Entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Spark clusters (Linux only) Sélectionnez le cluster HDInsight Spark sur lequel vous souhaitez exécuter votre application. Main class name La valeur par défaut est la classe principale du fichier sélectionné. Vous pouvez changer la classe en sélectionnant les points de suspension ( ... ), puis en choisissant une autre classe. 
Dans le projet, accédez à myApp>src>main>scala>myApp.
Dans la barre de menus, accédez à Tools>Spark Console>Run Spark Livy Interactive Session Console(Scala) .
La console doit ressembler à l’image ci-dessous. Dans la fenêtre de la console, tapez
sc.appName, puis appuyez sur Ctrl + Entrée. Le résultat s’affiche. Vous pouvez arrêter la console locale en cliquant sur le bouton rouge.
Envoyer la sélection à la console Spark
Il est pratique pour vous de prévoir le résultat du script en envoyant du code à la console locale ou à Livy Interactive Session Console(Scala). Vous pouvez mettre en surbrillance du code dans le fichier Scala, puis cliquer avec le bouton droit sur Send Selection To Spark Console (Envoyer la sélection vers la console Spark). Le code sélectionné est envoyé vers la console. Le résultat s’affiche après le code dans la console. La console vérifie les erreurs, le cas échant.

Effectuer l’intégration au broker d’ID HDInsight
Se connecter à votre cluster HDInsight ESP avec le broker d’ID
Vous pouvez suivre les étapes habituelles pour vous connecter à l’abonnement Azure afin de vous connecter à votre cluster HDInsight ESP avec le broker d’ID. Après vous être connecté, vous verrez la liste des clusters dans Azure Explorer. Pour plus d’instructions, consultez Se connecter à votre cluster HDInsight.
Exécuter une application Scala Spark sur un cluster HDInsight ESP avec le broker d’ID
Vous pouvez suivre les étapes habituelles pour soumettre un travail à un cluster HDInsight ESP avec le broker d’ID. Pour plus d’instructions, consultez Exécuter une application Scala Spark sur un cluster HDInsight Spark.
Nous chargeons les fichiers nécessaires vers un dossier nommé d’après votre compte de connexion, et vous pouvez voir le chemin de chargement dans le fichier de configuration.

Console Spark sur un cluster HDInsight ESP avec le broker d’ID
Vous pouvez exécuter Spark Local Console(Scala) ou Spark Livy Interactive Session Console(Scala) sur un cluster HDInsight ESP avec le broker d’ID. Pour plus d’instructions, reportez-vous à Console Spark.
Notes
Pour le cluster HDInsight ESP avec le broker d’ID, la liaison d’un cluster et le débogage d’applications Apache Spark à distance ne sont pas pris en charge.
Rôle Lecteur seul
Lorsque les utilisateurs envoient du travail à un cluster avec l’autorisation de rôle Lecteur seul, les informations d’identification Ambari sont obligatoires.
Lier le cluster à partir du menu contextuel
Connectez-vous avec un compte membre du rôle Lecteur seul.
Dans Azure Explorer, développez HDInsight pour voir les clusters HDInsight de votre abonnement. Les clusters signalés par "Role:Reader" ont uniquement l’autorisation du rôle Lecteur seul.

Cliquez avec le bouton droit de la souris sur le cluster avec l’autorisation de rôle Lecteur seul. Sélectionnez Link this cluster dans le menu contextuel pour lier le cluster. Entrez le nom d’utilisateur et le mot de passe Ambari.

Si le cluster est correctement lié, HDInsight est actualisé. L’étape du cluster sera reliée.

Lier le cluster en développant le nœud Jobs (Travaux)
Cliquez sur le nœud Jobs (Travaux). La fenêtre contextuelle Cluster Job Access Denied (Accès refusé au travail du cluster) s’ouvre alors.
Cliquez sur Link this cluster pour lier le cluster.

Lier le cluster à partir de la fenêtre d’exécution/débogage des configurations
Créez une configuration HDInsight. Sélectionnez ensuite Remotely Run in Cluster (Exécuter à distance dans le cluster).
Sélectionnez un cluster, qui a l’autorisation de rôle lecteur uniquement pour les clusters Spark (Linux uniquement) . Un message d’avertissement s’affiche. Vous pouvez cliquer sur Link this cluster pour lier le cluster.

Afficher les comptes de stockage
Pour les clusters possédant l’autorisation de rôle Lecteur seul, cliquez sur le nœud Storage Accounts (Comptes de stockage). La fenêtre contextuelle Storage Access Denied (Accès au stockage refusé) s’ouvre alors. Vous pouvez cliquer sur Ouvrir l’Explorateur Stockage Azure pour ouvrir l’Explorateur de stockage.


Pour les clusters liés, cliquez sur le nœud Storage Accounts. La fenêtre contextuelle Storage Access Denied s’ouvre alors. Vous pouvez cliquer sur Ouvrir Stockage Azure pour ouvrir l’Explorateur de stockage.


Convertir des applications IntelliJ IDEA existantes pour qu’elles utilisent le kit de ressources Azure pour IntelliJ
Vous pouvez convertir les applications Spark Scala existantes que vous avez créées dans IntelliJ IDEA pour qu’elles soient compatibles avec le kit de ressources Azure pour IntelliJ. Vous pouvez ensuite utiliser le plug-in pour envoyer les applications à un cluster HDInsight Spark.
Pour une application Spark Scala existante créée à l’aide d’IntelliJ IDEA, ouvrez le fichier
.imlassocié.Au niveau de la racine se trouve un élément module ressemblant au texte suivant :
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Ajoutez
UniqueKey="HDInsightTool"à l’élément module, qui doit alors ressembler au texte suivant :<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Enregistrez les modifications. Votre application doit maintenant être compatible avec le kit de ressources Azure pour IntelliJ. Vous pouvez effectuer un test en cliquant avec le bouton droit sur le nom du projet dans Project. Le menu contextuel doit maintenant comporter l’option Submit Spark Application to HDInsight(Envoyer l’application Spark à HDInsight).
Nettoyer les ressources
Si vous ne comptez pas continuer à utiliser cette application, effectuez les étapes suivantes pour supprimer le cluster que vous avez créé :
Connectez-vous au portail Azure.
Dans la zone Recherche située en haut, tapez HDInsight.
Sous Services, sélectionnez Clusters HDInsight.
Dans la liste des clusters HDInsight qui s’affiche, sélectionnez les points de suspension ... en regard du cluster que vous avez créé pour cet article.
Sélectionnez Supprimer. Sélectionnez Oui.

Erreurs et solution
Supprimez le marquage du dossier src en tant que Sources si vous obtenez des erreurs d’échec de build comme ci-dessous :

Supprimez le marquage du dossier src en tant que Sources pour résoudre ce problème :
Accédez à Fichier et sélectionnez la Structure du projet.
Sélectionnez les Modules sous Paramètres du projet.
Sélectionnez le fichier src et supprimez le marquage en tant que Sources.
Cliquez sur le bouton Appliquer, puis sur le bouton OK pour fermer la boîte de dialogue.

Étapes suivantes
Dans cet article, vous avez découvert comment utiliser le plug-in Azure Toolkit for IntelliJ pour développer des applications Apache Spark écrites en Scala. Vous pouvez ensuite les envoyer à un cluster HDInsight Spark directement à partir de l’environnement de développement intégré (IDE) IntelliJ. Passez à l’article suivant pour découvrir comment les données que vous avez inscrites dans Apache Spark peuvent être tirées (pull) et placées dans un outil analytique décisionnel tel que Power BI.