Configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de série chronologique avec Python (SDKv1)
S’APPLIQUE À : SDK Python azureml v1
SDK Python azureml v1
Dans cet article, vous allez apprendre à configurer l’apprentissage AutoML pour des modèles de prévision de série chronologique avec ML automatisé Azure Machine Learning dans le SDK Python Azure Machine Learning.
Pour cela, vous devez :
- Préparer les données pour la modélisation de série chronologique.
- Configurer des paramètres spécifiques de série chronologique dans un objet
AutoMLConfig. - Exécuter des prédictions avec les données de série chronologique.
Pour une expérience à faible code, consultez le Tutoriel : Prévoir la demande à l’aide du Machine Learning automatisé pour un exemple de prévision de série chronologique utilisant le Machine Learning automatisé dans Azure Machine Learning Studio.
Contrairement aux méthodes classiques de séries chronologiques, dans Machine Learning automatisé, les valeurs des séries chronologiques sont ajoutées à un tableau croisé dynamique pour devenir des dimensions supplémentaires pour le régresseur, avec d’autres prédicteurs. Cette approche intègre plusieurs variables contextuelles et les relations qu’elles entretiennent au cours de l’apprentissage. Dans la mesure où plusieurs facteurs peuvent influencer une prévision, cette méthode s’aligne bien sur les scénarios de prévision du monde réel. Par exemple, lors de la prévision des ventes, les interactions entre les tendances historiques, les taux de change et les prix déterminent conjointement le résultat des ventes.
Prérequis
Pour cet article, vous avez besoin des éléments suivants :
Un espace de travail Azure Machine Learning. Pour créer l’espace de travail, consultez Créer des ressources d’espace de travail.
Cet article suppose une connaissance de base en matière de configuration d’une expérience de Machine Learning automatisé. Suivez le guide pratique pour connaître les principaux modèles de conception des expériences de Machine Learning automatisé.
Important
Les commandes python de cet article requièrent la dernière
azureml-train-automlversion du package.- Installez le dernier package
azureml-train-automldans votre environnement local. - Pour plus d’informations sur le dernier package
azureml-train-automl, consultez les notes de publication.
- Installez le dernier package
Données de formation et de validation
La principale différence entre un type de tâche de régression de prévision et un type de tâche de régression au sein de ML automatisé consiste à intégrer une fonctionnalité dans vos données de formation qui représente une série chronologique valide. Une série chronologique normale a une fréquence cohérente et bien définie et a une valeur à chaque point de l’exemple dans un intervalle de temps continu.
Important
Lors de l’entraînement d’un modèle pour la prévision de valeurs futures, assurez-vous que toutes les fonctionnalités utilisées pour l’entraînement peuvent être utilisées lors de l’exécution de prédictions à l’horizon prévu. Par exemple, lorsque vous créez une prévision de la demande, l’intégration d’une fonctionnalité pour le prix actuel du stock peut augmenter considérablement la précision de l’apprentissage. Toutefois, si vous prévoyez à un horizon lointain, vous ne pourrez peut-être pas prévoir avec précision les futures valeurs d’actions correspondant aux points de séries chronologiques futures et la précision du modèle pourrait en pâtir.
Vous pouvez spécifier des données de formation et de validation distincts directement dans l’objet AutoMLConfig. En savoir plus sur AutoMLConfig.
Pour les prévisions de série chronologique, seule la validation croisée à origine dynamique est utilisée pour la validation par défaut. Elle divise la série en données d’apprentissage et données de validation à l’aide d’un point d’origine. Les échantillons de validation croisée sont générés par glissement de l’origine temporelle. Cette stratégie permet de préserver l’intégrité des données des séries chronologiques et d’éliminer le risque de fuite de données.
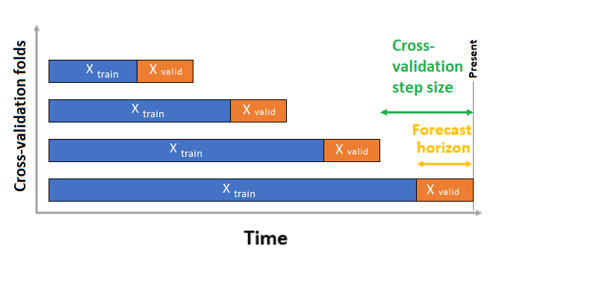
Transmettez vos données d’entraînement et de validation en tant que jeu de données unique au paramètre training_data. Définissez le nombre de plis de validation croisée avec le paramètre n_cross_validations et définissez le nombre de périodes entre deux plis de validation croisée consécutifs avec cv_step_size. Vous pouvez également laisser un ou les deux paramètres vides, et AutoML les définit automatiquement.
S’APPLIQUE À :SDK Python azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Vous pouvez également fournir vos propres données de validation. Pour en savoir plus, consultez Configurer les fractionnements de données et la validation croisée dans AutoML.
En savoir plus sur la façon dont AutoML applique la validation croisée afin d’empêcher les modèles de surajustement.
Configurer une expérience
L’objet AutoMLConfig définit les paramètres et les données nécessaires pour une tâche de Machine Learning automatisé. La configuration d’un modèle de prévisions est semblable à celle d’un modèle de régression standard, mais certains modèles et certaines options de configuration et étapes de caractérisation existent spécifiquement pour les données de séries chronologiques.
Modèles pris en charge
Le Machine Learning automatisé essaie automatiquement différents modèles et algorithmes dans le cadre du processus de création et de paramétrage du modèle. En tant qu’utilisateur, vous n’avez pas besoin de spécifier l’algorithme. Pour les expériences de prévision, les modèles natifs de série chronologique et de Deep Learning font partie du système de recommandation.
Conseil
Les modèles de régression traditionnels sont également testés dans le cadre du système de recommandation pour les expériences de prévision. Consultez la liste complète des modèles pris en charge dans la documentation de référence du Kit de développement logiciel (SDK).
Paramètres de configuration
Comme pour un problème de régression, vous définissez les paramètres d’entraînement standard comme type de tâche, le nombre d’itérations, les données d’apprentissage et le nombre de validations croisées. Les tâches de prévision requièrent les paramètres time_column_name et forecast_horizon pour configurer votre expérience. Si les données incluent plusieurs séries chronologiques, telles les données de ventes de plusieurs magasins ou des données énergétiques de différents états, le ML automatisé le détecte automatiquement et définit le paramètre time_series_id_column_names (préversion) pour vous. Vous pouvez également inclure des paramètres supplémentaires pour mieux configurer votre exécution. Consultez la section des configurations facultatives pour plus d’informations sur ce qui peut être inclus.
Important
L’identification automatique des séries chronologiques est actuellement disponible en préversion. Cette préversion est fournie sans contrat de niveau de service. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
| Nom du paramètre | Description |
|---|---|
time_column_name |
Permet de spécifier la colonne DateHeure dans les données d’entrée utilisées pour la génération de la série chronologique et la déduction de sa fréquence. |
forecast_horizon |
Définit le nombre de périodes à venir que vous souhaitez prévoir. L’horizon est exprimé en unités de fréquence de série chronologique. Les unités sont basées sur l’intervalle de temps de vos données d’apprentissage (par exemple mensuelles ou hebdomadaires) que l’analyste doit prévoir. |
Le code suivant,
- Utilise la classe
ForecastingParameterspour définir les paramètres de prévisions associés à l'apprentissage de l'expérience. - Définit le
time_column_namesur le champday_datetimedans le jeu de données. - Définit le
forecast_horizonsur 50 afin de prédire pour l’ensemble du jeu de tests.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Ces forecasting_parameters sont ensuite transmises à votre objet AutoMLConfig standard, ainsi que le type de tâche forecasting, la métrique principale, les critères de sortie et les données de formation.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
La quantité de données nécessaire pour entraîner un modèle de prévision avec le ML automatisé dépend des valeurs forecast_horizon, n_cross_validations, target_lags ou target_rolling_window_size qui sont spécifiées lors de la configuration de votre AutoMLConfig.
La formule suivante calcule la quantité de données d’historique nécessaire à la construction de fonctionnalités de série chronologique.
Quantité minimale de données d’historique nécessaire : (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Une Error exception est levée pour toutes les séries du jeu de données qui ne respectent pas la quantité de données d’historique nécessaire pour les paramètres appropriés spécifiés.
Étapes de caractérisation
Dans chaque expérience de Machine Learning automatisée, des techniques de mise à l’échelle automatique et de normalisation sont appliquées par défaut à vos données. Ces techniques sont des types de caractérisation qui aident certains algorithmes sensibles aux caractéristiques à des échelles différentes. En savoir plus sur les étapes de caractérisation par défaut dans Caractérisation dans AutoML
Toutefois, les étapes suivantes sont effectuées uniquement pour les types de tâches forecasting :
- Détecter un exemple de fréquence de série chronologique (par exemple horaire, quotidien, hebdomadaire) et créer de nouveaux enregistrements pour les points temporels absents pour rendre la série continue.
- Imputer les valeurs manquantes dans la cible (via un préremplissage) et les colonnes de fonctionnalités (via les valeurs de colonne médiane)
- Créer des fonctionnalités basées sur des identificateurs de série chronologique pour activer des effets fixes sur différentes séries
- Créer des caractéristiques temporelles pour faciliter l’apprentissage de modèles saisonniers
- Encoder des variables catégorielles avec des quantités numériques
- Détecter les séries chronologiques non stationnaires et les différencier automatiquement pour atténuer l’impact des racines d’unité.
Pour afficher la liste complète des caractéristiques traitées possibles générées à partir des données de séries chronologiques, consultez Classe TimeIndexFeaturizer.
Notes
Les étapes de caractérisation du Machine Learning automatisé (normalisation des fonctionnalités, gestion des données manquantes, conversion de texte en valeurs numériques, etc.) font partie du modèle sous-jacent. Lorsque vous utilisez le modèle pour des prédictions, les étapes de caractérisation qui sont appliquées pendant la formation sont appliquées automatiquement à vos données d’entrée.
Personnaliser la caractérisation
Vous pouvez également personnaliser vos paramètres de caractérisation pour vous assurer que les données et les caractéristiques utilisées pour effectuer l'apprentissage de votre modèle ML génèrent des prédictions pertinentes.
Les personnalisations prises en charge pour des tâches forecasting sont les suivantes :
| Personnalisation | Définition |
|---|---|
| Mise à jour de l’objectif de la colonne | Remplacer le type de caractéristique détecté automatiquement pour la colonne spécifiée. |
| Mise à jour des paramètres du transformateur | Mettre à jour les paramètres du transformateur spécifié. Prend actuellement en charge imputer (fill_value et median). |
| Suppression de colonnes | Indique les colonnes à supprimer de la caractérisation. |
Pour personnaliser les caractérisations avec le kit de développement logiciel (SDK), spécifiez "featurization": FeaturizationConfig dans votre objet AutoMLConfig. En savoir plus sur les caractérisations personnalisées.
Notes
La fonctionnalité de suppression de colonnes est déconseillée depuis la version 1.19 du kit de développement logiciel (SDK). Supprimez des colonnes de votre jeu de données dans le cadre du nettoyage des données, avant de les consommer dans votre expérience de ML automatisé.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Si vous utilisez le studio Azure Machine Learning pour votre expérience, consultez l’article sur la personnalisation de la caractérisation dans le studio.
Configurations facultatives
D’autres configurations facultatives sont disponibles pour les tâches de prévisions, telles que l’activation du Deep Learning et la spécification d’une agrégation de fenêtres dynamiques cibles. La liste complète des paramètres supplémentaires est disponible dans la documentation de référence du Kit de développement logiciel (SDK) ForecastingParameters.
Fréquence et agrégation des données cibles
Utilisez la fréquence, freq, paramètre pour éviter les défaillances causées par des données irrégulières. Les données irrégulières incluent des données qui ne suivent pas une cadence définie, comme les données horaires ou quotidiennes.
Pour des données très irrégulières ou des besoins différents de l’entreprise, les utilisateurs peuvent éventuellement définir la fréquence de prévision souhaitée, freq et spécifier la target_aggregation_function pour agréger la colonne cible de la série chronologique. Utilisez ces deux paramètres dans votre objet AutoMLConfig pour potentiellement réduire le temps de préparation des données.
Les opérations d’agrégation prises en charge pour les valeurs des colonnes cibles sont les suivantes :
| Fonction | Description |
|---|---|
sum |
Somme des valeurs cibles |
mean |
Moyenne des valeurs cibles |
min |
Valeur minimale d’une cible |
max |
Valeur maximale d’une cible |
Activez le Deep Learning
Notes
DNN est en préversion pour les prévisions dans le Machine Learning automatisé et n’est pas pris en charge pour les exécutions locales ou initiées dans Databricks.
Vous pouvez également appliquer le Deep Learning avec des réseaux neuronaux profonds, DNN, pour améliorer les scores de votre modèle. Le Deep Learning du ML automatisé permet de prévoir des données de série chronologique univariées et multivariées.
Les modèles Deep Learning ont trois capacités intrinsèques :
- Ils peuvent apprendre de mappages arbitraires des entrées aux sorties.
- Ils prennent en charge plusieurs entrées et sorties.
- Ils peuvent extraire automatiquement des modèles dans les données d’entrée qui s’étendent sur des séquences longues.
Pour activer le Deep Learning, définissez la enable_dnn=True dans l’objet AutoMLConfig.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Avertissement
Lorsque vous activez DNN pour les expériences créées avec le Kit de développement logiciel (SDK), les meilleures explications des modèles sont désactivées.
Pour activer DNN pour une expérience AutoML créée dans le studio Azure Machine Learning, consultez les paramètres de type de tâche dans la procédure de l’interface utilisateur Studio.
Agrégation de fenêtres dynamiques cibles
La dernière valeur de la cible constitue souvent la meilleure information dont un prédicteur peut disposer. Les agrégations de fenêtres dynamiques cibles permettent d’ajouter une agrégation dynamique de valeurs de données comme caractéristiques. Le fait de générer ces caractéristiques et de les utiliser comme données contextuelles supplémentaires contribue à la précision du modèle d’apprentissage.
Par exemple, imaginons que vous souhaitiez prédire la demande d’énergie. Nous pouvons ajouter une caractéristique de fenêtre dynamique de trois jours pour tenir compte des modifications thermiques des espaces chauffés. Dans cet exemple, créez cette fenêtre en définissant target_rolling_window_size= 3 dans le constructeur AutoMLConfig.
Le tableau montre l’ingénierie de caractéristiques obtenue qui se produit lors de l’application de l’agrégation de fenêtres. Les colonnes pour minimum, maximum et somme sont générées sur une fenêtre glissante de trois en fonction des paramètres définis. Chaque ligne comporte une nouvelle caractéristique calculée. Dans le cas du timestamp du 8 septembre 2017 à 4 h, les valeurs maximum, minimum et somme sont calculées suivant les valeurs de la demande du 8 septembre 2017 entre 1 h et 3 h. Cette fenêtre de trois se déplace de façon à remplir les données des lignes restantes.

Consultez un exemple de code Python tirant parti de la caractéristique d’agrégation de fenêtres dynamiques cibles.
Gestion des séries courtes
Le ML automatisé considère une série chronologique comme une série courte si le nombre de points de données est insuffisant pour mener les phases de formation et de validation du développement du modèle. Le nombre de points de données varie d'une expérience à l'autre et dépend du paramètre max_horizon, du nombre de divisions pour la validation croisée et de la longueur de la recherche arrière du modèle, c'est-à-dire le maximum d'historique nécessaire pour construire les caractéristiques de la série chronologique.
Le ML automatisé permet par défaut une gestion des séries courtes avec le paramètre short_series_handling_configuration de l'objet ForecastingParameters.
Pour activer la gestion des séries courtes, le paramètre freq doit également être défini. Pour définir une fréquence horaire, nous allons définir freq='H'. Affichez les options de la chaîne Frequency en visitant la section DataOffset objects de la page pandas Time series. Pour modifier le comportement par défaut, short_series_handling_configuration = 'auto', mettez à jour le paramètre short_series_handling_configuration dans votre objet ForecastingParameter.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
Le tableau suivant récapitule les paramètres disponibles pour short_series_handling_config.
| Paramètre | Description |
|---|---|
auto |
Valeur par défaut pour la gestion des séries courtes. - Si toutes les séries sont courtes, remplissez les données. - Si toutes les séries ne sont pas courtes, supprimez les séries courtes. |
pad |
Si short_series_handling_config = pad, le ML automatisé ajoute des valeurs aléatoires à chaque série courte trouvée. Vous trouverez ci-dessous la liste des types de colonnes et de leur contenu : - Colonnes d'objets avec « n'est pas un nombre » (NAN) - Colonnes numériques avec 0 - Colonnes booléennes/logiques avec False - La colonne cible est remplie avec des valeurs aléatoires, avec une moyenne de zéro et un écart type de 1. |
drop |
Si short_series_handling_config = drop, le ML automatisé supprime la série courte ; celle-ci ne sera donc pas utilisée pour l'apprentissage ou la prédiction. Les prédictions de ces séries renvoient NAN. |
None |
Aucune série n'est remplie ou supprimée |
Avertissement
Le remplissage peut avoir un impact sur la précision du modèle qui en résulte, car nous introduisons des données artificielles dans le seul but de terminer l'apprentissage sans rencontrer d'échecs. Si la plupart des séries sont courtes, vous pouvez également constater un impact sur les résultats de l'explicabilité.
Détection et gestion des séries chronologiques non stationnaires
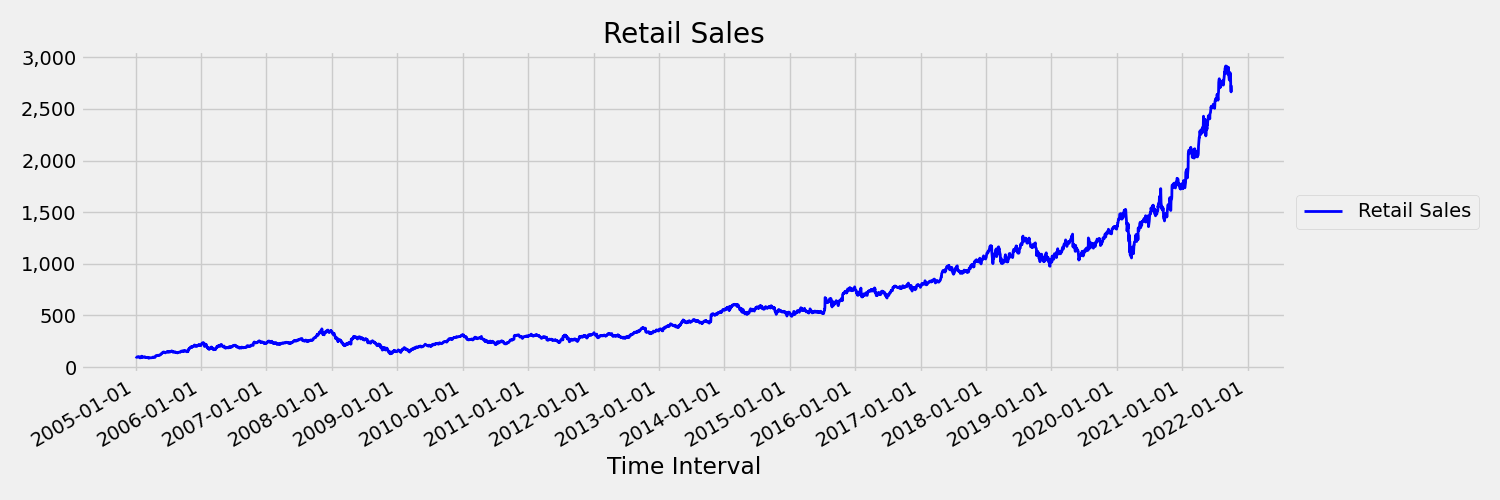
Une série chronologique dont les moments (moyenne et variance) changent au fil du temps est appelée série non stationnaire. Par exemple, les séries chronologiques qui montrent des tendances stochastiques sont non stationnaires par nature. Pour visualiser cela, l’image ci-dessous trace une série qui tend généralement à évoluer à la hausse. À présent, calculez et comparez les valeurs moyennes de la première et de la deuxième moitié de la série. Sont-elles identiques ? Ici, la moyenne de la série dans la première moitié du tracé est plus petite que dans la seconde moitié. Le fait que la moyenne de la série dépend de l’intervalle de temps qui est examiné est un exemple des moments qui varient avec le temps. Ici, la moyenne d’une série est le premier moment.
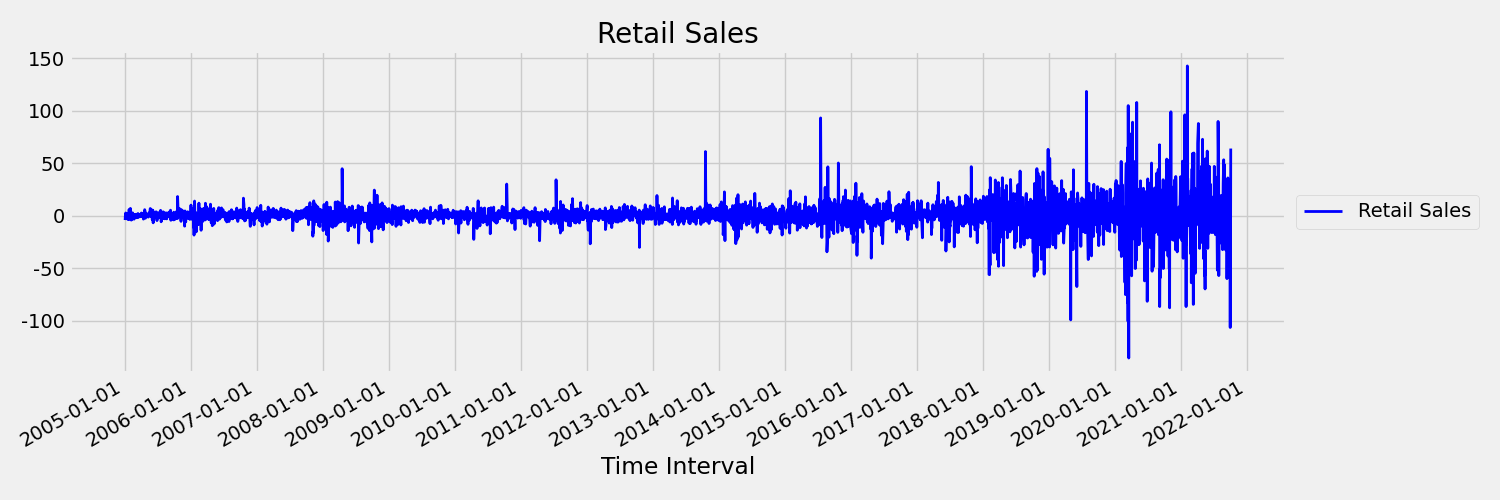
Examinons maintenant l’image qui trace la série d’origine en différences premières, $x_t = y_t - y_{t-1}$, $x_t$ étant le changement des ventes au détail, tandis que $y_t$ et $y_{t-1}$ représentent respectivement la série d’origine et son premier décalage. La moyenne de la série est à peu près constante, quel que soit l’intervalle de temps qui est examiné. Il s’agit d’un exemple d’une série chronologique stationnaire de premier ordre. La raison pour laquelle nous avons ajouté le terme « premier ordre » est que le premier moment (moyenne) ne change pas avec l’intervalle de temps. Il n’en va pas de même de la variance, qui est un deuxième moment.
Par nature, les modèles d’apprentissage automatique AutoML ne peuvent pas traiter les tendances stochastiques ou d'autres problèmes bien connus associés aux séries temporelles non stationnaires. non stationnaires. Par conséquent, leur justesse de prévision hors échantillon est « médiocre » si de telles tendances sont présentes.
AutoML analyse automatiquement le jeu de données de série chronologique afin de vérifier s’il est stationnaire ou non. Lorsque des séries temporelles non stationnaires sont détectées, AutoML applique automatiquement une transformation de différenciation pour atténuer l'effet des séries temporelles non stationnaires.
Exécuter l’expérience
Une fois votre objet AutoMLConfig prêt, vous pouvez soumettre l’expérience. Une fois le modèle terminé, récupérez la meilleure itération d’exécution.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Prévision avec le meilleur modèle
Utilisez l’itération de modèle optimale pour prévoir des valeurs pour les données qui n’ont pas été utilisées pour effectuer l'apprentissage du modèle.
Évaluation de la précision du modèle avec une prévision propagée
Avant de mettre un modèle en production, vous devez évaluer sa précision sur un jeu de test retenu à partir des données d’entraînement. Il est recommandé de mener une évaluation propagée qui fait avancer le prévisionniste formé dans le temps sur le jeu de test, en faisant la moyenne des métriques d’erreur sur plusieurs fenêtres de prédiction afin d’obtenir des estimations statistiquement robustes pour un ensemble de métriques choisies. Dans l’idéal, le jeu de test pour l’évaluation est long par rapport à l’horizon de prévision du modèle. Dans le cas contraire, les estimations des erreurs de prévision peuvent être statistiquement bruyantes et, par conséquent, moins fiables.
Par exemple, supposons que vous entraînez un modèle sur les ventes quotidiennes pour prédire la demande jusqu’à deux semaines (14 jours) dans le futur. Si suffisamment de données historiques sont disponibles, vous pouvez réserver les derniers mois voire une année des données pour le jeu de test. L’évaluation propagée commence par générer une prévision d’avance de 14 jours pour les deux premières semaines du jeu de test. Ensuite, le prévisionniste est avancé d’un certain nombre de jours dans le jeu de test, et vous générez une autre prévision de 14 jours à partir de la nouvelle position. Le processus se poursuit jusqu’à ce que vous arriviez à la fin du jeu de test.
Pour effectuer une évaluation propagée, vous appelez la méthode rolling_forecast de fitted_model, puis calculez les métriques souhaitées sur le résultat. Par exemple, supposons que vous disposez de fonctionnalités de jeu de tests dans un DataFrame pandas appelé test_features_df et que le test définisse des valeurs réelles de la cible dans un tableau numpy appelé test_target. Une évaluation propagée utilisant l’erreur carrée moyenne est illustrée dans l’exemple de code suivant :
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
Dans cet exemple, la taille d’étape de la prévision propagée est définie sur 1, ce qui signifie que le prévisionniste est avancé sur 1 période, ou 1 jour dans notre exemple de prédiction de la demande, à chaque itération. Le nombre total de prévisions retournées par rolling_forecast dépend donc de la longueur du jeu de test et de la taille de cette étape. Pour plus d’informations et d’exemples, consultez la documentation rolling_forecast() et le notebook Prévisions à partir des données de formation.
Prédiction dans l’avenir
La fonction forecast_quantiles() permet de spécifier quand les prédictions doivent démarrer, contrairement à la méthode predict(), qui est généralement utilisée pour les tâches de classification et de régression. La méthode forecast_quantiles() génère par défaut une prévision de point ou une prévision moyenne/médiane dénuée de cône d’incertitude. En savoir plus sur la prévision à partir du notebook de données de formation.
Dans l’exemple suivant, vous commencez par remplacer toutes les valeurs dans y_pred par NaN. L’origine de la prévision se situe à la fin dans ce cas. Toutefois, si vous avez remplacé uniquement le second semestre de y_pred par NaN, la fonction laisserait les valeurs numériques du premier semestre inchangées, mais prévoirait les valeurs NaN au second semestre. La fonction retourne à la fois les valeurs prédites et les fonctionnalités alignées.
Vous pouvez également utiliser le paramètre forecast_destination dans la fonction forecast_quantiles() pour prévoir les valeurs jusqu’à une date spécifiée.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Souvent, les clients souhaitent comprendre les prévisions à un quantile spécifique de la distribution. Par exemple, lorsque la prévision est utilisée pour contrôler un inventaire composé d’article d’épicerie ou de machines virtuelles pour un service cloud. Dans ce cas, le point de contrôle ressemble généralement à « nous voulons que l’élément soit en stock et non 99 % du temps ». L’exemple suivant montre comment spécifier les quantiles que vous souhaitez afficher pour vos prévisions, comme le 50e ou 95e centile. Si vous ne spécifiez pas de quantile, comme dans l’exemple de code ci-dessus, seules les prévisions du 50e centile sont générées.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Vous pouvez calculer des métriques de modèle comme une erreur quadratique moyenne (RMSE) ou une erreur moyenne de pourcentage absolu (MAPE) pour vous aider à estimer les performances des modèles. Pour obtenir un exemple, consultez la section Evaluate du notebook à la demande de partage Bike.
Une fois que la précision du modèle global a été déterminée, l’étape suivante la plus réaliste consiste à utiliser le modèle pour prévoir des valeurs futures inconnues.
Fournissez un jeu de données au même format que le jeu de test test_dataset, mais avec des dates/heures futures, et le leu de prédiction résultant correspond aux valeurs prédites pour chaque étape de la série chronologique. Supposons que les derniers enregistrements de la série chronologique dans le jeu de données aient été datés du 31/12/2018. Pour prévoir la demande pour le jour suivant (ou d’autant de périodes pour lesquelles vous avez besoin d’effectuer des prévisions, <= forecast_horizon), créez un seul enregistrement de série chronologique pour chaque magasin pour le 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Répétez les étapes nécessaires pour charger ces données futures dans une trame de données, puis exécutez best_run.forecast_quantiles(test_dataset) pour prédire les valeurs futures.
Notes
Les prédictions de l’exemple ne sont pas prises en charge pour les prévisions avec le ML automatisé lorsque target_lags et/ou target_rolling_window_size sont activés.
Prévisions à grande échelle
Il existe des scénarios dans lesquels un modèle Machine Learning unique est insuffisant et plusieurs modèles sont nécessaires. Par exemple, en prédisant les ventes pour chaque magasin individuel d’une marque, ou en adaptant une expérience à des utilisateurs individuels. La création d’un modèle pour chaque instance peut aboutir à des résultats améliorés sur de nombreux problèmes de Machine Learning.
Le regroupement est un concept dans les prévisions de série chronologique qui permet de combiner des séries chronologiques pour former un modèle individuel par groupe. Cette approche peut être particulièrement utile si vous avez des séries chronologiques qui nécessitent un lissage, un remplissage ou des entités dans le groupe pouvant tirer parti de l’historique ou des tendances d’autres entités. De nombreux modèles et prévisions de série chronologique sont des solutions optimisées par Machine Learning automatisé pour ces scénarios de prévision à grande échelle.
Nombreux modèles
La solution de nombreux modèles Azure Machine Learning avec Machine Learning automatisé permet aux utilisateurs d’effectuer l’apprentissage de millions de modèles en parallèle, ainsi que de les gérer. L’accélérateur de solution de nombreux modèles tire parti de pipelines Azure Machine Learning pour effectuer la formation du modèle. Plus précisément, un objet Pipeline et ParalleRunStep sont utilisés et requièrent des paramètres de configuration spécifiques définis par le biais de ParallelRunConfig.
Le diagramme suivant montre le flux de travail de la solution de nombreux modèles.

Le code suivant illustre les paramètres de clé dont les utilisateurs ont besoin pour configurer l’exécution de leurs nombreux modèles. Consultez le notebook de ML automatisé à plusieurs modèles pour obtenir un grand nombre d’exemples de modèles de prévision
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Prévision de série chronologique hiérarchique
Dans la plupart des applications, les clients doivent comprendre leurs prévisions aux niveaux macro et micro de l'entreprise. Les prévisions peuvent porter sur les ventes de produits dans différents lieux géographiques ou sur la demande de main-d'œuvre prévue pour les différentes organisations d'une entreprise. organisations d’une entreprise. La possibilité d’effectuer l’apprentissage d’un modèle Machine Learning pour faire de prévisions intelligentes sur la base de données de hiérarchie est essentielle.
Une série chronologique hiérarchique est une structure dans laquelle chacune des séries uniques est organisée dans une hiérarchie basée sur des dimensions telles que la géographie ou le type de produit. L’exemple suivant montre des données avec des attributs uniques formant une hiérarchie. Notre hiérarchie est définie par : le type de produit (par exemple, casque ou tablette), la catégorie de produit qui fractionne les types de produits en accessoires et appareils, et la région dans laquelle les produits sont vendus.

Pour mieux visualiser cela, les niveaux feuille de la hiérarchie contiennent toutes les séries chronologiques avec des combinaisons uniques de valeurs d’attribut. Chaque niveau supérieur dans la hiérarchie considère une dimension de moins pour la définition de la série chronologique, et agrège chaque ensemble de nœuds enfants à partir du niveau inférieur dans un nœud parent.

La solution de série chronologique hiérarchique s’appuie sur la solution de nombreux modèles et partage une configuration similaire.
Le code suivant illustre les paramètres clés pour configurer les exécutions de prévision de séries chronologiques hiérarchiques. Consultez le notebook de ML automatisé de série chronologique hiérarchique pour obtenir un exemple de bout en bout.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Exemples de notebooks
Consultez les exemples de notebooks de prévision pour obtenir des exemples de code détaillés de la configuration de prévision avancée, notamment :
- Détection et personnalisation de congé
- Validation croisée d’origine
- Décalages configurables
- Caractéristiques des agrégations des périodes mobiles
Étapes suivantes
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour