Configurer des flux de données dans Opérations Azure IoT
Important
Cette page inclut des instructions pour la gestion des composants Azure IoT Operations à l’aide des manifestes de déploiement Kubernetes, qui sont en version préliminaire. Cette fonctionnalité est fournie avec plusieurs limitations et ne doit pas être utilisée pour les charges de travail de production.
Pour connaître les conditions juridiques qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou plus généralement non encore en disponibilité générale, consultez l’Avenant aux conditions d’utilisation des préversions de Microsoft Azure.
Un flux de données est le chemin qu’empruntent les données de la source à la destination avec des transformations facultatives. Vous pouvez configurer le flux de données en créant une ressource personnalisée de Flux de données ou à l’aide du portail Studio d’Opérations Azure IoT. Un flux de données est constitué de trois parties : la source, la transformation et la destination.

Pour définir la source et la destination, vous devez configurer les points de terminaison de flux de données. La transformation est facultative et peut inclure des opérations telles que l’enrichissement des données, le filtrage des données et le mappage des données à un autre champ.
Important
Chaque flux de données doit avoir le point de terminaison par défaut de l’Agent MQTT Opérations Azure IoT local comme soit la source soit la destination.
Vous pouvez utiliser l’expérience des opérations dans Opérations Azure IoT pour créer un flux de données. L’expérience des opérations fournit une interface visuelle pour configurer le flux de données. Vous pouvez également utiliser Bicep pour créer un flux de données à l’aide d’un fichier de modèle Bicep ou utiliser Kubernetes pour créer un flux de données à l’aide d’un fichier YAML.
Poursuivez la lecture pour apprendre à configurer la source, la transformation et la destination.
Prérequis
Vous pouvez déployer des flux de données dès que vous disposez d’une instance d’Azure IoT Operations à l’aide du profil de flux de données et du point de terminaison par défaut. Toutefois, vous pouvez configurer des profils et des points de terminaison de flux de données pour personnaliser le flux de données.
Profil de flux de données
Si vous n’avez pas besoin de paramètres de mise à l’échelle différents pour vos flux de données, utilisez le profil de flux de données par défaut fourni par Azure IoT Operations. Pour savoir comment configurer un profil de flux de données, consultez Configurer des profils de flux de données.
Points de terminaison de flux de données
Les points de terminaison du flux de données sont nécessaires pour configurer la source et la destination du flux de données. Pour commencer rapidement, vous pouvez utiliser le point de terminaison de flux de données par défaut pour le répartiteur MQTT local. Vous pouvez également créer d’autres types de points de terminaison de flux de données tels que Kafka, Event Hubs ou Azure Data Lake Storage. Pour savoir comment configurer chaque type de point de terminaison de flux de données, consultez Configurer des points de terminaison de flux de données.
Démarrage
Une fois que vous avez les conditions préalables, vous pouvez commencer à créer un flux de données.
Pour créer un flux de données dans l’expérience opérations, sélectionnez Flux de données>Créer un flux de données. Ensuite, vous voyez la page dans laquelle vous pouvez configurer la source, la transformation et la destination du flux de données.

Passez en revue les sections suivantes pour apprendre à configurer les types d’opérations du flux de données.
Source
Pour configurer une source pour le flux de données, spécifiez la référence du point de terminaison et une liste de sources de données pour le point de terminaison. Choisissez l’une des options suivantes comme source du flux de données.
Si le point de terminaison par défaut n’est pas utilisé comme source, il doit être utilisé comme destination. Pour en savoir plus, consultez Dataflows doit utiliser le point de terminaison de l’Agent MQTT local.
Option 1 : utiliser le point de terminaison du courtier de messages par défaut comme source
Sous Détails de la source, sélectionnez Courtier de messages.

Saisissez les paramètres suivants pour la source du courtier de messages :
Setting Description Point de terminaison du flux de données Sélectionnez par défaut pour utiliser le point de terminaison du courtier de messages MQTT par défaut. Sujet Le filtre de sujet auquel s'abonner pour les messages entrants. Voir Configurer les rubriques MQTT ou Kafka. Schéma du message Le schéma à utiliser pour désérialiser les messages entrants. Voir Spécifier le schéma pour désérialiser les données. Sélectionnez Appliquer.
Option 2 : Utiliser l'actif comme source
Vous pouvez utiliser une ressource comme source du flux de données. L’utilisation d’un actif comme source n’est possible que dans le cadre de l’expérience opérationnelle.
Sous Détails de la source, sélectionnez Ressource.
Sélectionnez la ressource que vous souhaitez utiliser comme point de terminaison source.
Sélectionnez Continuer.
Une liste de points de données pour la ressource sélectionnée s’affiche.

Sélectionnez Appliquer pour utiliser la ressource comme point de terminaison source.
Lors de l’utilisation d’une ressource comme source, la définition de ressource est utilisée pour déduire le schéma du flux de données. La définition de ressource inclut le schéma des points de données de la ressource. Pour en savoir plus, consultez Gérer les configurations de ressources à distance.
Une fois configurées, les données de l'actif atteignent le flux de données via le courtier MQTT local. Par conséquent, lors de l’utilisation d’une ressource comme source, le flux de données utilise le point de terminaison par défaut de l’Agent MQTT local comme source en réalité.
Option 3 : utiliser un point de terminaison de flux de données MQTT ou Kafka personnalisé comme source
Si vous avez créé un point de terminaison de flux de données MQTT ou Kafka personnalisé (par exemple, pour l’utiliser avec Event Grid ou Event Hubs), vous pouvez l’utiliser comme source pour le flux de données. N’oubliez pas que les points de terminaison de type de stockage, comme Data Lake ou Fabric OneLake, ne peuvent pas être utilisés comme source.
Sous Détails de la source, sélectionnez Courtier de messages.

Saisissez les paramètres suivants pour la source du courtier de messages :
Setting Description Point de terminaison du flux de données Utilisez le bouton Resélectionner pour sélectionner un point de terminaison de flux de données MQTT ou Kafka personnalisé. Pour plus d’informations, consultez Configurer les points de terminaison de flux de données MQTT ou Configurer les points de terminaison de flux de données Azure Event Hubs et Kafka. Sujet Le filtre de sujet auquel s'abonner pour les messages entrants. Voir Configurer les rubriques MQTT ou Kafka. Schéma du message Le schéma à utiliser pour désérialiser les messages entrants. Voir Spécifier le schéma pour désérialiser les données. Sélectionnez Appliquer.
Configurer des sources de données (rubriques MQTT ou Kafka)
Vous pouvez spécifier plusieurs sujets MQTT ou Kafka dans une source sans avoir à modifier la configuration du point d’arrivée du flux de données. Cette flexibilité signifie que le même point de terminaison peut être réutilisé sur plusieurs flux de données, même si les rubriques varient. Pour plus d’informations, consultez Réutiliser les points de terminaison des flux de données.
Rubriques MQTT
Lorsque la source est un point de terminaison MQTT (Event Grid inclus), vous pouvez utiliser le filtre de rubrique MQTT pour vous abonner aux messages entrants. Le filtre de rubrique peut inclure des caractères génériques pour s’abonner à plusieurs rubriques. Par exemple, thermostats/+/telemetry/temperature/# s’abonne à tous les messages de télémétrie de température provenant de thermostats. Pour configurer les filtres de rubrique MQTT :
Dans les détails de la source du flux de données d'expérience des opérations, sélectionnez Message broker, puis utilisez le champ Sujet pour spécifier le filtre de sujet MQTT auquel s'abonner pour les messages entrants.
Remarque
Un seul filtre de sujet peut être spécifié dans l'expérience des opérations. Pour utiliser plusieurs filtres de sujets, utilisez Bicep ou Kubernetes.
Abonnements partagés
Pour utiliser des abonnements partagés avec des sources de courtier de messages, vous pouvez spécifier la rubrique d'abonnement partagée sous la forme de $shared/<GROUP_NAME>/<TOPIC_FILTER>.
Dans les détails de la source du flux de données d'expérience opérationnelle, sélectionnez Courtier de messages et utilisez le champ Sujet pour spécifier le groupe d'abonnement partagé et le sujet.
Si le nombre d'instances dans le profil de flux de données est supérieur à un, l'abonnement partagé est automatiquement activé pour tous les flux de données qui utilisent une source de courtier de messages. Dans ce cas, le préfixe $shared est ajouté et le nom du groupe d’abonnement partagé généré automatiquement. Par exemple, si vous disposez d'un profil de flux de données avec un nombre d'instances de 3 et que votre flux de données utilise un point de terminaison de courtier de messages comme source configuré avec des rubriques topic1 et topic2, ils sont automatiquement convertis en abonnements partagés comme $shared/<GENERATED_GROUP_NAME>/topic1 et $shared/<GENERATED_GROUP_NAME>/topic2.
Vous pouvez créer explicitement un sujet nommé $shared/mygroup/topic dans votre configuration. Cependant, l'ajout explicite du sujet $shared n'est pas recommandé puisque le préfixe $shared est automatiquement ajouté lorsque cela est nécessaire. Les flux de données peuvent effectuer des optimisations avec le nom du groupe s'il n'est pas défini. Par exemple, $share n'est pas défini et les flux de données doivent uniquement fonctionner sur le nom du sujet.
Important
Les flux de données nécessitant un abonnement partagé lorsque le nombre d'instances est supérieur à un sont importants lors de l'utilisation du courtier Event Grid MQTT comme source, car il ne prend pas en charge les abonnements partagés. Pour éviter de manquer des messages, définissez le nombre d'instances de profil de flux de données sur un lorsque vous utilisez le courtier Event Grid MQTT comme source. C’est-à-dire lorsque le flux de données est l’abonné et reçoit des messages depuis le cloud.
Rubriques Kafka
Lorsque la source est un point de terminaison Kafka (Event Hubs inclus), spécifiez les rubriques Kafka individuelles auxquelles s'abonner pour les messages entrants. Les caractères génériques ne sont pas pris en charge. Vous devez donc spécifier chaque rubrique statiquement.
Remarque
Lorsque vous utilisez Event Hubs via le point de terminaison Kafka, chaque hub d’événements individuel au sein de l’espace de noms est la rubrique Kafka. Par exemple, si vous avez un espace de noms Event Hubs avec deux hubs d’événements, thermostats et humidifiers, vous pouvez spécifier chaque hub d’événements en tant que rubrique Kafka.
Pour configurer les thèmes Kafka :
Dans les détails de la source du flux de données d'expérience des opérations, sélectionnez Message broker, puis utilisez le champ Sujet pour spécifier le filtre de sujet Kafka auquel s'abonner pour les messages entrants.
Remarque
Un seul filtre de sujet peut être spécifié dans l'expérience des opérations. Pour utiliser plusieurs filtres de sujets, utilisez Bicep ou Kubernetes.
Spécifiez le schéma source
Lorsque vous utilisez MQTT ou Kafka comme source, vous pouvez spécifier un schéma pour afficher la liste des points de données dans le portail d'expérience des opérations. L'utilisation d'un schéma pour désérialiser et valider les messages entrants n'est actuellement pas prise en charge.
Si la source est une ressource, le schéma est déduit automatiquement de la définition de ressource.
Conseil
Pour générer le schéma à partir d'un exemple de fichier de données, utilisez l'assistant de génération de schéma.
Pour configurer le schéma utilisé pour désérialiser les messages entrants à partir d’une source :
Dans les détails de la source du flux de données d'expérience opérationnelle, sélectionnez Message broker et utilisez le champ Schéma de message pour spécifier le schéma. Vous pouvez utiliser le bouton Charger pour charger d’abord un fichier de schéma. Pour en savoir plus, voir Comprendre les schémas de messages.
Pour en savoir plus, voir Comprendre les schémas de messages.
Transformation
L’opération de transformation a lieu là où vous pouvez transformer les données à la source avant de les envoyer à la destination. Les transformations sont facultatives. Si vous n’avez pas besoin d’apporter de modifications aux données, n’incluez pas l’opération de transformation dans la configuration du flux de données. Plusieurs transformations sont reliées sous forme de phases, quel que soit leur ordre dans la configuration. L’ordre des étapes est toujours :
- Enrichir : ajouter des données supplémentaires aux données sources en fonction d’un jeu de données et d’une condition à remplir.
- Filtrer : filtrer les données en fonction d’une condition.
- Cartographier, calculer, renommer ou ajouter une nouvelle propriété : déplacez les données d'un champ à un autre avec une conversion facultative.
Cette section est une introduction aux transformations de flux de données. Pour des informations plus détaillées, consultez Cartographier les données à l'aide de flux de données, Convertir les données à l'aide de conversions de flux de données et Enrichir les données à l'aide de flux de données.
Dans le portail d’expérience des opérations, sélectionnez Flux de données>Ajouter une transformation (facultatif).

Enrichir : Ajouter des données de référence
Pour enrichir les données, ajoutez d’abord un ensemble de données de référence dans le magasin d’état Azure IoT Operations. Le jeu de données est utilisé pour ajouter des données supplémentaires aux données sources en fonction d’une condition. La condition est spécifiée en tant que champ dans les données sources qui correspond à un champ du jeu de données.
Vous pouvez charger des exemples de données dans le magasin d’état à l’aide de l’interface de ligne de commande du magasin d’état CLI. Les noms de clés dans le magasin d’état correspondent à un ensemble de données dans la configuration du flux de données.
Actuellement, l’étape d’enrichissement n’est pas prise en charge dans l’expérience des opérations.
Si le jeu de données a un enregistrement avec le champ asset similaire à :
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Les données de la source avec le champ deviceId correspondant à thermostat1 ont les champs location et manufacturer disponibles dans les phases de filtre et de carte.
Pour plus d’informations sur la syntaxe des conditions, consultez Enrichir des données à l’aide de flux de données et Convertir des données à l’aide de flux de données.
Filtrer : Filtrer les données en fonction d’une condition
Pour filtrer les données selon une condition, vous pouvez utiliser la phase filter. La condition est spécifiée en tant que champ dans les données sources qui correspond à une valeur.
Sous Transformation (facultatif), sélectionnez Filtrer>Ajouter.

Entrez les paramètres requis.
Setting Description Condition de filtre La condition permettant de filtrer les données en fonction d'un champ dans les données source. Description Fournissez une description de la condition du filtre. Dans le champ de condition de filtre, entrez
@ou sélectionnez Ctrl + Espace pour choisir des points de données dans une liste déroulante.Vous pouvez entrer les propriétés des métadonnées MQTT à l’aide du format
@$metadata.user_properties.<property>ou@$metadata.topic. Vous pouvez également saisir des en-têtes $metadata en utilisant le format@$metadata.<header>. La syntaxe$metadataest seulement nécessaire pour les propriétés MQTT qui font partie de l’en-tête de message. Pour plus d’informations, consultez les références de champ.La condition peut utiliser les champs des données sources. Par exemple, vous pouvez utiliser une condition de filtre comme
@temperature > 20pour filtrer les données inférieures ou égales à 20 en fonction du champ de température.Sélectionnez Appliquer.
Mapper : Déplacer les données d’un champ vers un autre
Pour mapper les données à un autre champ avec une conversion facultative, vous pouvez utiliser l’opération map. La conversion est spécifiée en tant que formule qui utilise les champs dans les données sources.
Dans l'expérience des opérations, le mappage est actuellement pris en charge à l'aide des transformations de propriété Compute, Rename et New.
Compute
Vous pouvez utiliser la transformation Compute pour appliquer une formule aux données source. Cette opération permet d'appliquer une formule aux données sources et de stocker le champ de résultat.
Sous Transformation (facultatif), sélectionnez Calcul>Ajouter.

Entrez les paramètres requis.
Setting Description Sélectionnez la formule Choisissez une formule existante dans la liste déroulante ou sélectionnez Personnalisé pour saisir une formule manuellement. Sortie Spécifiez le nom d’affichage de sortie pour le résultat. Formule Saisissez la formule à appliquer aux données sources. Description Fournissez une description de la transformation. Dernière valeur connue Vous pouvez également utiliser la dernière valeur connue si la valeur actuelle n'est pas disponible. Vous pouvez saisir ou modifier une formule dans le champ Formule. La formule peut utiliser les champs des données sources. Entrez
@ou sélectionnez Ctrl + Espace pour choisir des points de données dans une liste déroulante.Vous pouvez entrer les propriétés des métadonnées MQTT à l’aide du format
@$metadata.user_properties.<property>ou@$metadata.topic. Vous pouvez également saisir des en-têtes $metadata en utilisant le format@$metadata.<header>. La syntaxe$metadataest seulement nécessaire pour les propriétés MQTT qui font partie de l’en-tête de message. Pour plus d’informations, consultez les références de champ.La formule peut utiliser les champs des données sources. Par exemple, vous pouvez utiliser le champ
temperaturedans les données source pour convertir la température en Celsius et la stocker dans le champ de sortietemperatureCelsius.Sélectionnez Appliquer.
Rename
Vous pouvez renommer un point de données à l’aide de la transformation Renommer. Cette opération est utilisée pour renommer un point de données dans les données source avec un nouveau nom. Le nouveau nom peut être utilisé dans les étapes ultérieures du flux de données.
Sous Transformer (facultatif), sélectionnez Renommer>Ajouter.

Entrez les paramètres requis.
Setting Description Datapoint Sélectionnez un point de données dans la liste déroulante ou entrez un en-tête $metadata. Nouveau nom de point de données Entrez le nouveau nom du point de données. Description Fournissez une description de la transformation. Entrez
@ou sélectionnez Ctrl + Espace pour choisir des points de données dans une liste déroulante.Vous pouvez entrer les propriétés des métadonnées MQTT à l’aide du format
@$metadata.user_properties.<property>ou@$metadata.topic. Vous pouvez également saisir des en-têtes $metadata en utilisant le format@$metadata.<header>. La syntaxe$metadataest seulement nécessaire pour les propriétés MQTT qui font partie de l’en-tête de message. Pour plus d’informations, consultez les références de champ.Sélectionnez Appliquer.
Nouvelle propriété
Vous pouvez ajouter une nouvelle propriété aux données source à l’aide de la transformation Nouvelle propriété. Cette opération permet d'ajouter une nouvelle propriété aux données sources. La nouvelle propriété peut être utilisée dans les étapes ultérieures du flux de données.
Sous Transformer (facultatif), sélectionnez Nouvelle propriété>Ajouter.

Entrez les paramètres requis.
Setting Description Clé de propriété Entrez la clé de la nouvelle propriété. Valeur de la propriété Entrez la valeur de la nouvelle propriété. Description Fournissez une description de la nouvelle propriété. Sélectionnez Appliquer.
Pour en savoir plus, consultez Mapper des données à l’aide de flux de données et Convertir des données à l’aide de flux de données.
Sérialiser des données en fonction d’un schéma
Si vous souhaitez sérialiser les données avant de les envoyer à la destination, vous devez spécifier un schéma et un format de sérialisation. Sinon, les données sont sérialisées au format JSON avec les types inférés. Les points de terminaison de stockage tels que Microsoft Fabric ou Azure Data Lake nécessitent un schéma pour garantir la cohérence des données. Les formats de sérialisation pris en charge sont Parquet et Delta.
Conseil
Pour générer le schéma à partir d'un exemple de fichier de données, utilisez l'assistant de génération de schéma.
Pour l'expérience des opérations, vous spécifiez le schéma et le format de sérialisation dans les détails du point de terminaison du flux de données. Les points de terminaison qui prennent en charge les formats de sérialisation sont Microsoft Fabric OneLake, Azure Data Lake Storage Gen 2, Azure Data Explorer et le stockage local. Par exemple, pour sérialiser les données au format Delta, vous devez télécharger un schéma dans le registre de schémas et le référencer dans la configuration du point de terminaison de destination du flux de données.

Pour plus d’informations sur le registre de schémas, consultez Comprendre les schémas de message.
Destination
Pour configurer une destination pour le flux de données, spécifiez la référence de point de terminaison et la destination de données. Vous pouvez spécifier une liste de destinations de données pour le point de terminaison.
Pour envoyer des données à une destination autre que le répartiteur MQTT local, créez un point de terminaison de flux de données. Pour en savoir plus, voir Configurer les points de terminaison du flux de données. Si la destination n’est pas l’Agent MQTT local, il doit être utilisé comme source. Pour en savoir plus, consultez Dataflows doit utiliser le point de terminaison de l’Agent MQTT local.
Important
Les points de terminaison de stockage nécessitent un schéma pour la sérialisation. Pour utiliser Dataflow avec Microsoft Fabric OneLake, Azure Data Lake Storage, Explorateur de données Azure ou Local Storage, vous devez spécifier une référence de schéma.
Sélectionnez le point de terminaison de flux de données à utiliser comme destination.

Les points de terminaison de stockage nécessitent un schéma pour la sérialisation. Si vous choisissez un point de terminaison de destination Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer ou Local Storage, vous devez spécifier une référence de schéma. Par exemple, pour sérialiser les données sur un point de terminaison Microsoft Fabric au format Delta, vous devez charger un schéma dans le registre de schémas et le référencer dans la configuration du point de terminaison de destination du flux de données.

Sélectionnez Continuer pour configurer la destination.
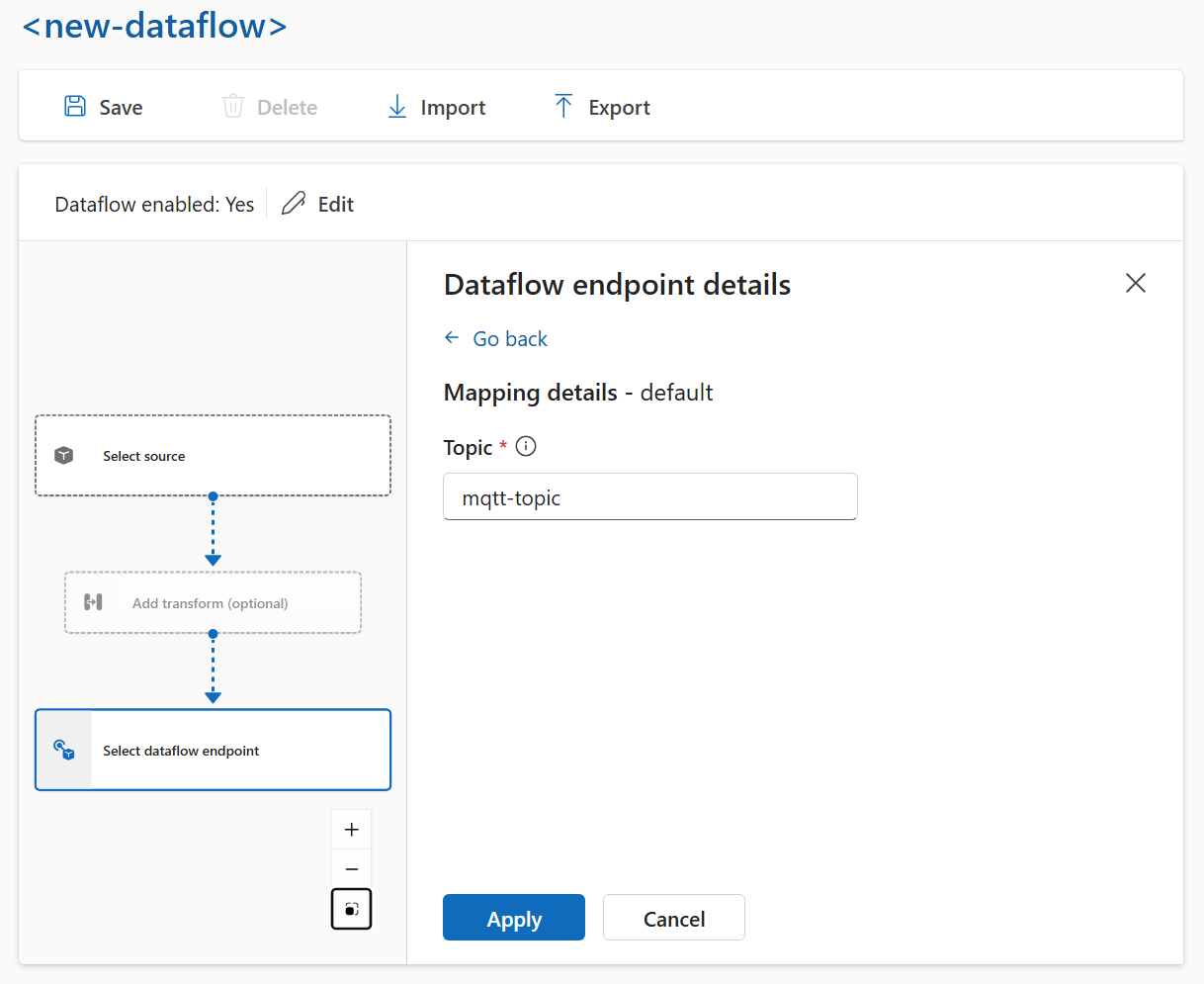
Entrez les paramètres requis pour la destination, y compris la rubrique ou la table à laquelle envoyer les données. Pour plus d’informations, consultez Configurer la destination des données (rubrique, conteneur ou table ).
Configurer la destination des données (rubrique, conteneur ou table)
Comme pour les sources de données, la destination de données est un concept utilisé pour conserver les points de terminaison de flux de données réutilisables sur plusieurs flux de données. Essentiellement, il représente le sous-répertoire dans la configuration du point de terminaison de flux de données. Par exemple, si le point de terminaison de flux de données est un point de terminaison de stockage, la destination des données est la table du compte de stockage. Si le point de terminaison de flux de données est un point de terminaison Kafka, la destination de données est la rubrique Kafka.
| Type de point de terminaison | Sens de destination des données | Description |
|---|---|---|
| MQTT (ou Event Grid) | Sujet | Rubrique MQTT dans laquelle les données sont envoyées. Seules les rubriques statiques sont prises en charge, pas de caractères génériques. |
| Kafka (ou Event Hubs) | Sujet | Rubrique Kafka dans laquelle les données sont envoyées. Seules les rubriques statiques sont prises en charge, pas de caractères génériques. Si le point de terminaison est un espace de noms Event Hubs, la destination des données est le hub d’événements individuel dans l’espace de noms. |
| Azure Data Lake Storage | Conteneur | Le conteneur dans le compte de stockage. Pas la table. |
| Microsoft Fabric OneLake | Table ou dossier | Correspond au type de chemin d’accès configuré pour le point de terminaison. |
| Explorateur de données Azure | Table | La table dans la base de données Azure Data Explorer. |
| Stockage local | Dossier | Nom du dossier ou du répertoire dans le montage de volume persistant de stockage local. Lors de l’utilisation d’Azure Container Storage activée par Azure Arc Cloud Ingest Edge Volumes, cela doit correspondre au paramètre spec.path de la sous-valeur que vous avez créée. |
Pour configurer la destination des données :
Lorsque vous utilisez l’expérience des opérations, le champ de destination de données est automatiquement interprété en fonction du type de point de terminaison. Par exemple, si le point de terminaison de flux de données est un point de terminaison de stockage, la page de détails de destination vous invite à entrer le nom du conteneur. Si le point de terminaison de flux de données est un point de terminaison MQTT, la page des détails de destination vous invite à entrer la rubrique, et ainsi de suite.
Exemple
L’exemple suivant illustre une configuration de flux de données utilisant le point de terminaison MQTT comme source et destination. La source filtre les données de la rubriques MQTT azure-iot-operations/data/thermostat. La transformation convertit la température en Fahrenheit et filtre les données où la température multipliée par l'humidité est inférieure à 100 000. La destination envoie les données à la rubrique MQTT factory.

Pour obtenir d’autres exemples de configurations de flux de données, consultez API REST Azure : flux de données et le démarrage rapide Bicep.
Vérifier qu’un flux de données fonctionne
Suivez le Tutoriel : pont MQTT bidirectionnel vers Azure Event Grid pour vérifier que le flux de données fonctionne.
Exporter la configuration du flux de données
Pour exporter la configuration du flux de données, vous pouvez utiliser l’expérience des opérations ou en exportant la ressource personnalisée Flux de données.
Sélectionnez le flux de données que vous souhaitez exporter et sélectionnez Exporter dans la barre d’outils.

Configuration appropriée du flux de données
Pour vous assurer que le flux de données fonctionne comme prévu, vérifiez les éléments suivants :
- Le point de terminaison du flux de données MQTT par défaut doit être utilisé comme source ou comme destination.
- Le profil de flux de données existe et est référencé dans la configuration du flux de données.
- La source est un point de terminaison MQTT, un point de terminaison Kafka ou une ressource. Les points de terminaison de type stockage ne peuvent pas être utilisés comme source.
- Lorsque vous utilisez Event Grid comme source, le nombre d’instances de profil de flux de données est défini sur 1, car l’Agent MQTT Event Grid ne prend pas en charge les abonnements partagés.
- Lorsque vous utilisez Event Hubs comme source, chaque Event Hub de l’espace de noms est une rubrique Kafka distincte et doit être spécifié comme la source de données.
- La transformation, si elle est utilisée, est configurée avec une syntaxe appropriée, y compris l’échappement de caractères spéciaux approprié.
- Lorsque vous utilisez des points de terminaison de type stockage comme destination, un schéma est spécifié.