Qu’est-ce que la synthèse vocale ?
Dans cette vue d’ensemble, vous allez découvrir les avantages et les capacités de la fonctionnalité de synthèse vocale du service Speech, qui fait partie d’Azure AI services.
La conversion de texte par synthèse vocale permet à vos applications, outils ou appareils de convertir du texte en discours humain synthétisé. La fonctionnalité de conversion de texte par synthèse vocale est également appelée « synthèse vocale ». Utilisez des voix neuronales prédéfinies humaines prêtes à l’emploi, ou créez une voix neuronale personnalisée propre à votre produit ou à votre marque. Pour obtenir la liste complète des voix, langues et paramètres régionaux pris en charge, consultez Prise en charge des langues et des voix pour le service Speech.
Fonctionnalités de base
La synthèse vocale comprend les fonctionnalités suivantes :
| Fonctionnalité | Résumé | Démonstration |
|---|---|---|
| Voix neuronale prédéfinie (appelée Neuronal sur la page des tarifs) | Voix très naturelles prêtes à l’emploi. Créez un abonnement Azure et une ressource Speech, puis utilisez le Kit de développement logiciel (SDK) Speech ou visitez le portail Speech Studio et sélectionnez les voix neuronales prédéfinies pour commencer. Consultez les détails des prix. | Passez en revue la Galerie de voix et déterminez la voix adaptée à vos besoins métier. |
| Voix neuronale personnalisée (appelée Neuronal personnalisé sur la page des tarifs) | Libre-service facile à utiliser pour la création d’une voix de personnalisation naturelle, avec un accès limité pour une utilisation responsable. Créez un abonnement Azure et une ressource Speech (avec le niveau S0) et demandez à utiliser la fonctionnalité de voix personnalisée. Une fois que vous êtes autorisé à y accéder, visitez le portail Speech Studio, puis sélectionnez Custom Voice pour commencer. Consultez les détails des prix. | Consultez les échantillons vocaux. |
En savoir plus sur les fonctionnalités de synthèse vocale
La conversion de texte par synthèse vocale utilise des réseaux neuronaux profonds pour rendre les voix des ordinateurs quasiment indistinctes des enregistrements des personnes. Avec l’articulation claire des mots, la synthèse vocale neuronale réduit considérablement la fatigue d’écoute quand les utilisateurs interagissent avec les systèmes d’IA.
Les modèles d’accent et d’intonation dans le langage parlé sont appelés prosodie. Les systèmes traditionnels de conversion de texte par synthèse vocale décomposent les prosodies en analyse linguistique distincte et en étapes de prédiction acoustique régies par des modèles indépendants. Cela peut entraîner une synthèse vocale étouffée, atténuée.
Voici plus d’informations sur les fonctionnalités de synthèse vocale dans le service Speech, ainsi que sur la façon dont elles surmontent les limites des systèmes de synthèse vocale traditionnels :
Synthèse vocale en temps réel : utilisez le kit de développement logiciel (SDK) Speech ou l’API REST pour convertir du texte en parole à l’aide de voix neuronales prédéfinies ou de voix neuronales personnalisées.
Synthèse asynchrone d’audio long : utilisez l’API de synthèse par lots pour synthétiser de manière asynchrone des fichiers de synthèse vocale de plus de 10 minutes (par exemple, des livres audio ou des conférences). Contrairement à la synthèse effectuée via le kit de développement logiciel (SDK) Speech ou l’API REST de reconnaissance vocale, les réponses ne sont pas retournées en temps réel. Il est prévu que les demandes soient envoyées de façon asynchrone, que les réponses fassent l’objet d’une interrogation et que l’audio synthétisé soit téléchargé quand le service le met à disposition.
Voix neuronales prédéfinies : Azure AI Speech utilise les réseaux neuronaux profonds pour dépasser les limites de la synthèse vocale traditionnelle en termes d’accent tonique et d’intonation dans le langage parlé. La prédiction prosodique et la synthèse vocale se produisent simultanément, ce qui aboutit à un résultat plus fluide et plus naturel. Chaque modèle vocal neural prédéfini est disponible à 24 kHz et à haute fidélité 48 kHz. Vous pouvez utiliser des voix neuronales pour :
- Rendre les interactions avec les chatbots et les assistants vocaux plus naturelles et plus agréables.
- Convertir des textes numériques comme les livres électroniques en livres audio.
- Améliorer les systèmes de navigation embarqués.
Pour obtenir la liste complète des voix neuronales Azure AI Speech prédéfinies, consultez Prise en charge de la langue et de la voix pour le service Speech.
Améliorer le résultat de la synthèse vocale avec SSML : Speech Synthesis Markup Language (SSML) est un langage de balisage basé sur XML utilisé pour personnaliser les résultats de la synthèse vocale. Avec SSML, vous pouvez ajuster la tonalité de la voix, ajouter des pauses, améliorer la prononciation, changer le débit de parole, ajuster le volume et attribuer plusieurs voix à un même document.
Vous pouvez utiliser SSML pour définir vos propres lexiques ou basculer vers des types de diction différents. Avec les voix multilingues, vous pouvez également ajuster les langues parlées par le biais de SSML. Pour améliorer le résultat vocal de votre scénario, consultez Améliorer la synthèse avec SSML (Speech Synthesis Markup Language) et Synthèse vocale à l’aide de l’outil Création de contenu audio.
Visèmes : Les visèmes sont les poses clés dans la parole observée, notamment la position des lèvres, de la mâchoire et de la langue lors de la production d’un phonème particulier. Les visèmes ont une corrélation forte avec les voix et les phonèmes.
À l’aide des événements de visème dans SDK Speech, vous pouvez générer des données d’animation faciale. Ces données peuvent être utilisées pour animer des visages dans la communication, l’enseignement, le divertissement et le service à la clientèle. Le visème est actuellement pris en charge uniquement pour les voix neuronales
en-US(anglais des États-Unis).
Remarque
En plus des voix neuronales (non-HD) Azure AI Speech, vous pouvez également utiliser des voix Azure AI Speech haute définition (HD) et des voix neuronales Azure OpenAI (HD et non-HD). Les voix HD offrent une meilleure qualité pour des scénarios plus polyvalents.
Certaines voix ne prennent pas en charge toutes les balises SSML (Speech Synthesis Markup Language). Ceci inclut le texte neuronal pour les voix HD de synthèse vocale, les voix personnelles et les voix incorporées.
- Pour les voix haute définition (HD) d’Azure AI Speech, vérifiez la prise en charge de SSML ici.
- Pour une voix personnelle, vous pouvez trouver les informations sur la prise en charge de SSML ici.
- Pour les voix incorporées, vérifiez la prise en charge de SSML ici.
Démarrage
Pour bien démarrer avec la synthèse vocale, consultez le démarrage rapide. La synthèse vocale est disponible via le kit de développement logiciel (SDK) Speech, l’API REST et l’interface CLI Speech.
Conseil
Pour convertir du texte par synthèse vocale avec une approche sans code, essayez l’outil Création de contenu audio dans Speech Studio.
Exemple de code
Vous trouverez un exemple de code pour la synthèse vocale sur GitHub. Ces exemples couvrent la conversion de texte par synthèse vocale dans les langages de programmation les plus populaires.
Voix neuronale personnalisée
En plus des voix neuronales prédéfinies, vous pouvez créer des voix neuronales personnalisées qui sont propres à votre produit ou à votre marque. Pour commencer, vous n’avez besoin que de quelques fichiers audio et des transcriptions associées. Pour plus d’informations, consultez Bien démarrer avec la voix neuronale personnalisée.
Remarque sur la tarification
Caractères facturables
Lorsque vous utilisez la fonctionnalité de synthèse vocale, vous êtes facturé pour chaque caractère converti en parole, y compris les signes de ponctuation. Même si le document SSML lui-même n’est pas facturable, les éléments facultatifs utilisés pour ajuster la façon dont le texte est converti en parole, tels que les phonèmes et la tonalité de la voix, sont comptabilisés comme caractères facturables. Voici une liste des éléments pouvant être facturés :
- Texte transmis à la fonctionnalité de synthèse vocale dans le corps SSML de la requête
- Tout balisage dans le champ de texte du corps de la demande au format SSML, à l’exception des balises
<speak>et<voice> - Lettres, ponctuation, espaces, tabulations, balisage et tous les caractères d’espace blanc
- Chaque point de code défini au format Unicode
Pour plus d’informations, consultez les tarifs du service Speech.
Important
Chaque caractère chinois compte pour deux caractères dans la facturation, notamment le kanji utilisé en japonais, le hanja utilisé en coréen ou le hanzi utilisé dans d’autres langues.
Temps d’apprentissage et d’hébergement du modèle pour la voix neuronale personnalisée
L’entraînement et l’hébergement de la voix neuronale personnalisée sont calculés par heure et facturés par seconde. Pour connaître le prix de l’unité de facturation, consultez Tarifs du service Speech.
Le temps d’apprentissage de la voix neuronale personnalisée (CNV) est mesuré par « heure de calcul » (unité pour mesurer le temps d’exécution de la machine). En règle générale, lors de l’entraînement d’un modèle vocal, deux tâches de calcul s’exécutent en parallèle. Ainsi, les heures de calcul calculées sont plus longues que le temps d’entraînement réel. En moyenne, l’entraînement d’une voix neuronale personnalisée Lite nécessite moins d’une heure de calcul, tandis que dans le cas d’une voix neuronale personnalisée Pro, il faut généralement 20 à 40 heures de calcul pour entraîner une voix monostyle et environ 90 heures de calcul pour entraîner une voix multistyle. Le temps d’entraînement d’une voix neuronale personnalisée est facturé avec un plafond de 96 heures de calcul. Ainsi, si un modèle vocal est entraîné en 98 heures de calcul, vous n’êtes facturé que 96 heures de calcul.
L’hébergement du point de terminaison CNV (voix neuronale personnalisée) est mesuré selon le temps réel (heure). Le temps d’hébergement (heures) de chaque point de terminaison est calculé à 00:00 UTC tous les jours pour les 24 heures précédentes. Par exemple, si le point de terminaison a été actif pendant 24 heures le premier jour, il est facturé pour 24 heures à 00:00 UTC le deuxième jour. Si le point de terminaison vient d’être créé ou a été suspendu pendant la journée, il est facturé pour son temps d’exécution cumulé jusqu’à 00:00 UTC le deuxième jour. Si le point de terminaison n’est actuellement pas hébergé, il n’est pas facturé. En plus du calcul quotidien à 00:00 UTC chaque jour, la facturation est également déclenchée immédiatement quand un point de terminaison est supprimé ou suspendu. Par exemple, pour un point de terminaison créé à 08:00 UTC le 1er décembre, le calcul de l’hébergement donne 16 heures à 00:00 UTC le 2 décembre et 24 heures à 00:00 UTC le 3 décembre. Si l’utilisateur suspend l’hébergement du point de terminaison à 16:30 UTC le 3 décembre, la durée (16.5 heures) allant de 00:00 à 16:30 UTC le 3 décembre est calculée pour la facturation.
Voix personnelle
Lorsque vous utilisez la fonctionnalité de voix personnelle, vous êtes facturé pour le stockage de profil et la synthèse.
- Stockage de profil : Une fois qu’un profil vocal personnel est créé, il sera facturé jusqu’à ce qu’il soit supprimé du système. L’unité de facturation est par voix par jour. Si le stockage vocal dure pendant une période inférieure à 24 heures, il est facturé comme un jour complet.
- Synthèse : Facturé au caractère. Pour plus d’informations sur les caractères facturables, consultez les caractères facturables ci-dessus.
Avatar de synthèse vocale
Lors de l’utilisation de la fonctionnalité d’avatar de synthèse vocale, les frais seront facturés en fonction de la longueur de la sortie vidéo et sera facturé à la seconde. Toutefois, pour l’avatar en temps réel, les frais sont basés sur l’heure à laquelle l’avatar est actif, qu’il parle ou reste silencieux, et sera également facturé par seconde. Pour optimiser les coûts d’utilisation des avatars en temps réel, reportez-vous aux conseils fournis dans l’exemple de code (recherchez « Utiliser la vidéo locale pour inactif »). L’hébergement d’avatar est facturé par seconde par point de terminaison. Vous pouvez suspendre votre point de terminaison pour économiser des coûts. Si vous souhaitez suspendre votre point de terminaison, vous pouvez le supprimer directement. Pour l’utiliser à nouveau, redéployez simplement le point de terminaison.
Surveiller les métriques de la synthèse vocale Azure
La surveillance des métriques clés associées aux services de synthèse vocale est essentielle pour gérer l’utilisation des ressources et contrôler les coûts. Cette section vous guide pour trouver des informations d’utilisation dans le portail Azure et fournit des définitions détaillées des métriques clés. Pour plus d’informations sur les métriques Azure Monitor, consultez Vue d’ensemble des métriques Azure Monitor.
Comment trouver des informations d’utilisation dans le portail Azure
Pour gérer efficacement vos ressources Azure, il est essentiel d’accéder aux informations d’utilisation et de les passer en revue régulièrement. Voici comment trouver les informations d’utilisation :
Accédez au portail Azure et connectez-vous avec votre compte Azure.
Accédez à Ressources, puis sélectionnez la ressource que vous voulez surveiller.
Sélectionnez Métriques sous Surveillance dans le menu de gauche.
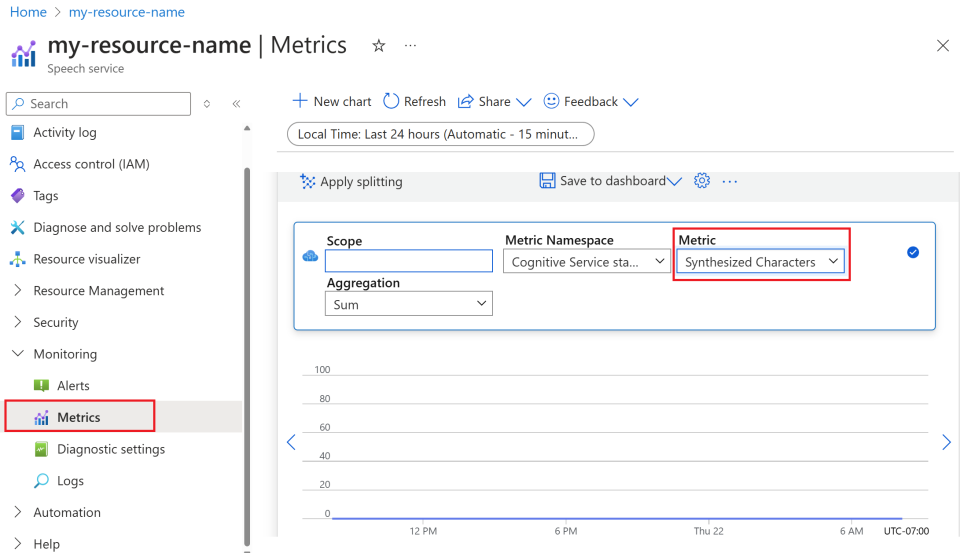
Personnalisez les vues des métriques.
Vous pouvez filtrer les données par type de ressource, type de métrique, intervalle de temps et d’autres paramètres pour créer des vues personnalisées correspondant à vos besoins de surveillance. En outre, vous pouvez enregistrer la vue des métriques dans des tableaux de bord en sélectionnant Enregistrer dans le tableau de bord pour faciliter l’accès aux métriques fréquemment utilisées.
Configurer des alertes.
Pour gérer l’utilisation plus efficacement, configurez des alertes en accédant à l’onglet Alertes sous Surveillance dans le menu de gauche. Les alertes peuvent vous avertir quand votre utilisation atteint des seuils spécifiques, ce qui vous permet d’éviter des coûts inattendus.
Définition des métriques
Voici un tableau résumant les métriques clés pour les services de synthèse vocale Azure.
| Nom de la métrique | Description |
|---|---|
| Caractères synthétisés | Fait le suivi du nombre de caractères convertis en parole, y compris la voix neuronale prédéfinie et la voix neuronale personnalisée. Pour plus d’informations sur les caractères facturables, consultez Caractères facturables. |
| Secondes de vidéo synthétisées | Mesure la durée totale de vidéo synthétisée, y compris la synthèse d’avatars par lots, la synthèse d’avatars en temps réel et la synthèse d’avatars personnalisés. |
| Secondes d’hébergement du modèle d’avatar | Fait le suivi du temps total en secondes pendant lequel votre modèle d’avatar personnalisé est hébergé. |
| Heures d’hébergement du modèle vocal | Fait le suivi du temps total en heures pendant lequel votre modèle de voix neuronale personnalisée est hébergé. |
| Minutes d’entraînement du modèle vocal | Mesure le temps total en minutes pour l’entraînement de votre modèle de voix neuronale personnalisée. |
Documents de référence
IA responsable
Un système d’IA englobe non seulement la technologie, mais aussi ses utilisateurs, les personnes concernées et l’environnement dans lequel il est déployé. Lisez les notes de transparence pour en savoir plus sur l’utilisation et le déploiement d’une IA responsable dans vos systèmes.
- Note de transparence et cas d'usage pour la voix neuronale personnalisée
- Caractéristiques et limitations de l’utilisation de la voix neuronale personnalisée
- Accès limité à la voix neuronale personnalisée
- Instructions pour le déploiement responsable de la technologie des voix de synthèse
- Divulgation d'un talent vocal
- Guide de conception de la divulgation
- Modèles de conception de divulgation
- Code de conduite pour les intégrations de synthèse vocale
- Données, confidentialité et sécurité pour la voix neuronale personnalisée