Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
L’ingestion des données est le processus de collecte, de lecture et de préparation des données à partir de différentes sources telles que des fichiers, des bases de données, des API ou des services cloud afin qu’elles puissent être utilisées dans les applications en aval. Dans la pratique, ce processus suit le flux de travail Extract-Transform-Load (ETL) :
- Extrayez des données de sa source d’origine, qu’il s’agisse d’un document PDF, d’un document Word, d’un fichier audio ou d’une API web.
- Transformez les données en nettoyant, en segmentant, en enrichissant ou en convertissant des formats.
- Chargez les données dans une destination telle qu’une base de données, un magasin vectoriel ou un modèle IA pour la récupération et l’analyse.
Pour les scénarios IA et Machine Learning, en particulier Retrieval-Augmented Génération (RAG), l’ingestion de données ne consiste pas seulement à convertir des données d’un format vers un autre. Il s’agit de rendre les données utilisables pour les applications intelligentes. Cela signifie représenter des documents d’une manière qui conserve leur structure et leur signification, les fractionnant en blocs gérables, en les enrichissant avec des métadonnées ou des incorporations, et en les stockant afin qu’ils puissent être récupérés rapidement et avec précision.
Pourquoi l’ingestion des données est importante pour les applications IA
Imaginez que vous créez un chatbot alimenté par RAG pour aider les employés à trouver des informations dans la vaste collection de documents de votre entreprise. Ces documents peuvent inclure des fichiers PDF, des fichiers Word, des présentations PowerPoint et des pages web dispersées sur différents systèmes.
Votre chatbot doit comprendre et rechercher des milliers de documents pour fournir des réponses contextuelles précises. Mais les documents bruts ne conviennent pas aux systèmes IA. Vous devez les transformer dans un format qui conserve la signification tout en les rendant accessibles à la recherche et récupérables.
C’est là que l’ingestion des données devient critique. Vous devez extraire du texte à partir de différents formats de fichiers, diviser les documents volumineux en blocs plus petits qui s’intègrent dans les limites du modèle IA, enrichir le contenu avec des métadonnées, générer des incorporations pour la recherche sémantique et stocker tout ce qui permet une récupération rapide. Chaque étape nécessite une considération minutieuse de la façon de préserver la signification et le contexte d’origine.
Bibliothèque Microsoft.Extensions.DataIngestion
Le 📦 package Microsoft.Extensions.DataIngestion fournit des blocs de construction .NET fondamentaux pour l’ingestion de données. Cela permet aux développeurs de lire, de traiter et de préparer des documents pour les flux de travail d'IA et d'apprentissage automatique, en particulier les scénarios de génération augmentée par récupération (RAG).
Avec ces blocs de construction, vous pouvez créer des pipelines d’ingestion de données robustes, flexibles et intelligents adaptés aux besoins de votre application :
- Représentation unifiée du document : Représentez n’importe quel type de fichier (par exemple, PDF, Image ou Microsoft Word) dans un format cohérent qui fonctionne bien avec les modèles de langage volumineux.
- Ingestion de données flexibles : Lisez des documents à partir des services cloud et des sources locales à l’aide de plusieurs lecteurs intégrés, ce qui facilite l’apport de données à partir de l’endroit où elle réside.
- Améliorations intégrées de l’IA : Enrichissez automatiquement le contenu avec des résumés, une analyse des sentiments, une extraction de mots clés et une classification, en préparant vos données pour les flux de travail intelligents.
- Stratégies de segmentation personnalisables : Fractionnez des documents en blocs à l’aide d’approches basées sur des jetons, basées sur des sections ou sémantiques, afin de pouvoir optimiser vos besoins de récupération et d’analyse.
- Stockage prêt pour la production : Stockez les blocs traités dans les bases de données vectorielles populaires et les magasins de documents, avec prise en charge de la génération d'embeddings, rendant ainsi vos pipelines adaptés aux scénarios réels.
- Composition du pipeline de bout en bout : Chaînez des lecteurs, des processeurs, des segmenteurs et des enregistreurs avec l’API IngestionPipeline<T>, ce qui réduit la répétition de code et facilite la création, la personnalisation et l’extension de flux de travail complets.
- Performances et scalabilité : Conçus pour le traitement évolutif des données, ces composants peuvent gérer efficacement de grands volumes de données, ce qui les rend adaptés aux applications de niveau entreprise.
Tous ces composants sont ouverts et extensibles par conception. Vous pouvez ajouter une logique personnalisée et de nouveaux connecteurs et étendre le système pour prendre en charge les scénarios IA émergents. En standardisant la façon dont les documents sont représentés, traités et stockés, les développeurs .NET peuvent créer des pipelines de données fiables, évolutifs et gérables sans « réinventer la roue » pour chaque projet.
Construit sur des bases stables
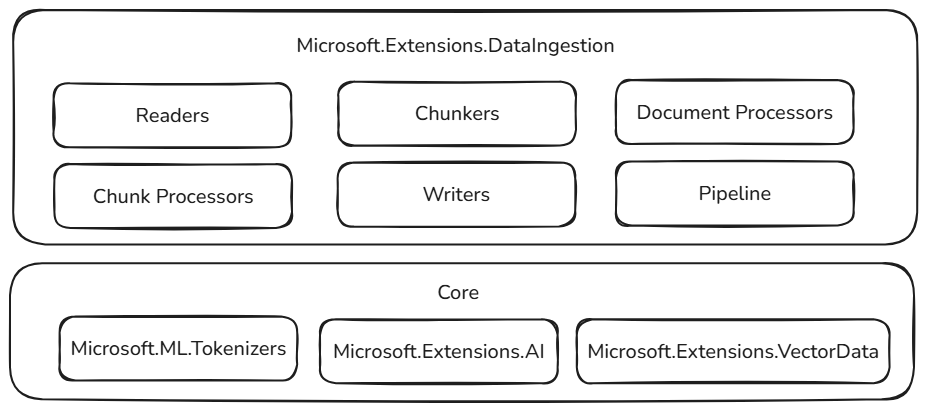
Ces blocs de construction d’ingestion de données sont basés sur des composants éprouvés et extensibles dans l’écosystème .NET, ce qui garantit la fiabilité, l’interopérabilité et l’intégration transparente aux flux de travail IA existants :
- Microsoft.ML.Tokenizers : Les tokenizers fournissent la base de la segmentation de documents basés sur des jetons. Cela permet un fractionnement précis du contenu, qui est essentiel pour la préparation des données pour les modèles de langage volumineux et l’optimisation des stratégies de récupération.
- Microsoft.Extensions.AI : Cet ensemble de bibliothèques alimente les transformations d’enrichissement à l’aide de modèles de langage volumineux. Il permet des fonctionnalités telles que la synthèse, l’analyse des sentiments, l’extraction de mots clés et la génération d’incorporation, ce qui facilite l’amélioration de vos données avec des insights intelligents.
- Microsoft.Extensions.VectorData : Cet ensemble de bibliothèques offre une interface cohérente pour stocker des blocs traités dans un large éventail de magasins vectoriels, notamment Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch, etc. Cela garantit que vos pipelines de données sont prêts pour la mise en production et peuvent être mis à l’échelle sur différents backends de stockage.
En plus des modèles et outils familiers, ces abstractions s’appuient sur des composants déjà extensibles. La fonctionnalité de plug-in et l’interopérabilité sont primordiales, de sorte que le reste de l’écosystème d’IA .NET augmente, les fonctionnalités des composants d’ingestion de données augmentent également. Cette approche permet aux développeurs d’intégrer facilement de nouveaux connecteurs, enrichissements et options de stockage, en conservant leurs pipelines prêts à l’avenir et adaptables aux scénarios d’IA en évolution.
Éléments de base pour l’ingestion de données
La bibliothèque Microsoft.Extensions.DataIngestion est construite autour de plusieurs composants clés qui fonctionnent ensemble pour créer un pipeline de traitement des données complet. Cette section explore chaque composant et explique comment ils s’intègrent ensemble.
Documents et lecteurs de documents
Au fondement de la bibliothèque est le IngestionDocument type, qui fournit un moyen unifié de représenter n’importe quel format de fichier sans perdre d’informations importantes.
IngestionDocument est centré sur Markdown, car les modèles de langage volumineux fonctionnent mieux avec la mise en forme Markdown.
L’abstraction IngestionDocumentReader gère le chargement des documents à partir de différentes sources, qu’il s’agisse de fichiers locaux ou de flux de données. Quelques lecteurs sont disponibles :
D’autres lecteurs (y compris LlamaParse et Azure Document Intelligence) seront ajoutés à l’avenir.
Cette conception signifie que vous pouvez utiliser des documents provenant de différentes sources à l’aide de la même API cohérente, ce qui rend votre code plus facile à gérer et flexible.
Traitement du document
Les processeurs de documents appliquent des transformations au niveau du document pour améliorer et préparer du contenu. La bibliothèque fournit la classe ImageAlternativeTextEnricher en tant que processeur intégré qui utilise des modèles de langue à grande échelle pour générer un texte alternatif descriptif pour les images dans les documents.
Segments et stratégies de division en unités
Une fois que vous avez chargé un document, vous devez généralement le décomposer en morceaux plus petits appelés blocs. Les blocs représentent des sous-sections d’un document qui peut être traité, stocké et récupéré efficacement par les systèmes IA. Ce processus de segmentation est essentiel pour les scénarios de génération augmentée de récupération dans lesquels vous devez trouver rapidement les informations les plus pertinentes.
La bibliothèque fournit plusieurs stratégies de segmentation pour répondre à différents cas d’usage :
- Segmentation basée sur l’en-tête pour diviser selon les en-têtes.
- Segmentation basée sur les sections pour diviser par sections (par exemple, pages).
- Découpage sensible au contexte sémantique pour conserver les pensées complètes.
Ces stratégies de segmentation s’appuient sur la bibliothèque Microsoft.ML.Tokenizers pour fractionner intelligemment du texte en éléments de taille appropriée qui fonctionnent bien avec les modèles de langage volumineux. La stratégie de segmentation appropriée dépend de vos types de documents et de la façon dont vous prévoyez de récupérer des informations.
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel("gpt-4");
IngestionChunkerOptions options = new(tokenizer)
{
MaxTokensPerChunk = 2000,
OverlapTokens = 0
};
IngestionChunker<string> chunker = new HeaderChunker(options);
Traitement et enrichissement de morceaux
Une fois que les documents sont divisés en blocs, vous pouvez appliquer des processeurs pour améliorer et enrichir le contenu. Les processeurs de segments fonctionnent sur des éléments individuels et peuvent effectuer les opérations suivantes :
-
Enrichissement du contenu , y compris les résumés automatiques (
SummaryEnricher), l’analyse des sentiments (SentimentEnricher) et l’extraction de mots clés (KeywordEnricher). -
Classification pour la catégorisation de contenu automatisée basée sur des catégories prédéfinies (
ClassificationEnricher).
Ces processeurs utilisent Microsoft.Extensions.AI.Abstractions pour tirer parti de modèles de langage volumineux pour la transformation de contenu intelligente, ce qui rend vos blocs plus utiles pour les applications IA en aval.
Enregistreur de documents et stockage
IngestionChunkWriter<T> stocke les blocs traités dans un magasin de données pour une récupération ultérieure. À l’aide de Microsoft.Extensions.AI et microsoft.Extensions.VectorData.Abstractions, la bibliothèque fournit la classe qui prend en charge le VectorStoreWriter<T> stockage de blocs dans n’importe quel magasin vectoriel pris en charge par Microsoft.Extensions.VectorData.
Les magasins vectoriels incluent des options populaires telles que Qdrant, SQL Server, CosmosDB, MongoDB, ElasticSearch, etc. L’auteur peut également générer automatiquement des intégrations pour vos segments à l’aide de Microsoft.Extensions.AI, en les préparant pour des scénarios de recherche sémantique et de récupération.
OpenAIClient openAIClient = new(
new ApiKeyCredential(Environment.GetEnvironmentVariable("GITHUB_TOKEN")!),
new OpenAIClientOptions { Endpoint = new Uri("https://models.github.ai/inference") });
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator =
openAIClient.GetEmbeddingClient("text-embedding-3-small").AsIEmbeddingGenerator();
using SqliteVectorStore vectorStore = new(
"Data Source=vectors.db;Pooling=false",
new()
{
EmbeddingGenerator = embeddingGenerator
});
// The writer requires the embedding dimension count to be specified.
// For OpenAI's `text-embedding-3-small`, the dimension count is 1536.
using VectorStoreWriter<string> writer = new(vectorStore, dimensionCount: 1536);
Pipeline de traitement de documents
L’API IngestionPipeline<T> vous permet de chaîner les différents composants d’ingestion de données dans un flux de travail complet. Vous pouvez combiner :
- Lecteurs pour charger des documents à partir de différentes sources.
- Processeurs pour transformer et enrichir le contenu du document.
- Segments pour décomposer des documents en éléments gérables.
- Modules d'écriture pour stocker les résultats finaux dans votre magasin de données choisi.
Cette approche de pipeline réduit le code réutilisable et facilite la génération, le test et la gestion de flux de travail d’ingestion de données complexes.
using IngestionPipeline<string> pipeline = new(reader, chunker, writer, loggerFactory: loggerFactory)
{
DocumentProcessors = { imageAlternativeTextEnricher },
ChunkProcessors = { summaryEnricher }
};
await foreach (var result in pipeline.ProcessAsync(new DirectoryInfo("."), searchPattern: "*.md"))
{
Console.WriteLine($"Completed processing '{result.DocumentId}'. Succeeded: '{result.Succeeded}'.");
}
L'échec de l'ingestion d'un seul document ne devrait pas entraîner l'échec du pipeline entier. C’est pourquoi IngestionPipeline<T>.ProcessAsync implémente une réussite partielle en retournant IAsyncEnumerable<IngestionResult>. L’appelant est responsable de la gestion des défaillances (par exemple, en réessayant les documents ayant échoué ou en s’arrêtant lors de la première erreur).
Collaborez avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner des issues et des pull requests. Pour plus d’informations, consultez notre guide des contributeurs.