Partitionnement personnalisé de sortie BLOB dans Azure Stream Analytics
Azure Stream Analytics prend en charge le partitionnement personnalisé de sortie blob avec des champs ou attributs personnalisés et des modèles de chemin DateTime personnalisés.
Champs ou attributs personnalisé
Des champs ou attributs d’entrée personnalisés améliorent en aval le traitement de données et les flux de travail de génération de rapports en permettant de mieux contrôler la sortie.
Options de clé de partition
La clé de partition, ou nom de colonne, utilisée pour partitionner les données d’entrée peut contenir n’importe quel caractère accepté pour les noms blob. Il n’est pas possible d’utiliser des champs imbriqués en tant que clé de partition, sauf s’ils sont utilisés avec des alias. Toutefois, vous pouvez utiliser certains caractères pour créer une hiérarchie de fichiers. Par exemple, pour créer une colonne qui combine des données de deux autres colonnes afin de créer une clé de partition unique, vous pouvez utiliser la requête suivante :
SELECT name, id, CONCAT(name, "/", id) AS nameid
La clé de partition doit être NVARCHAR(MAX), BIGINT, FLOAT ou BIT (niveau de compatibilité 1.2 ou supérieur). Les types DateTime, Array et Records ne sont pas pris en charge, mais ils peuvent être utilisés en tant que clés de partition s’ils sont convertis en chaînes. Pour plus d’informations, consultez Types de données Azure Stream Analytics.
Exemple
Supposons qu’un travail prenne des données d’entrée de sessions utilisateur actives connectées à un service externe de jeu vidéo où les données ingérées contient une colonne client_id pour identifier les sessions. Pour partitionner les données par client_id, définissez le champ de blob Modèle de chemin d’accès de façon à inclure un jeton de partition {client_id} dans les propriétés de sortie blob lorsque vous créez un travail. Les données avec différentes valeurs client_id transitant par le travail Stream Analytics, les données de sortie sont enregistrées dans des dossiers distincts sur la base d’une seule valeur client_id par dossier.

De même, si l’entrée du travail était constituée de données provenant de millions de capteurs où chaque capteur avait un sensor_id, le modèle de chemin d’accès serait {sensor_id} pour partitionner les données de chaque capteur dans des dossiers distincts.
Quand vous utilisez l’API REST, la section de sortie d’un fichier JSON utilisé pour cette requête peut ressembler à l’image suivante :

Une fois que l’exécution du travail commence, le conteneur clients peut ressembler à l’image suivante :
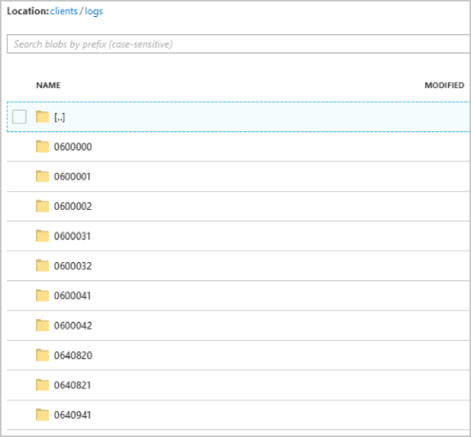
Chaque dossier peut contenir plusieurs objets blob contenant chacun un ou plusieurs enregistrements. Dans l’exemple précédent, il y a un seul blob dans un dossier étiqueté "06000000" avec le contenu suivant :
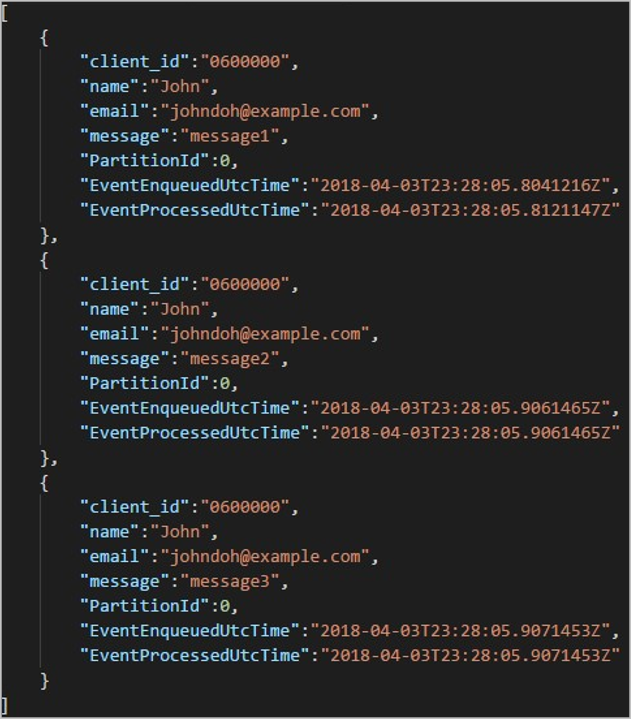
Notez que chaque enregistrement dans le blob comporte une colonne client_id correspondant au nom de dossier parce que la colonne utilisée pour partitionner la sortie dans le chemin d’accès de sortie était client_id.
Limites
Une seule clé de partition personnalisée est autorisée dans la propriété de sortie de blob du modèle de chemin d’accès. Tous les modèles de chemin d’accès suivants sont valides :
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Si les clients souhaitent utiliser plusieurs champs d’entrée, ils peuvent créer une clé composite dans la requête pour une partition de chemin personnalisée dans la sortie de blob à l’aide de
CONCAT. par exempleselect concat (col1, col2) as compositeColumn into blobOutput from input. Ils peuvent ensuite spécifiercompositeColumncomme chemin d’accès personnalisé dans le Stockage Blob Azure.Les clés de partition ignorant la casse, les clés de partition telles que
Johnetjohnsont équivalentes. En outre, des expressions ne peuvent pas être utilisées comme clés de partition. Par exemple,{columnA + columnB}ne fonctionne pas.Quand un flux d’entrée est constitué d’enregistrements avec une cardinalité de clé de partition inférieure à 8 000, les enregistrements sont ajoutés à des objets blob existants. Ils ne créent de nouveaux objets blob que lorsque cela est nécessaire. Si la cardinalité est supérieure à 8 000, rien ne garantie que les objets blob existants seront écrits. Les nouveaux objets blob ne seront pas créés pour un nombre arbitraire d’enregistrements avec la même clé de partition.
Si la sortie d’objet blob est configurée comme immuable, Stream Analytics crée un objet blob lors de chaque envoi de données.
Modèles de chemin DateTime personnalisés
Avec les modèles de chemin d’accès DateTime personnalisés, vous pouvez spécifier un format de sortie conforme aux conventions Hive Streaming, ce qui permet à Stream Analytics d’envoyer des données à Azure HDInsight et à Azure Databricks pour un traitement en aval. Les modèles de chemin d’accès DateTime personnalisés s’implémentent facilement en ajoutant le mot clé datetime dans le champ Préfixe de chemin d’accès de votre sortie blob, ainsi que le spécificateur de format. par exemple {datetime:yyyy}.
Jetons pris en charge
Les jetons de spécificateur de format suivants peuvent être utilisés individuellement ou en combinaison pour créer des formats DateTime personnalisés.
| Spécificateur de format | Description | Résultats pour l’exemple date/heure 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Année sous la forme d’un nombre à quatre chiffres | 2018 |
| {datetime:MM} | Mois de 01 à 12 | 01 |
| {datetime:M} | Mois de 1 à 12 | 1 |
| {datetime:dd} | Jour de 01 à 31 | 02 |
| {datetime:d} | Jour de 1 à 31 | 2 |
| {datetime:HH} | Heure au format 24 heures, de 00 à 23 | 10 |
| {datetime:mm} | Minutes de 00 à 60 | 06 |
| {datetime:m} | Minutes de 0 à 60 | 6 |
| {datetime:ss} | Secondes de 00 à 60 | 08 |
Si vous ne souhaitez pas utiliser des modèles DateTime personnalisés, vous pouvez ajouter le jeton {date} et/ou {time} au champ Préfixe de chemin d’accès afin d’obtenir une liste déroulante contenant les formats DateTime prédéfinis.

Extensibilité et restrictions
Vous pouvez utiliser autant de jetons ({datetime:<specifier>}) que vous le souhaitez dans le modèle de chemin d’accès, sans toutefois dépasser la limite de caractères du préfixe de chemin. Vous ne pouvez pas créer d’autres combinaisons de spécificateurs de format dans un jeton que celles déjà définies dans les listes déroulantes de date et d’heure.
Exemple de partition de chemin de logs/MM/dd :
| Expression valide | Expression non valide |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Vous pouvez utiliser le même spécificateur de format plusieurs fois dans le préfixe du chemin d’accès. Le jeton doit alors être répété à chaque occurrence.
Conventions Hive Streaming
Les modèles de chemin d’accès personnalisés pour le Stockage Blob peuvent respecter la convention Hive Streaming, selon laquelle les noms de dossier doivent contenir l’étiquette column=.
par exemple year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Une sortie personnalisée vous évite d’avoir à modifier les tables et à ajouter manuellement des partitions aux données de port entre Stream Analytics et Hive. À la place, un grand nombre de dossiers peuvent être ajoutés automatiquement à l’aide de la commande suivante :
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Exemple
Créez un compte de stockage, un groupe de ressources, un travail Stream Analytics et une source d’entrée conformément au démarrage rapide du Portail Azure de Stream Analytics. Utilisez les mêmes exemples de données que dans le démarrage rapide. Des exemples de données sont également disponibles dans GitHub.
Créez un récepteur de sortie Blob avec la configuration suivante :
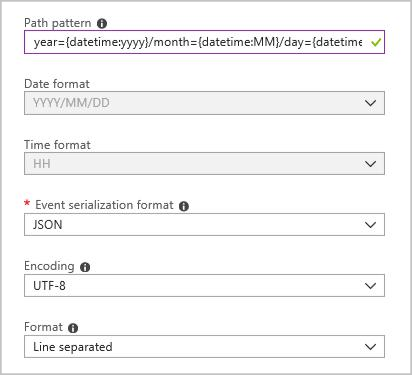
Le modèle de chemin d’accès complet est :
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Quand vous démarrez le travail, une structure de dossiers basée sur le modèle de chemin est automatiquement créée dans votre conteneur d’objets blob. Vous pouvez descendre dans la hiérarchie jusqu’au jour souhaité.
