Sécurité, accès et opérations pour les migrations Teradata
Cet article est la troisième partie d’une série de sept parties qui fournit des conseils sur la migration de Teradata vers Azure Synapse Analytics. Cet article présente les bonnes pratiques pour les opérations d’accès à la sécurité.
Considérations relatives à la sécurité
Cet article décrit les méthodes de connexion pour les environnements Teradata hérités existants et comment ils peuvent être migrés vers Azure Synapse Analytics avec un risque et un impact minimaux sur l’utilisateur.
Cet article part du principe qu’il est nécessaire de migrer les méthodes de connexion existantes et la structure utilisateur/rôle/autorisation en l’état. Sinon, utilisez le portail Azure pour créer et gérer un nouveau régime de sécurité.
Pour plus d’informations sur les options de sécurité Azure Synapse, consultez le livre blanc sur la sécurité.
Connexion et authentification
Options d’autorisation Teradata
Conseil
L’authentification dans Teradata et Azure Synapse peut être effectuée « dans la base de données » ou via des méthodes externes.
Teradata prend en charge plusieurs mécanismes pour la connexion et l’autorisation. Les valeurs de mécanisme valides sont les suivantes :
TD1, qui sélectionne Teradata 1 comme mécanisme d’authentification. Le nom d’utilisateur et le mot de passe sont obligatoires.
TD2, qui sélectionne Teradata 2 comme mécanisme d’authentification. Le nom d’utilisateur et le mot de passe sont obligatoires.
TDNEGO, qui sélectionne automatiquement l’un des mécanismes d’authentification en fonction de la stratégie, sans intervention de l’utilisateur.
LDAP, qui sélectionne Lightweight Directory Access Protocol (LDAP) comme mécanisme d’authentification. L’application fournit le nom d’utilisateur et le mot de passe.
KRB5, qui sélectionne Kerberos (KRB5) sur les clients Windows travaillant avec des serveurs Windows. Pour se connecter à l’aide de KRB5, l’utilisateur doit fournir un domaine, un nom d’utilisateur et un mot de passe. Le domaine est spécifié en définissant le nom d’utilisateur sur
MyUserName@MyDomain.NTLM, qui sélectionne NTLM sur les clients Windows travaillant avec des serveurs Windows. L’application fournit le nom d’utilisateur et le mot de passe.
KRB5 (Kerberos), KRB5C (Kerberos Compatibility), NTLM (NT LAN Manager) et NTLMC (NT LAN Manager Compatibility) sont destinés uniquement à Windows.
Options d’autorisation Azure Synapse
Azure Synapse prend en charge deux options de base pour la connexion et l’autorisation :
Authentification SQL : l’authentification SQL se fait via une connexion de base de données qui inclut un identificateur de base de données, un ID utilisateur et un mot de passe, ainsi que d’autres paramètres facultatifs. Il s’agit d’une fonctionnalité équivalente aux connexions Teradata TD1, TD2 et par défaut.
Authentification Microsoft Entra : avec l’authentification Microsoft Entra, vous pouvez gérer de manière centralisée les identités des utilisateurs de base de données et d’autres services Microsoft dans un emplacement central. La gestion centralisée des ID fournit un emplacement unique pour gérer les utilisateurs SQL Data Warehouse et elle simplifie la gestion des autorisations. Microsoft Entra ID peut également prendre en charge les connexions aux services LDAP et Kerberos, par exemple, Microsoft Entra ID peut être utilisé pour se connecter à des annuaires LDAP existants s’ils doivent rester en place après la migration de la base de données.
Utilisateurs, rôles et autorisations
Vue d’ensemble
Conseil
Une planification générale est essentielle pour un projet de migration réussi.
Teradata et Azure Synapse implémentent le contrôle d’accès à la base de données via une combinaison d’utilisateurs, de rôles et d’autorisations. Les deux utilisent des instructions SQL CREATE USER et CREATE ROLE standard pour définir des utilisateurs et des rôles, et des instructions GRANT et REVOKE pour attribuer ou supprimer des autorisations pour ces utilisateurs et/ou rôles.
Conseil
L’automatisation des processus de migration est recommandée pour réduire le temps écoulé et l’étendue des erreurs.
Conceptuellement, les deux bases de données sont similaires et il peut être possible d’automatiser la migration des ID utilisateur, des rôles et des autorisations existants dans une certaine mesure. Migrez ces données en extrayant les informations héritées existantes sur l’utilisateur et le rôle des tables de catalogue système Teradata et en générant des instructions équivalentes CREATE USER et CREATE ROLE correspondantes à exécuter dans Azure Synapse pour recréer la même hiérarchie utilisateur/rôle.
Après l’extraction des données, utilisez des tables de catalogue système Teradata pour générer des instructions GRANT équivalentes afin d’attribuer des autorisations (où il existe un équivalent). Le diagramme suivant montre comment utiliser les métadonnées existantes pour générer les SQL nécessaires.
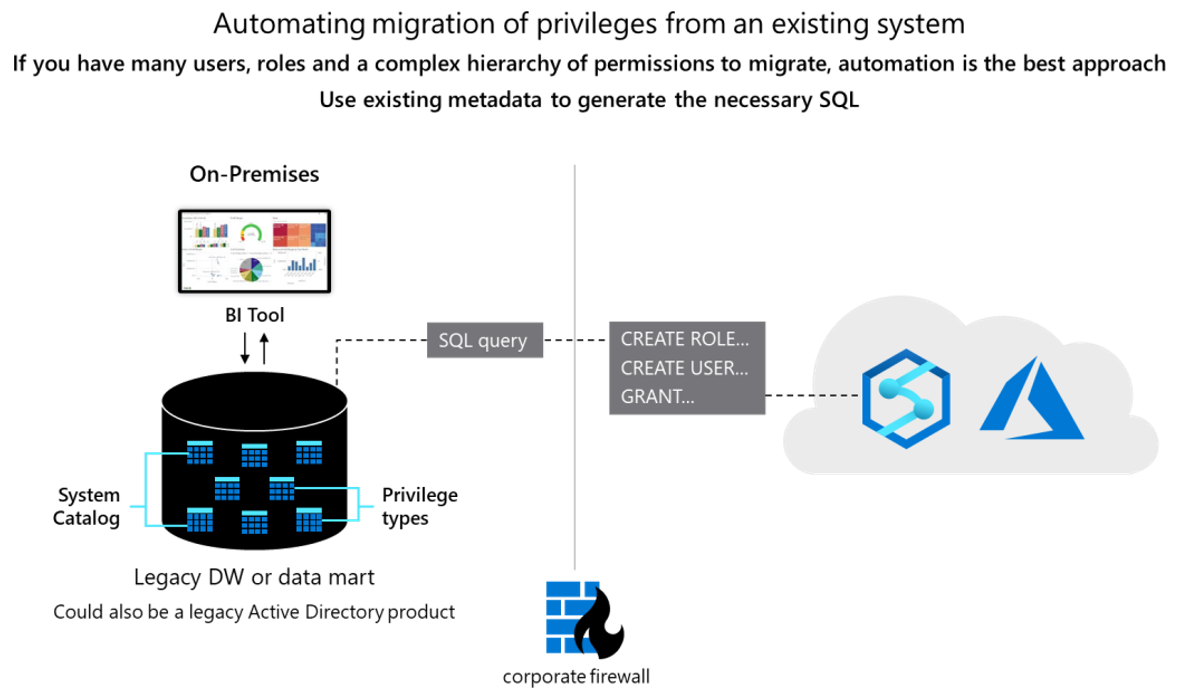
Utilisateurs et rôles
Conseil
La migration d’un entrepôt de données nécessite plus que de simples tables, vues et instructions SQL.
Les informations sur les utilisateurs et rôles actuels dans un système Teradata se trouvent dans les tables de catalogue système DBC.USERS (ou DBC.DATABASES) et DBC.ROLEMEMBERS. Interrogez ces tables (si l’utilisateur dispose de l’accès SELECT à ces tables) pour obtenir les listes actuelles des utilisateurs et rôles définis dans le système. Voici quelques exemples de requêtes pour effectuer cette opération pour des utilisateurs individuels :
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
Ces exemples modifient les instructions SELECT pour produire un jeu de résultats qui est une série d’instructions CREATE USER et CREATE ROLE, en incluant le texte approprié en tant que littéral dans l’instruction SELECT.
Il n’existe aucun moyen de récupérer les mots de passe existants. Vous devez donc implémenter un schéma pour allouer de nouveaux mots de passe initiaux sur Azure Synapse.
Autorisations
Conseil
Il existe des autorisations Azure Synapse équivalentes pour les opérations de base de données standard telles que DML et DDL.
Dans un système Teradata, les tables système DBC.ALLRIGHTS et DBC.ALLROLERIGHTS contiennent les droits d’accès pour les utilisateurs et les rôles. Interrogez ces tables (si l’utilisateur dispose de l’accès SELECT à ces tables) pour obtenir les listes actuelles de droits d’accès définis dans le système. Voici quelques exemples de requêtes pour des utilisateurs individuels :
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
Modifiez ces exemples d’instructions SELECT pour produire un jeu de résultats qui est une série d’instructions GRANT en incluant le texte approprié en tant que littéral dans l’instruction SELECT.
Utilisez la table AccessRightsAbbv pour rechercher le texte intégral du droit d’accès, car la clé de jointure est un champ « type » abrégé. Consultez le tableau suivant pour obtenir la liste des droits d’accès Teradata et leur équivalent dans Azure Synapse.
| Nom de l’autorisation Teradata | Type Teradata | Équivalent Azure Synapse |
|---|---|---|
| ABORT SESSION | AS | KILL DATABASE CONNECTION |
| ALTER EXTERNAL PROCEDURE | AE | 4 |
| ALTER FUNCTION | AF | ALTER FUNCTION |
| ALTER PROCEDURE | AP | ALTER PROCEDURE |
| CHECKPOINT | CP | CHECKPOINT |
| CREATE AUTHORIZATION | CA | CREATE LOGIN |
| CREATE DATABASE | CD | CREATE DATABASE |
| CREATE EXTERNALPROCEDURE | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| CREATE GLOP | GC | 3 |
| CREATE MACRO | CM | CREATE PROCEDURE 2 |
| CREATE OWNER PROCEDURE | OP | CREATE PROCEDURE |
| CREATE PROCEDURE | PC | CREATE PROCEDURE |
| CREATE PROFILE | CO | CREATE LOGIN 1 |
| CREATE ROLE | CR | CREATE ROLE |
| DROP DATABASE | DD | DROP DATABASE |
| DROP FUNCTION | DF | DROP FUNCTION |
| DROP GLOP | GD | 3 |
| DROP MACRO | DM | DROP PROCEDURE 2 |
| DROP PROCEDURE | PD | DELETE PROCEDURE |
| DROP PROFILE | DO | DROP LOGIN 1 |
| DROP ROLE | DR | DELETE ROLE |
| DROP TABLE | DT | DROP TABLE |
| DROP_TRIGGER | DG | 3 |
| DROP USER | DU | DROP USER |
| DROP VIEW | DV | DROP VIEW |
| DUMP | DP | 4 |
| EXECUTE | E | Exécutez |
| EXECUTE FUNCTION | EF | Exécutez |
| EXECUTE PROCEDURE | PE | Exécutez |
| GLOP MEMBER | GM | 3 |
| INDEX | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | MS | 5 |
| OVERRIDE DUMP CONSTRAINT | OA | 4 |
| OVERRIDE RESTORE CONSTRAINT | OR | 4 |
| REFERENCES | RF | REFERENCES |
| REPLCONTROL | RO | 5 |
| RESTORE | RS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| SHOW | SH | 3 |
| UPDATE | U | UPDATE |
Notes de la table AccessRightsAbbv :
Teradata
PROFILEest fonctionnellement équivalent àLOGINdans Azure Synapse.Le tableau suivant récapitule les différences entre les macros et les procédures stockées dans Teradata. Dans Azure Synapse, les procédures fournissent les fonctionnalités décrites dans le tableau.
Macro Procédure stockée Contient SQL Contient SQL Peut contenir des commandes BTEQ dot Contient le SPL complet Peut recevoir des valeurs de paramètre qui lui sont transmises Peut recevoir des valeurs de paramètre qui lui sont transmises Peut récupérer une ou plusieurs lignes Doit utiliser un curseur pour récupérer plusieurs lignes Stockée dans l’espace DBC PERM Stockée dans DATABASE ou USER PERM Retourne des lignes au client Peut retourner une ou plusieurs valeurs au client en tant que paramètres SHOW,GLOPetTRIGGERn’ont pas d’équivalent direct dans Azure Synapse.Ces fonctionnalités sont gérées automatiquement par le système dans Azure Synapse. Consultez Considérations opérationnelles.
Dans Azure Synapse, ces fonctionnalités sont gérées en dehors de la base de données.
Pour plus d’informations sur les droits d’accès dans Azure Synapse, consultez Autorisations de sécurité Azure Synapse Analytics.
Considérations opérationnelles
Conseil
Les tâches opérationnelles sont nécessaires pour assurer l’efficacité de tout entrepôt de données.
Cette section explique comment implémenter des tâches opérationnelles Teradata classiques dans Azure Synapse avec un risque et un impact minimaux sur les utilisateurs.
Comme pour tous les produits de l’entrepôt de données, une fois en production, il existe des tâches de gestion en cours qui sont nécessaires pour maintenir l’exécution efficace du système et fournir des données pour la surveillance et l’audit. L’utilisation des ressources et la planification de la capacité pour une croissance future se situent également dans cette catégorie, comme la sauvegarde/restauration des données.
Bien que les tâches conceptuelles de gestion et d’exploitation pour différents entrepôts de données soient similaires, les implémentations individuelles peuvent différer. En général, les produits modernes basés sur le cloud tels qu’Azure Synapse ont tendance à incorporer une approche plus automatisée et « gérée par le système » (par opposition à une approche plus « manuelle » dans les entrepôts de données hérités tels que Teradata).
Les sections suivantes comparent les options Teradata et Azure Synapse pour différentes tâches opérationnelles.
Tâches de nettoyage
Conseil
Les tâches de nettoyage permettent à un entrepôt de production de fonctionner efficacement et d’optimiser l’utilisation des ressources telles que le stockage.
Dans la plupart des environnements d’entrepôt de données hérités, il est nécessaire d’effectuer des tâches régulières de « nettoyage », telles que la récupération de l’espace de stockage sur disque qui peut être libéré en supprimant les anciennes versions des lignes mises à jour ou supprimées, ou en réorganisant les fichiers journaux de données ou les blocs d’index pour plus d’efficacité. La collecte de statistiques est également une tâche potentiellement chronophage. La collecte des statistiques est requise après une ingestion de données en bloc pour fournir à l’optimiseur de requête des données à jour pour la génération de base des plans d’exécution des requêtes.
Teradata recommande de collecter des statistiques comme suit :
Collectez des statistiques sur les tables non renseignées pour configurer l’histogramme d’intervalle utilisé dans le traitement interne. Cette collection initiale accélère les collections de statistiques suivantes. Veillez à récoltez les statistiques une fois les données ajoutées.
Collectez les statistiques de phase de prototype pour les tables nouvellement remplies.
Collectez les statistiques de phase de production, après un pourcentage significatif de modifications de la table ou de la partition (environ 10 % de lignes). Pour les volumes élevés de valeurs non uniques, telles que les dates ou les horodatages, il peut être avantageux de recollecter à 7 %.
Collectez les statistiques de phase de production une fois que vous avez créé des utilisateurs et appliqué des charges de requête réelles à la base de données (jusqu’à environ trois mois d’interrogation).
Collectez des statistiques au cours des premières semaines après une mise à niveau ou une migration pendant des périodes d’utilisation faible du processeur.
La collecte de statistiques peut être gérée manuellement à l’aide des API ouvertes de gestion des statistiques automatisées ou automatiquement à l’aide du portlet Teradata Viewpoint Stats Manager.
Conseil
Automatisez et surveillez les tâches de nettoyage dans Azure.
La base de données Teradata contient de nombreuses tables de journaux dans le dictionnaire de données qui accumulent des données, automatiquement ou après l’activation de certaines fonctionnalités. Étant donné que les données de journal augmentent au fil du temps, videz les informations plus anciennes pour éviter d’utiliser de l’espace permanent. Il existe des options permettant d’automatiser la maintenance de ces journaux disponibles. Les tables de dictionnaire Teradata qui nécessitent une maintenance sont décrites ci-dessous.
Tables de dictionnaire dont la maintenance doit être assurée
Réinitialisez les accumulateurs et les valeurs maximales à l’aide de la vue DBC.AMPUsage et de la macro ClearPeakDisk fournies avec le logiciel :
DBC.Acctg: utilisation des ressources par compte/utilisateurDBC.DataBaseSpace: gestion de l’espace de base de données et de table
Teradata gère automatiquement ces tables, mais les bonnes pratiques peuvent réduire leur taille :
DBC.AccessRights: droits de l’utilisateur sur les objetsDBC.RoleGrants: droits du rôle sur les objetsDBC.Roles: rôles définisDBC.Accounts: codes de compte par utilisateur
Archivez ces tables de journalisation (si vous le souhaitez) et videz les informations remontant à 60 à 90 jours. La conservation des données dépend des exigences du client :
DBC.SW_Event_Log: journal de la console de base de donnéesDBC.ResUsage: tables de monitoring des ressourcesDBC.EventLog: historique d’ouverture/de fermeture de sessionDBC.AccLogTbl: événements utilisateur/d’objets journalisésDBC.DBQL tables: activité utilisateur/SQL journalisée.NETSecPolicyLogTbl: journalise les pistes d’audit des stratégies de sécurité dynamiques.NETSecPolicyLogRuleTbl: contrôle quand et comment la stratégie de sécurité dynamique est journalisée
Videz ces tables lorsque le média amovible associé est arrivé à expiration et remplacé :
DBC.RCEvent: archive/événements de récupérationDBC.RCConfiguration: archive/configuration de récupérationDBC.RCMedia: VolSerial pour archive/récupération
Azure Synapse a la possibilité de créer automatiquement des statistiques afin qu’elles puissent être utilisées en fonction des besoins. Effectuez une défragmentation manuelle des index et des blocs de données, sur une base planifiée ou automatiquement. L’utilisation des fonctionnalités Azure intégrées natives peut réduire l’effort requis dans un exercice de migration.
Supervision et audit
Conseil
Au fil du temps, plusieurs outils différents ont été implémentés pour permettre le monitoring et la journalisation des systèmes Teradata.
Teradata fournit plusieurs outils pour superviser l’opération, notamment Teradata Viewpoint et Ecosystem Manager. Pour la journalisation de l’historique des requêtes, le journal DBQL (Database Query Log) est une fonctionnalité de base de données Teradata qui fournit une série de tables prédéfinies qui peuvent stocker les enregistrements historiques des requêtes et leur durée, leurs performances et leur activité cible en fonction des règles définies par l’utilisateur.
Les administrateurs de base de données peuvent utiliser Teradata Viewpoint pour déterminer l’état du système, les tendances et l’état d’une requête individuelle. En observant les tendances d’utilisation du système, les administrateurs système sont mieux en mesure de planifier les implémentations de projet, les travaux par lots et la maintenance afin d’éviter les périodes d’utilisation de pointe. Les utilisateurs professionnels peuvent utiliser Teradata Viewpoint pour accéder rapidement à l’état des rapports et des requêtes, et explorer les détails.
Conseil
Le portail Azure fournit une interface utilisateur pour gérer les tâches de monitoring et d’audit pour l’ensemble des données et processus Azure.
De même, Azure Synapse fournit une expérience de supervision enrichie dans le Portail Azure pour fournir des insights à la charge de travail de votre entrepôt de données. Le portail Azure est l’outil recommandé pour superviser votre entrepôt de données car il offre des périodes de conservation configurables, des alertes, des suggestions, ainsi que des graphiques et des tableaux de bord personnalisables pour les métriques et les journaux d’activité.
Le portail permet également une intégration à d’autres services de monitoring Azure, comme OMS (Operations Management Suite) et Azure Monitor (journaux), pour fournir une expérience de monitoring globale non seulement pour l’entrepôt de données, mais également pour l’ensemble de la plateforme d’analytique Azure afin de bénéficier d’une expérience de monitoring intégrée.
Conseil
Les métriques de bas niveau et à l’échelle du système sont automatiquement enregistrées dans Azure Synapse.
Les statistiques d’utilisation des ressources pour Azure Synapse sont automatiquement enregistrées dans le système. Les métriques de chaque requête incluent des statistiques d’utilisation pour le processeur, la mémoire, le cache, les E/S et l’espace de travail temporaire, ainsi que des informations de connectivité telles que les tentatives de connexion ayant échoué.
Azure Synapse fournit un ensemble de vues de gestion dynamique (DMV). Ces vues sont utiles quand vous dépannez et identifiez activement les goulots d’étranglement des performances de votre charge de travail.
Pour plus d’informations, consultez les options d’opérations et de gestion d’Azure Synapse.
Haute disponibilité et récupération d’urgence
Teradata implémente des fonctionnalités telles que FALLBACK, l’utilitaire de copie de restauration d’archive (ARC) et l’architecture de flux de données (DSA) pour fournir une protection contre la perte de données et la haute disponibilité (HA) via la réplication et l’archivage des données. Les options de reprise d’activité incluent la solution Dual Active Solution, la reprise d’activité en tant que service ou un système de remplacement en fonction des exigences de temps de récupération.
Conseil
Azure Synapse crée automatiquement des instantanés pour garantir des temps de récupération rapides.
Azure Synapse utilise des captures instantanées de base de données pour fournir une haute disponibilité de l’entrepôt. Une capture instantanée d’entrepôt de données crée un point de restauration qui peut être utilisé pour récupérer ou copier un entrepôt de données dans un état antérieur. Comme Azure Synapse est un système distribué, une capture instantanée d’entrepôt de données est constituée de nombreux fichiers qui sont stockés dans le Stockage Azure. Les captures instantanées capturent les changements incrémentiels à partir des données stockées dans votre entrepôt de données.
Azure Synapse prend automatiquement des captures instantanées tout au long de la journée, créant ainsi des points de restauration qui sont disponibles pendant sept jours. Cette période de conservation ne peut pas être modifiée. Azure Synapse prend en charge un objectif de point de récupération de huit heures. Un entrepôt de données peut être restauré dans la région primaire à partir de n’importe quelle capture instantanée prise au cours des sept derniers jours.
Conseil
Utilisez des instantanés définis par l’utilisateur pour définir un point de récupération avant les mises à jour clés.
Les points de restauration définis par l’utilisateur sont également pris en charge, ce qui permet de déclencher manuellement des captures instantanées pour créer des points de restauration d’un entrepôt de données avant et après des modifications importantes. Cette fonctionnalité garantit que les points de restauration sont logiquement cohérents, ce qui renforce la protection des données en cas d’interruptions de la charge de travail ou d’erreurs d’utilisateur pendant un objectif de point de récupération souhaité de moins de 8 heures.
Conseil
Microsoft Azure fournit des sauvegardes automatiques à un emplacement géographique distinct pour activer la récupération d’urgence.
A l’instar des captures instantanées décrites précédemment, Azure Synapse effectue également une géosauvegarde standard une fois par jour dans un centre de données associé. Le RPO pour une géo-restauration est de 24 heures. Vous pouvez restaurer la géosauvegarde sur un serveur dans n’importe quelle autre région où Azure Synapse est pris en charge. Une géosauvegarde garantit qu’un entrepôt de données peut être restauré si les points de restauration de la région primaire ne sont pas disponibles.
Gestion des charges de travail
Conseil
Dans un entrepôt de données de production, il existe généralement des charges de travail mixtes avec différentes caractéristiques d’utilisation des ressources s’exécutant simultanément.
Une charge de travail est une classe de demandes de base de données avec des caractéristiques communes dont l’accès à la base de données peut être géré avec un ensemble de règles. Les charges de travail sont utiles pour :
Définition de différentes priorités d’accès pour différents types de demandes.
Monitoring des modèles d’utilisation des ressources, réglage des performances et planification de la capacité.
Limitation du nombre de demandes ou de sessions qui peuvent s’exécuter en même temps.
Dans un système Teradata, la gestion des charges de travail consiste à gérer les performances des charges de travail en supervisant l’activité du système et en agissant lorsque des limites prédéfinies sont atteintes. La gestion des charges de travail utilise des règles et chaque règle s’applique uniquement à certaines demandes de base de données. Toutefois, la collection de toutes les règles s’applique à tous les travaux actifs sur la plateforme. Teradata Active System Management (TASM) effectue une gestion complète des charges de travail dans une base de données Teradata.
Dans Azure Synapse, les classes de ressources sont des limites de ressources prédéterminées qui régissent les ressources de calcul et la concurrence lors de l’exécution des requêtes. Les classes de ressources peuvent vous aider à gérer votre charge de travail en définissant des limites quant au nombre de requêtes qui s’exécutent simultanément et sur les ressources de calcul qui leur sont respectivement attribuées. Il faut faire un compromis entre la mémoire et la concurrence.
Azure Synapse journalise automatiquement les statistiques d’utilisation des ressources. Les métriques incluent des statistiques d’utilisation pour le processeur, la mémoire, le cache, les E/S et l’espace de travail temporaire pour chaque requête. Azure Synapse journalise également les informations de connectivité, comme les tentatives de connexion ayant échoué.
Conseil
Les métriques de bas niveau et à l’échelle du système sont automatiquement enregistrées dans Azure.
Azure Synapse prend en charge les concepts de gestion des charges de travail de base suivants :
Classification des charges de travail : vous pouvez attribuer une requête à un groupe de charges de travail pour définir des niveaux d’importance.
Importance de la charge de travail : vous pouvez influencer l’ordre dans lequel une requête accède aux ressources. Par défaut, les requêtes sont libérées de la file d’attente sur la base du premier entré/premier sorti à mesure que les ressources deviennent disponibles. L’importance de la charge de travail permet aux requêtes de priorité plus élevée de recevoir les ressources immédiatement.
Isolation des charges de travail : vous pouvez réserver des ressources pour un groupe de charges de travail, affecter une utilisation maximale et minimale pour différentes ressources, limiter les ressources qu’un groupe de requêtes peut consommer et définir une valeur de délai d’expiration pour tuer automatiquement les requêtes avec perte de contrôle.
L’exécution de charges de travail mixtes peut poser des problèmes de ressources sur les systèmes chargés. Un schéma de gestion des charges de travail réussi gère efficacement les ressources, garantit une utilisation hautement efficace des ressources et optimise le retour sur investissement (ROI). La classification de la charge de travail, l’importance de la charge de travail et l’isolation de la charge de travail donnent plus de contrôle sur la façon dont la charge de travail utilise les ressources système.
Le guide de gestion des charges de travail décrit les techniques permettant d’analyser la charge de travail, de gérer et de surveiller l’importance de la charge de travail](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md), et les étapes de conversion d’une classe de ressources en groupe de charge de travail. Utilisez le Portail Azure et les requêtes T-SQL sur les DMV pour surveiller la charge de travail pour vous assurer que les ressources applicables sont utilisées efficacement. Azure Synapse fournit un ensemble de vues de gestion dynamique (DMV) pour surveiller tous les aspects de la gestion des charges de travail. Ces vues sont utiles quand vous dépannez et identifiez activement les goulots d’étranglement des performances de votre charge de travail.
Ces informations peuvent également être utilisées pour la planification de la capacité, en déterminant les ressources requises pour des utilisateurs supplémentaires ou une charge de travail d’application. Cela s’applique également à la planification de scale-up/scale-down des ressources de calcul pour la prise en charge rentable des charges de travail maximales.
Pour plus d’informations sur la gestion des charges de travail dans Azure Synapse, consultez Gestion des charges de travail avec des classes de ressources.
Mettre à l’échelle des ressources de calcul
Conseil
L’un des principaux avantages d’Azure est la possibilité de mettre à l’échelle indépendamment les ressources de calcul à la demande pour gérer les charges de travail maximales de manière rentable.
L’architecture de l’entrepôt de données sépare le stockage et le calcul, ce qui permet de les mettre à l’échelle indépendamment l’un de l’autre. En conséquence, les ressources de calcul peuvent être mises à l’échelle pour répondre aux exigences de performance, indépendamment du stockage de données. Vous avez également la possibilité de suspendre ou reprendre des ressources de calcul. L’un des avantages naturels de cette architecture est que la facturation du calcul est effectuée séparément de celle du stockage. Si un entrepôt de données n’est pas utilisé, vous pouvez économiser sur les coûts de calcul en interrompant le calcul.
Les ressources de calcul peuvent être mises à l’échelle ou mises à l’échelle en ajustant le paramètre d’unités d’entrepôt de données pour l’entrepôt de données. Les performances de chargement et de requête s’accroîtront de manière linéaire à mesure que vous augmentez la valeur DWU.
L’ajout de nœuds de calcul supplémentaires ajoute plus de puissance de calcul et la capacité à tirer parti d’un traitement plus parallèle. À mesure que le nombre de nœuds de calcul augmente, le nombre de distributions par nœud de calcul diminue, ce qui fournit davantage de puissance de calcul et de traitement parallèle pour vos requêtes. De même, la diminution des unités d’entrepôt de données réduit le nombre de nœuds de calcul, ce qui réduit les ressources de calcul pour les requêtes.
Étapes suivantes
Pour en savoir plus sur la visualisation et la création de rapports, consultez l’article suivant de cette série : Visualisation et création de rapports pour les migrations Teradata.