Custom Translator pour les débutants
Custom Translator vous permet de créer un système de traduction qui reflète la terminologie et le style spécifiques à votre entreprise, votre secteur d’activité et votre domaine. L’entraînement et le déploiement d’un système personnalisé sont faciles, et ne nécessitent aucune compétence en programmation. Le système de traduction personnalisé s’intègre de manière transparente à vos applications, workflows et sites web existants. Il est disponible sur Azure via le même service cloud de l’API de traduction de texte de Microsoft, qui délivre des milliards de traductions chaque jour.
La plateforme permet aux utilisateurs de créer et de publier des systèmes de traduction personnalisés de et vers l’anglais. Le service Custom Translator prend en charge plus de 60 langues qui correspondent directement aux langues disponibles pour la traduction automatique neuronale (TAN). Pour obtenir une liste complète, consultez prise en charge de la langue Traducteur.
Un modèle de traduction personnalisé est-il le bon choix pour moi ?
Un modèle de traduction personnalisée bien entraîné fournit des traductions plus justes pour un domaine spécifique, car il s’appuie sur des documents précédemment traduits dans le domaine concerné pour apprendre les traductions à privilégier. Translator utilise ces termes et expressions en contexte pour produire des traductions fluides dans la langue cible tout en respectant la grammaire contextuelle.
L’entraînement d’un modèle de traduction personnalisé complet nécessite une quantité importante de données. Si vous n’avez pas au moins 10 000 phrases de documents ayant fait l’objet d’un entraînement, vous ne pouvez pas entraîner un modèle de traduction linguistique complet. Toutefois, vous pouvez entraîner un modèle de type dictionnaire uniquement ou utiliser les traductions prêtes à l’emploi, de haute qualité, disponibles avec l’API de traduction de texte.
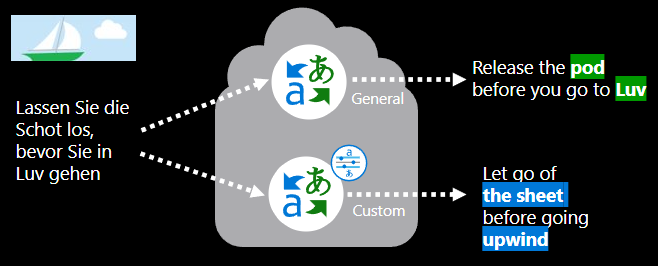
En quoi consiste l’entraînement d’un modèle de traduction personnalisé ?
La création d’un modèle de traduction personnalisé implique les aspects suivants :
Compréhension de votre cas d’usage.
Obtention de données traduites spécifiques au domaine (de préférence traduites manuellement).
Évaluation de la qualité de la traduction ou les traductions de la langue cible.
Comment évaluer mon cas d’usage ?
Avoir une idée claire de votre cas d’usage et du résultat souhaité est la première étape vers la recherche de données d’entraînement efficaces. Voici quelques considérations à prendre en compte :
Votre résultat souhaité est-il spécifié et comment est-il mesuré ?
Est-ce que votre domaine d’activité est identifié ?
Avez-vous des phrases relatives à un domaine spécifique avec une terminologie et un style similaires ?
Votre cas d’usage implique-t-il plusieurs domaines ? Si oui, devez-vous créer un ou plusieurs systèmes de traduction ?
Avez-vous des impératifs qui impactent la résidence des données régionales au repos et en transit ?
Les utilisateurs cibles se trouvent-ils dans une ou plusieurs régions ?
Comment sourcer mes données ?
La recherche de données de qualité dans le domaine est souvent une tâche difficile qui varie en fonction de la classification des utilisateurs. Voici quelques questions que vous pouvez vous poser au fur et à mesure que vous évaluez les données qui peuvent être disponibles :
Votre entreprise dispose-t-elle de données de traduction précédentes que vous pouvez utiliser ? Les entreprises ont souvent un grand nombre de données de traduction accumulées depuis de nombreuses années d’utilisation de la traduction humaine.
Disposez-vous d’une grande quantité de données monolingues ? Les données monolingues sont des données dans une seule langue. Si c’est le cas, pouvez-vous obtenir des traductions de ces données ?
Pouvez-vous analyser des portails en ligne pour collecter des phrases sources et synthétiser des phrases cibles ?
Que dois-je utiliser comme support d’entraînement ?
| Source | Résultat | Règles à suivre |
|---|---|---|
| Documents d’apprentissage bilingues | Enseigne votre terminologie et votre style au système. | Soyez libre. Toute traduction humaine dans le domaine est meilleure que la traduction automatique. Ajoutez et supprimez des documents à mesure que vous essayez d’améliorer le score BLEU. |
| Documents de réglage | Effectue l'apprentissage des paramètres de la traduction automatique neuronale. | Soyez strict. Créez-les afin qu’ils soient mieux représentatifs de ce que vous allez traduire à l’avenir. |
| Documents de test | Calculez le score BLEU. | Soyez strict. Créez des documents de test afin de mieux représenter ce que vous envisagez de traduire à l’avenir. |
| Dictionnaire d’expressions | Force la traduction donnée 100 % du temps. | Soyez restrictif. Un dictionnaire d’expressions respecte la casse. Tous les mots ou expressions figurant dans la liste sont traduits comme vous le souhaitez. Dans de nombreux cas, il est préférable de ne pas utiliser de dictionnaire d’expressions et de laisser le système apprendre. |
| Dictionnaire de phrases | Force la traduction donnée 100 % du temps. | Soyez strict. Un dictionnaire de phrases ne respecte pas la casse et convient parfaitement aux phrases courtes de domaine. La totalité (et pas seulement une partie) de la phrase soumise doit être identique à l’entrée de dictionnaire source Si seulement une partie de la phrase correspond, l’entrée n’est pas mise en correspondance. |
Qu’est-ce qu’un score BLEU ?
BLEU (Bilingual Evaluation Understudy) est un algorithme qui permet d’évaluer la précision ou la justesse d’un texte traduit automatiquement d’une langue à une autre. Custom Translator utilise la métrique BLEU pour indiquer la justesse de la traduction.
Un score BLEU est un nombre compris entre zéro et 100. Un score égal à zéro indique une traduction de faible qualité, où rien dans la traduction ne correspond à la référence. Un score égal à 100 indique une traduction parfaite identique à la référence. Il n’est pas nécessaire d’atteindre un score de 100. Un score BLEU compris entre 40 et 60 indique une traduction de haute qualité.
Que se passe-t-il si je n’envoie pas de données de réglage ou de test ?
Les phrases de réglage et de test sont les plus représentatives possible de ce que vous prévoyez de traduire à l’avenir. Si vous n’envoyez aucune donnée de réglage ou de test, Custom Translator exclut automatiquement des phrases de vos documents d’entraînement pour les utiliser en tant que données de réglage et de test.
| Générée par le système | Sélection manuelle |
|---|---|
| Pratique. | Permet un réglage précis de vos besoins futurs. |
| Présente un certain intérêt, si vous savez que vos données d’entraînement sont représentatives de ce que vous comptez traduire. | Offre plus de liberté pour composer vos données d’entraînement. |
| Facile à refaire quand vous étendez ou réduisez le domaine. | Permet d’utiliser plus de données et d’obtenir une meilleure couverture du domaine. |
| Change à chaque entraînement. | Reste statique au fil des entraînements répétés |
Comment le support d’entraînement est-il traité par Custom Translator ?
En vue de l’entraînement, les documents sont soumis à une série d’étapes de traitement et de filtrage. La connaissance du processus de filtrage peut vous aider à comprendre l’intérêt du nombre de phrases affichées ainsi que les étapes à suivre pour préparer les documents d’entraînement en vue d’un entraînement avec Custom Translator. Les étapes de filtrage sont les suivantes :
Alignement de phrase
Si votre document n'est pas au format
XLIFF,XLSX,TMX, ouALIGN, Custom Translator aligne les phrases de vos documents source et cible, phrase par phrase. Translator n’effectue pas l’alignement des documents. Il suit votre convention de nommage des documents pour trouver un document correspondant dans l’autre langue. Dans le texte source, Custom Translator tente de trouver la phrase correspondante dans la langue cible. Il a recours au balisage des documents (balises HTML incorporées, par exemple) pour faciliter l'alignement.Si vous voyez un écart important entre le nombre de phrases dans les documents source et cible, cela signifie que votre document source n’est peut-être pas parallèle ou qu’il n’a pas pu être aligné. Les paires de documents présentant une importante différence de phrases (>10 %) de chaque côté nécessitent un second examen pour s’assurer qu’elles sont bien parallèles.
Extraction des données de réglage et de test
Les données de réglage et de test sont facultatives. Si vous ne les fournissez pas, le système supprime le pourcentage approprié de données dans vos documents d’entraînement pour s’en servir à des fins de réglage et de test. La suppression se produit de manière dynamique dans le cadre du processus d’entraînement. Dans la mesure où cette étape se produit dans le cadre de l’entraînement, vos documents chargés ne sont pas affectés. Vous pouvez voir le nombre final de phrases utilisées pour chaque catégorie de données (entraînement, réglage, test et dictionnaire) dans la page des détails du modèle, une fois l’entraînement réussi.
Filtre de longueur
- Supprime les phrases n’ayant qu’un seul mot de chaque côté.
- Supprime les phrases de plus de 100 mots de chaque côté. Le chinois, le japonais et le coréen sont exemptés.
- Supprime les phrases de moins de trois caractères. Le chinois, le japonais et le coréen sont exemptés.
- Supprime les phrases de plus de 2000 caractères pour le chinois, le japonais et le coréen.
- Supprime les phrases ayant moins de 1 % de caractères alphanumériques.
- Supprime les entrées de dictionnaire contenant plus de 50 mots.
Espace blanc
- Remplace les séquences d’espaces blancs, notamment les tabulations et les séquences CR/LF (retour chariot/saut de ligne), par un seul espace.
- Supprime les espaces de début ou de fin de la phrase.
Ponctuation de fin de phrase
Remplace les caractères de ponctuation de fin de phrase multiples par une seule instance. Normalisation des caractères japonais.
Convertit les lettres et chiffres à pleine chasse en caractères à demi-chasse.
Balises XML sans séquence d'échappement
Transforme les balises sans séquence d’échappement en balises avec séquence échappement :
Tag Devient < < > > & & Caractères non valides
Custom Translator supprime les phrases contenant le caractère Unicode U+FFFD. Le caractère U+FFFD signale l'échec d'une conversion d'encodage.
Quelles sont les étapes à suivre avant de charger des données ?
- Supprimez les phrases dont le codage n’est pas valide.
- Supprimez les caractères de contrôle Unicode.
- Alignez les phrases (sources-cibles), si faisable.
- Supprimez les phrases sources et cibles qui ne correspondent pas aux langues source et cible.
- Quand les phrases sources et cibles comportent des langues mélangées, vérifiez que les mots non traduits sont intentionnels, par exemple les noms d’organisations et de produits.
- Évitez d’enseigner des erreurs à votre modèle en vous assurant que la grammaire et la typographie sont correctes.
- Avoir une phrase source mappée à une phrase cible. Bien que notre processus d’entraînement gère les lignes source et cible contenant plusieurs phrases, le mappage un-à-un est une bonne pratique.
Comment évaluer les résultats ?
Une fois votre modèle correctement entraîné, vous pouvez voir le score BLEU du modèle et le score BLEU du modèle de référence dans la page des détails du modèle. Nous utilisons le même jeu de données de test pour générer le score BLEU du modèle et le score BLEU de référence. Ces données vous aide à prendre une décision éclairée quant au modèle convenant le mieux à votre cas d’usage.