Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La mise en miroir dans Fabric offre un moyen simple d’éviter des processus ETL complexes (extraire, transformer, charger) et d’intégrer en toute transparence vos données d’entrepôt Google BigQuery existantes avec le reste de vos données dans Fabric. Vous pouvez répliquer en continu vos données Google BigQuery directement dans oneLake de Fabric. Une fois dans Fabric, vous pouvez tirer parti de fonctionnalités puissantes pour le décisionnel, l’intelligence artificielle, l’ingénierie des données, la science des données et le partage de données.
Pour obtenir un didacticiel sur la configuration de votre base de données Google BigQuery pour la mise en miroir dans Fabric, consultez Tutorial : Configurer Microsoft Fabric bases de données mises en miroir à partir de Google BigQuery.
Important
La fonctionnalité de mise en miroir pour Google BigQuery est désormais en version préliminaire. Les charges de travail de production ne sont pas prises en charge pendant la version préliminaire.
Pourquoi utiliser la mise en miroir dans Fabric ?
La mise en miroir dans Microsoft Fabric élimine la complexité de l’assemblage d’outils de différents fournisseurs. Vous n’avez pas besoin de migrer vos données. Connectez-vous à vos données Google BigQuery en quasi temps réel pour utiliser le tableau d’outils d’analytique de Fabric. Fabric fonctionne également en toute transparence avec les produits Microsoft, Google BigQuery et un large éventail de technologies qui prennent en charge le format de table Delta Lake open source.
Quelles expériences d’analytique sont intégrées ?
La mise en miroir crée deux éléments dans votre espace de travail Fabric :
- Élément de base de données mis en miroir. La mise en miroir gère la réplication des données dans OneLake et la conversion en Parquet, dans un format prêt pour l'analyse. La mise en miroir permet des scénarios en aval tels que l’ingénierie des données, la science des données, etc. Les bases de données mises en miroir sont distinctes des endpoints d’entrepôt et d’analytique SQL.
- Un Serveur d'analyse SQL
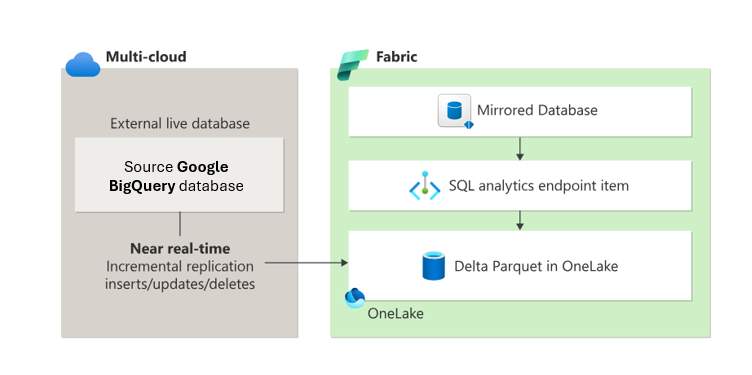
À partir de chaque base de données mise en miroir, un point de terminaison analytique SQL fournit une expérience d'analyse en lecture seule sur les tables Delta créées lors de la mise en miroir. Ce point de terminaison prend en charge la syntaxe T-SQL pour définir et interroger des objets de données, mais il n’autorise pas les modifications directes des données, car les données sont en lecture seule.
Avec le point de terminaison d'analyse SQL, vous pouvez :
- Parcourez les tables qui référencent vos données Delta Lake mises en miroir à partir de BigQuery.
- Créez des requêtes et des vues sans code et explorez visuellement les données, sans SQL requis.
- Créez des vues SQL, des fonctions table valorisées en ligne (TVF) et des procédures stockées pour intégrer la logique métier à l'aide de T-SQL.
- Définissez et gérez les autorisations sur les objets.
- Interroger des données dans d’autres entrepôts et Lakehouses dans le même espace de travail.
En plus de l'éditeur de requête SQL, Il existe un vaste écosystème d'outils qui peut interroger le point de terminaison d'analyse SQL, notamment SQL Server Management Studio (SSMS), l'extension MSSQL pour Visual Studio Code et même GitHub Copilot.
Considérations relatives à la sécurité
Il existe des exigences d’autorisation utilisateur spécifiques pour activer le mirroring Fabric.
Fabric fournit également des fonctionnalités de protection des données pour gérer l’accès dans Microsoft Fabric. Pour plus d’informations, consultez notre documentation sur les fonctionnalités de protection des données.
Considérations relatives aux coûts BigQuery mises en miroir
Le calcul Fabric utilisé pour répliquer vos données dans Fabric OneLake est gratuit. Le coût de stockage pour la duplication est gratuit jusqu'à une limite déterminée par la capacité. Le calcul pour l’interrogation de données à l’aide de SQL, de Power BI ou de Spark est facturé à des tarifs réguliers.
Fabric ne facture pas les frais d’entrée de données réseau dans OneLake pour la mise en miroir.
Il existe des coûts de calcul et de requête cloud avec Google BigQuery lorsque les données sont mises en miroir : BigQuery Change Data Capture (CDC) utilise la puissance de calcul de BigQuery pour les modifications de lignes, l'API de Write Storage pour l'ingestion des données, et le stockage BigQuery pour le stockage des données, ce qui entraîne des coûts.
Pour plus d’informations sur les coûts de mise en miroir de Google BigQuery, consultez la tarification expliquée.