Modélisation des menaces dans les systèmes IA/ML et leurs dépendances
Auteurs : Andrew Marshall, Jugal Parikh, Emre Kiciman et Ram Shankar Siva Kumar
Remerciements particuliers à Raul Rojas et au flux de travail d'ingénierie de sécurité AETHER
Novembre 2019
Ce document est le résultat du groupe de travail AETHER Engineering Practices for AI (Pratiques d'ingénierie d'AETHER pour l'IA) qui complète les pratiques de modélisation des menaces SDL existantes en fournissant de nouvelles instructions relatives à l'attaque par énumération et l'atténuation des menaces spécifiques à l'espace d'intelligence artificielle et d'apprentissage automatique. Il est destiné à servir de référence lors des revues de la conception de la sécurité des éléments suivants :
Produits/services qui interagissent avec des services IA/ML ou qui en deviennent dépendants
Produits/services en cours de création axés sur les systèmes IA/ML
L'atténuation traditionnelle des menaces de sécurité est plus importante que jamais. Les exigences établies par Security Development Lifecycle sont essentielles pour établir les bases de la sécurité des produits sur lesquelles s'appuient ces conseils. L'absence de réponse aux menaces de sécurité traditionnelles contribue à rendre possibles les attaques spécifiques aux systèmes IA/ML abordées dans ce document, tant dans le domaine logiciel que physique, ainsi qu'à faire descendre le rang des violations insignifiantes dans la pile logicielle. Pour une introduction aux nouvelles menaces de sécurité du réseau dans cet espace, consultez Sécurisation des futurs systèmes IA/ML chez Microsoft.
Les ensembles de compétences des ingénieurs en sécurité et des spécialistes des données ne se recoupent généralement pas. Ce guide permet aux deux disciplines d'avoir des conversations structurées sur ces nouvelles menaces/atténuations sans qu'il soit nécessaire que les ingénieurs en sécurité deviennent des scientifiques des données ou vice versa.
Ce document est divisé en deux sections :
- « Nouvelles considérations clés dans la modélisation des menaces » se concentre sur les nouvelles façons de penser et les nouvelles questions à se poser lors de la modélisation des menaces des systèmes IA/ML. Les scientifiques des données et les ingénieurs en sécurité doivent passer en revue ces informations, car il s'agit de leur guide opérationnel pour les discussions relatives à la modélisation des menaces et à la hiérarchisation des atténuations.
- « Menaces spécifiques aux systèmes IA/ML et leurs atténuations » fournit des détails sur des attaques spécifiques, ainsi que des mesures d'atténuation spécifiques utilisées aujourd'hui pour protéger les produits et services Microsoft contre ces menaces. Cette section est principalement destinée aux scientifiques des données qui peuvent avoir besoin d'implémenter des mesures spécifiques d'atténuation des menaces en tant que sortie du processus de revue de la modélisation des menaces ou de la sécurité.
Ce guide s'articule autour de la taxonomie des menaces de l'apprentissage automatique contradictoire élaborée par Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen et Jeffrey Snover, exposée dans le document « Modes d'échec de l'apprentissage automatique. » Pour obtenir des conseils en matière de gestion des incidents sur le triage des menaces de sécurité détaillées dans le présent document, consultez la barre de bogues SDL pour les menaces IA/ML. Tous ces documents sont évolutifs et s'adapteront au fil du temps au paysage des menaces.
Éléments clés à prendre en compte dans la modélisation des menaces : modification de la façon dont vous visualisez les limites d'approbation
Supposez une violation ou un empoisonnement des données que vous utilisez pour effectuer l'apprentissage ainsi que ceux du fournisseur de données. Apprenez à détecter des entrées de données anormales et malveillantes, ainsi qu'à faire la distinction entre elles et à les récupérer.
Résumé
Les magasins de données d'apprentissage et les systèmes qui les hébergent font partie de votre étendue de modélisation des menaces. Aujourd'hui, la plus grande menace pour la sécurité en apprentissage automatique est l'empoisonnement des données en raison de l'absence de détections et d'atténuations standard dans cet espace, combiné à la dépendance envers des jeux de données publics non fiables ou non traités comme sources de données d'apprentissage. Le suivi de la provenance et de la traçabilité des données est essentiel pour s'assurer de leur fiabilité et éviter le cycle de formation « garbage in, garbage out » (ordures à l'entrée, ordures à la sortie).
Questions à poser lors de la revue de la sécurité
Comment savoir si vos données sont empoisonnées ou falsifiées ?
– De quelle télémétrie disposez-vous pour détecter une asymétrie dans la qualité de vos données d'apprentissage ?
Effectuez-vous l'apprentissage à partir d'entrées fournies par l'utilisateur ?
– Quel type de validation ou d'assainissement d'entrée effectuez-vous sur ce contenu ?
– La structure de ces données est-elle documentée de la même manière que dans l'article Datasheets for Datasets ?
Si vous effectuez l'apprentissage à l'aide de magasins de données en ligne, quelles sont les étapes à suivre pour garantir la sécurité de la connexion entre votre modèle et les données ?
– Ont-ils un moyen de signaler des violations aux consommateurs de leurs flux ?
– En sont-ils même capable ?
Dans quelle mesure vos données d'apprentissage sont-elles sensibles ?
– Les cataloguez-vous ou contrôlez-vous l'ajout/la mise à jour/la suppression des entrées de données ?
Votre modèle peut-il produire des données sensibles ?
– Ces données ont-elles été obtenues avec l'autorisation de la source ?
Le modèle génère-t-il uniquement les résultats nécessaires pour atteindre son objectif ?
Votre modèle retourne-t-il des scores de confiance bruts ou toute autre sortie directe qui peut être enregistrée et dupliquée ?
Quel est l'impact de la récupération de vos données d'apprentissage en attaquant/inversant votre modèle ?
Si les niveaux de confiance de la sortie de votre modèle chutent soudainement, pouvez-vous savoir comment/pourquoi, ainsi que les données qui en sont la cause ?
Avez-vous défini une entrée bien formée pour votre modèle ? Que faites-vous pour vous assurer que les entrées sont conformes à ce format, et que faites-vous si elles ne le sont pas ?
Si vos sorties sont erronées, mais ne provoquent pas de signalement d'erreurs, comment le savez-vous ?
Savez-vous si vos algorithmes d'apprentissage sont résilients aux entrées contradictoires à un niveau mathématique ?
Comment effectuez-vous une récupération à partir d'une contamination contradictoire de vos données d'apprentissage ?
– Pouvez-vous isoler/mettre en quarantaine le contenu contradictoire et effectuer à nouveau l'apprentissage des modèles concernés ?
– Pouvez-vous restaurer/récupérer le modèle d'une version antérieure pour une nouvelle formation ?
Utilisez-vous l'apprentissage par renforcement sur le contenu public non traité ?
Commencez à réfléchir à la traçabilité de vos données : si vous deviez trouver un problème, pourriez-vous le suivre jusqu'à son introduction dans le jeu de données ? Si ce n'est pas le cas, est-ce un problème ?
Sachez d'où proviennent vos données d'apprentissage et identifiez les normes statistiques afin de commencer à comprendre à quoi ressemblent les anomalies.
– Quels éléments de vos données d'apprentissage sont vulnérables à une influence externe ?
– Qui peut contribuer aux jeux de données que vous utilisez pour effectuer l'apprentissage ?
– Comment vous attaqueriez-vous à vos sources de données d'apprentissage pour nuire à un concurrent ?
Menaces et atténuations connexes dans ce document
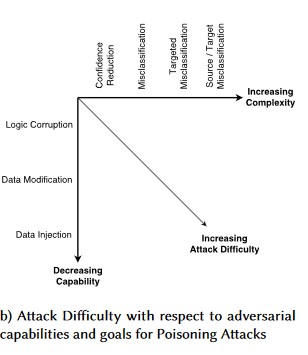
Perturbation contradictoire (toutes les variantes)
Empoisonnement des données (toutes les variantes)
Exemples d'attaques
Forçage du classement d'e-mails sans gravité en tant que courrier indésirable, ou aboutissant à la non-détection d'un exemple malveillant.
Entrées créées par un attaquant afin de réduire le niveau de confiance de la classification correcte, en particulier dans des scénarios pouvant avoir des conséquences considérables.
Injection aléatoire de bruit dans les données sources classées afin de réduire la probabilité d'utilisation de la classification correcte à l'avenir, ce qui a pour effet d'affaiblir le modèle.
Contamination des données d'apprentissage pour forcer la classification incorrecte de certains points de données, ce qui entraîne la prise ou l'omission de mesures spécifiques par un système.
Identification des actions que vos modèles ou produit/service pourraient entreprendre et qui peuvent causer un préjudice aux clients en ligne ou dans le domaine physique
Résumé
Si elles ne sont pas atténuées, les attaques contre les systèmes IA/ML peuvent se frayer un chemin jusqu'au monde physique. Tout scénario qui peut être déformé pour nuire psychologiquement ou physiquement aux utilisateurs constitue un risque catastrophique pour votre produit/service. Cela s'étend à toutes les données sensibles sur vos clients utilisées pour la formation et les choix de conception qui peuvent entraîner la divulgation de ces points de données privés.
Questions à poser lors de la revue de la sécurité
Effectuez-vous l'apprentissage avec des exemples contradictoires ? Quel est leur impact sur la sortie de votre modèle dans le domaine physique ?
À quoi ressemble le trollage pour votre produit/service ? Comment pouvez-vous le détecter et y répondre ?
Que faudrait-il faire pour que votre modèle produise un résultat qui pousse votre service à refuser l'accès aux utilisateurs légitimes ?
Quel est l'impact de la copie/du vol de votre modèle ?
Votre modèle peut-il être utilisé pour déduire l'appartenance d'une personne à un groupe particulier, ou l'information peut-elle se trouver dans les données d'apprentissage ?
Un attaquant peut-il porter atteinte à la réputation de votre produit ou provoquer des réactions négatives en matière de relations publiques en le forçant à effectuer des actions spécifiques ?
Comment traitez-vous les données correctement mises en forme, mais ouvertement biaisées, comme les trolls ?
Pour chaque façon d'interagir avec votre modèle ou de l'interroger, cette méthode peut-elle être interrogée pour divulguer des données d'apprentissage ou des fonctionnalités de modèle ?
Menaces et atténuations connexes dans ce document
Inférence d'appartenance
Inversion de modèle
Vol de modèle
Exemples d'attaques
Reconstruction et extraction de données d'apprentissage par interrogation répétée du modèle pour obtenir des résultats de confiance maximale.
Duplication du modèle lui-même par une mise en correspondance exhaustive des requêtes-réponses.
Inclusion dans le jeu d'apprentissage de l'interrogation du modèle d'une façon qui révèle un élément spécifique de données privées.
Voiture autonome manipulée pour ignorer les panneaux stop et les feux de circulation.
Robots conversationnels manipulés pour troller des utilisateurs bénins.
Identification de toutes les sources de dépendances aux systèmes IA/ML et des couches de présentation frontales dans la chaîne d'approvisionnement de données/modèle
Résumé
De nombreuses attaques en IA et en Machine Learning commencent par un accès légitime aux API qui sont exposées pour fournir l'accès à un modèle par requête. En raison de la richesse des sources de données et des expériences des utilisateurs, authentifiées mais « inappropriées » (il s'agit d'une zone grise), l'accès de tiers à vos modèles est un risque en raison de la possibilité d'agir comme une couche de présentation au-dessus d'un service fourni par Microsoft.
Questions à poser lors de la revue de la sécurité
Quels sont les clients/partenaires authentifiés pour accéder à vos API de modèle ou de service ?
– Peuvent-ils agir comme une couche de présentation par-dessus votre service ?
– Pouvez-vous révoquer leur accès rapidement en cas de violation ?
– Quelle est votre stratégie de récupération en cas d'utilisation malveillante de votre service ou de vos dépendances ?
Un tiers peut-il construire une façade autour de votre modèle pour le réutiliser et nuire à Microsoft ou à ses clients ?
Les clients vous fournissent-ils des données d'apprentissage directement ?
– Comment sécurisez-vous ces données ?
– Que se passe-t-il si elles sont malveillantes et que votre service est la cible ?
À quoi ressemble un faux positif dans ce cas ? Quel est l'impact d'un faux négatif ?
Pouvez-vous suivre et mesurer l'écart entre les taux de vrais positifs et de faux positifs sur plusieurs modèles ?
De quel type de télémétrie avez-vous besoin pour prouver la fiabilité de la sortie de votre modèle à vos clients ?
Identifiez toutes les dépendances de votre chaîne d'approvisionnement de données d'apprentissage/ML à l'égard de tiers, pas seulement les logiciels open source, mais également les fournisseurs de données.
– Pourquoi les utilisez-vous et comment vérifiez-vous leur fiabilité ?
Utilisez-vous des modèles prédéfinis conçus par des tiers ou soumettez-vous des données d'apprentissage à des fournisseurs MLaaS tiers ?
Inventaire des actualités concernant des attaques sur des produits/services similaires. Sachant que de nombreuses menaces IA/ML se transmettent d'un type de modèle à l'autre, quel impact ces attaques auraient-elles sur vos propres produits ?
Menaces et atténuations connexes dans ce document
Reprogrammation de réseau neural
Exemples contradictoires dans le domaine physique
Fournisseur d'apprentissage automatique malveillant récupérant des données d'apprentissage
Attaque de la chaîne d'approvisionnement d'apprentissage automatique
Modèle à porte dérobée
Dépendances spécifiques aux systèmes ML compromises
Exemples d'attaques
Un fournisseur MLaaS malveillant infiltre votre modèle avec un contournement spécifique.
Un client hostile trouve une vulnérabilité dans la dépendance commune aux logiciels open source que vous utilisez et charge la charge utile des données d'apprentissage créée pour compromettre votre service.
Un partenaire peu scrupuleux utilise des API de reconnaissance faciale et crée une couche de présentation sur votre service pour produire des hypertrucages (deep fakes).
Menaces spécifiques aux systèmes IA/ML et leurs atténuations
Numéro 1 : perturbation contradictoire
Description
Dans une attaque par perturbation, l'attaquant modifie furtivement la requête pour obtenir la réponse souhaitée d'un modèle déployé en production[1]. Il s'agit d'une violation de l'intégrité d'entrée du modèle qui entraîne des attaques de style aléatoire dont le résultat final, sans être nécessairement une violation d'accès ou une EOP, compromet les performances de classification du modèle. Cela peut également se manifester au travers de trolls utilisant certains mots cibles de façon à ce que l'IA les interdise, ce qui a pour effet que le service est refusé à des utilisateurs légitimes dont le nom correspond à un mot « interdit ».
 [24]
[24]
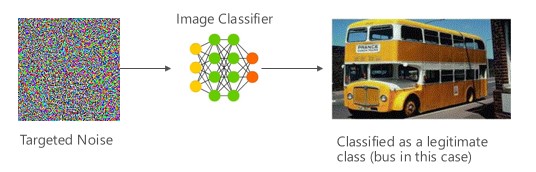
Variante numéro 1a : classification incorrecte ciblée
Dans ce cas, les attaquants génèrent un exemple qui n'est pas dans la classe d'entrée du classificateur cible, mais qui est classé par le modèle comme classe d'entrée particulière. L'exemple contradictoire peut apparaître comme un bruit aléatoire à l'œil nu. Cependant, les attaquants ont une certaine connaissance du système d'apprentissage automatique cible qui leur permet de générer un bruit blanc qui n'est pas aléatoire, mais qui exploite certains aspects spécifiques du modèle cible. L'adversaire fournit un exemple d'entrée qui n'est pas une classe légitime, mais le système cible le classe comme telle.
Exemples
 [6]
[6]
Corrections
Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training (Renforcement de la robustesse de la protection contre l'apprentissage automatique contradictoire à l'aide de la confiance dans le modèle induite par l'entraînement contre l'apprentissage automatique contradictoire) [19] : les auteurs proposent Highly Confident Near Neighbor (HCNN), un cadre qui combine les informations de confiance et la recherche du plus proche voisin, pour renforcer la robustesse l'apprentissage automatique contradictoire d'un modèle de base. Cela peut aider à distinguer entre les bonnes et les mauvaises prédictions du modèle dans le voisinage d'un point échantillonné de la distribution d'apprentissage sous-jacente.
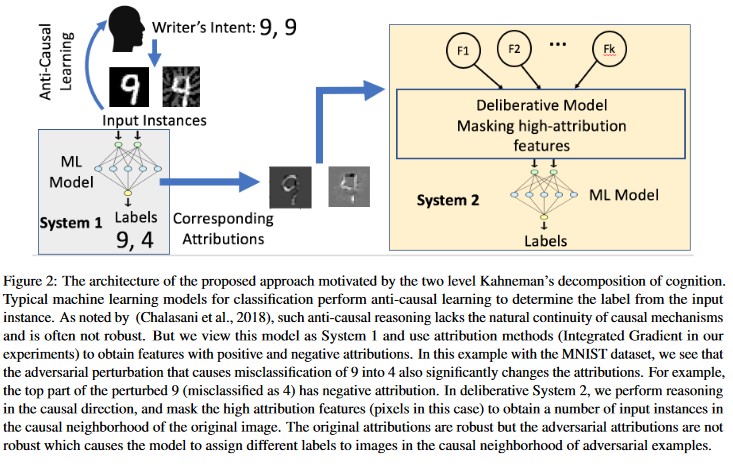
Attribution-driven Causal Analysis (Analyse causale basée sur l'attribution) [20] : les auteurs étudient le lien entre la résistance aux perturbations de l'apprentissage automatique contradictoire et l'explication basée sur l'attribution des décisions individuelles générées par les modèles d'apprentissage automatique. Ils signalent que les entrées contradictoires ne sont pas robustes dans l'espace d'attribution. Autrement dit, le masquage de quelques caractéristiques avec une attribution élevée amène à modifier l'indécision du modèle d'apprentissage automatique sur les exemples contradictoires. En revanche, les entrées naturelles sont robustes dans l'espace d'attribution.
 [20]
[20]
Ces approches peuvent rendre les modèles d'apprentissage automatique plus résilients aux attaques contradictoires, car le fait de tromper ce système de cognition à deux couches nécessite non seulement d'attaquer le modèle d'origine, mais également de s'assurer que l'attribution générée pour l'exemple contradictoire est semblable aux exemples originaux. Les deux systèmes doivent être compromis simultanément pour qu'une attaque contradictoire soit réussie.
Parallèles classiques
Élévation à distance des privilèges, car un attaquant a désormais le contrôle de votre modèle.
Niveau de gravité
Critique
Variante numéro 1b : erreur de classification source/cible
Cela se caractérise par la tentative d'un attaquant visant à obtenir d'un modèle qu'il lui renvoie l'étiquette souhaitée pour une entrée donnée. Cela oblige généralement un modèle à renvoyer un faux positif ou un faux négatif. Le résultat final est une prise de contrôle subtile de la précision de la classification du modèle, par laquelle un attaquant peut induire des contournements spécifiques à volonté.
Si cette attaque a un impact négatif important sur l'exactitude de la classification, elle peut aussi être plus longue à réaliser étant donné qu'un adversaire doit non seulement manipuler les données sources pour qu'elles ne soient plus étiquetées correctement, mais aussi les étiqueter spécifiquement avec l'étiquette frauduleuse souhaitée. Ces attaques impliquent souvent plusieurs étapes/tentatives pour forcer la classification incorrecte[3]. Si le modèle est susceptible de transférer des attaques d'apprentissage qui forcent la classification incorrecte ciblée, il se peut qu'il n'y ait pas d'empreinte discernable du trafic de l'attaquant, car les attaques de détection peuvent être effectuées hors connexion.
Exemples
Forçage du classement d'e-mails sans gravité en tant que courrier indésirable, ou aboutissant à la non-détection d'un exemple malveillant. On parle également dans ce cas d'attaque par évasion de modèle ou mimétisme.
Corrections
Actions de détection réactive/défensive
- Implémentez un seuil de temps minimal entre les appels à l'API fournissant des résultats de classification. Cela ralentit les tests d'attaque en plusieurs étapes en accroissant le temps total nécessaire pour trouver une perturbation réussie.
Actions proactives/protectrices
Feature Denoising for Improving Adversarial Robustness (Le débruitage des fonctionnalités pour améliorer la robustesse de la protection contre l'apprentissage automatique contradictoire) [22] : les auteurs développent une nouvelle architecture réseau qui augmente la robustesse de la protection contre l'apprentissage automatique contradictoire en effectuant un débruitage des fonctionnalités. Plus précisément, les réseaux contiennent des blocs qui débruitent les caractéristiques en utilisant des moyens non locaux ou d'autres filtres. L'ensemble des réseaux sont formés de bout en bout. Combinés à la formation contradictoire, les réseaux de débruitage des caractéristiques améliorent considérablement la robustesse contre les attaques contradictoires à la fois dans le cadre d'attaques de boîte blanche et de boîte noire.
Entraînement contradictoire et régularisation : entraînement à l'aide d'échantillons de problèmes d'apprentissage automatique contradictoire connus pour renforcer la résilience et la robustesse face aux entrées malveillantes. Cela peut également être considéré comme une forme de régularisation, qui pénalise la norme des gradients d'entrée et rend la fonction de prédiction du classificateur plus lisse (en augmentant la marge d'entrée). Cela inclut des classifications correctes avec des taux de confiance plus faibles.
Investissez dans le développement d'une classification monotone avec sélection de caractéristiques monotones. Cela garantit que l'adversaire ne pourra pas se soustraire au classificateur en se contentant d'ajouter des caractéristiques de la classe négative[13].
La compression des caractéristiques[18] peut être utilisée pour durcir les modèles DNN en détectant des exemples contradictoires. Elle réduit l'espace de recherche dont dispose un adversaire en fusionnant les échantillons qui correspondent à de nombreux vecteurs de caractéristiques différents dans l'espace d'origine. En comparant la prédiction d'un modèle DNN de l'entrée d'origine avec celle de l'entrée compressée, la compression des caractéristiques peut aider à détecter des exemples contradictoires. Si les exemples originaux et compressés produisent des sorties sensiblement différentes du modèle, l'entrée est susceptible d'être contradictoire. En mesurant le désaccord entre les prédictions et en sélectionnant une valeur seuil, le système peut générer la prédiction correcte pour les exemples légitimes et rejette les entrées contradictoires.

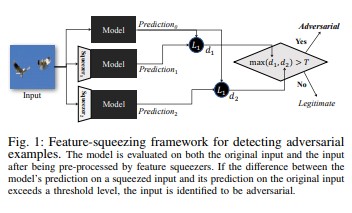 [18]
[18]Certified Defenses against Adversarial Examples (Défenses certifiées contre les exemples de problèmes d'apprentissage automatique contradictoire) [22] : les auteurs proposent une méthode basée sur une relaxation semi-définie qui produit un certificat attestant que, pour un réseau et une entrée de test donnés, aucune attaque ne peut forcer l'erreur à dépasser une certaine valeur. Ensuite, comme ce certificat est différenciable, les auteurs l'optimisent conjointement avec les paramètres du réseau, fournissant ainsi un régularisateur adaptatif qui encourage la robustesse contre toutes les attaques.
Actions de réponse
- Émettez des alertes sur les résultats de classification ayant une forte variance entre les classificateurs, en particulier s'ils proviennent d'un seul utilisateur ou d'un petit groupe d'utilisateurs.
Parallèles classiques
Élévation à distance des privilèges
Niveau de gravité
Critique
Variante numéro 1c : classification incorrecte aléatoire
Il s'agit d'une variation spéciale dans laquelle la classification cible de l'attaquant peut être tout autre chose que la classification source légitime. L'attaque implique généralement l'injection aléatoire de bruit dans les données sources classées afin de réduire la probabilité d'utilisation de la classification correcte à l'avenir[3].
Exemples
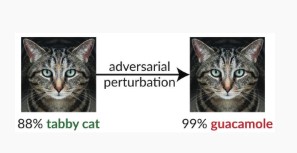
Corrections
Identique à la variante 1a.
Parallèles classiques
Déni de service non persistant
Niveau de gravité
Important
Variante numéro 1d : réduction de la confiance
Un attaquant peut créer des entrées afin de réduire le niveau de confiance de la classification correcte, en particulier dans des scénarios pouvant avoir des conséquences considérables. Cela peut également se traduire sous la forme d'un grand nombre de faux positifs destinés à saturer les administrateurs ou les systèmes de surveillance avec des alertes frauduleuses qu'il est impossible de distinguer des alertes légitimes[3].
Exemples

Corrections
- Outre les actions abordées dans la variante numéro 1a, la limitation des événements peut être utilisée pour réduire le volume d'alertes provenant d'une seule source.
Parallèles classiques
Déni de service non persistant
Niveau de gravité
Important
Numéro 2a : empoisonnement des données ciblées
Description
L'objectif de l'attaquant est de contaminer le modèle de machine généré lors de la phase d'apprentissage, de sorte que les prédictions sur de nouvelles données soient modifiées pendant la phase de test[1]. Dans des attaques par empoisonnement ciblées, l'attaquant souhaite classer erronément des exemples spécifiques pour faire en sorte que des mesures spécifiques soient prises ou omises.
Exemples
Soumission d'un logiciel AV en tant que logiciel malveillant pour forcer sa classification incorrecte comme malveillant et éliminer l'utilisation des logiciels AV ciblés sur les systèmes clients.
Corrections
Définir des capteurs d'anomalies pour examiner la distribution des données au jour le jour et alerter sur les variations :
– Mesurer la variation des données d'apprentissage quotidiennement, la télémétrie pour l'asymétrie/la dérive
Validation des entrées, à la fois assainissement et vérification de l'intégrité
L'empoisonnement injecte des exemples d'apprentissage périphériques. Deux stratégies principales pour contrer cette menace :
– Assainissement/validation des données : supprimer les exemples d'empoisonnement des données d'apprentissage – Mise en conteneur pour combattre les attaques par empoisonnement[14]
– Défense de type RONI (Reject-on-Negative-Impact)[15]
– Apprentissage robuste : choisissez des algorithmes d'apprentissage robustes en présence d'échantillons d'empoisonnement.
– L'une de ces approches est décrite dans [21], où les auteurs abordent le problème de l'empoisonnement des données en deux étapes : 1) l'introduction d'une nouvelle méthode robuste de factorisation de la matrice pour récupérer le véritable sous-espace, et 2) une nouvelle régression robuste des composantes de principe pour éliminer les instances d'apprentissage automatique contradictoire sur la base récupérée à l'étape (1). Ils caractérisent les conditions nécessaires et suffisantes pour la récupération du sous-espace réel et la présentation d'une limite sur la perte de prédiction attendue par rapport à la réalité du terrain.
Parallèles classiques
Hôte avec cheval de Troie grâce auquel l'attaquant persiste sur le réseau. Les données d'apprentissage ou de configuration sont compromises et sont ingérées/approuvées pour la création du modèle.
Niveau de gravité
Critique
Numéro 2b : empoisonnement des données aveugles
Description
L'objectif est de ruiner la qualité ou l'intégrité du jeu de données attaqué. De nombreux jeux de données sont publics, non fiables ou non traités. Cela suscite donc des inquiétudes supplémentaires quant à la capacité d'identifier les violations d'intégrité des données en premier lieu. Effectuer l'apprentissage sur des données compromises sans le savoir est une situation « garbage in, garbage out » (ordures à l'entrée, ordures à la sortie). Une fois la situation détectée, le triage doit déterminer l'étendue des données qui ont été violées ainsi que leur mise en quarantaine ou leur reformation.
Exemples
Une entreprise scrape un site web connu et fiable de données sur les contrats à terme du pétrole pour l'apprentissage de ses modèles. Le site web du fournisseur de données est par la suite compromis par une attaque par injection de code SQL. L'attaquant peut empoisonner le jeu de données à sa guise, tandis que le modèle en cours d'apprentissage n'est pas informé de la contamination des données.
Corrections
Identique à la variante 2a.
Parallèles classiques
Déni de service authentifié auprès d'une ressource de valeur élevée
Niveau de gravité
Important
Numéro 3 : attaques par inversion de modèle
Description
Les fonctionnalités privées utilisées dans des modèles d'apprentissage automatique peuvent être récupérées[1]. Elles peuvent permettre, par exemple, de reconstituer des données d'apprentissage privées auxquelles l'attaquant n'a pas accès. Également connues sous le nom d'attaques de type « hill-climbing » dans la communauté biométrique[16, 17], elles consistent à rechercher l'entrée qui optimise le niveau de confiance renvoyé, pour autant que la classification corresponde à la cible[4].
Exemples
 [4]
[4]
Corrections
Les interfaces des modèles formés à partir de données sensibles nécessitent un contrôle d'accès fort.
Interrogations sur les taux limites autorisées par le modèle.
Implémentez des portes entre les utilisateurs/appelants et le modèle réel en effectuant une validation des entrées pour toutes les requêtes proposées, en rejetant tout ce qui ne correspond pas à la définition du modèle de l'exactitude des entrées et en renvoyant uniquement la quantité minimale d'informations nécessaires pour être utile.
Parallèles classiques
Divulgation d'informations ciblées et secrètes
Niveau de gravité
Par défaut, ces données sont importantes selon la barre de bogue SDL standard, mais l'extraction de données sensibles ou personnellement identifiables rendrait la situation critique.
Numéro 4 : attaque par inférence d'abonnement
Description
L'attaquant peut déterminer si un enregistrement de données spécifique faisait ou non partie du jeu de données d'apprentissage du modèle[1]. Les chercheurs ont pu prédire la procédure principale d'un patient (par exemple, l'opération chirurgicale qu'il a subie) en se basant sur les attributs (par exemple, l'âge, le sexe, l'hôpital) [1].
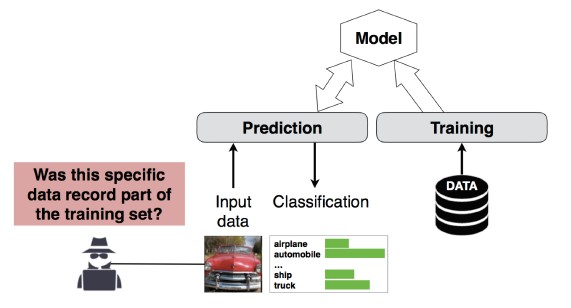 [12]
[12]
Corrections
Les documents de recherche démontrant la viabilité de cette attaque indiquent que la confidentialité différentielle[4, 9] est une atténuation efficace. C'est un domaine encore naissant chez Microsoft, et AETHER Engineering Security recommande de créer un savoir-faire en investissant dans la recherche dans ce domaine. Cette recherche doit énumérer les capacités de confidentialité différentielle et évaluer leur efficacité pratique en tant qu'atténuation, puis concevoir des méthodes pour que ces défenses soient héritées de façon transparente sur nos plateformes de services en ligne, de la même façon que le code de compilation dans Visual Studio vous offre des protections de sécurité par défaut qui sont transparentes pour le développeur et les utilisateurs.
L'utilisation de l'abandon des neurones et de l'empilement des modèles peut, dans une certaine mesure, constituer une atténuation efficace. L'utilisation de l'abandon des neurones augmente non seulement la résilience d'un réseau neural face à cette attaque, mais aussi les performances du modèle[4].
Parallèles classiques
Confidentialité des données. Des inférences sont effectuées à propos de l'inclusion d'un point de données dans le jeu d'apprentissage, mais les données d'apprentissage elles-mêmes ne sont pas divulguées.
Niveau de gravité
Il s'agit d'un problème de confidentialité, et non d'un problème de sécurité. Il est traité dans le guide de modélisation des menaces, car les domaines se chevauchent, mais toute réponse donnée ici est motivée par la confidentialité, et non par la sécurité.
Numéro 5 : vol de modèle
Description
Les attaquants recréent le modèle sous-jacent en interrogeant le modèle de façon légitime. La fonctionnalité du nouveau modèle est identique à celle du modèle sous-jacent[1]. Une fois le modèle recréé, il est possible de l'inverser afin de récupérer des informations sur des caractéristiques ou d'opérer des inférences sur des données d'apprentissage.
Résolution d'équation : pour un modèle qui retourne des probabilités de classe via une sortie d'API, un attaquant peut élaborer des requêtes visant à déterminer des variables inconnues dans un modèle.
Recherche de chemin : attaque consistant à exploiter les particularités d'une API pour extraire les « décisions » prises par un arbre de décision lors de la classification d'une entrée[7].
Attaque par transférabilité : un attaquant peut effectuer l'apprentissage d'un modèle local (par exemple, en adressant des requêtes de prédiction au modèle ciblé) et l'utiliser pour fabriquer des exemples contradictoires qui sont transférés vers le modèle cible[8]. Si votre modèle est extrait et trouvé vulnérable à un type d'entrée contradictoire, de nouvelles attaques dirigées contre votre modèle déployé en production peuvent être développées entièrement hors connexion par l'attaquant qui a extrait une copie de votre modèle.
Exemples
Quand un modèle d'apprentissage automatique sert à détecter des comportements hostiles, par exemple, pour identifier du courrier indésirable, classer des programmes malveillants et épingler des anomalies du réseau, une extraction du modèle peut faciliter des attaques par évasion[7].
Corrections
Actions proactives/protectrices
Réduisez ou embrouillez les détails retournés dans les API de prédiction tout en gardant leur utilité pour les applications « honnêtes »[7].
Définissez une requête bien formée pour les entrées de votre modèle et ne renvoyez les résultats qu'en réponse à des entrées complètes et bien formées correspondant à ce format.
Retournez les valeurs de confiance arrondies. La plupart des appelants légitimes n'ont pas besoin de plusieurs décimales de précision.
Parallèles classiques
Falsification non authentifiée et en lecture seule des données du système, divulgation ciblée d'informations de grande valeur ?
Niveau de gravité
Important dans les modèles sensibles à la sécurité, modérément dans le cas contraire
Numéro 6 : reprogrammation de réseau neural
Description
Une requête spécialement conçue par une persona non grata permet de reprogrammer un système d'apprentissage automatique pour accomplir une tâche qui s'écarte de l'intention initiale du créateur du système[1].
Exemples
Contrôles d'accès faibles sur une API de reconnaissance faciale permettant à des tiers d'incorporer celle-ci dans des applications conçues pour nuire aux clients de Microsoft, comme un générateur d'hypertrucages (deep fakes).
Corrections
Forte authentification mutuelle client<->serveur et contrôle d'accès aux interfaces modèles
Retrait des comptes incriminés.
Identifiez et appliquez un contrat de niveau de service pour vos API. Déterminez le délai acceptable pour régler un problème une fois qu'il a été signalé et s'assurer que le problème ne se reproduise plus une fois le contrat de service expiré.
Parallèles classiques
Il s'agit d'un scénario d'abus. Vous êtes moins susceptible d'ouvrir un incident de sécurité à ce sujet que de simplement désactiver le compte de la personne malveillante.
Niveau de gravité
Importante à critique
Numéro 7 : exemple d'apprentissage automatique contradictoire dans le domaine physique (bits->atomes)
Description
Un exemple d'apprentissage automatique est une entrée ou une requête provenant d'une entité malveillante, émise dans le seul but de tromper le système d'apprentissage automatique[1].
Exemples
Ces exemples peuvent se manifester dans le domaine physique, comme dans le cas d'une voiture autonome amenée à ignorer un panneau stop en raison d'une certaine couleur (entrée contradictoire) de la lumière se reflétant sur le panneau, ayant pour effet d'amener le système de reconnaissance des images à ne plus voir le signal Stop en tant que tel.
Parallèles classiques
Élévation de privilèges, exécution de code à distance
Corrections
Ces attaques se manifestent parce que les problèmes de la couche Machine Learning (la couche de données et d’algorithmes sous la prise de décision basée sur l’intelligence artificielle) n’ont pas été atténués. Comme pour tout autre logiciel *ou* système physique, la couche située sous la cible peut toujours être attaquée par le biais de vecteurs traditionnels. C'est la raison pour laquelle les pratiques de sécurité traditionnelles sont plus importantes que jamais, en particulier avec la couche de vulnérabilités non atténuées (la couche de données/d'algorithme) qui est utilisée entre l'IA et les logiciels traditionnels.
Niveau de gravité
Critique
Numéro 8 : fournisseurs malveillants d'applications d'apprentissage automatique capables de récupérer des données d'entraînement
Description
Un fournisseur malveillant présente un algorithme doté d'une porte dérobée, dans lequel les données d'apprentissage privées sont récupérées. Ils sont ainsi parvenus à reconstituer des visages et des textes à partir du seul modèle.
Parallèles classiques
Divulgation d'informations ciblées
Corrections
Les documents de recherche démontrant la viabilité de cette attaque indiquent que le chiffrement homomorphe est une atténuation efficace. C'est un domaine dans lequel Microsoft investit peu actuellement, et AETHER Engineering Security recommande de créer un savoir-faire en investissant dans la recherche dans ce domaine. Cette recherche doit énumérer les principes de chiffrement homomorphe et évaluer leur efficacité pratique comme atténuations face aux fournisseurs MLaas (ML-as-a-Service) malveillants.
Niveau de gravité
Importante si les données sont des informations d'identification personnelle, modérée dans le cas contraire
Numéro 9 : attaque de la chaîne d'approvisionnement d'apprentissage automatique
Description
En raison du grand volume de données de ressources (données + calcul) nécessaires à l'entraînement des algorithmes, la pratique actuelle consiste à réutiliser les modèles entraînés par les grandes entreprises et à les modifier légèrement pour la tâche à accomplir (par exemple, ResNet est un modèle de reconnaissance d'images très répandu chez Microsoft). Ces modèles sont organisés en zoo (Caffe héberge des modèles populaires de reconnaissance des images). Cette attaque dirigée contre les modèles hébergés dans Caffe a pour effet d'empoisonner le puits pour tout autre utilisateur. [1]
Parallèles classiques
Compromission d'une dépendance à l'égard d'un tiers non liée à la sécurité
Magasin d'applications hébergeant de façon involontaire des logiciels malveillants
Corrections
Réduisez les dépendances à l'égard de tiers pour les modèles et les données dans la mesure du possible.
Incorporez ces dépendances dans votre processus de modélisation des menaces.
Tirez parti de l'authentification forte, du contrôle d'accès et du chiffrement entre les systèmes internes et tiers.
Niveau de gravité
Critique
Numéro 10 : apprentissage automatique avec porte dérobée
Description
Le processus d'apprentissage est externalisé à un tiers malveillant qui falsifie les données d'apprentissage et fournit un modèle doté d'un cheval de Troie qui force les classifications incorrectes ciblées, telles que la classification d'un virus donné comme non malveillant[1]. Il s'agit d'un risque dans les scénarios de génération de modèle ML-as-a-service.
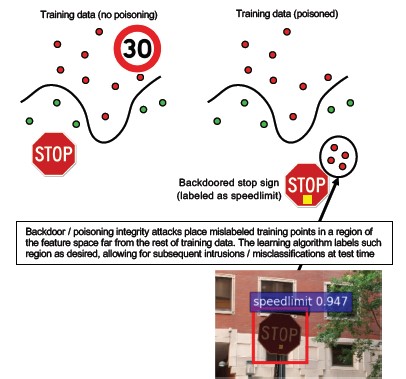 [12]
[12]
Parallèles classiques
Compromission d'une dépendance à l'égard d'un tiers liée à la sécurité
Mécanisme de mise à jour de logiciel compromis
Compromission de l'autorité de certification
Corrections
Actions de détection réactive/défensive
- Le dommage est déjà fait une fois que cette menace a été détectée, de sorte que le modèle et toutes les données d'apprentissage fournies par le fournisseur malveillant ne sont pas fiables.
Actions proactives/protectrices
Effectuer l'apprentissage de tous les modèles sensibles en interne
Cataloguer les données d'apprentissage ou s'assurer qu'elles proviennent d'un tiers de confiance ayant des pratiques de sécurité fortes
Modéliser les menaces de l'interaction entre le fournisseur MLaaS et vos propres systèmes
Actions de réponse
- Identique à la compromission d'une dépendance externe
Niveau de gravité
Critique
Numéro 11 : dépendances d'exploit informatique du système d'apprentissage automatique
Description
Dans ce cas, l'attaquant ne manipule PAS les algorithmes. Au lieu de cela, il exploite des vulnérabilités logicielles, telles que le dépassement de mémoire tampon ou l'exécution de scripts intersites[1]. Il est toujours plus facile de compromettre les couches logicielles sous IA/ML que d'attaquer directement la couche d'apprentissage. C'est pourquoi les pratiques traditionnelles d'atténuation des menaces de sécurité détaillées dans Security Development Lifecycle sont essentielles.
Parallèles classiques
Dépendance à l'égard de logiciels open source compromise
Vulnérabilité du serveur web (échec de validation des entrées API, XSS, CSRF)
Corrections
Collaborez avec votre équipe de sécurité pour suivre les meilleures pratiques en vigueur en matière de cycle de vie du développement de la sécurité et d'assurance de sécurité opérationnelle.
Niveau de gravité
Variable ; jusqu'à critique selon le type de vulnérabilité logicielle traditionnelle.
Bibliographie
[1] Failure Modes in Machine Learning ; Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen et Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] Équipe virtuelle de provenance et de traçabilité des données, Flux de travail d'ingénierie de sécurité AETHER
[3] Adversarial Examples in Deep Learning: Characterization and Divergence, Wei, et al,https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha et T. Ristenpart. « Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures », dans Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot et Patrick McDaniel. Adversarial Examples in Machine Learning AIWTB 2017.
[7] Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL) ; Fan Zhang, Université de Cornell ; Ari Juels, Cornell Tech ; Michael K. Reiter, Université de Caroline du Nord à Chapel Hill ; Thomas Ristenpart, Cornell Tech. Stealing Machine Learning Models via Prediction APIs.
[8] Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh et Patrick McDaniel. The Space of Transferable Adversarial Examples.
[9] Yunhui Long1, Vincent Bindschaedler1, Lei Wang2, Diyue Bu2, Xiaofeng Wang2, Haixu Tang2, Carl A. Gunter1 et Kai Chen3,4. Understanding Membership Inferences on Well-Generalized Learning Models.
[10] Simon-Gabriel et al. Adversarial vulnerability of neural networks increases with input dimension. ArXiv 2018.
[11] Lyu et al. A unified gradient regularization family for adversarial examples. ICDM 2015.
[12] Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Inigo Incer et al. Adversarially Robust Malware Detection Using Monotonic Classification.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto et Fabio Roli. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks
[15] An Improved Reject on Negative Impact Defense Hongjiang Li and Patrick P.K. Chan
[16] Adler. Vulnerabilities in biometric encryption systems. 5e conférence internationale. AVBPA. 2005.
[17] Galbally, McCool, Fierrez, Marcel et Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks. Patt. Rec. 2010.
[18] Weilin Xu, David Evans et Yanjun Qi. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. Network and Distributed System Security Symposium, 2018. Du 18 au 21 février.
[19] Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha. Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training.
[20] Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami. Attribution-driven Causal Analysis for Detection of Adversarial Examples.
[21] Chang Liu et al. Robust Linear Regression Against Training Data Poisoning.
[22] Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille et Kaiming He. Feature Denoising for Improving Adversarial Robustness.
[23] Aditi Raghunathan, Jacob Steinhardt et Percy Liang. Certified Defenses against Adversarial Examples.
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour