Installer le notebook Jupyter sur votre ordinateur et le connecter à Apache Spark sur HDInsight
Cet article explique comment installer le notebook Jupyter avec les noyaux PySpark (pour Python) et Apache Spark (pour Scala) personnalisés à l’aide de Spark Magic. Vous connectez ensuite le bloc-notes à un cluster HDInsight.
Le processus d’installation de Jupyter et de connexion à Apache Spark sur HDInsight comprend quatre étapes principales.
- Configuration du cluster Spark.
- Installation du notebook Jupyter.
- Installation des noyaux PySpark et Spark avec Spark Magic.
- Configuration de Spark Magic pour accéder au cluster Spark sur HDInsight.
Pour plus d’informations sur les noyaux personnalisés et Spark Magic, consultez Noyaux disponibles pour les notebooks Jupyter avec les clusters HDInsight Spark Linux sur HDInsight.
Prérequis
Un cluster Apache Spark sur HDInsight. Pour obtenir des instructions, consultez Création de clusters Apache Spark dans Azure HDInsight. Le bloc-notes local se connecte au cluster HDInsight.
Connaissances sur l’utilisation des blocs-notes Jupyter Notebook avec Spark sur HDInsight.
Installer le notebook Jupyter sur votre ordinateur
Installez Python avant d’installer les notebooks Jupyter. Le distribution Anaconda installera à la fois Python et Jupyter Notebook.
Téléchargez le programme d’installation Anaconda pour votre plateforme et exécutez le programme d’installation. Lors de l’exécution de l’assistant d’installation, veillez à sélectionner l’option permettant d’ajouter Anaconda à votre variable PATH. Consultez aussi ces instructions d’installation de Jupyter à l’aide d’Anaconda.
Installer Spark magic
Entrez la commande
pip install sparkmagic==0.13.1pour installer Spark Magic pour les clusters HDInsight version 3.6 et 4.0. Consultez également la documentation sparkmagic.Assurez-vous que
ipywidgetsest correctement installé en exécutant la commande suivante :jupyter nbextension enable --py --sys-prefix widgetsnbextension
Installer les noyaux PySpark et Spark
Identifiez l’emplacement où
sparkmagicest installé en exécutant la commande suivante :pip show sparkmagicChangez ensuite votre répertoire de travail vers l’emplacement identifié avec la commande ci-dessus.
À partir de votre nouveau répertoire de travail, entrez une ou plusieurs des commandes ci-dessous pour installer chaque noyau souhaité :
Noyau Commande Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelfacultatif. Exécutez la commande suivante pour activer l’extension serveur :
jupyter serverextension enable --py sparkmagic
Configurer Spark Magic pour la connexion au cluster Spark HDInsight
Dans cette section, vous configurez Spark magic, que vous avez installé précédemment, pour qu’il se connecte à un cluster Apache Spark.
Démarrez l’interpréteur de commandes Python avec la commande suivante :
pythonLes informations de configuration de Jupyter sont généralement stockées dans le répertoire de base des utilisateurs. Entrez la commande suivante pour identifier le répertoire de base, puis créez un dossier nommé .sparkmagic. Le chemin complet est généré.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Dans le dossier
.sparkmagic, créez un fichier config.json dans lequel vous ajoutez l’extrait de code JSON suivant.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Apportez les modifications suivantes au fichier :
Valeur du modèle Nouvelle valeur {USERNAME} Nom de connexion au cluster ; la valeur par défaut est admin.{CLUSTERDNSNAME} Nom du cluster {BASE64ENCODEDPASSWORD} Mot de passe encodé en base64 pour votre mot de passe actuel. Vous pouvez générer un mot de passe en base64 sur https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Valeur à conserver si vous utilisez sparkmagic 0.12.7(clusters versions 3.5 et 3.6). Si vous utilisezsparkmagic 0.2.3(clusters version 3.4), remplacez-la par"should_heartbeat": true.Vous pouvez voir un exemple complet de fichier dans cet exemple config.json.
Conseil
Les pulsations sont envoyées pour vous assurer que les sessions ne sont pas divulguées. Lorsqu’un ordinateur se met en veille ou s’arrête, la pulsation n’est pas envoyée, causant ainsi le nettoyage de la session. Pour les clusters v3.4, si vous souhaitez désactiver ce comportement, vous pouvez définir la configuration Livy
livy.server.interactive.heartbeat.timeoutà0à partir de l’interface utilisateur Ambari. Pour les clusters v3.5, si vous ne définissez pas la configuration 3.5 ci-dessus, la session ne sera pas supprimée.Démarrez Jupyter. Utilisez la commande suivante depuis l’invite de commandes :
jupyter notebookVérifiez que vous pouvez utiliser Spark magic avec les noyaux. Effectuez ensuite les tâches suivantes.
a. Créer un nouveau bloc-notes. En haut à droite, sélectionnez New. Vous devez voir le noyau par défaut Python 2 ou Python 3 et les noyaux que vous avez installés. Les valeurs réelles peuvent varier en fonction de vos choix d’installation. Sélectionnez PySpark.
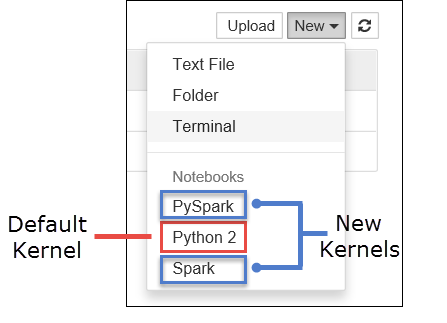
Important
Après avoir sélectionné New, passez en revue le code dans votre interpréteur de commandes pour rechercher les erreurs éventuelles. Si vous voyez l’erreur
TypeError: __init__() got an unexpected keyword argument 'io_loop', cela est probablement dû à un problème connu avec certaines versions de Tornado. Dans ce cas, arrêtez le noyau, puis passez à une version antérieure de Tornado en utilisant la commande suivante :pip install tornado==4.5.3.b. Exécutez l’extrait de code suivant :
%%sql SELECT * FROM hivesampletable LIMIT 5Votre connexion au cluster HDInsight sera testée, si vous parvenez à récupérer la sortie.
Si vous souhaitez mettre à jour la configuration du notebook pour vous connecter à un autre cluster, mettez à jour le fichier config.json avec les nouvelles valeurs, comme indiqué à l’étape 3 ci-dessus.
Pourquoi dois-je installer Jupyter sur mon ordinateur ?
Raisons d’installer Jupyter sur son ordinateur et de le connecter à un cluster Apache Spark sur HDInsight :
- offre la possibilité de créer vos blocs-notes localement, de tester votre application sur un cluster en cours d’exécution, puis de charger les blocs-notes dans le cluster. Vous pouvez charger les notebooks dans le cluster à l’aide du notebook Jupyter en cours d’exécution ou du cluster, ou en les enregistrant dans le dossier
/HdiNotebooksdu compte de stockage associé au cluster. Pour plus d’informations sur le stockage des notebooks, consultez Where are Jupyter Notebooks stored(Où sont stockés les notebooks Jupyter) ? - Les blocs-notes étant disponibles localement, vous pouvez vous connecter à différents clusters Spark selon les besoins de votre application.
- Vous pouvez utiliser GitHub pour implémenter un système de contrôle de code source et disposer du contrôle de version pour les blocs-notes. Vous pouvez également disposer d’un environnement de collaboration où plusieurs utilisateurs peuvent travailler avec le même bloc-notes.
- Vous pouvez travailler avec les blocs-notes localement sans avoir un cluster activé. Il vous suffit d’un cluster avec lequel tester vos blocs-notes, sans avoir à gérer manuellement vos blocs-notes ou à disposer d’un environnement de développement.
- Il peut être plus facile de configurer votre propre environnement de développement local que de configurer l’installation de Jupyter sur le cluster. Vous pouvez tirer parti de tous les logiciels que vous avez installés localement sans configurer un ou plusieurs clusters distants.
Avertissement
Lorsque Jupyter est installé sur votre ordinateur local, plusieurs utilisateurs peuvent exécuter le même bloc-notes sur le même cluster Spark en même temps. Dans ce cas, plusieurs sessions Livy sont créées. Si vous rencontrez un problème et que vous souhaitez effectuer un débogage, il sera difficile de savoir quelle session Livy appartient à quel utilisateur.
Étapes suivantes
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour