Paramétrer les index non-cluster avec les suggestions d’index manquants
S’applique à : ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
La fonctionnalité des index manquants est un outil léger qui permet de rechercher les index manquants qui pourraient améliorer nettement les performances des requêtes. Cet article explique comment utiliser les suggestions d’index manquants pour paramétrer efficacement les index et améliorer les performances des requêtes.
Limitations de la fonctionnalité des index manquants
Quand l’optimiseur de requête génère un plan de requête, il effectue une analyse pour déterminer quels sont les meilleurs index d’une condition de filtre spécifique. S’il n’existe pas de meilleurs index, l’optimiseur de requête génère toujours un plan de requête à l’aide des méthodes d’accès les moins coûteuses. Toutefois, il stocke également les informations relatives à ces index. La fonctionnalité des index manquants vous permet d’accéder aux informations relatives aux meilleurs index pour que vous puissiez décider s’ils doivent être implémentés.
L’optimisation des requêtes est un processus sensible au facteur temps. Il existe donc des limitations à la fonctionnalité des index manquants. Ces limitations incluent :
- Les suggestions d’index manquants sont basées sur des estimations effectuées durant l’optimisation d’une seule requête, avant son exécution. Les suggestions d’index manquants ne sont pas testées ou mises à jour après l’exécution de la requête.
- La fonctionnalité des index manquants suggère uniquement des index rowstore sur disque non-cluster. Les index uniques et filtrés ne sont pas suggérés.
- Les colonnes clés sont suggérées, mais la suggestion ne spécifie pas l’ordre de ces colonnes. Pour plus d’informations sur l’ordre des colonnes, consultez la section Appliquer les suggestions d’index manquants dans cet article.
- Les colonnes incluses sont suggérées, mais SQL Server n’effectue aucune analyse de type coût/avantage concernant la taille de l’index résultant quand un grand nombre de colonnes incluses sont suggérées.
- Les requêtes d’index manquants peuvent offrir des variantes d’index similaires pour la même table et les mêmes colonnes d’une requête à l’autre. Il est important de passer en revue les suggestions d’index et de les combiner dans la mesure du possible.
- Aucune suggestion n’est proposée pour les plans de requête triviaux.
- Les informations de coût sont moins précises pour les requêtes impliquant uniquement des prédicats d’inégalité.
- Les suggestions sont rassemblées pour 600 groupes d’index manquants au maximum. Une fois ce seuil atteint, plus aucune donnée de groupe d’index manquantes n’est collectée.
En raison de ces limitations, il est préférable de considérer les suggestions d’index manquants comme l’une des nombreuses sources d’informations disponibles au moment de l’analyse, de la conception, du paramétrage et des tests d’index. Les suggestions d’index manquants ne sont pas des recommandations pour créer des index exactement tel que cela est suggéré.
Remarque
Azure SQL Database propose un paramétrage automatique d’index. Le paramétrage automatique d’index utilise le machine learning pour apprendre horizontalement à partir de toutes les bases de données d’Azure SQL Database via l’IA. Cela permet ainsi une amélioration dynamique des actions de paramétrage. Le paramétrage automatique d’index comprend un processus de vérification qui permet de garantir une amélioration positive des performances de la charge de travail à partir des index créés.
Voir les recommandations relatives aux index manquants
La fonctionnalité des index manquants se compose de deux composants :
- Élément
MissingIndexesdans le code XML des plans d’exécution. Cela vous permet de corréler les index que l’optimiseur de requête considère comme manquants par rapport aux requêtes pour lesquelles ils sont manquants. - Ensemble de vues DMV (vues de gestion dynamique) qui peuvent être interrogées pour retourner des informations sur les index manquants. Cela vous permet de voir toutes les recommandations d’index manquants pour une base de données.
Voir les suggestions d’index manquants dans les plans d’exécution
Vous pouvez générer ou obtenir les plans d’exécution de requête de plusieurs façons :
- Durant l’écriture ou le paramétrage d’une requête, vous pouvez utiliser SSMS (SQL Server Management Studio) pour afficher le plan d’exécution estimé sans exécuter la requête, ou pour exécuter la requête et afficher un plan d’exécution réel.
- Le Magasin des requêtes, une fois activé, collecte les plans d’exécution.
- Vous pouvez identifier les plans d’exécution mis en cache en interrogeant les vues DMV (vues de gestion dynamique) telles que sys.dm_exec_text_query_plan.
Par exemple, vous pouvez utiliser la requête suivante pour générer des requêtes d’index manquants à partir de l’exemple de base de données AdventureWorks.
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
Pour générer et voir les requêtes d’index manquants :
Ouvrez SSMS et connectez une session à votre copie de l’exemple de base de données AdventureWorks.
Collez la requête dans la session, puis générez un plan d’exécution estimé dans SSMS pour cette requête en sélectionnant le bouton de barre d’outils Afficher le plan d’exécution estimé. Le plan d’exécution s’affiche dans un volet de la session active. Une instruction Index manquant de couleur verte apparaît vers le haut du plan graphique.

Un seul plan d’exécution peut contenir plusieurs requêtes d’index manquants. Toutefois, une seule requête d’index manquant peut être affichée dans le plan d’exécution graphique. Vous pouvez voir la liste complète des index manquants d’un plan d’exécution en affichant le fichier XML du plan d’exécution.
Cliquez avec le bouton droit sur le plan d’exécution, puis sélectionnez Afficher le fichier XML du plan d’exécution dans le menu.
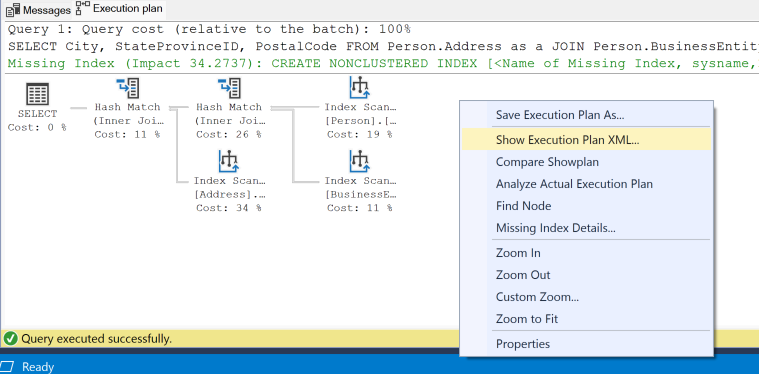
Le code XML du plan d’exécution s’ouvre sous forme d’un nouvel onglet dans SSMS.
Remarque
Une seule suggestion d’index manquant s’affiche dans l’option de menu Détails sur l’index absent, même si plusieurs suggestions sont présentes dans le code XML du plan d’exécution. La suggestion d’index manquant affichée n’est peut-être pas celle dont l’amélioration estimée est la plus élevée pour la requête.
Affichez la boîte de dialogue Rechercher à l’aide du raccourci Ctrl+F.
Recherchez
MissingIndex.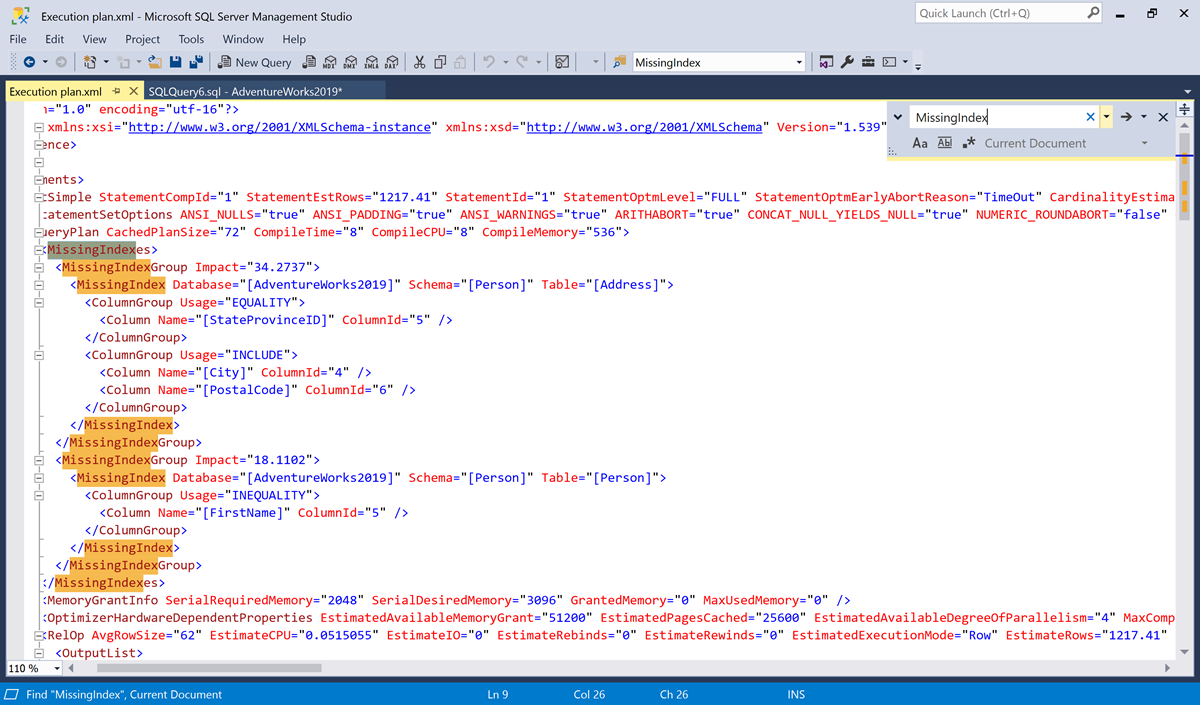
Dans cet exemple, il existe deux éléments
MissingIndex.- La première suggestion d’index manquant indique que la requête peut utiliser un index pour la table
Person.Address, qui prend en charge une recherche d’égalité sur la colonneStateProvinceID, laquelle comprend deux colonnes supplémentaires,CityetPostalCode. Au moment de l’optimisation, l’optimiseur de requête pensait que cet index pouvait réduire le coût estimé de la requête de 34,2737 %. - La seconde suggestion d’index manquant indique que la requête peut utiliser un index pour la table
Person.Person, qui prend en charge une recherche d’inégalité sur la colonne FirstName. Au moment de l’optimisation, l’optimiseur de requête pensait que cet index pouvait réduire le coût estimé de la requête de 18,1102 %.
- La première suggestion d’index manquant indique que la requête peut utiliser un index pour la table


Chaque index non cluster sur disque de votre base de données occupe de l’espace, ajoute une surcharge pour les insertions, les mises à jour et les suppressions, et peut nécessiter une maintenance. Pour ces raisons, il est recommandé de passer en revue toutes les requêtes d’index manquants ainsi que les index existants d’une table avant d’ajouter un index basé sur un plan d’exécution de requête.
Voir les suggestions d’index manquants dans les vues DMV
Vous pouvez récupérer les informations sur les index manquants en interrogeant les objets de gestion dynamique listés dans le tableau suivant.
| Vue de gestion dynamique | Informations renvoyées |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | Renvoie des informations récapitulatives sur les groupes d’index manquants, par exemple les améliorations des performances qui pourraient être acquises en implémentant un groupe spécifique d’index manquants. |
| sys.dm_db_missing_index_groups (Transact-SQL) | Renvoie des informations sur un groupe spécifique d’index manquants, tels que l’identificateur de groupe et les identificateurs de tous les index manquants contenus dans ce groupe. |
| sys.dm_db_missing_index_details (Transact-SQL) | Renvoie des informations détaillées sur un index manquant ; par exemple, le nom et l’identificateur de la table où l’index est manquant, ainsi que les colonnes et les types de colonnes qui doivent correspondre à l’index manquant. |
| sys.dm_db_missing_index_columns (Transact-SQL) | Renvoie des informations sur les colonnes des tables de base de données dans lesquelles un index est manquant. |
La requête suivante utilise les vues DMV d’index manquants pour générer les instructions CREATE INDEX. Les instructions de création d’index présentées ici sont destinées à vous aider à créer votre propre instruction DDL (langage de définition de données), une fois que vous avez examiné toutes les requêtes ainsi que tous les index existants de la table.
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
Cette requête trie les suggestions en fonction d’une colonne nommée estimated_improvement. L’amélioration estimée est basée sur une combinaison des éléments suivants :
- Estimation du coût des requêtes associées à la requête d’index manquant.
- Estimation de l’impact de l’ajout de l’index. Il s’agit d’une estimation de la réduction du coût de requête apportée par l’index non-cluster.
- Somme des exécutions des opérateurs de requête (recherches et analyses) pour les requêtes associées à la requête d’index manquant. Comme nous l’avons vu dans la méthode permettant de faire persister les index manquants avec le Magasin des requêtes, ces informations sont régulièrement effacées.
Remarque
Le script Index-Creation dans Tiger Toolbox de Microsoft examine les vues DMV d’index manquants et supprime automatiquement tous les index suggérés redondants. De plus, il analyse les index à faible impact et génère des scripts de création d’index que vous pouvez passer en revue. Comme dans la requête ci-dessus, il n’exécute PAS les commandes de création d’index. Le script Index-Creation convient à SQL Server et Azure SQL Managed Instance. Pour Azure SQL Database, implémentez le paramétrage automatique d’index.
Passez en revue les limitations de la fonctionnalité des index manquants et la façon d’appliquer les suggestions d’index manquants avant de créer des index, puis modifiez le nom d’index pour qu’il corresponde à la convention de nommage de votre base de données.
Faire persister les index manquants avec le Magasin des requêtes
Les suggestions d’index manquants dans les vues DMV sont effacées par des événements tels que les redémarrages d’instances, les basculements et la mise hors connexion d’une base de données. De plus, quand les métadonnées d’une table changent, toutes les informations d’index manquants relatives à cette table sont supprimées de ces objets de gestion dynamique. Les modifications apportées aux métadonnées d’une table peuvent se produire lorsque des colonnes sont ajoutées ou supprimées d’une table, par exemple, ou lorsqu’un index est créé sur une colonne d’une table. L’exécution d’une opération ALTER INDEX REBUILD sur l’index d’une table entraîne également l’effacement des requêtes d’index manquants pour cette table.
De même, les plans d’exécution stockés dans le cache de plans sont effacés par des événements tels que les redémarrages d’instances, les basculements et la mise hors connexion d’une base de données. Les plans d’exécution peuvent être supprimés du cache pour plusieurs raisons, notamment la sollicitation de la mémoire et les recompilations.
Vous pouvez faire persister les suggestions d’index manquants des plans d’exécution pour ces événements en activant le Magasin des requêtes.
La requête suivante récupère les 20 premiers plans de requête contenant des requêtes d’index manquants dans le Magasin des requêtes en fonction d’une estimation du nombre total de lectures logiques de la requête. Les données se limitent aux exécutions de requêtes effectuées au cours des dernières 48 heures.
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
Appliquer les suggestions d’index manquants
Pour utiliser efficacement les suggestions d’index manquants, suivez les recommandations sur la conception d’index non-cluster. Durant le paramétrage d’index non-cluster avec des suggestions d’index manquants, passez en revue la structure de la table de base, combinez avec soin les index, tenez compte de l’ordre des colonnes clés et passez en revue les suggestions de colonnes incluses.
Passer en revue la structure de la table de base
Avant de créer des index non-cluster sur une table en fonction des suggestions d’index manquants, passez en revue l’index cluster de la table.
Pour vérifier la présence d’un index cluster, vous pouvez utiliser la procédure stockée système sp_helpindex. Par exemple, nous pouvons voir un récapitulatif des index de la table Person.Address en exécutant l’instruction suivante :
exec sp_helpindex 'Person.Address';
GO
Examinez la colonne index_description. Une table ne peut avoir qu’un seul index cluster. Si un index cluster a été implémenté pour la table, index_description contient le mot « cluster ».

Si aucun index cluster n’est présent, la table est un tas. Dans ce cas, vérifiez si la table a été créée intentionnellement en tant que tas pour résoudre un problème de performances spécifique. La plupart des tables tirent parti des index cluster. Il arrive que les tables soient implémentées sous forme de tas par accident. Implémentez un index cluster en fonction des recommandations sur la conception d’index cluster.
Vérifier si les index manquants et les index existants se chevauchent
Les index manquants peuvent offrir des variantes d’index non cluster similaires pour la même table et les mêmes colonnes d’une requête à l’autre. Les index manquants peuvent également être similaires aux index existants d’une table. Pour des performances optimales, il est préférable d’examiner les index manquants et les index existants à la recherche de chevauchements afin d’éviter de créer des index en double.
Créer un script de traitement des index existants d’une table
Vous pouvez examiner la définition des index existants d’une table de plusieurs façons, notamment en écrivant un script de traitement des index à l’aide du volet Détails de l’Explorateur d’objets :
- Connectez l’Explorateur d’objets à votre instance ou base de données.
- Développez le nœud de la base de données en question dans l’Explorateur d’objets.
- Développez le dossier Tables .
- Développez la table pour laquelle vous souhaitez générer un script de traitement des index.
- Sélectionnez le dossier Index.
- Si le volet Détails de l’Explorateur d’objets n’est pas déjà ouvert, dans le menu Affichage, sélectionnez Détails de l’Explorateur d’objets, ou appuyez sur F7.
- Sélectionnez tous les index listés dans le volet Détails de l’Explorateur d’objets à l’aide du raccourci Ctrl+A.
- Cliquez avec le bouton droit n’importe où dans la zone sélectionnée, choisissez l’option de menu Script index as (Générer un script d’index), puis CREATE To et Nouvelle fenêtre d’éditeur de requête.

Passer en revue les index et les combiner si possible
Passez en revue les recommandations relatives aux index manquants d’une table sous forme de groupe ainsi que les définitions d’index existants de la table. Rappelez-vous que durant la définition des index, les colonnes d’égalité doivent généralement être placées avant les colonnes d’inégalité. Ensemble, elles doivent former la clé de l’index. Pour déterminer un ordre efficace pour les colonnes d'égalité, vous devez les organiser en fonction de leur sélectivité : répertoriez les colonnes les plus sélectives (les colonnes de gauche dans la liste des colonnes). Les colonnes uniques sont les plus sélectives, alors que les colonnes contenant de nombreuses valeurs répétitives le sont moins.
Les colonnes incluses doivent être ajoutées à l'instruction CREATE INDEX à l'aide de la clause INCLUDE. L’ordre des colonnes incluses n’affecte pas les performances des requêtes. Ainsi, quand plusieurs index sont combinés, les colonnes incluses peuvent être combinées dans n’importe quel ordre. Découvrez davantage d’informations dans les recommandations relatives aux colonnes incluses.
Par exemple, vous pouvez avoir une table Person.Address avec un index existant sur la colonne clé StateProvinceID. Vous pouvez éventuellement voir des recommandations d’index manquants pour la table Person.Address et les colonnes suivantes :
- Filtres EQUALITY pour
StateProvinceIDetCity - Filtres EQUALITY pour
StateProvinceIDetCity, INCLUDEPostalCode
Si vous modifiez l’index existant pour qu’il corresponde à la deuxième recommandation, un index ayant des clés sur StateProvinceID et City ainsi que PostalCode est probablement plus adapté aux requêtes qui ont généré les deux suggestions d’index.
Les compromis sont courants dans le paramétrage des index. Il est probable que pour de nombreux jeux de données, la colonne City soit plus sélective que la colonne StateProvinceID. Toutefois, si notre index existant sur StateProvinceID est fortement utilisé, et si les autres requêtes effectuent principalement des recherches à la fois sur StateProvinceID et City, la surcharge de traitement est généralement moins importante pour la base de données si elle a un seul index avec les deux colonnes dans la clé, StateProvinceID étant la colonne de début, bien qu’il ne s’agisse pas de la colonne la plus sélective.
Vous pouvez modifier les index de plusieurs façons :
- Vous pouvez utiliser l’instruction CREATE INDEX avec la clause DROP_EXISTING. Vous pouvez être amené à renommer les index à la suite de la modification pour que le nom décrive toujours avec justesse la définition de l’index, en fonction de votre convention de nommage.
- Vous pouvez utiliser l’instruction DROP INDEX (Transact-SQL) suivie d’une instruction CREATE INDEX.
L’ordre des clés d’index est important au moment de la combinaison des suggestions d’index : City en tant que colonne de début est différent de StateProvinceID en tant que colonne de début. Découvrez davantage d’informations dans les recommandations sur la conception d’index non-cluster.
Quand vous créez des index, utilisez les opérations d’index en ligne si elles sont disponibles.
Bien que les index puissent considérablement améliorer les performances des requêtes dans certains cas, ils entraînent également une surcharge de traitement et des coûts de gestion. Passez en revue les recommandations générales sur la conception d’index pour évaluer les avantages des index avant de les créer.
Vérifier la réussite des changements apportés aux index
Il est important de vérifier si les changements apportés aux index ont réussi : l’optimiseur de requête utilise-t-il vos index ?
Il existe plusieurs façons de vérifier les changements apportés aux index, notamment en utilisant le Magasin des requêtes pour identifier les requêtes où il manque des requêtes d’index. Notez le query_id des requêtes. Utilisez la vue Requêtes suivies dans le Magasin des requêtes pour vérifier si les plans d’exécution d’une requête ont changé, et si l’optimiseur utilise votre index nouveau ou modifié. Découvrez plus en détail les requêtes suivies dans la description de la résolution des problèmes de performances des requêtes.
Contenu connexe
Découvrez plus en détail le paramétrage des index et des performances dans les articles suivants :
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour