Guide pratique pour améliorer votre modèle Custom Vision
Dans ce guide, vous découvrez comment améliorer la qualité de votre modèle Custom Vision. La qualité de votre classifieur ou détecteur d’objet dépend de la quantité, de la qualité et de la variété des données étiquetées que vous fournissez ainsi que de l’équilibre de l’ensemble du jeu de données. Un bon modèle comporte un jeu de données d’entraînement équilibré, qui est représentatif de ce qui lui sera soumis. Le processus de création d’un tel modèle est itératif ; il est courant d’effectuer plusieurs cycles d’entraînement pour atteindre les résultats attendus.
Voici un modèle général pour vous aider à entraîner un modèle plus précis :
- Effectuer le premier cycle d’apprentissage.
- Ajouter d’autres images et équilibrer les données ; réentraîner
- Ajouter des images avec différents arrière-plans, éclairages, tailles d’objet, angles de vue et styles ; réentraîner
- Utiliser de nouvelles images pour tester la prédiction
- Modifier les données d’entraînement existantes en fonction des résultats de la prédiction
Empêcher le surajustement
Parfois, un modèle apprend à faire des prédictions en fonction de caractéristiques arbitraires que vos images ont en commun. Par exemple, si vous créez un classifieur pommes/agrumes et que vous avez utilisé des images de pommes tenues dans des mains et des images d’agrumes posés dans des assiettes blanches, le classifieur risque de donner une trop grande importance à la distinction mains/assiettes, plutôt qu’à la distinction pommes/agrumes.
Pour corriger ce problème, fournissez des images avec différents angles, arrière-plans, tailles d’objet, groupes et autres variations. Les sections suivantes développent ces concepts.
Quantité de données
Le nombre d’images d’entraînement est le facteur le plus important pour votre jeu de données. Nous recommandons d’utiliser au moins 50 images par étiquette pour commencer. Avec moins d’images, il existe un risque plus élevé de surajustement. Et même si vos chiffres de performance suggèrent une bonne qualité, votre modèle aura peut-être du mal avec des données réelles.
Équilibre des données
Il est également essentiel de prendre en compte les quantités relatives de vos données d’entraînement. Par exemple, l’utilisation de 500 images pour une seule étiquette et de 50 images pour une autre déséquilibre le jeu de données d’entraînement. Le modèle sera donc plus précis pour prédire une étiquette plutôt qu’une autre. Les résultats seront très certainement meilleurs avec un ratio d’au moins 1:2 entre l’étiquette la moins bien dotée et l’étiquette la plus foisonnante. Si, par exemple, l’étiquette la plus fournie comporte 500 images, la moins fournie doit inclure au moins 250 images pour l’entraînement.
Variété des données
Veillez à utiliser des images représentatives de ce qui va être soumis au classifieur en utilisation normale. Sinon, votre modèle risque d’apprendre à faire des prédictions en fonction de caractéristiques arbitraires que vos images ont en commun. Par exemple, si vous créez un classifieur pommes/agrumes et que vous avez utilisé des images de pommes tenues dans des mains et des images d’agrumes posés dans des assiettes blanches, le classifieur risque de donner une trop grande importance à la distinction mains/assiettes, plutôt qu’à la distinction pommes/agrumes.

Pour corriger ce problème, incluez des images très diverses afin d’avoir la certitude que votre modèle effectue correctement la généralisation. Voici quelques moyens de rendre un jeu d’apprentissage plus varié :
Contexte : Fournissez des images de votre objet devant différents arrière-plans. Les photos prises dans des contextes naturels sont plus performantes que celles dont l’arrière-plan est neutre, car elles apportent davantage d’informations au classifieur.

Éclairage : Fournissez des images présentant des éclairages variés (autrement dit, prises avec flash, avec exposition élevée, etc.), en particulier si les images utilisées pour la prédiction sont diversifiées de ce point de vue. Il est également conseillé d’utiliser des images dont la saturation, la teinte et la luminosité varient.

Taille de l'objet : Fournissez des images dans lesquelles les objets varient en taille et en nombre (par exemple, une photo de régime de bananes et un gros plan sur une banane isolée). Les différences de taille permettent au classifieur de mieux généraliser.

Angle de vue : fournissez des images prises avec différents angles de vue. Par ailleurs, si toutes vos photos doivent être prises par des caméras fixes (par exemple, des caméras de surveillance), veillez à attribuer une étiquette différente à chaque objet revenant régulièrement pour éviter tout surajustement (interprétation des objets non connexes, par exemple des lampadaires, comme étant la principale caractéristique).

Style : Fournissez des images de styles différents de la même classe (par exemple, des variétés différentes du même fruit). En revanche, si vous avez des objets de styles radicalement différents (par exemple, Mickey Mouse et une vraie souris), nous vous recommandons de les étiqueter comme des classes distinctes afin de mieux représenter leurs caractéristiques distinctes.

Images négatives (classifieurs uniquement)
Si vous utilisez un classifieur d’images, vous devrez peut-être ajouter des échantillons négatifs pour rendre votre classifieur plus précis. Les échantillons négatifs sont des images qui ne correspondent à aucune des autres étiquettes. Quand vous chargez ces images, appliquez l’étiquette spéciale Negative (Négatif) à celles-ci.
Les détecteurs d’objets prennent en charge automatiquement les échantillons négatifs, car les zones d’image en dehors des cadres englobants dessinés sont considérées comme négatives.
Notes
Le service Custom Vision prend en charge un traitement automatique des images négatives. Par exemple, si vous générez un classifieur raisins/bananes et que vous soumettez une image de chaussure à la prédiction, il devra lui donner un score proche de 0 % aussi bien pour les raisins que pour les bananes.
À l’inverse, dans les cas où les images négatives représentent simplement une variante des images utilisées pour l’apprentissage, il est probable que le modèle les catégorise comme une classe étiquetée en raison des grandes similitudes qu’elles présentent. Par exemple, si vous avez un classifieur oranges/pamplemousses et que vous fournissez une image de clémentine, il est possible qu’il l’évalue comme étant une orange car la clémentine présente des caractéristiques similaires à l'orange. Si vos images négatives sont de cette nature, nous vous conseillons de créer une ou plusieurs balises supplémentaires (comme Autre) et d’étiqueter ainsi les images négatives pendant l’apprentissage pour permettre au modèle de mieux faire la distinction entre ces classes.
Occlusion et la troncation (détecteurs d’objets uniquement)
Si vous souhaitez que votre détecteur d’objets détecte les objets tronqués (objets partiellement coupés dans l’image) ou les objets occlus (objets partiellement occultés par d’autres objets dans l’image), vous devez inclure des images d’entraînement qui couvrent ces cas de figure.
Notes
Ne confondez pas le problème des objets occultés par d’autres objets avec le seuil de chevauchement, un paramètre qui permet d’évaluer les performances du modèle. Le curseur du seuil de chevauchement sur le site web Custom Vision indique dans quelle mesure un cadre englobant prédit doit chevaucher le véritable cadre englobant pour être considéré comme correct.
Utiliser des images de prédiction à des fins de réentraînement
Quand vous utilisez ou testez le modèle en soumettant des images au point de terminaison de prédiction, le service Custom Vision stocke ces images. Vous pouvez alors les utiliser pour améliorer le modèle.
Pour voir les images soumises au modèle, ouvrez la page web Custom Vision, accédez à votre projet, puis sélectionnez l’onglet Prédictions. La vue par défaut montre des images à partir de l’itération active. Vous pouvez utiliser le menu déroulant Iteration pour voir les images envoyées au cours des précédentes itérations.
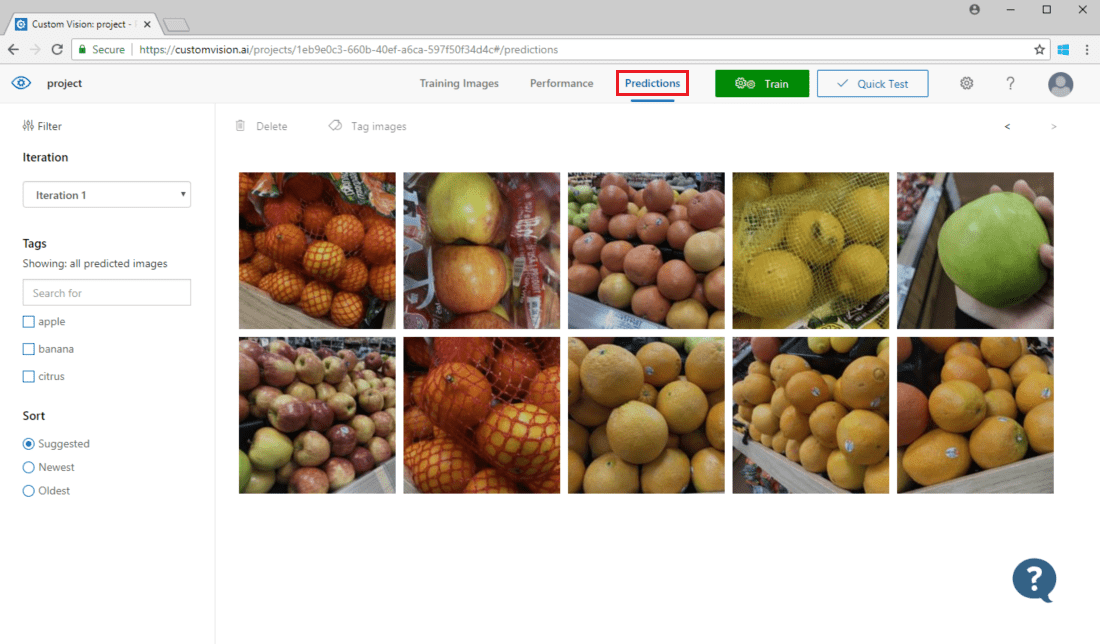
Pointez sur une image pour voir les étiquettes prédites par le modèle. Les images sont triées pour permettre à celles qui peuvent apporter le plus d’améliorations au modèle d’être listées en premier. Pour utiliser une autre méthode de tri, effectuez une sélection dans la section Sort.
Pour ajouter une image à vos données d’entraînement existantes, sélectionnez-la, sélectionnez les étiquettes correspondantes, puis sélectionnez Enregistrer et fermer. L’image est supprimée de Prédictions et ajoutée à l’ensemble d’images d’entraînement. Vous pouvez la voir en sélectionnant l’onglet Training Images (Images d’entraînement).
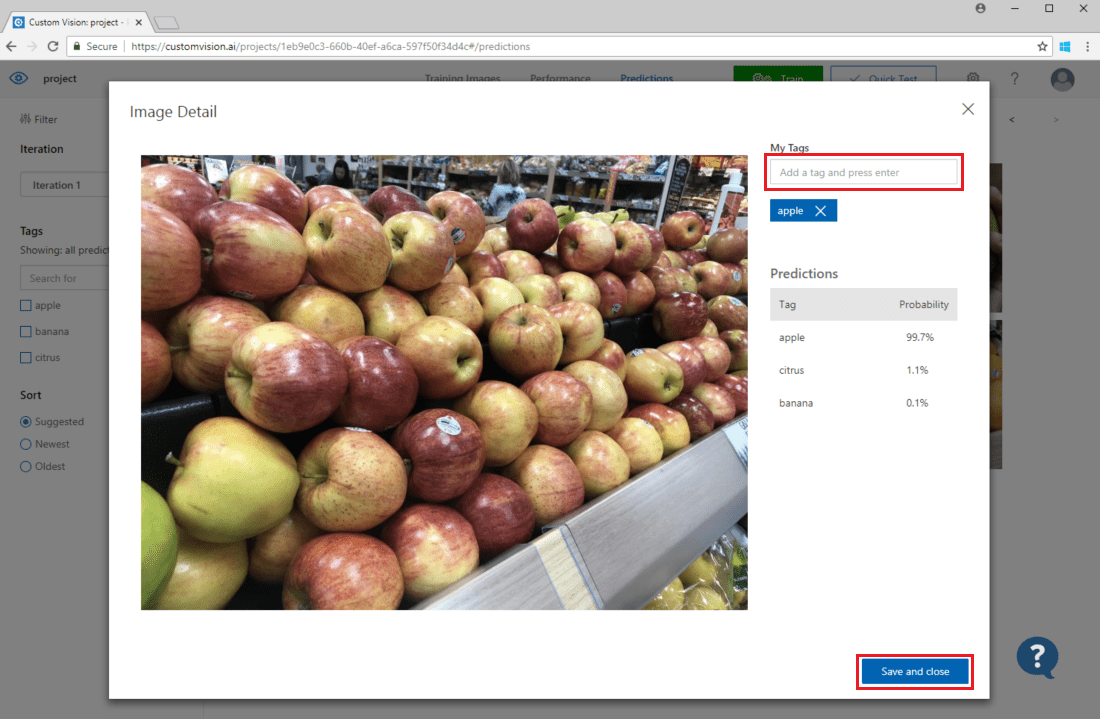
Utilisez ensuite le bouton Train (Entraîner) pour réentraîner le modèle.
Inspecter visuellement les prédictions
Pour examiner les prédictions d’images, accédez à l’onglet Training Images, sélectionnez votre itération d’entraînement précédente dans le menu déroulant Iteration et cochez une ou plusieurs balises sous la section Tags. La vue doit à présent montrer une zone rouge autour de chacune des images pour lesquelles le modèle n’a pas réussi à prédire correctement la balise donnée.
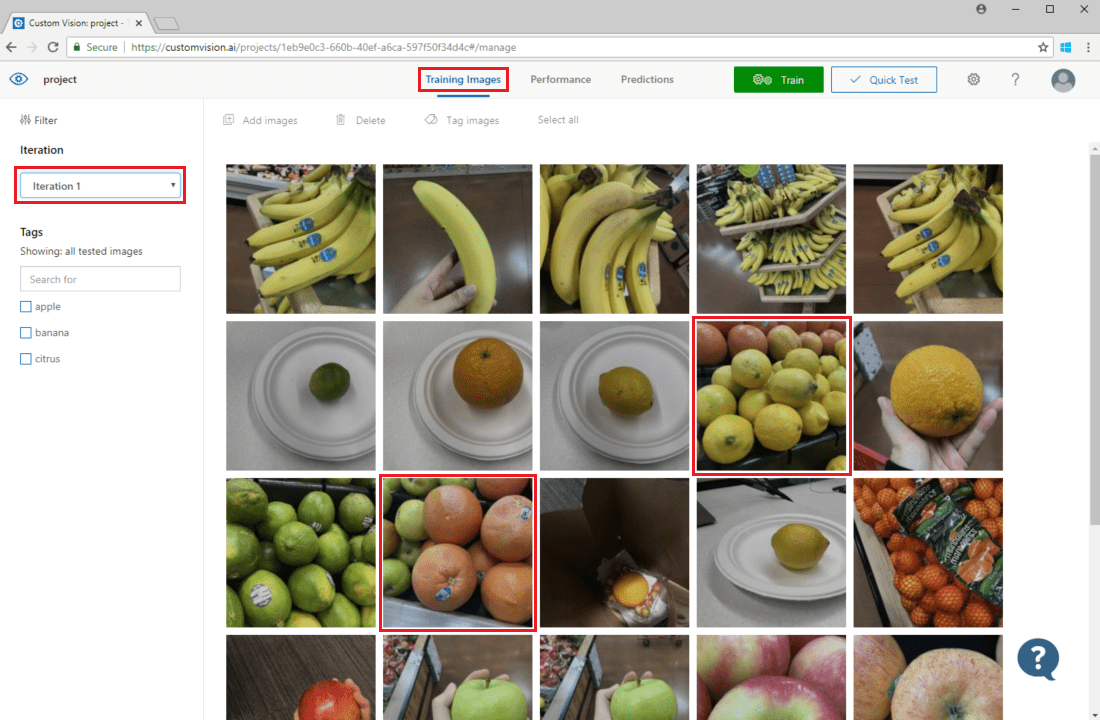
Parfois, un examen visuel permet d’identifier des modèles pouvant être rectifiés en ajoutant des données d’entraînement supplémentaires ou en modifiant les données existantes. Par exemple, un classifieur pommes/citrons verts risquerait d’étiqueter à tort toutes les pommes vertes comme des citrons verts. Vous pourriez alors corriger ce problème en ajoutant et en fournissant des données d’entraînement comportant des images étiquetées de pommes vertes.
Étapes suivantes
Dans ce guide, vous avez découvert plusieurs techniques permettant de rendre votre modèle de classification d’images personnalisé ou votre modèle de détecteur d’objet plus précis. Découvrez ensuite comment tester des images programmatiquement en les soumettant à l’API de prédiction.