Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit les concepts de base d’Azure Kubernetes Service (AKS), un service Kubernetes managé que vous pouvez utiliser pour déployer et exploiter des applications conteneurisées à grande échelle sur Azure.
Important
À compter du 30 novembre 2025, Azure Kubernetes Service (AKS) ne prend plus en charge ni fournit des mises à jour de sécurité pour Azure Linux 2.0. L’image de nœud Azure Linux 2.0 est figée à la version 202512.06.0. À compter du 31 mars 2026, les images de nœud seront supprimées et vous ne pourrez pas mettre à l’échelle vos pools de nœuds. Migrez vers une version Azure Linux prise en charge en mettant à niveau vos pools de nœuds vers une version Kubernetes prise en charge ou en migrant vers osSku AzureLinux3. Pour plus d’informations, consultez le problème de retrait sur GitHub et l’annonce de retrait des mises à jour Azure. Pour rester informé des annonces et des mises à jour, suivez les notes de publication d’AKS.
Présentation de Kubernetes
Kubernetes est une plateforme d’orchestration de conteneurs open source permettant d’automatiser le déploiement, la mise à l’échelle et la gestion d’applications conteneurisées. Pour plus d’informations, consultez la documentation Kubernetes officielle.
Présentation d’AKS
AKS est un service Kubernetes managé qui simplifie le déploiement, la gestion et la mise à l’échelle d’applications conteneurisées qui utilisent Kubernetes. Pour plus d’informations, consultez Qu’est-ce qu’Azure Kubernetes Service (AKS) ?.
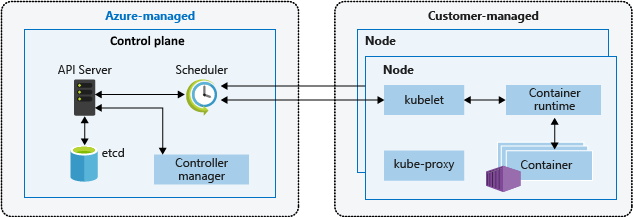
Composants de cluster
Un cluster AKS est divisé en deux principaux composants :
- Plan de contrôle : Le plan de contrôle fournit les services Kubernetes de base et l’orchestration des charges de travail des applications.
- Nœuds : Les nœuds sont les machines virtuelles sous-jacentes qui exécutent vos applications.
Remarque
Les composants managés AKS ont l’étiquette kubernetes.azure.com/managedby: aks.
AKS gère les versions Helm avec le préfixe aks-managed. L’augmentation continue des révisions sur ces versions est prévue et sans risque.
Plan de contrôle
Le plan de contrôle managé Azure se compose de plusieurs composants qui aident à gérer le cluster :
| Composant | Descriptif |
|---|---|
kube-apiserver |
Le serveur d’API (kube-apiserver) expose l’API Kubernetes pour pouvoir adresser des requêtes au cluster de l’intérieur et de l’extérieur du cluster. |
etcd |
Le store clé-valeur hautement disponible etcd aide à conserver l'état et la configuration de votre cluster Kubernetes. |
kube-scheduler |
Le planificateur (kube-scheduler) permet de prendre des décisions de planification. Il surveille les nouveaux pods sans nœud attribué et sélectionne un nœud sur lequel ils s'exécuteront. |
kube-controller-manager |
Le gestionnaire de contrôleurs (kube-controller-manager) exécute des processus de contrôleur, comme détecter lorsque des nœuds tombent en panne et résoudre le problème. |
cloud-controller-manager |
Le gestionnaire de contrôleurs cloud (cloud-controller-manager) incorpore la logique de contrôle spécifique au cloud pour exécuter des contrôleurs spécifiques au fournisseur de cloud. |
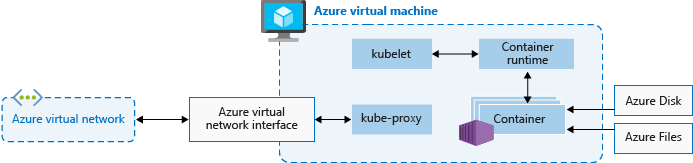
Nœuds
Chaque cluster AKS a au moins un nœud, qui est une machine virtuelle Azure qui exécute des composants de nœud Kubernetes. Les composants suivants s’exécutent sur chaque nœud :
| Composant | Descriptif |
|---|---|
kubelet |
Le kubelet garantit que les conteneurs s’exécutent dans un pod. |
kube-proxy |
Le kube-proxy est un proxy réseau qui gère les règles réseau sur les nœuds. |
container runtime |
Le runtime de conteneurs gère l’exécution et le cycle de vie des conteneurs. |
Configuration de nœuds
Configurez les paramètres suivants pour les nœuds.
Taille et image des machines virtuelles
La taille de machine virtuelle Azure pour vos nœuds définit les processeurs, la mémoire, la taille et le type de stockage disponible, tels qu’un disque SSD hautes performances ou un disque dur standard. La taille de machine virtuelle que vous choisissez dépend des exigences de charge de travail et du nombre de pods que vous envisagez d’exécuter sur chaque nœud. Depuis mai 2025, la référence SKU et la taille de machine virtuelle par défaut sont sélectionnées dynamiquement par AKS en fonction de la capacité et du quota disponibles si le paramètre est laissé vide pendant le déploiement. Pour plus d’informations, consultez Tailles de machine virtuelles prises en charge dans Azure Kubernetes Service (AKS).
Dans AKS, l’image de machine virtuelle pour les nœuds de votre cluster est basée sur Ubuntu Linux, Azure Linux ou Windows Server 2022. Quand vous créez un cluster AKS ou augmentez le nombre de nœuds, la plateforme Azure crée et configure automatiquement le nombre demandé de machines virtuelles. Les nœuds d’agent sont facturés en tant que machines virtuelles standard. Toutes les remises de taille de machine virtuelle, y compris les réservations Azure, sont appliquées automatiquement.
Disques du système d’exploitation
Le dimensionnement du disque de système d’exploitation par défaut est utilisé sur de nouveaux clusters ou pools de nœuds uniquement lorsqu’une taille de disque de système d’exploitation par défaut n’est pas spécifiée. Ce comportement s’applique aux disques de système d’exploitation managés et éphémères. Pour plus d’informations, consultez Dimensionnement du disque du système d’exploitation par défaut.
Réservations de ressources
AKS utilise des ressources de nœud pour permettre aux nœuds de fonctionner dans le cadre du cluster. Cette utilisation peut entraîner un écart entre les ressources totales du nœud et les ressources allouables dans AKS. Pour conserver les fonctionnalités et les performances des nœuds, AKS réserve deux types de ressources, processeur et mémoire, sur chaque nœud. Pour plus d’informations, consultez Réservations de ressources dans AKS.
Système d''exploitation
AKS prend en charge deux distributions Linux : Ubuntu et Azure Linux. Ubuntu est la distribution Linux par défaut sur AKS. Les pools de nœuds Windows sont également pris en charge sur AKS avec le canal de maintenance à long terme (LTSC) comme canal par défaut sur AKS. Pour plus d’informations sur les versions de système d’exploitation par défaut, consultez la documentation sur les images de nœud.
Runtime de conteneurs
Un runtime de conteneur est un logiciel qui exécute des conteneurs et gère des images conteneur sur un nœud. Le runtime permet d’extraire les appels système ou les fonctionnalités spécifiques au système d’exploitation pour exécuter des conteneurs sur Linux ou Windows. Pour les pools de nœuds Linux, containerd est utilisé sur Kubernetes version 1.19 et ultérieure. Pour les pools de nœuds Windows Server 2019 et 2022, containerd est disponible en général et est la seule option d’exécution sur Kubernetes version 1.23 et plus.
Pods
Un pod est un groupe d’un ou plusieurs conteneurs qui partagent les mêmes ressources de stockage et de réseau, et une spécification du mode d’exécution des conteneurs. Les pods ont généralement un mappage un-à-un avec un conteneur, mais vous pouvez exécuter plusieurs conteneurs dans un pod.
Pools de nœuds
Dans AKS, les nœuds d’une même configuration sont regroupés dans des pools de nœuds. Ces pools de nœuds contiennent les groupes de machines virtuelles identiques et les machines virtuelles sous-jacents qui exécutent vos applications.
Lorsque vous créez un cluster AKS, vous définissez le nombre initial de nœuds et leur taille (version), ce qui crée un pool de nœuds système. Les pools de nœuds système ont pour principal objectif d’héberger des pods système critiques tels que CoreDNS et konnectivity.
Pour prendre en charge les applications ayant des exigences de calcul ou de stockage différentes, vous pouvez créer des pools de nœuds utilisateur. Les pools de nœuds utilisateur sont principalement utilisés pour héberger vos pods d'application.
Pour plus d’informations, consultez Créer des pools de nœuds dans AKS et Gérer les pools de nœuds dans AKS.
Groupe de ressources de nœud
Lorsque vous créez un cluster AKS dans un groupe de ressources Azure, le fournisseur de ressources AKS crée automatiquement un deuxième groupe de ressources appelé groupe de ressources de nœud. Ce groupe de ressources contient toutes les ressources d’infrastructure associées au cluster, notamment les machines virtuelles, les groupes de machines virtuelles identiques et le stockage.
Pour plus d’informations, consultez les ressources suivantes :
- Pourquoi deux groupes de ressources sont-ils créés avec AKS ?
- Puis-je nommer mon groupe de ressources de nœud AKS comme je le veux ?
- Puis-je modifier les étiquettes et d’autres propriétés des ressources dans le groupe de ressources de nœud AKS ?
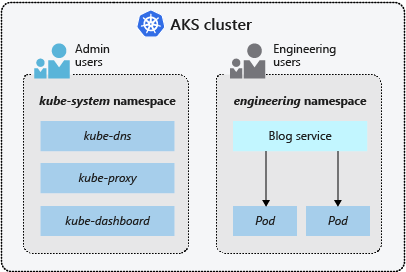
Espaces de noms
Les ressources Kubernetes, comme les pods et les déploiements, sont regroupées logiquement en espaces de noms pour diviser un cluster AKS, et pour créer, visualiser ou gérer l’accès à des ressources.
Les espaces de noms suivants sont créés par défaut dans un cluster AKS :
| Espace de noms | Descriptif |
|---|---|
default |
L’espace de noms par défaut vous permet de commencer à utiliser les ressources de cluster sans créer d’espace de noms. |
kube-node-lease |
L’espace de noms kube-node-lease permet aux nœuds de communiquer leur disponibilité au plan de contrôle. |
kube-public |
L’espace de noms kube-public n’est généralement pas utilisé, mais vous pouvez l’utiliser afin que les ressources soient visibles sur l’ensemble du cluster par n’importe quel utilisateur. |
kube-system |
L’espace de noms kube-system est utilisé par Kubernetes pour gérer les ressources de cluster, telles que coredns, konnectivity-agent et metrics-server. Il n’est pas recommandé de déployer vos propres applications sur cet espace de noms. Dans de rares cas où le déploiement de vos propres applications sur cet espace de noms est nécessaire, consultez le FAQ pour savoir comment procéder. |
Modes de cluster
Dans AKS, vous pouvez créer un cluster avec le mode Automatique ou Standard. AKS Automatic offre une expérience plus complètement managée. Vous pouvez gérer la configuration du cluster, notamment les nœuds, la mise à l’échelle, la sécurité et d’autres paramètres préconfigurés. Le mode Standard AKS offre un plus grand contrôle sur la configuration des clusters, notamment la possibilité de gérer les pools de nœuds, la mise à l’échelle et autres paramètres.
Pour plus d’informations, consultez Comparaison des fonctionnalités AKS Automatique et Standard.
Niveaux de tarification
AKS offre trois niveaux tarifaires pour la gestion des clusters : Gratuit, Standard et Premium. Le niveau tarifaire que vous choisissez détermine les fonctionnalités disponibles pour la gestion de votre cluster.
Pour plus d’informations, consultez Niveaux tarifaires pour la gestion des clusters AKS.
Versions Kubernetes prises en charge
Pour plus d’informations, consultez la section Versions de Kubernetes prises en charge dans AKS.
Contenu connexe
Pour plus d’informations sur les concepts clés d’AKS, consultez les ressources suivantes :