Fonctionnement de MLOps pour IoT Edge
En adoptant MLOps, le scientifique des données peut utiliser les capacités suivantes du monde DevOps :
- Contrôle de code source
- Pipelines d’entraînement reproductibles
- Contrôle de version et stockage de modèle
- Empaquetage de modèle
- Validation et déploiement du modèle
- Surveillances des modèles en production
- Réentraînement des modèles
Ces pratiques sont disponibles individuellement, mais MLOps les intègre de manière fluide pour permettre aux scientifiques des données, développeurs et ingénieurs ML de collaborer efficacement.
Le rôle de chaque composant est décrit dans cette unité :
Contrôle de code source : vous permet de collaborer avec d’autres scientifiques des données et développeurs. Tous les artefacts utilisés pour générer des modèles ML (notamment le code d’entraînement et les données d’entrée) sont capturés par le biais du contrôle de code source. Souvent, les modèles doivent être réentraînés et redéployés. La capture de tous les artefacts dans un système de contrôle de code source garantit la reproductibilité et la traçabilité.
Pipeline d’entraînement reproductible : vous permet de simplifier le développement de modèles en automatisant les tâches répétitives. En automatisant le pipeline d’entraînement, vous augmentez la vitesse à laquelle les nouveaux modèles sont générés.
Stockage de modèles et gestion de versions : facilitent la découverte, le partage et la collaboration. Vous pouvez également auditer des artefacts individuels et gérer leur accès.
Empaquetage de modèles : implique la capture des dépendances nécessaires à l’exécution d’un modèle dans son environnement d’inférence cible. L’empaquetage de modèles est implémentée au moyen de conteneurs. Les conteneurs s’étendent à la fois au cloud et à la périphérie intelligente. Vous pouvez implémenter vos modèles à l’aide de formats réutilisables tels que ONNX (Open Neural Network Exchange).
Validation de modèles : vous pouvez valider votre modèle de plusieurs façons, notamment avec des tests unitaires de base pour le code d’entraînement, une comparaison A/B avec une version précédente d’un modèle ou encore une suite de tests fonctionnels et de performances de bout en bout.
Déploiement : vous permet de déployer de nouveaux modèles sur différents types de plateformes, notamment IoT Edge. Vous devez pour cela comprendre et utiliser les caractéristiques uniques de la plateforme cible.
Supervision : vous permet de superviser vos modèles dans un environnement de production. Vous pouvez comprendre et améliorer les performances de vos modèles. Vous pouvez également superviser la dérive de données entre votre jeu de données d’entraînement et les données d’inférence pour savoir quand réentraîner votre modèle.
Réentraînement : en fonction des critères de supervision, vous devez pouvoir réentraîner vos modèles.
Considérations relatives à IoT : en plus de ce qui précède, des considérations spéciales entourent le déploiement sur IoT. Pour MLOps, IoT Edge est une plateforme de déploiement parmi d’autres. Toutefois, si vous déployez des modèles sur IoT Edge, vous devez tenir compte de certaines considérations supplémentaires. Les modèles MLOps, qui ciblent IoT Edge, doivent pouvoir s’exécuter hors connexion. Les modèles IoT sont plus vulnérables à la dérive de données en raison du taux élevé de données. Les modèles Machine Learning IoT doivent être déployés sur diverses plateformes cibles, ce qui vous oblige à appliquer les capacités de ces plateformes.
D’autres capacités de MLOps sont également applicables à l’environnement IoT Edge, comme le profilage, l’optimisation de modèles et le déploiement de modèles en tant que conteneurs. Quand vous utilisez un modèle en tant que service web ou appareil IoT Edge, vous devez fournir les éléments suivants :
- Les modèles réels en cours de déploiement.
- Un script d’entrée qui accepte la demande, utilise le ou les modèles pour attribuer un score aux données, puis retourne une réponse.
- Un environnement Azure Machine Learning qui décrit les dépendances pip et Conda requises par le ou les modèles.
- Script d’entrée et toutes les ressources supplémentaires comme le texte, les données, etc. nécessaires pour les modèles et le script d’entrée.
Vous devez également fournir la configuration de la plateforme de déploiement cible. Quand l’image est créée, les composants requis par Azure Machine Learning sont également ajoutés. Citons par exemple les ressources nécessaires pour exécuter le service web et interagir avec IoT Edge.
Revisiter le scénario
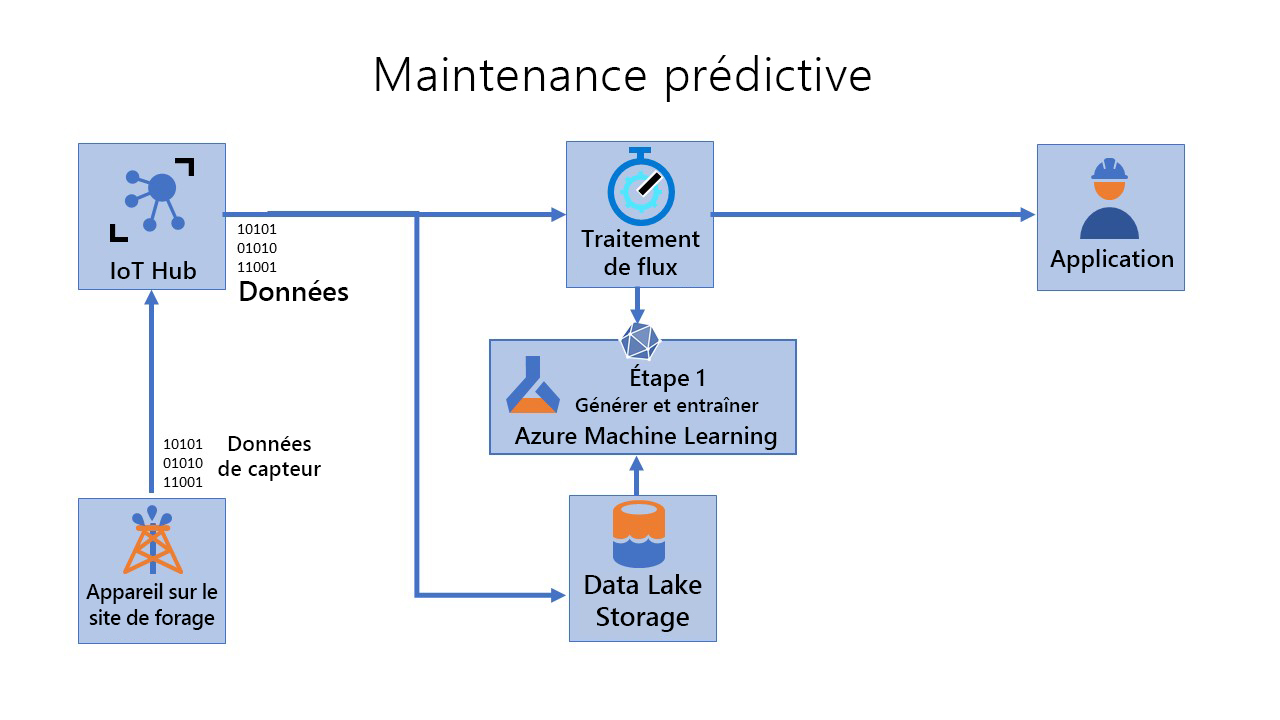
Revenons à présent à notre scénario précédent dans l’industrie pétrolière et gazière. Pour rappel, vous êtes responsable de la maintenance de milliers de pompes en activité dans des sites distants/offshore. Votre équipe doit rapidement identifier les pannes et les réparer sur le terrain. Vous souhaitez créer et déployer un système de maintenance prédictive pour les pompes en utilisant les données des capteurs pour créer des modèles Machine Learning à jour. Les modèles doivent refléter l’état actuel des données. Autrement dit, le modèle ne doit pas être obsolète compte tenu de la dérive de données. Enfin, étant donné que vous utilisez un scénario IoT Edge, les modèles doivent pouvoir s’exécuter sur des appareils périphériques (au besoin en mode hors connexion).
Pour traiter ce scénario avec MLOps pour des appareils périphériques, vous pouvez envisager trois pipelines.
Générer et entraîner (étape 1)
Empaqueter et déployer (étape 2)
Superviser et réentraîner (étape 3)
Étape 1 - Générer et entraîner : Au cours de cette étape, vous créez des modèles reproductibles et des pipelines d’entraînement réutilisables. Le pipeline CI est déclenché chaque fois que du code est archivé. Il publie un pipeline Azure Machine Learning mis à jour après la génération du code et l’exécution d’une suite de tests. Le pipeline de build comprend de nombreux tests unitaires et tests de qualité du code.
Étape 2 - Empaqueter et déployer : Au cours de cette étape, vous empaquetez, validez et déployez des modèles. Dans ce pipeline, vous opérationnalisez l’image de scoring et la promouvez de manière sécurisée dans différents environnements. Le pipeline est déclenché chaque fois qu’un nouvel artefact est disponible. Le modèle inscrit est empaqueté avec un script de scoring et les dépendances Python (fichier YAML Conda) dans une image Docker d’opérationnalisation. La version de l’image est automatiquement gérée par Azure Container Registry. L’image de scoring est déployée sur des instances de conteneur où elle peut être testée. En cas de réussite, l’image de scoring est déployée en tant que service web dans l’environnement de production.

Étape 3 : Superviser et réentraîner : expliquez et observez le comportement du modèle, puis automatisez le processus de réentraînement. Le pipeline Machine Learning orchestre le processus de réentraînement du modèle de manière asynchrone. Le réentraînement peut être déclenché selon une planification ou lorsque de nouvelles données sont disponibles en appelant le point de terminaison REST du pipeline publié à l’étape précédente. Au cours de cette étape, vous réentraînez, évaluez et inscrivez le modèle.
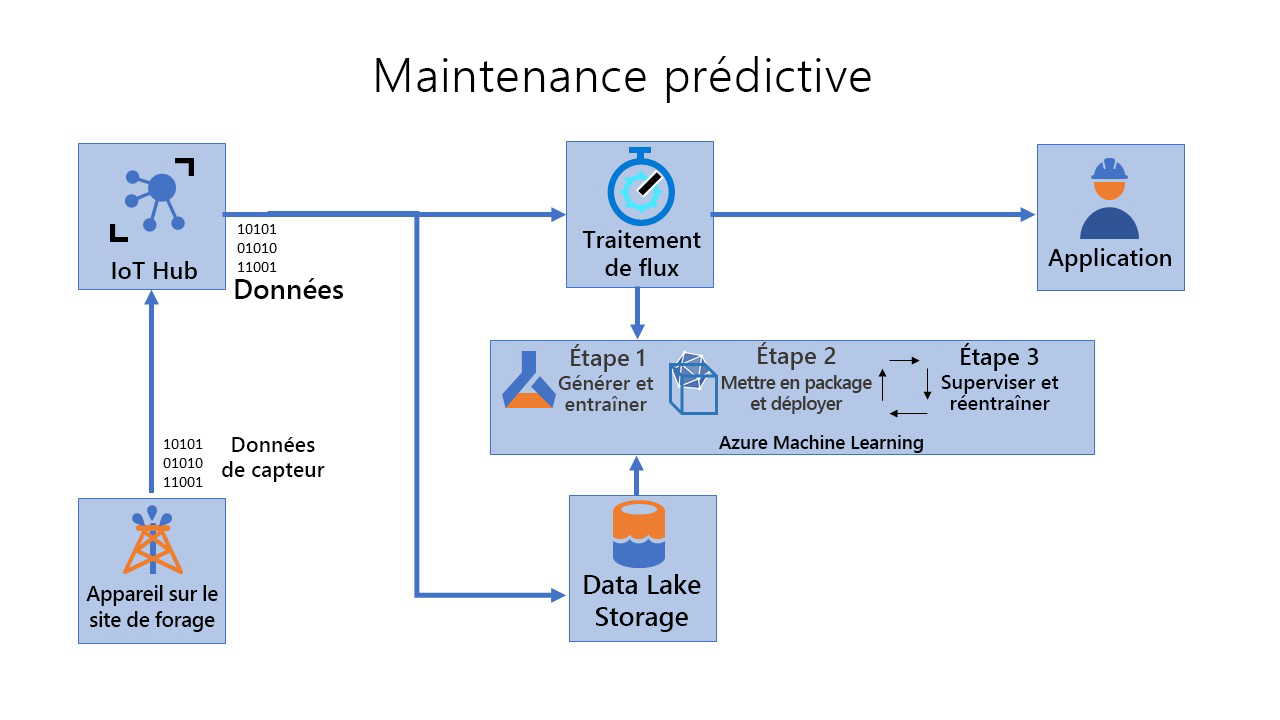
Le flux global est visible ici :
 .
.