Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’espace de travail Azure Synapse Analytics vous laisse créer deux types de bases de données en plus d’un lac de données Spark :
- Bases de données de lac dans lesquelles vous pouvez définir des tables sur des données de lac à l’aide de notebooks Apache Spark, de modèles de base de données ou de Microsoft Dataverse (précédemment appelé Common Data Service). Ces tables peuvent être interrogées via le langage T-SQL (Transact-SQL) à l’aide du pool SQL serverless.
- Bases de données SQL dans lesquelles vous pouvez définir vos propres bases de données et tables directement à l’aide d’un pool SQL serverless. Vous pouvez utiliser T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE pour définir les objets et ajouter d’autres vues, procédures et fonctions inline-table-value SQL sur les tables.
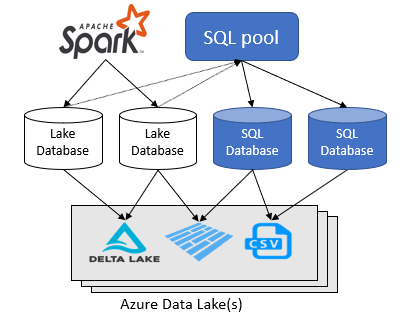
Cet article se concentre sur les bases de données de lac dans un pool SQL serverless dans Azure Synapse Analytics.
Azure Synapse Analytics vous permet de créer des bases de données de lac et des tables à l’aide de Spark ou d’un concepteur de base de données, puis d’analyser des données dans les bases de données de lac à l’aide du pool SQL serverless. Les bases de données de lac et les tables (sauvegardées sur Parquet ou CSV) créées sur les pools Apache Spark, les modèles de base de données de lac ou Dataverse, sont automatiquement disponibles pour l’interrogation avec le moteur du pool SQL serverless. Les bases de données de lac et les tables modifiées sont disponibles dans le pool SQL serverless après un certain temps. Il y a un délai avant que les modifications apportées dans Spark ou le concepteur de base de données apparaissent dans serverless.
Gérer une base de données de lac
Pour gérer les bases de données de lac créées dans Spark, vous pouvez utiliser les pools Apache Spark ou le concepteur de base de données. Par exemple, vous créez ou supprimez une base de données de lac par le biais d’un travail du pool Spark. Vous ne pouvez pas créer de base de données de lac ou les objets dans les bases de données de lac à l’aide du pool SQL serverless.
La base de données default Spark est disponible dans le contexte du pool SQL serverless en tant que base de données de lac appelée default.
Remarque
Vous ne pouvez pas créer une base de données de lac et une base de données SQL dans le pool SQL serverless avec le même nom.
Les tables dans les bases de données de lac ne peuvent pas être modifiées à partir d’un pool SQL serverless. Utilisez le concepteur de base de données ou les pools Apache Spark pour modifier une base de données de lac. Le pool SQL serverless vous laisse apporter les modifications suivantes dans une base de données de lac à l’aide de commandes T-SQL :
- Ajouter, modifier et supprimer des vues, de procédures, de fonctions inline table-value dans une base de données de lac.
- Ajouter et supprimer des utilisateurs Microsoft Entra à l’échelle de la base de données.
- Ajoutez des utilisateurs de base de données Microsoft Entra au rôle db_datareader ou supprimez-les de ce rôle. Les utilisateurs de base de données Microsoft Entra disposant du rôle db_datareader sont autorisés à lire toutes les tables de la base de données de lac, mais ils ne peuvent pas lire les données d’autres bases de données.
Modèle de sécurité
Les bases de données de lac et les tables sont sécurisées à deux niveaux :
- La couche de stockage sous-jacente en affectant aux utilisateurs Microsoft Entra l’une des options suivantes :
- Contrôle d’accès en fonction du rôle Azure (Azure RBAC)
- Rôle contrôle d’accès en fonction des attributs Azure (Azure ABAC)
- Autorisations de la liste contrôle d’accès (ACL)
- La couche SQL dans laquelle vous pouvez définir un utilisateur Microsoft Entra et lui accorder des autorisations SQL pour sélectionner
SELECTdes données dans des tables faisant référence aux données de lac.
Modèle de sécurité du lac
L’accès aux fichiers de la base de données de lac est contrôlé à l’aide des autorisations de lac sur la couche de stockage. Seuls les utilisateurs Microsoft Entra peuvent utiliser des tables dans les bases de données de lac, et ils peuvent accéder aux données de lac à l’aide de leurs propres identités.
Vous pouvez accorder l’accès aux données sous-jacentes utilisées pour les tables externes à un principal de sécurité, par exemple : un utilisateur, une application Microsoft Entra avec un principal de service affecté ou un groupe de sécurité. Pour l’accès aux données, accordez les deux autorisations suivantes :
- Accordez l’autorisation
read (R)sur les fichiers (par exemple, les fichiers de données sous-jacents de la table). - Accordez l’autorisation
execute (X)sur le dossier où les fichiers sont stockés et sur chaque dossier parent jusqu’à la racine. Pour plus d’informations sur ces autorisations, consultez Listes de contrôle d’accès (ACL).
Par exemple, dans https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/, les principaux de sécurité ont besoin de ce qui suit :
- autorisations
execute (X)sur tous les dossiers allant de<fs>àmyparquettable. - autorisations
read (R)surmyparquettableet sur les fichiers qui se trouvent dans ce dossier, pour pouvoir lire une table dans une base de données (synchronisée ou d’origine).
Si un principal de sécurité nécessite la capacité à créer ou à supprimer des objets dans une base de données, des autorisations write (W) supplémentaires sont requises sur les dossiers et les fichiers du dossier entrepôt. La modification des objets d’une base de données n’est pas possible à partir d’un pool SQL serverless, mais uniquement à partir de pools Spark ou du concepteur de bases de données.
Modèle de sécurité SQL
L’espace de travail Azure Synapse fournit un point de terminaison T-SQL qui vous laisse interroger la base de données de lac à l’aide du pool SQL serverless. En plus de l’accès aux données, l’interface SQL vous autorisé à contrôler qui peut accéder aux tables. Vous devez permettre à un utilisateur d’accéder aux bases de données de lac partagées à l’aide du pool SQL serverless. Il existe deux types d’utilisateurs qui peuvent accéder aux bases de données de lac :
- Administrateurs : attribuez le rôle d’espace de travail Administrateur Synapse SQL ou le rôle au niveau du serveur sysadmin à l’intérieur du pool SQL serverless. Ce rôle a un contrôle total sur toutes les bases de données. Les rôles Administrateur Synapse et Administrateur Synapse SQL disposent également de toutes les autorisations sur tous les objets dans un pool SQL serverless, par défaut.
- Lecteurs d’espace de travail : attribuez les autorisations au niveau du serveur GRANT CONNECT ANY DATABASE et GRANT SELECT ALL USER SECURABLES sur un pool SQL serverless à une connexion pour lui permettre d’accéder à toute base de données et de lire toute base de données. Cela peut être un bon choix pour l’attribution d’un accès en lecture/non-administrateur à un utilisateur.
- Lecteurs de base de données : créez des utilisateurs de base de données à partir de Microsoft Entra ID dans votre base de données de lac et ajoutez-les au rôle db_datareader, ce qui leur permet de lire des données dans la base de données de lac.
En savoir plus sur la définition du contrôle d’accès sur les bases de données partagées.
Objets SQL personnalisés dans les bases de données de lac
Les bases de données de lac autorisent la création d’objets T-SQL personnalisés, tels que des schémas, des procédures, des vues et des fonctions inline table-value (iTVF). Pour créer des objets SQL personnalisés, vous DEVEZ créer un schéma dans lequel vous allez placer les objets. Les objets SQL personnalisés ne peuvent pas être placés dans le schéma dbo, car celui-ci est réservé aux tables de lac définies dans Spark, dans le concepteur de base de données ou dans Dataverse.
Important
Vous devez créer un schéma SQL personnalisé dans lequel vous allez placer vos objets SQL. Les objets SQL personnalisés ne peuvent pas être placés dans le schéma dbo. Le schéma dbo est réservé aux tables de lac créées à l’origine dans Spark ou dans le concepteur de base de données.
Exemples
Créer un lecteur de base de données SQL dans une base de données de lac
Dans cet exemple, nous ajoutons dans la base de données de lac un utilisateur Microsoft Entra qui peut lire des données via des tables partagées. Les utilisateurs sont ajoutés dans la base de données de lac via le pool SQL serverless. Ensuite, attribuez le rôle db_datareader à l’utilisateur afin qu’il puisse lire les données.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Créer un lecteur de données au niveau de l’espace de travail
Une connexion avec les autorisations GRANT CONNECT ANY DATABASE et GRANT SELECT ALL USER SECURABLES est en mesure de lire toutes les tables avec le pool SQL serverless, mais pas de créer des bases de données SQL ou de modifier les objets qu’elles contiennent.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Ce script vous laisse créer des utilisateurs sans privilèges d’administrateur qui peuvent lire n’importe quelle table dans les bases de données de lac.
Créer une base de données Spark et s’y connecter avec le pool SQL serverless
Commencez par créer une base de données Spark nommée mytestlakedb à l’aide d’un cluster Spark que vous avez déjà créé dans votre espace de travail. Pour cela, vous pouvez par exemple utiliser un notebook C# Spark avec l’instruction .NET pour Spark suivante :
spark.sql("CREATE DATABASE mytestlakedb")
Après un bref délai, vous pouvez voir la base de données de lac depuis le pool SQL serverless. Exécutez par exemple l’instruction suivante à partir du pool SQL serverless.
SELECT * FROM sys.databases;
Vérifiez que mytestlakedb est inclus dans les résultats.
Créer des objets SQL personnalisés dans une base de données de lac
L’exemple suivant montre comment créer une vue, une procédure et une fonction inline table-value (iTVF) personnalisée dans le schéma reports :
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Contenu connexe
- Métadonnées partagées Azure Synapse Analytics
- Tables de métadonnées partagées Azure Synapse Analytics
- Démarrage rapide : Créer une base de données de lac en tirant parti des modèles de base de données
- Tutoriel : Utiliser un pool SQL serverless avec Power BI Desktop et créer un rapport
- Synchroniser Apache Spark pour les définitions de tables externes d’Azure Synapse dans le pool SQL serverless
- Tutoriel : Explorer et analyser des lacs de données avec un pool SQL serverless