Concepts de GPT-4 Turbo avec Vision
GPT-4 Turbo avec Vision est un grand modèle multimodal (LMM) développé par OpenAI qui peut analyser des images et fournir des réponses textuelles à des questions les concernant. Il intègre à la fois le traitement du langage naturel et la compréhension visuelle. Ce guide fournit des détails sur les fonctionnalités et les limitations de GPT-4 Turbo avec Vision.
Pour essayer GPT-4 Turbo avec Vision, consultez le guide de démarrage rapide.
Conversations avec vision
Le modèle GPT-4 Turbo avec Vision répond à des questions générales sur les éléments présents dans les images ou vidéos que vous chargez.
Améliorations
Les améliorations apportées vous permettent d’incorporer d’autres services Azure AI (comme Azure AI Vision) pour ajouter de nouvelles fonctionnalités à l’expérience de conversation avec vision.
Ancrage des objets : Azure AI Vision complète la réponse texte de GPT-4 Turbo avec Vision en identifiant et en localisant les objets importants dans les images d’entrée. Cela permet au modèle de conversation de donner des réponses plus précises et détaillées sur le contenu de l’image.
Important
Pour utiliser l’amélioration Vision, vous avez besoin d’une ressource Vision par ordinateur. Elle doit se trouver dans le niveau payant (S1) et dans la même région Azure que votre ressource GPT-4 Turbo avec Vision.
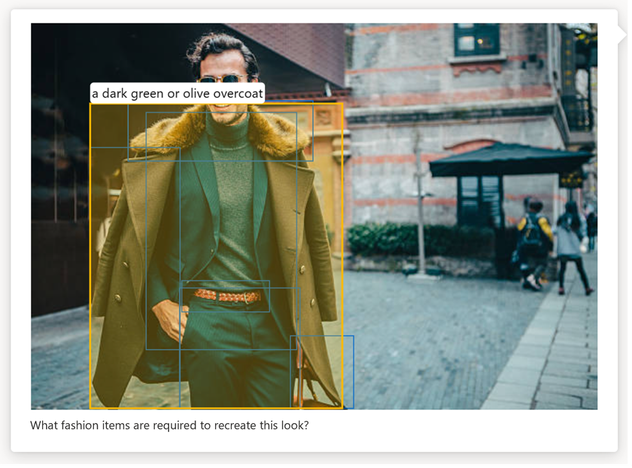

Reconnaissance optique de caractères (OCR) : Azure AI Vision complète GPT-4 Turbo avec Vision en fournissant des résultats OCR de haute qualité comme informations supplémentaires au modèle de conversation. Il permet au modèle de produire des réponses de meilleure qualité pour les images contenant du texte dense, les images transformées et les documents financiers comportant beaucoup de chiffres, et augmente le nombre de langues que le modèle peut reconnaître dans le texte.
Important
Pour utiliser l’amélioration Vision, vous avez besoin d’une ressource Vision par ordinateur. Elle doit se trouver dans le niveau payant (S1) et dans la même région Azure que votre ressource GPT-4 Turbo avec Vision.

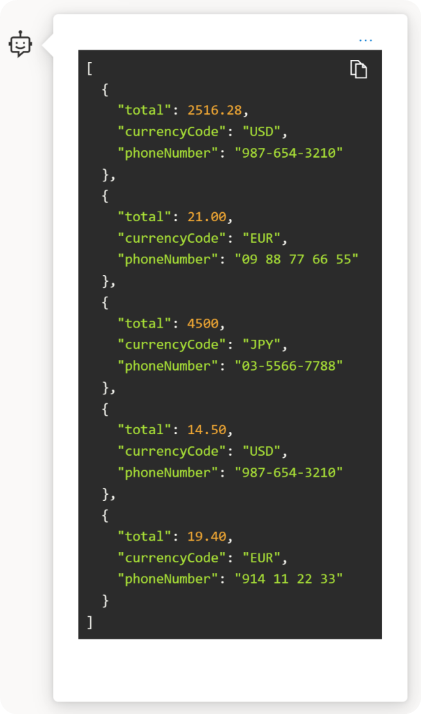
Invite vidéo : parmi les améliorations apportées, l’invite vidéo prend en charge l’utilisation de clips vidéo en entrée pour la conversation IA, ce qui permet au modèle de générer des résumés et des réponses sur du contenu vidéo. Elle utilise la récupération vidéo d’Azure AI Vision pour échantillonner un ensemble d’images à partir d’une vidéo et créer une transcription du message parlé dans la vidéo.
Remarque
Pour utiliser l’amélioration des invites vidéo, vous avez besoin d’une ressource Azure AI Vision, dans le niveau payant (S1), en plus de votre ressource Azure OpenAI.
Informations sur les tarifs spéciaux
Important
Les détails des tarifs sont susceptibles de changer.
GPT-4 Turbo avec Vision engendre des frais au même titre que les autres modèles de conversation Azure OpenAI. Vous êtes facturé un tarif par jeton pour les invites et les complétions, comme cela est détaillé dans la page des tarifs. Les frais de base et les fonctionnalités supplémentaires sont décrits ici :
Les tarifs de base pour GPT-4 Turbo avec Vision sont les suivants :
- Entrée : 0,01 $ par 1000 jetons
- Sortie : 0,03 $ par 1000 jetons
Pour plus d’informations sur la façon dont le texte et les images sont convertis en jetons, consultez la section Jetons de la vue d’ensemble.
Si vous activez les améliorations, une utilisation supplémentaire s’applique à l’utilisation de GPT-4 Turbo avec Vision avec la fonctionnalité Azure AI Vision.
| Modèle | Prix |
|---|---|
| + Fonctionnalités de module complémentaire améliorées pour l’OCR | 1,5$ pour 1000 transactions |
| + Fonctionnalités de module complémentaire améliorées pour la détection d’objets | 1,5$ pour 1000 transactions |
| + Fonctionnalité de module complémentaire améliorée pour l’intégration de la « Récupération vidéo » 1 | Ingestion : 0,05 $ par minute de vidéo Transactions : 0,25 $ par 1000 requêtes de l’index de récupération vidéo |
1 Le traitement des vidéos implique l’utilisation de jetons supplémentaires pour identifier les images clés à des fins d’analyse. Le nombre de ces jetons supplémentaires équivaut à peu près à la somme des jetons dans l’entrée de texte, plus 700 jetons.
Exemple de calcul de prix pour une image
Important
Le contenu suivant est un exemple uniquement, et les prix sont susceptibles de changer à l’avenir.
Pour un cas d’usage classique, prenez une image avec des objets visibles et du texte et une entrée d’invite de 100 jetons. Lorsque le service traite l’invite, il génère 100 jetons de sortie. Dans l’image, le texte et les objets peuvent être détectés. Le prix de cette transaction est le suivant :
| Article | Détail | Coûts |
|---|---|---|
| Entrée d’invite de texte | 100 jetons de texte | 0,001 $ |
| Exemple d’entrée image (voir Jetons d’image) | 170 + 85 jetons d’image | $0.00255 |
| Fonctionnalités de module complémentaire améliorées pour l’OCR | 1,50$ / 1000 transactions | 0,0015$ |
| Fonctionnalités de module complémentaire améliorées pour la détection d’objets | 1,50$ / 1000 transactions | 0,0015$ |
| Jetons de sortie | 100 jetons (supposés) | 0,003 $ |
| Total | $0.00955 |
Exemple de calcul de prix pour une vidéo
Important
Le contenu suivant est un exemple uniquement, et les prix sont susceptibles de changer à l’avenir.
Pour un cas d’usage classique, prenez une vidéo de 3 minutes avec une entrée d’invite de 100 jetons. La vidéo comporte une transcription longue de 100 jetons, et lorsque le service traite l’invite, il génère 100 jetons de sortie. Le prix de cette transaction est le suivant :
| Article | Détail | Coûts |
|---|---|---|
| Jetons d’entrée GPT-4 Turbo avec Vision | 100 jetons de texte | 0,001 $ |
| Coût supplémentaire pour identifier les images | 100 jetons d’entrée + 700 jetons + 1 transaction de récupération vidéo | 0,00825 $ |
| Entrées d’image et entrée de transcription | 20 images (85 jetons chacune) + 100 jetons de transcription | 0,018 $ |
| Jetons de sortie | 100 jetons (supposés) | 0,003 $ |
| Total | 0,03025 $ |
En outre, il existe un coût d’indexation unique de 0,15 $ afin de générer l’index de récupération vidéo pour cette vidéo de trois minutes. Cet index peut être réutilisé sur une quantité quelconque d’appels d’API de récupération vidéo et GPT-4 Turbo avec Vision.
Limites
Cette section décrit les limitations de GPT-4 Turbo avec Vision.
Prise en charge de l’image
- Limitation des améliorations d’images par session de conversation : les améliorations ne peuvent pas être appliquées à plusieurs images au sein d’un seul appel de conversation.
- Taille maximale de l’image d’entrée : la taille maximale des images d’entrée est limitée à 20 Mo.
- Mise au point de l’objet dans l’API d’amélioration : lorsque l’API d’amélioration est utilisée pour l’indexation d’objets et que le modèle détecte les doublons d’un objet, il génère un cadre englobant et une étiquette pour tous les doublons au lieu de les séparer pour chacun d’eux.
- Précision de faible résolution : lorsque les images sont analysées à l’aide du paramètre « basse résolution », elle permet des réponses plus rapides et utilise moins de jetons d’entrée pour certains cas d’usage. Toutefois, cela pourrait avoir une incidence sur la précision de la reconnaissance des objets et du texte dans l'image.
- Restriction de conversation d’image : lorsque vous chargez des images dans Azure OpenAI Studio ou l’API, il existe une limite de 10 images par appel de conversation.
Prise en charge vidéo
- Résolution faible : Les images vidéo sont analysées à l’aide du paramètre GPT-4 Turbo avec le paramètre « basse résolution » de Vision, ce qui peut affecter la précision de la reconnaissance de petits objets et de texte dans la vidéo.
- Limites des fichiers vidéo : types de fichiers MP4 et MOV sont pris en charge. Dans Azure OpenAI Studio, les vidéos doivent être inférieures à 3 minutes. Lorsque vous utilisez l’API, il n’existe pas de limitation de ce type.
- Limites d’invite : invite vidéo ne contient qu’une seule vidéo et aucune image. Dans Azure OpenAI Studio, vous pouvez effacer la session pour essayer une autre vidéo ou d’autres images.
- Sélection limitée d’images : le service sélectionne 20 images dans l’ensemble de la vidéo, ce qui peut ne pas capturer tous les moments ou détails critiques. La sélection d’images peut être répartie uniformément dans la vidéo ou ciblée par une requête de récupération vidéo spécifique, selon l’invite.
- prise en charge de la langue : le service prend principalement en charge l’anglais pour la mise au point de transcriptions. Les transcriptions ne fournissent pas d’informations précises sur les paroles des chansons.
Étapes suivantes
- Suivez le guide de démarrage rapide pour bien démarrer avec GPT-4 Turbo avec Vision.
- Pour obtenir une présentation plus approfondie des API et pour savoir comment utiliser des invites vidéo dans une conversation, suivez le guide pratique.
- Consultez la référence de l’API sur les complétions et les incorporations.
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour