Tutoriel Python : Déployer un modèle de régression linéaire avec le Machine Learning SQL
S’applique à : ![]() SQL Server 2017 (14.x) et versions ultérieures
SQL Server 2017 (14.x) et versions ultérieures ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Dans la quatrième partie de cette série de quatre tutoriels, vous allez déployer un modèle de régression linéaire développé dans Python dans une base de données SQL Server à l’aide de Machine Learning Services ou sur des clusters Big Data.
Dans la quatrième partie de cette série de quatre tutoriels, vous allez déployer un modèle de régression linéaire développé dans Python dans une base de données SQL Server à l’aide de Machine Learning Services.
Dans la quatrième partie de cette série de quatre tutoriels, vous allez déployer un modèle de régression linéaire développé en Python dans une base de données Azure SQL Managed Instance à l’aide de Machine Learning Services.
Dans cet article, vous allez apprendre à :
- Créer une procédure stockée qui génère le modèle Machine Learning
- Stocker le modèle dans une table de base de données
- Créer une procédure stockée qui effectue des prédictions à l’aide du modèle
- Exécuter le modèle avec de nouvelles données
Dans la première partie, vous avez appris à restaurer l’exemple de base de données.
Dans la deuxième partie, vous avez appris à charger les données à partir d’une base de données dans une trame de données Python et à préparer les données dans Python.
Dans la troisième partie, vous avez appris à former un modèle Machine Learning de régression linéaire dans Python.
Prérequis
- La quatrième partie de ce tutoriel suppose que vous avez terminé la première partie et ses conditions préalables.
Créer une procédure stockée qui génère le modèle
À l’aide des scripts Python que vous avez développés, créez maintenant une procédure stockée generate_rental_py_model qui forme et génère le modèle de régression linéaire à l’aide de LinearRegression à partir de scikit-learn.
Exécutez l’instruction T-SQL suivante dans Azure Data Studio pour créer la procédure stockée afin de former le modèle.
-- Stored procedure that trains and generates a Python model using the rental_data and a linear regression algorithm
DROP PROCEDURE IF EXISTS generate_rental_py_model;
go
CREATE PROCEDURE generate_rental_py_model (@trained_model varbinary(max) OUTPUT)
AS
BEGIN
EXECUTE sp_execute_external_script
@language = N'Python'
, @script = N'
from sklearn.linear_model import LinearRegression
import pickle
df = rental_train_data
# Get all the columns from the dataframe.
columns = df.columns.tolist()
# Store the variable well be predicting on.
target = "RentalCount"
# Initialize the model class.
lin_model = LinearRegression()
# Fit the model to the training data.
lin_model.fit(df[columns], df[target])
# Before saving the model to the DB table, convert it to a binary object
trained_model = pickle.dumps(lin_model)'
, @input_data_1 = N'select "RentalCount", "Year", "Month", "Day", "WeekDay", "Snow", "Holiday" from dbo.rental_data where Year < 2015'
, @input_data_1_name = N'rental_train_data'
, @params = N'@trained_model varbinary(max) OUTPUT'
, @trained_model = @trained_model OUTPUT;
END;
GO
Stocker le modèle dans une table de base de données
Créez une table dans la base de données TutorialDB, puis enregistrez le modèle dans la table.
Exécutez l’instruction T-SQL suivante dans Azure Data Studio pour créer une table appelée dbo.rental_py_models qui est utilisée pour stocker le modèle.
USE TutorialDB; DROP TABLE IF EXISTS dbo.rental_py_models; GO CREATE TABLE dbo.rental_py_models ( model_name VARCHAR(30) NOT NULL DEFAULT('default model') PRIMARY KEY, model VARBINARY(MAX) NOT NULL ); GOEnregistrez le modèle dans la table sous la forme d’un objet binaire, avec le nom du modèle linear_model.
DECLARE @model VARBINARY(MAX); EXECUTE generate_rental_py_model @model OUTPUT; INSERT INTO rental_py_models (model_name, model) VALUES('linear_model', @model);
Créer une procédure stockée qui effectue des prédictions
Créez une procédure stockée py_predict_rentalcount qui effectue des prédictions à l’aide du modèle formé et d’un jeu de nouvelles données. Exécutez le code T-SQL ci-dessous dans Azure Data Studio.
DROP PROCEDURE IF EXISTS py_predict_rentalcount; GO CREATE PROCEDURE py_predict_rentalcount (@model varchar(100)) AS BEGIN DECLARE @py_model varbinary(max) = (select model from rental_py_models where model_name = @model); EXECUTE sp_execute_external_script @language = N'Python', @script = N' # Import the scikit-learn function to compute error. from sklearn.metrics import mean_squared_error import pickle import pandas rental_model = pickle.loads(py_model) df = rental_score_data # Get all the columns from the dataframe. columns = df.columns.tolist() # Variable you will be predicting on. target = "RentalCount" # Generate the predictions for the test set. lin_predictions = rental_model.predict(df[columns]) print(lin_predictions) # Compute error between the test predictions and the actual values. lin_mse = mean_squared_error(lin_predictions, df[target]) #print(lin_mse) predictions_df = pandas.DataFrame(lin_predictions) OutputDataSet = pandas.concat([predictions_df, df["RentalCount"], df["Month"], df["Day"], df["WeekDay"], df["Snow"], df["Holiday"], df["Year"]], axis=1) ' , @input_data_1 = N'Select "RentalCount", "Year" ,"Month", "Day", "WeekDay", "Snow", "Holiday" from rental_data where Year = 2015' , @input_data_1_name = N'rental_score_data' , @params = N'@py_model varbinary(max)' , @py_model = @py_model with result sets (("RentalCount_Predicted" float, "RentalCount" float, "Month" float,"Day" float,"WeekDay" float,"Snow" float,"Holiday" float, "Year" float)); END; GOCréez une table pour stocker les prédictions.
DROP TABLE IF EXISTS [dbo].[py_rental_predictions]; GO CREATE TABLE [dbo].[py_rental_predictions]( [RentalCount_Predicted] [int] NULL, [RentalCount_Actual] [int] NULL, [Month] [int] NULL, [Day] [int] NULL, [WeekDay] [int] NULL, [Snow] [int] NULL, [Holiday] [int] NULL, [Year] [int] NULL ) ON [PRIMARY] GOExécuter la procédure stockée pour prédire le nombre de loyers
--Insert the results of the predictions for test set into a table INSERT INTO py_rental_predictions EXEC py_predict_rentalcount 'linear_model'; -- Select contents of the table SELECT * FROM py_rental_predictions;Vous devez obtenir des résultats similaires à ce qui suit :
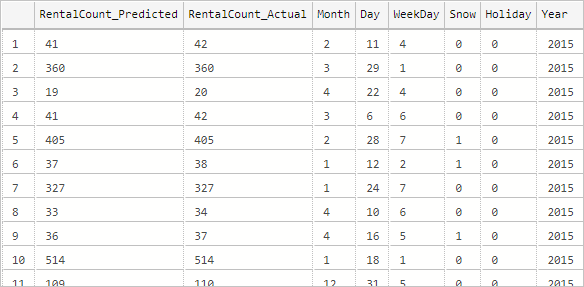
Vous avez correctement créé, entraîné et déployé un modèle. Vous avez ensuite utilisé ce modèle dans une procédure stockée pour prédire des valeurs en fonction de nouvelles données.
Étapes suivantes
Dans la quatrième partie de cette série de tutoriels, vous avez effectué les étapes suivantes :
- Créer une procédure stockée qui génère le modèle Machine Learning
- Stocker le modèle dans une table de base de données
- Créer une procédure stockée qui effectue des prédictions à l’aide du modèle
- Exécuter le modèle avec de nouvelles données
Pour en savoir plus sur l’utilisation de Python avec le Machine Learning SQL, consultez :