Ressources déployées avec Clusters Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Cet article décrit les ressources déployées par un cluster Big Data SQL Server.
Un cluster Big Data déploie des pods en fonction du profil de déploiement. Pour plus d’informations, consultez Configurations par défaut.
Cet article décrit les pods déployés avec un profil aks-dev-test-ha et comprend un pool Spark. Interrogez Kubernetes pour voir les pods déployés dans votre cluster. L’exemple suivant retourne une liste de pods sous un espace de noms spécifique.
kubectl get pods -n <namespace>
Remplacez <namespace> par le nom de votre cluster Big Data.
Pour plus d’informations, consultez Guide pratique pour déployer Clusters Big Data SQL Server sur Kubernetes.
Le diagramme suivant montre les composants déployés dans un cluster Big Data :
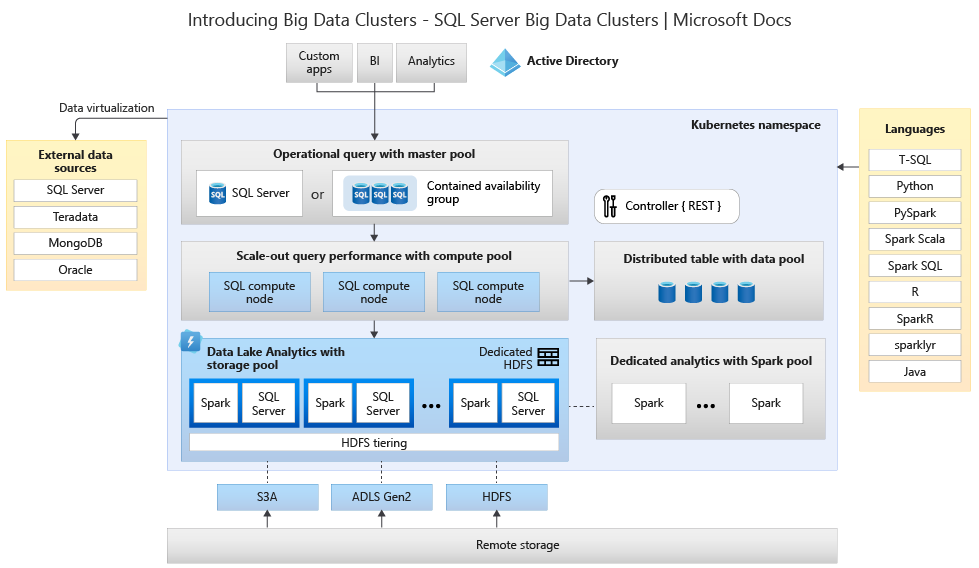
Pour plus d’informations sur l’architecture, consultez Présentation des Clusters Big Data SQL Server.
Pods déployés
Le tableau suivant liste les pods déployés dans un cluster Big Data.
| Nom | Domaine |
|---|---|
control-<nnnn> |
Contrôle |
controldb-<#> |
Contrôle |
controlwd-<nnnn> |
Contrôle |
logsdb-<#> |
Contrôle |
logsui-<nnnn> |
Contrôle |
metricsdb-<#> |
Contrôle |
metricsdc-<nnnn> |
Contrôle |
metricsui-<nnnn> |
Contrôle |
mgmtproxy-<nnnn> |
Contrôle |
zookeeper-<#> |
Contrôle |
dns-<nnnn> |
Contrôle |
master-<#n> |
Instance maître |
operator-<nnnn> |
Instance maître |
compute-<#n>-<#m> |
Pool de calcul |
data-<#>-<#> |
Pool de données |
storage-<#>-<#> |
Pool de stockage |
nmnode-<#>-<#> |
Pool de stockage |
sparkhead-<#> |
Pool de stockage |
appproxy-<#m> |
Pool d’applications |
gateway-<#> |
Service de passerelle |
Tous les pods ne sont pas inclus dans chaque cluster Big Data. Les déploiements avec une haute disponibilité ou une intégration à Active Directory incluent des pods spécifiques.
Pods propres à la haute disponibilité :
operator-<nnnn>zookeeper-<#>
Pod propres à Active Directory :
dns-<nnnn>
Les sections suivantes décrivent les pods et listent les conteneurs dans chaque pod.
Control
Les pods de contrôle fournissent le service de contrôle.
| Nom du pod | Count | Type de contrôleur Kubernetes | Containers |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
1 par nœud Kubernetes. | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 ou 1 pour l’intégration à Active Directory | ReplicaSet | - dns- fluentbit |
Instance principale
master-<#n> est l’instance maître SQL Server.
- Gère le pool de données via DDL
- Manipule les données dans le pool de données via DML
- Déplace l’exécution des requêtes analytiques vers le pool de données
| Nom du pod | Count | Type de contrôleur Kubernetes | Containers |
|---|---|---|---|
master-<#n> |
1 ou plus pour la haute disponibilité. | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
0 ou 1 pour la haute disponibilité | ReplicaSet | - mssql-ha-operator |
* Uniquement les déploiements à haute disponibilité. L’opérateur implémente et inscrit la définition de ressource personnalisée pour SQL Server et les ressources de groupe de disponibilité. Quand l’opérateur est déployé, il s’inscrit lui-même en tant qu’écouteur pour les notifications relatives aux ressources SQL Server déployées dans le cluster Kubernetes. mssql-ha-supervisor prend en charge le groupe de disponibilité.
Chaque pod master contient une instance de SQL Server. Un déploiement à haute disponibilité comprend trois pods. Chaque pod comprend une instance de SQL Server avec des bases de données dans un groupe de disponibilité Always On SQL Server.
Ajoutez des pods supplémentaires au moment du déploiement, en fonction de votre charge de travail.
Pool de calcul
Le pool de calcul fournit une instance de SQL Server pour le calcul.
| Nom du pod | Count | Type de contrôleur Kubernetes | Containers |
|---|---|---|---|
compute-<#n>-<#m> |
1 ou plus. | StatefulSet | - mssql-server- fluentbit- collectd |
#nidentifie le pool de calcul.#midentifie l’ID d’instance dans le pool.
Les instances du pool de calcul SQL Server sont sans état. Elles nécessitent uniquement le stockage pour tempdb.
Ajoutez des pods supplémentaires au moment du déploiement, en fonction de votre charge de travail.
Pool de données
Le pool de données fournit des instances de SQL Server pour le stockage et le calcul.
| Nom du pod | Count | Type de contrôleur Kubernetes | Containers |
|---|---|---|---|
data-<#n>-<#m> |
0 ou plus | StatefulSet | - mssql-server - fluentbit- collectd |
#nidentifie le pool de données.#midentifie l’ID d’instance dans le pool.
Ajoutez des pods supplémentaires au moment du déploiement, en fonction de la charge de travail.
Pool de stockage
Le pool de stockage fournit l’ingestion des données par le biais de Spark, le stockage dans HDFS, l’accès aux données par le biais de HDFS et des points de terminaison SQL Server.
| Nom du pod | Count | Type de contrôleur Kubernetes | Containers |
|---|---|---|---|
storage-0-# |
1 ou plus. Ajoutez des pods supplémentaires au moment du déploiement, en fonction de la charge de travail. | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
1 ou plus pour la haute disponibilité | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
1 ou plus pour la haute disponibilité | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 ou 3 pour la haute disponibilité. | StatefulSet | - zookeeper- fluentbit |
Pool d'applications
Le pool d’applications est inclus dans certains profils de configuration de test. Le pool d’applications héberge des proxys de service d’application que vous définissez quand vous déployez vos applications pour des clusters Big Data.
appproxy est une API web qui se trouve devant les applications du pool d’applications. Elle authentifie les utilisateurs, puis route les requêtes vers les applications.
| Nom du pod | Type de contrôleur Kubernetes | Containers |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
Pour plus d’informations, consultez Présentation du déploiement d’application sur un cluster Big Data.
Ajoutez des pods supplémentaires au moment du déploiement, en fonction de la charge de travail.
Service de passerelle
Les services de passerelle fournissent la passerelle Knox à Spark, HDFS, Yarn, l’interface utilisateur Yarn et l’interface utilisateur Spark.
| Nom du pod | Type de contrôleur Kubernetes | Containers |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
Une seule passerelle est prise en charge.
Références de conteneur open source
Pour plus d’informations sur des versions et projets open source spécifiques, consultez Informations de référence sur les logiciels Open Source.
Étapes suivantes
Pour en savoir plus sur les Clusters Big Data SQL Server, consultez les ressources suivantes :
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour