Incorporation des fonctions UDF scalaires
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x) ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Cet article présente l’incorporation (inlining) des fonctions UDF scalaires. Il s’agit d’une fonctionnalité qui est prise en charge dans la suite de fonctionnalités de traitement intelligent des requêtes. Cette fonctionnalité améliore les performances des requêtes qui appellent des fonctions scalaires définies par l’utilisateur dans SQL Server (à partir de SQL Server 2019 (15.x)).
Fonctions scalaires T-SQL définies par l’utilisateur
Les fonctions définies par l’utilisateur (UDF) qui sont implémentées dans Transact-SQL et qui retournent une valeur de données unique sont appelées fonctions UDF (définies par l’utilisateur) scalaires T-SQL. Les fonctions UDF T-SQL offrent une façon élégante de réutiliser le code et d’assurer la modularité entre les requêtes Transact-SQL. Certains calculs (tels que des règles métier complexes) sont plus faciles à exprimer sous forme de fonctions UDF impératives. Les fonctions UDF favorisent la création d’une logique complexe sans devoir savoir écrire des requêtes SQL complexes. Pour plus d’informations sur les fonctions UDF, consultez Créer des fonctions définies par l’utilisateur (moteur de base de données).
Performances des fonctions UDF scalaires
Les fonctions UDF scalaires présentent généralement des performances médiocres pour les raisons suivantes :
Appel itératif. les fonctions UDF sont appelées de façon itérative, une fois par tuple éligible. Cela implique des coûts supplémentaires de changements de contexte répétés en raison de l’appel de fonction. En particulier, les fonctions UDF qui exécutent des requêtes Transact-SQL dans leur définition sont gravement affectées.
Absence d’évaluation des coûts. pendant l’optimisation, seuls les opérateurs relationnels sont estimés, tandis que les opérateurs scalaires ne le sont pas. Avant l’introduction des fonctions UDF scalaires, les autres opérateurs scalaires étaient généralement peu coûteux et n’exigeaient pas une évaluation des coûts. L’ajout d’un coût processeur réduit pour une opération scalaire suffisait. Il existe des scénarios où le coût réel est important et reste pourtant sous-représenté.
Exécution interprétée. les fonctions UDF sont évaluées sous la forme d’un lot d’instructions, exécuté instruction par instruction. Chaque instruction proprement dite est compilée et le plan compilé est mis en cache. Cette stratégie de mise en cache permet d’économiser du temps, car elle évite les recompilations, mais chaque instruction s’exécute de manière isolée. Aucune optimisation entre les instructions n’est réalisée.
Exécution en série. SQL Server n’autorise pas le parallélisme intra-requête dans des requêtes qui appellent des fonctions UDF.
Incorporation automatique des fonctions UDF scalaires
L’objectif de la fonctionnalité d’incorporation des fonctions UDF scalaires consiste à améliorer les performances des requêtes qui appellent des fonctions UDF scalaires T-SQL, lorsque l’exécution des fonctions UDF constitue le principal goulot d’étranglement.
Avec cette nouvelle fonctionnalité, les fonctions UDF scalaires sont automatiquement transformées en expressions scalaires ou sous-requêtes scalaires qui sont substituées dans la requête d’appel à la place de l’opérateur UDF. Ces expressions et sous-requêtes sont ensuite optimisées. Par conséquent, le plan de requête n’a plus d’opérateur de fonction définie par l’utilisateur, mais ses effets sont observés dans le plan, tels que des vues ou des fonctions table (TVF) inline.
Exemple 1 - Fonction UDF scalaire à instruction unique
Regardez la requête qui suit.
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (L_EXTENDEDPRICE *(1 - L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE;
Cette requête calcule la somme des prix avec remise des articles et présente les résultats groupés par date d’expédition et priorité d’expédition. L’expression L_EXTENDEDPRICE *(1 - L_DISCOUNT) est la formule correspondant au prix avec remise d’un article donné. Il est possible d’extraire ces formules dans des fonctions afin d’assurer leur modularité et leur réutilisation.
CREATE FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2) AS
BEGIN
RETURN @price * (1 - @discount);
END
La requête peut alors être modifiée pour appeler cette fonction UDF.
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (dbo.discount_price(L_EXTENDEDPRICE, L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
Pour les raisons décrites précédemment, la requête avec la fonction UDF présente des performances médiocres. À présent, avec l’incorporation des fonctions UDF scalaires, l’expression scalaire figurant dans le corps de la fonction UDF est substituée directement dans la requête. Les résultats de l’exécution de la requête sont affichés dans le tableau ci-dessous :
| Requête : | Requête sans fonction UDF | Requête avec fonction UDF (sans incorporation) | Requête avec incorporation des fonctions UDF scalaires |
|---|---|---|---|
| Durée d’exécution : | 1,6 seconde | 29 minutes et 11 secondes | 1,6 seconde |
Ces nombres sont basés sur une base de données CCI de 10 Go (utilisant le schéma TPC-H) en cours d’exécution sur une machine à biprocesseur (12 cœurs) dotée de 96 Go de RAM et soutenue par un disque SSD. Ces nombres incluent la durée de compilation et d’exécution avec un pool de mémoires tampons et un cache de procédures à froid. La configuration par défaut a été utilisée et aucun autre index n’a été créé.
Exemple 2 - Fonction UDF scalaire à instructions multiples
Les fonctions UDF scalaires qui sont implémentées à l’aide de plusieurs instructions T-SQL, telles que les affectations de variables et le branchement conditionnel, peuvent également être incorporées. Considérez la fonction UDF scalaire suivante qui, à partir d’une clé client donnée, détermine la catégorie de service pour le client. Elle arrive à cette catégorie en calculant au départ le prix total de toutes les commandes passées par le client à l’aide d’une requête SQL. Ensuite, elle utilise une logique IF (...) ELSE pour décider de la catégorie en fonction du prix total.
CREATE OR ALTER FUNCTION dbo.customer_category(@ckey INT)
RETURNS CHAR(10) AS
BEGIN
DECLARE @total_price DECIMAL(18,2);
DECLARE @category CHAR(10);
SELECT @total_price = SUM(O_TOTALPRICE) FROM ORDERS WHERE O_CUSTKEY = @ckey;
IF @total_price < 500000
SET @category = 'REGULAR';
ELSE IF @total_price < 1000000
SET @category = 'GOLD';
ELSE
SET @category = 'PLATINUM';
RETURN @category;
END
À présent, considérez une requête qui appelle cette fonction UDF.
SELECT C_NAME, dbo.customer_category(C_CUSTKEY) FROM CUSTOMER;
Le plan d’exécution pour cette requête dans SQL Server 2017 (14.x) (niveau de compatibilité 140 ou antérieur) est le suivant :

Comme le montre le plan, SQL Server adopte une stratégie simple ici : appeler la fonction UDF et fournir les résultats pour chaque tuple figurant dans la table CUSTOMER. Cette stratégie est naïve et inefficace. Avec l’incorporation, ces fonctions UDF sont transformées en sous-requêtes scalaires équivalentes, qui sont substituées dans la requête d’appel à la place de la fonction UDF.
Pour la même requête, le plan avec la fonction UDF incorporée se présente comme suit.
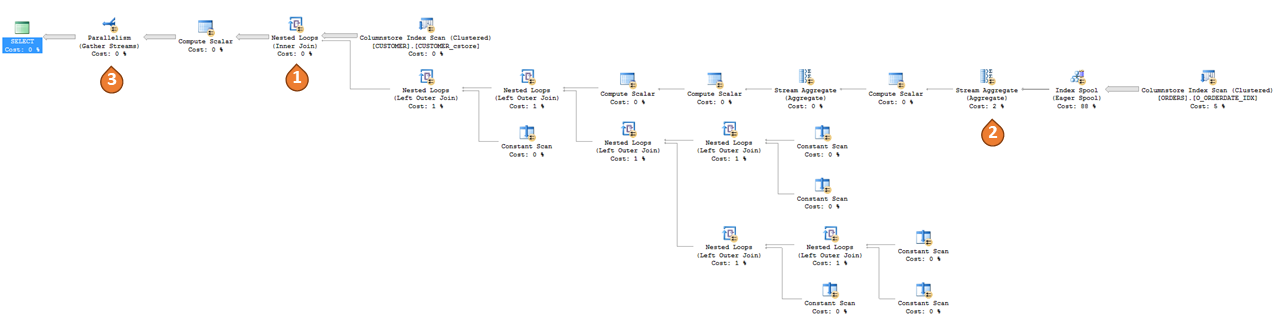
Comme mentionné précédemment, le plan de requête n’a plus d’opérateur de fonction définie par l’utilisateur, mais ses effets sont désormais observables dans le plan, tels que des vues ou des fonctions table (TVF) inline. Voici quelques observations clés tirées du plan ci-dessus :
- SQL Server a déduit la jointure implicite entre
CUSTOMERetORDERS, et l’a rendue explicite via un opérateur de jointure. - SQL Server a également déduit le
GROUP BY O_CUSTKEY on ORDERSimplicite et a utilisé IndexSpool + StreamAggregate pour l’implémenter. - SQL Server utilise désormais le parallélisme entre tous les opérateurs.
Selon la complexité de la logique dans la fonction UDF, le plan de requête obtenu peut également grandir et se complexifier. Comme nous pouvons le constater, les opérations effectuées au sein de la fonction UDF ne constituent plus une boîte noire ; par conséquent, l’optimiseur de requête est en mesure d’évaluer le coût de ces opérations et de les optimiser. En outre, comme la fonction UDF n’est plus dans le plan, l’appel itératif de la fonction UDF est remplacé par un plan qui permet d’éviter toute surcharge d’appel de fonction.
Exigences des fonctions UDF scalaires incorporables
Une fonction UDF T-SQL scalaire peut être inlined si toutes les conditions suivantes sont remplies :
- La fonction UDF est écrite à l’aide des constructions suivantes :
DECLARE,SET: Déclaration et affectations des variables.SELECT:requête SQL avec une ou plusieurs affectations de variables 1.IF/ELSE: Création de branches avec des niveaux d’imbrication arbitraires.RETURN: Une ou plusieurs instructions return. À compter de SQL Server 2019 (15.x) CU5, la fonction UDF ne peut contenir qu’une seule instruction RETURN afin d’être prise en compte pour l’incorporation 6.UDF:appels de fonction imbriqués/récursifs 2.- Autres : Opérations relationnelles telles que
EXISTS,IS NULL.
- La fonction UDF n’appelle pas de fonction intrinsèque dépendante du temps (telle que
GETDATE()) ou ayant des effets secondaires 3 (telle queNEWSEQUENTIALID()). - La fonction UDF utilise la clause
EXECUTE AS CALLER(comportement par défaut si la clauseEXECUTE ASn’est pas spécifiée). - La fonction UDF ne référence pas de variables de table ni de paramètres table.
- La requête qui appelle une fonction UDF scalaire ne référence pas un appel de fonction UDF scalaire dans sa clause
GROUP BY. - La requête qui appelle une fonction UDF scalaire dans sa liste de sélection avec la clause
DISTINCTn’a pas de clauseORDER BY. - La fonction UDF n’est pas utilisée dans la clause
ORDER BY. - La fonction UDF n’est pas compilée en mode natif (l’interopérabilité est prise en charge).
- La fonction UDF n’est pas utilisée dans une colonne calculée ni une définition de contrainte de vérification.
- La fonction UDF ne référence pas de types définis par l’utilisateur.
- Aucune signature n’est ajoutée à la fonction UDF.
- La fonction UDF n’est pas une fonction de partition.
- La fonction UDF ne contient aucune référence à des expressions de table commune (CTE).
- Quand elle est inlined, la fonction UDF ne contient pas de références à des fonctions intrinsèques qui peuvent modifier les résultats (comme
@@ROWCOUNT) 4. - La fonction UDF ne contient pas de fonctions d’agrégation transmises comme paramètres à une fonction UDF scalaire 4.
- La fonction UDF ne référence pas de vues intégrées (comme
OBJECT_ID) 4. - La fonction UDF ne référence pas de méthodes XML 5.
- La fonction UDF ne contient pas de SELECT avec
ORDER BYsans clauseTOP 15. - La fonction UDF ne contient pas de requête SELECT qui effectue une assignation avec la clause
ORDER BY(par exemple,SELECT @x = @x + 1 FROM table1 ORDER BY col1) 5. - La fonction UDF ne contient pas plusieurs instructions RETURN 6.
- La fonction UDF n’est pas appelée à partir d’une instruction RETURN 6.
- La fonction UDF ne référence pas la fonction
STRING_AGG6. - La fonction UDF ne référence pas les tables distantes 7.
- La requête d’appel à UDF n’utilise pas
GROUPING SETS,CUBEniROLLUP7. - La requête d’appel à UDF ne contient pas de variable utilisée comme paramètre UDF pour l’affectation (par exemple,
SELECT @y = 2,@x = UDF(@y)) 7. - La fonction UDF ne fait pas référence à des colonnes chiffrées 8.
- La fonction UDF ne contient pas de références pour
WITH XMLNAMESPACES8. - La requête appelant la fonction UDF ne comporte pas d’expressions de table communes (CTE) 8.
1 SELECT avec une accumulation/agrégation de variable n’est pas pris en charge pour l’incorporation (par exemple, SELECT @val += col1 FROM table1).
2 Les fonctions UDF récursives sont incorporées seulement jusqu’à une certaine profondeur.
3 Les fonctions intrinsèques dont les résultats dépendent de l’heure système actuelle sont dépendantes de l’heure. Une fonction intrinsèque qui peut mettre à jour un état global interne est un exemple de fonction avec effets secondaires. Ces fonctions retournent des résultats différents chaque fois qu’elles sont appelées, selon l’état interne.
4 Restriction ajoutée dans SQL Server 2019 (15.x) CU2
5 Restriction ajoutée dans SQL Server 2019 (15.x) CU4
6 Restriction ajoutée dans SQL Server 2019 (15.x) CU5
7 Restriction ajoutée dans SQL Server 2019 (15.x) CU6
8 Restriction ajoutée dans SQL Server 2019 (15.x) CU11
Pour plus d’informations sur les derniers correctifs d’incorporation des fonctions UDF scalaires T-SQL et les dernières modifications apportées aux scénarios d’éligibilité d’incorporation, consultez l’article de la base de connaissances : CORRECTIF : problèmes d'Incorporation des fonctions UDF scalaires dans SQL Server 2019.
Vérifier le fait qu’une fonction UDF peut être ou non incorporée
Pour chaque fonction UDF scalaire T-SQL, la vue de catalogue sys.sql_modules inclut une propriété appelée is_inlineable, qui indique si une fonction UDF est incorporable ou non.
La propriété is_inlineable est dérivée des constructions trouvées dans la définition UDF. Elle ne vérifie pas si la fonction définie par l’utilisateur est incorporable au moment de la compilation. Pour plus d’informations, consultez les conditions d’incorporation.
La valeur 1 indique qu’elle est incorporable, et 0 indique le contraire. Cette propriété a également la valeur 1 pour toutes les fonctions table inline. Pour tous les autres modules, la valeur est 0.
Si une fonction UDF scalaire est incorporable, cela n’implique pas qu’elle sera toujours incorporée. SQL Server décide (pour chaque requête et chaque fonction UDF) s’il convient d’incorporer une fonction UDF ou non. Voici quelques exemples de cas où une fonction UDF peut ne pas être incorporée :
Si la définition de la fonction UDF s’exécute dans des milliers de lignes de code, SQL Server peut choisir de ne pas l’incorporer.
Un appel de fonction UDF compris dans une clause
GROUP BYne sera pas incorporé. Cette décision est prise lorsque la requête qui référence une fonction UDF scalaire est compilée.Si la fonction UDF est signée avec un certificat. Étant donné que les signatures peuvent être ajoutées et supprimées après la création d’une fonction UDF, le choix de l’incorporation se fait lorsque la requête qui référence une fonction UDF est compilée. Par exemple, les fonctions système sont généralement signées avec un certificat. Vous pouvez utiliser sys.crypt_properties pour rechercher les objets signés.
SELECT * FROM sys.crypt_properties AS cp INNER JOIN sys.objects AS o ON cp.major_id = o.object_id;
Vérifier si l’incorporation a eu lieu ou non
Si toutes les conditions préalables sont remplies et que SQL Server décide d’effectuer l’incorporation, il transforme la fonction UDF en une expression relationnelle. À partir du plan de requête, il est facile de déterminer si l’incorporation a eu lieu ou non :
- Le fichier xml du plan n’aura pas de nœud xml
<UserDefinedFunction>pour une fonction UDF qui a été incorporée correctement. - Certains événements XEvents sont émis.
Activer l’incorporation des fonctions UDF scalaires
Vous pouvez rendre les charges de travail automatiquement éligibles à l’incorporation des fonctions UDF scalaires en activant le niveau de compatibilité 150 pour la base de données. Vous pouvez définir cette option à l’aide de Transact-SQL. Par exemple :
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
En outre, aucune autre modification des requêtes ou des fonctions UDF n’est requise pour tirer parti de cette fonctionnalité.
Désactiver l’incorporation des fonctions UDF scalaires sans modifier le niveau de compatibilité
L’incorporation des fonctions UDF scalaires peut être désactivée au niveau de la portée de la base de données, de l’instruction ou de la fonction UDF, tout en conservant le niveau de compatibilité de la base de données 150 ou supérieur. Pour désactiver l’incorporation des fonctions UDF scalaires au niveau de la portée de la base de données, exécutez l’instruction suivante dans le contexte de la base de données applicable :
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Pour réactiver l’incorporation des fonctions UDF scalaires pour la base de données, exécutez l’instruction suivante dans le contexte de la base de données applicable :
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON;
Lorsque l'option est activée (ON), ce paramètre apparaît activé dans sys.database_scoped_configurations.
Vous pouvez également désactiver l’incorporation des fonctions UDF scalaires pour une requête spécifique en désignant DISABLE_TSQL_SCALAR_UDF_INLINING comme indicateur de requête USE HINT.
Un indicateur de requête USE HINT est prioritaire par rapport à la configuration étendue à la base de données et par rapport à un paramètre de niveau de compatibilité.
Par exemple :
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (dbo.discount_price(L_EXTENDEDPRICE, L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
L’incorporation des fonctions UDF scalaires peut également être désactivée pour une fonction UDF spécifique à l’aide de la clause INLINE dans l’instruction CREATE FUNCTION ou ALTER FUNCTION.
Par exemple :
CREATE OR ALTER FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2)
WITH INLINE = OFF
AS
BEGIN
RETURN @price * (1 - @discount);
END;
Une fois l’instruction ci-dessus exécutée, cette fonction UDF ne sera jamais incorporée dans aucune requête qui l’appelle. Pour réactiver l’incorporation pour cette fonction UDF, exécutez l’instruction suivante :
CREATE OR ALTER FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2)
WITH INLINE = ON
AS
BEGIN
RETURN @price * (1 - @discount);
END
La clause INLINE n’est pas obligatoire. Si la clause INLINE n’est pas spécifiée, elle est automatiquement définie sur ON/OFF selon que la fonction UDF peut ou non être incorporée. Si INLINE = ON est spécifié mais que la fonction UDF s’avère inéligible pour l’incorporation, une erreur est levée.
Remarques importantes
Comme cela est décrit dans cet article, l’incorporation des fonctions UDF scalaires transforme une requête avec des fonctions UDF scalaires en une requête avec une sous-requête scalaire équivalente. En raison de cette transformation, les utilisateurs peuvent remarquer des différences de comportement dans les scénarios suivants :
L’incorporation génère un hachage de requête différent pour le même texte de requête.
Certains avertissements dans les instructions figurant dans la fonction UDF (tels qu’une division par zéro, etc.), qui peuvent avoir été cachés précédemment, peuvent apparaître en raison de l’incorporation.
Les indicateurs de jointure au niveau des requêtes ne sont peut-être plus valides, car l’incorporation peut introduire de nouvelles jointures. Les indicateurs de jointure locaux doivent être utilisés à la place.
Les vues qui référencent des fonctions UDF scalaires inline ne peuvent pas être indexées. Si vous avez besoin de créer un index sur ces vues, désactivez l’incorporation pour les fonctions UDF référencées.
Il peut y avoir des différences de comportement de Dynamic Data Masking avec l’incorporation des données UDF.
Dans certaines situations (selon la logique utilisée dans la fonction UDF), l’incorporation peut être plus conservatrice que le masquage des colonnes de sortie. Dans les scénarios où les colonnes référencées dans une fonction UDF ne sont pas les colonnes de sortie, elles ne sont pas masquées.
Si une fonction UDF référence des fonctions intégrées telles que
SCOPE_IDENTITY(),@@ROWCOUNTou@@ERROR, la valeur retournée par la fonction intégrée change avec l’incorporation. Ce changement de comportement est dû au fait que l’incorporation modifie l’étendue des instructions au sein de la fonction UDF. À partir de SQL Server 2019 (15.x) CU2, l’incorporation est bloquée si la fonction UDF référence certaines fonctions intrinsèques (par exemple@@ROWCOUNT).Si une variable est assignée avec le résultat d’une fonction définie par l’opération (UDF) inlined et qu’elle est également utilisée comme index_column_name dans l’indicateur de requête FORCESEEK, le message d’erreur 8622 indique que le processeur de requêtes ne peut pas créer de plan de requête en raison des indicateurs définis dans la requête.
Voir aussi
- Créer des fonctions définies par l’utilisateur (moteur de base de données)
- Centre de performances pour le moteur de base de données SQL Server et Azure SQL Database
- Guide d’architecture de traitement des requêtes
- Guide de référence des opérateurs Showplan logiques et physiques
- Joins
- Illustration du traitement de requêtes intelligent
- CORRECTIF : Problèmes d’incorporation de la fonction FDU scalaire dans SQL Server 2019
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour