Déboguer des travaux Apache Spark en cours d’exécution sur Azure HDInsight
Dans cet article, vous allez apprendre à suivre et déboguer les travaux Apache Spark s’exécutant sur des clusters HDInsight. Déboguez à l’aide de l’interface utilisateur d’Apache Hadoop YARN, de l’interface utilisateur de Spark et du serveur d’historique Spark. Vous démarrez une tâche Spark à partir d’un bloc-notes disponible avec le cluster Spark, Machine Learning : analyse prédictive des données d’inspections alimentaires à l’aide de MLLib. Utilisez les étapes ci-dessous pour effectuer le suivi d’une application que vous avez envoyée avec une autre méthode, par exemple, spark-submit.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight.
Vous devriez avoir démarré le notebook, Machine learning : analyse prédictive des données d’inspections alimentaires à l’aide de MLLib . Pour obtenir des instructions sur l’exécution de ce bloc-notes, suivez le lien.
Effectuer le suivi d’une application dans l’interface utilisateur YARN
Lancez l’interface utilisateur YARN. Sélectionnez Yarn sous Tableaux de bord du cluster.

Conseil
Vous pouvez également lancer l’interface utilisateur de YARN à partir de celle d’Ambari. Pour lancer l’interface utilisateur d’Ambari, sélectionnez Accueil Ambari sous Tableaux de bord du cluster. À partir de l’interface utilisateur d’Ambari, accédez à YARN>Liens rapides> Instance active de Resource Manager > Resource Manager UI.
Étant donné que vous avez commencé le travail Spark avec des notebooks Jupyter, l’application porte le nom remotesparkmagics (comme toutes les applications commencées à partir de notebooks). Sélectionnez l’ID d’application en regard du nom de l’application pour obtenir plus d’informations sur le travail. Cette action lance la vue de l’application.

Pour les applications lancées à partir de notebooks Jupyter, l’état est toujours EN COURS D’EXÉCUTION tant que le notebook n’est pas fermé.
Dans la vue de l’application, vous pouvez descendre pour rechercher les conteneurs associés à l’application et aux journaux d’activité (stdout/stderr). Vous pouvez également lancer l’interface utilisateur Spark en cliquant sur le lien qui correspond à l’ URL de suivi, comme indiqué ci-dessous.

Effectuer le suivi d’une application dans l’interface utilisateur Spark
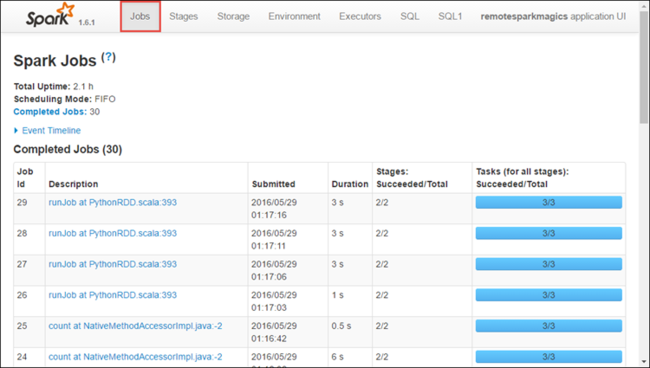
Dans l’interface utilisateur Spark, vous pouvez explorer les travaux Spark générés par l’application que vous avez démarrée précédemment.
Pour lancer l’interface utilisateur Spark, dans la vue de l’application, sélectionnez le lien URL de suivi, comme illustré dans la capture d’écran ci-dessus. Y figurent tous les travaux Spark lancés par l’application en cours d’exécution dans le notebook Jupyter.
Sélectionnez l’onglet Exécuteurs pour consulter les informations de traitement et de stockage pour chaque exécuteur. Vous pouvez également récupérer la pile des appels en sélectionnant le lien Thread Dump.

Sélectionnez l’onglet Étapes pour consulter les étapes de l’application.

Chaque étape peut comporter plusieurs tâches dont vous pouvez afficher les statistiques d’exécution, comme illustré ci-dessous.

Dans la page de détails de l’étape, vous pouvez lancer la visualisation DAG. Développez le lien DAG Visualization (Visualisation DAG) situé en haut de la page, comme indiqué ci-dessous.

Le graphique DAG (Direct Aclyic Graph) représente les différentes étapes de l’application. Chaque rectangle bleu dans le graphique représente une opération Spark appelée à partir de l’application.
Dans la page de détails de l’étape, vous pouvez également lancer la vue Chronologie de l’application. Développez le lien Event Timeline (Chronologie de l’événement) situé en haut de la page, comme indiqué ci-dessous.

Cette image affiche les événements Spark sous la forme d’une chronologie. La vue chronologie est disponible sur trois niveaux : entre différents travaux, dans un travail et dans une étape. L’image ci-dessus capture la vue chronologie pour une étape donnée.
Conseil
Si vous cochez la case Activer le zoom , vous pouvez faire défiler la vue chronologie vers la gauche et vers la droite.
Les autres onglets de l’interface utilisateur Spark fournissent également des informations utiles sur l’instance Spark.
- Onglet Stockage : si votre application crée un RDD, vous trouverez des informations sous l’onglet Stockage.
- Onglet Environnement : cet onglet fournit des informations utiles concernant votre instance Spark, par exemple :
- version de Scala ;
- répertoire du journal des événements associé au cluster ;
- nombre de cœurs d’exécuteur de l’application ;
Rechercher des informations sur les tâches terminées à l’aide du serveur d’historique Spark
Une fois qu’un travail est terminé, les informations concernant ce travail sont conservées dans le serveur d’historique Spark.
Pour lancer le serveur d’historique Spark, dans la page Vue d’ensemble, sélectionnez Serveur d’historique Spark sous Tableaux de bord du cluster.

Conseil
Vous pouvez également lancer l’interface utilisateur du serveur d’historique Spark à partir de celle d’Ambari. Pour lancer l’interface utilisateur d’Ambari, depuis le volet Vue d’ensemble, sélectionnez Accueil Ambari sous Tableaux de bord du cluster. À partir de l’interface utilisateur d’Ambari, accédez à Spark2>Quick Links>Spark2 History Server UI.
Les applications terminées s’affichent dans une liste. Sélectionnez un ID d’application pour obtenir plus d’informations sur l’application.
