Modèles personnalisés Intelligence documentaire
Important
- Les mises en production de préversion publique Document Intelligence fournissent un accès anticipé aux fonctionnalités en cours de développement actif.
- Les fonctionnalités, approches et processus peuvent changer, avant la disponibilité générale (GA), en fonction des commentaires des utilisateurs.
- La version d'aperçu publique des bibliothèques clientes Document Intelligence est par défaut la version 2024-02-29-preview de l'API REST.
- La version d’évaluation publique 2024-02-29-preview est actuellement disponible uniquement dans les régions Azure suivantes :
- USA Est
- USA Ouest 2
- Europe Ouest
Ce contenu s’applique à :![]() v4.0 (préversion) | Versions précédentes :
v4.0 (préversion) | Versions précédentes :![]() v3.1(GA)
v3.1(GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Ce contenu s’applique à :![]() v3.1 (GA) | Dernière version :
v3.1 (GA) | Dernière version :![]() v4.0 (préversion) | Versions précédentes :
v4.0 (préversion) | Versions précédentes :![]() v3.0
v3.0![]() v2.1
v2.1
Ce contenu s’applique à :![]() v3.0 (GA) | Dernières versions :
v3.0 (GA) | Dernières versions :![]() v4.0 (préversion)
v4.0 (préversion)![]() v3.1 | Version précédente :
v3.1 | Version précédente :![]() v2.1
v2.1
Ce contenu s’applique à :![]() v2.1 | Dernière version :
v2.1 | Dernière version :![]() v4.0 (préversion)
v4.0 (préversion)
Intelligence documentaire utilise une technologie de Machine Learning avancée pour identifier les documents, détecter et extraire des informations de formulaires et de documents et retourner les données extraites dans une sortie JSON structurée. Avec Intelligence documentaire, vous pouvez utiliser des modèles d’analyse de documents, prédéfinis/préentraînés ou vos modèles personnalisés autonomes entraînés.
Les modèles personnalisés incluent désormais des modèles de classification personnalisés pour les scénarios où vous devez identifier le type de document avant d’appeler le modèle d’extraction. Les modèles de classifieur sont disponibles à partir de l’API 2023-07-31 (GA). Un modèle de classification peut être associé à un modèle d’extraction personnalisé pour analyser et extraire des champs de formulaires et de documents spécifiques à votre entreprise pour créer une solution de traitement de documents. Ces modèles personnalisés autonomes peuvent être combinés pour créer des modèles composés.
Types de modèles de document personnalisés
Il existe deux types de modèles de document personnalisés : le modèle personnalisé ou formulaire personnalisé, et le modèle neuronal personnalisé ou modèles de document personnalisés. Le processus d’étiquetage et d’apprentissage est identique pour les deux. Les modèles présentent toutefois plusieurs différences :
Modèles d’extraction personnalisés
Pour créer un modèle d’extraction personnalisé, étiquetez un jeu de données de documents avec les valeurs que vous souhaitez extraire et effectuer l’apprentissage du modèle sur le jeu de données étiqueté. Vous n’avez besoin pour commencer que de cinq exemples du même type de formulaire ou de document.
Modèle neuronal personnalisé
Important
À compter de la version 4.0–2024-02-29-preview de l’API, les modèles neuronaux personnalisés prennent désormais en charge les champs qui se chevauchent, la confiance au niveau de la table, des lignes et des cellules.
Le modèle neural personnalisé (document personnalisé) est des modèles de Deep Learning et un modèle de base dont l’apprentissage est effectué sur un grand nombre de documents. Ce modèle est ensuite affiné ou adapté à vos données lorsque vous effectuez son apprentissage avec un jeu de données étiqueté. Les modèles neuronaux personnalisés prennent en charge les documents structurés, semi-structurés et non structurés pour extraire des champs. Ne sont actuellement acceptés que les documents en langue anglaise. Quand vous choisissez entre les deux types de modèles, commencez avec un modèle neural pour vérifier s’il répond à vos besoins fonctionnels. Pour plus d’informations sur les modèles de documents personnalisés, consultez Modèles neuronaux personnalisés.
Modèle personnalisé
Le modèle personnalisé ou le modèle de formulaire personnalisé s’appuie sur un modèle visuel cohérent pour extraire les données étiquetées. La variance de structure visuelle de vos documents affecte la précision de votre modèle. Les formulaires structurés, comme les questionnaires ou les applications, sont des exemples de modèles visuels cohérents.
Votre jeu d’apprentissage est constitué de documents structurés présentant une mise en forme et une mise en page statiques et constantes d’un document à l’autre. Les modèles personnalisés prennent en charge les paires clé-valeur, les marques de sélection, les tables, les champs de signature et les régions. Le modèle modèle et peut être entraîné sur des documents dans n’importe quel langage pris en charge. Pour plus d’informations, consultezModèles personnalisés.
Si le langage de vos documents et scénarios d’extraction prend en charge les modèles neuronaux personnalisés, nous vous recommandons d’utiliser des modèles neuronaux personnalisés plutôt que des modèles de modèle pour une plus grande précision.
Conseil
Pour vous assurer que vos documents d’apprentissage présentent un modèle visuel cohérent, supprimez toutes les données entrées par l’utilisateur de chacun des formulaires du jeu. Si les formulaires vides ont une apparence identique, ils représentent un modèle visuel cohérent.
Pour plus d’informations, consultezInterprétation et amélioration de l’exactitude et de la confiance des modèles personnalisés.
Critères des entrées
Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Formats de fichiers pris en charge :
Modèle PDF Image :
jpeg/jpg, png, bmp, tiff, heifMicrosoft Office :
Word (docx), Excel (xlsx), PowerPoint (pptx)Lire ✔ ✔ ✔ Layout ✔ ✔ ✔ (Aperçu du 29/02/2024, aperçu du 31/10/2023 et versions ultérieures) Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ ✱ Les fichiers Microsoft Office ne sont actuellement pas pris en charge pour d’autres modèles ou versions.
Pour PDF et TIFF, il est possible de traiter jusqu’à 2000 pages (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse des documents est de 500 Mo pour le niveau payant (S0) et de 4 Mo pour le niveau gratuit (F0).
Les dimensions des images doivent être comprises entre 50 x 50 et 10 000 x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond à environ
8points de texte à 150 points par pouce.Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’entraînement du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle et 1G-Mo pour le modèle neural.
Pour l’entraînement du modèle de classification personnalisée, la taille totale des données de formation est
1GB, avec un maximum à 10 000 pages.
Mode de génération
L’opération de création de modèle personnalisé ajoute la prise en charge des modèles personnalisés de modèle et neuronaux. Les versions précédentes de l’API REST et des bibliothèques clientes prenaient en charge uniquement un mode de génération unique, désormais appelé mode modèle.
Les modèles acceptent uniquement les documents présentant une structure de page globalement similaire (apparence uniforme) ou le même positionnement relatif des éléments dans le document.
Les modèles neuraux prennent en charge des documents qui comportent les mêmes informations, mais des structures de page différentes. Ces documents incluent par exemple les formulaires W2 pour les États-Unis, qui contiennent les mêmes informations mais présentent une apparence différente en fonction de l’entreprise. Actuellement, les modèles neuraux prennent uniquement en charge le texte en anglais.
Ce tableau fournit des liens vers les références du kit SDK du langage de programmation en mode génération et des exemples de code sur GitHub :
| Langage de programmation | Informations de référence sur le SDK | Exemple de code |
|---|---|---|
| C#/.NET | DocumentBuildMode Struct | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode Class | BuildModel.java |
| JavaScript | DocumentBuildMode type | buildModel.js |
| Python | DocumentBuildMode Enum | sample_build_model.py |
Comparer les fonctionnalités du modèle
Le tableau suivant compare les fonctionnalités des modèles personnalisés et celles des modèles neuraux personnalisés :
| Fonctionnalité | Modèle personnalisé (formulaire) | Neuronal personnalisé (document) |
|---|---|---|
| Structure du document | Modèle, formulaire et structuré | Documents structurés, semi-structurés et non structurés |
| Durée d’apprentissage | 1 à 5 minutes | 20 minutes à 1 heure |
| Extraction de données | Paires clé-valeur, tableaux, marques de sélection, coordonnées et signatures | Paires clé-valeur, marques de sélection et tableaux |
| Champs qui se chevauchent | Non pris en charge | Prise en charge |
| Variantes de document | Nécessite un modèle pour chaque variation | Utilise un seul modèle pour toutes les variations |
| Support multilingue | Prise en charge de plusieurs langues | Anglais, avec prise en charge linguistique en préversion de l’espagnol, du français, de l’allemand, de l’italien et du néerlandais |
Modèle de classification personnalisé
La classification de documents est un nouveau scénario pris en charge par Intelligence documentaire avec l’API 2023-07-31 (v3.1 GA). L’API classifieur de document prend en charge les scénarios de classification et de fractionnement. Effectuez l'apprentissage d’un modèle de classification pour identifier les différents types de documents pris en charge par votre application. Le fichier d’entrée du modèle de classification peut contenir plusieurs documents et classifie chaque document dans une plage de pages associée. Pour en savoir plus, consultez Modèles declassification personnalisés.
Remarque
À compter de la version d’API 2024-02-29-preview, la classification des documents prend désormais en charge les types de documents Office pour la classification. Cette version de l’API introduit également un apprentissage incrémentiel pour le modèle de classification.
Outils de modèles personnalisés
Les modèles Intelligence documentaire v3.1 et versions ultérieures prennent en charge les outils, applications, programmes et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle personnalisé | • Document Intelligence Studio • API REST • Kit SDK C# • Kit SDK Python |
custom-model-id |
Intelligence documentaire v2.1 prend en charge les outils, applications et bibliothèques suivants :
Remarque
Les modèles de type neuronal personnalisé et modèle personnalisé sont disponibles avec les API Intelligence documentaire v3.1 et v3.0.
| Fonction | Ressources |
|---|---|
| Modèle personnalisé | • Outil d’étiquetage Intelligence Documentaire • API REST • Kit SDK Bibliothèque de client • Conteneur Docker Intelligence Documentaire |
Créer un modèle personnalisé
Extrayez des données de vos documents spécifiques ou uniques à l’aide de modèles personnalisés. Vous avez besoin des ressources suivantes :
Un abonnement Azure. Vous pouvez en créer un gratuitement.
Instance Intelligence documentaire dans le Portail Azure. Vous pouvez utiliser le niveau tarifaire gratuit (
F0) pour tester le service. Une fois votre ressource déployée, sélectionnez Accéder à la ressource pour accéder à la clé et au point de terminaison.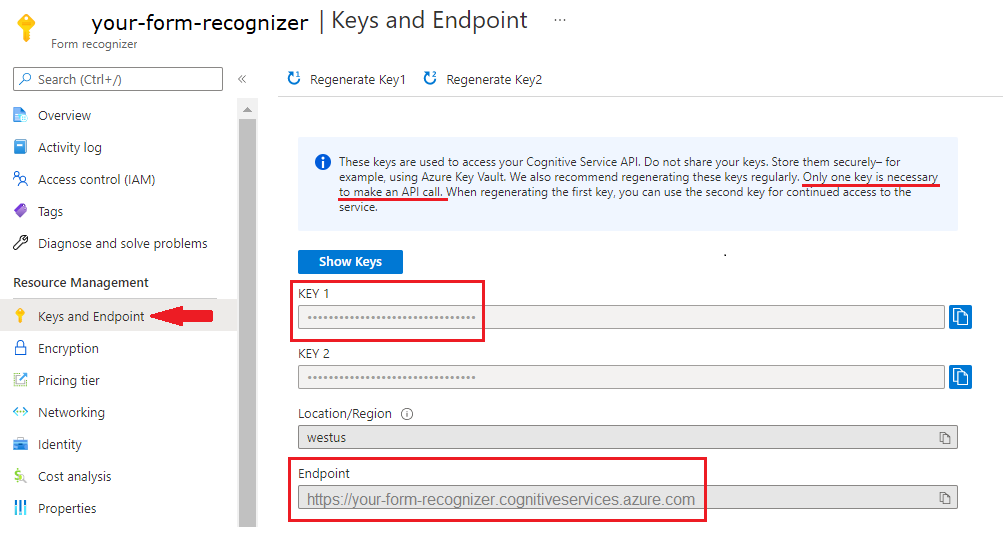
Outil d’étiquetage d’exemples
Conseil
- Pour une expérience améliorée et une qualité de modèle avancée, essayez Studio Intelligence Documentaire v3.0.
- V3.0 Studio prend en charge n’importe quel modèle entraîné avec des données étiquetées v2.1.
- Vous pouvez consulter le guide de migration d’API pour obtenir des informations détaillées sur la migration de v2.1 vers v3.0.
- Consultez nos guides de démarrage rapide sur l’API REST ou sur les SDK C#, Java, JavaScript ou Python pour bien démarrer avec la version v3.0.
L’outil d’étiquetage des exemples Intelligence documentaire est un outil open source qui vous permet de tester les fonctionnalités les plus récentes d’Intelligence documentaire et de reconnaissance optique de caractères (OCR).
Essayez le guide de démarrage rapide de l’outil d’étiquetage des exemples pour commencer à créer et à utiliser un modèle personnalisé.
Document Intelligence Studio
Remarque
Studio Intelligence documentaire est disponible avec les API v3.1 et v3.0.
Sur la page d’accueil de Studio Intelligence documentaire, sélectionnez Modèles d’extraction personnalisés.
Sous Mes projets, sélectionnez Créer un projet.
Renseignez les champs sur les détails du projet.
Configurez la ressource de service en ajoutant votre compte de stockage et votre conteneur d’objets blob dans Connect your training data source (Connecter votre source de données d’entraînement).
Passez en revue et créez votre projet.
Ajoutez vos exemples de documents pour étiqueter, créer et tester votre modèle personnalisé.
Pour obtenir une procédure pas à pas détaillée pour créer votre premier modèle d’extraction personnalisé, consultezComment créer un modèle d’extraction personnalisé.
Résumé de l’extraction du modèle personnalisé
Ce tableau compare les zones d’extraction de données prises en charge :
| Modèle | Champs de formulaire | Marques de sélection | Champs structurés (tableaux) | Signature | Étiquetage de la région | Champs qui se chevauchent |
|---|---|---|---|---|---|---|
| Modèle personnalisé | ✔ | ✔ | ✔ | ✔ | ✔ | n/a |
| Modèle neuronal personnalisé | ✔ | ✔ | ✔ | n/a | * | ✔ (2024-02-29-preview) |
Symboles de tableau :
✔ – pris en charge
**n/a – Actuellement indisponible ;
* – Se comporte différemment selon le modèle. Avec les modèles de modèle, les données synthétiques sont générées au moment de l’entraînement. Avec les modèles neuraux, la sortie du texte reconnu dans la région est sélectionnée.
Conseil
Lorsque vous choisissez entre les deux types de modèles, commencez avec un modèle neuronal personnalisé s’il répond à vos besoins fonctionnels. Pour plus d’informations sur les modèles neuronaux personnalisés, consultez Modèles neuronaux personnalisés.
Options de développement de modèles personnalisés
Le tableau suivant décrit les fonctionnalités disponibles avec les outils et les bibliothèques clientes associés. Nous vous recommandons d’utiliser les outils compatibles qui y figurent.
| Type du document | API REST | Kit SDK | Étiquetage et test des modèles |
|---|---|---|---|
| Modèle personnalisé v4.0 v3.1 v3.0 | Intelligence documentaire 3.1 | Kit de développement logiciel (SDK) Document Intelligence | Document Intelligence Studio |
| Neuronal personnalisé v4.0 v3.1 v3.0 | Intelligence documentaire 3.1 | Kit de développement logiciel (SDK) Document Intelligence | Document Intelligence Studio |
| Formulaire personnalisé v2.1 | API GA Intelligence documentaire 2.1 | Kit de développement logiciel (SDK) Intelligence documentaire | Outil d’étiquetage des exemples |
Remarque
Les modèles personnalisés dont l’apprentissage est effectué avec la version 3.0 de l’API comportent quelques améliorations par rapport à la version 2.1, grâce aux optimisations apportées au moteur d’OCR. Les jeux de données ayant servi à effectuer l’apprentissage d’un modèle personnalisé à l’aide de la version 2.1 de l’API restent utilisables pour l’apprentissage d’un nouveau modèle à l’aide de la version 3.0 de l’API.
Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Les formats de fichier pris en charge sont JPEG/JPG, PNG, BMP, TIFF et PDF (texte incorporé ou numérisé). Les PDF avec du texte incorporé sont préférables pour éviter tout risque d’erreur au niveau de l’extraction et de l’emplacement des caractères.
Pour les fichiers PDF et TIFF, jusqu’à 2 000 pages peuvent être traitées. Avec un abonnement de niveau Gratuit, seules les deux premières pages sont traitées.
La taille du fichier doit être inférieure à 500 Mo pour le niveau payant (S0) et 4 Mo pour le niveau gratuit (F0).
Les dimensions des images doivent être comprises entre 50 x 50 et 10 000 x 10 000 pixels.
Les dimensions des PDF vont jusqu’à 17x17 pouces, ce qui correspond au format papier Legal, A3 ou plus petit.
La taille totale des données d’entraînement doit être de 500 pages maximum.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
Conseil
Données d’entraînement :
- Si possible, utilisez des documents PDF utilisant du texte au lieu d’images. Les fichiers PDF numérisés sont traités comme des images.
- Fournissez une seule instance du formulaire par document.
- Pour les formulaires remplis, utilisez les exemples dont tous les champs sont renseignés.
- Utilisez des formulaires avec des valeurs différentes dans chaque champ.
- Si vos images de formulaire sont de qualité inférieure, utilisez un jeu de données plus volumineux. Par exemple, utilisez 10 à 15 images.
Langues et régions prises en charge
Consultez notre pagemodèles personnalisés - Language Support pour obtenir la liste complète des langages pris en charge.
Étapes suivantes
Essayez de traiter vos propres formulaires et documents avec l’outil d’étiquetage d’échantillons Intelligence Documentaire.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.
Essayez de traiter vos propres formulaires et documents avec Document Intelligence Studio.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.