Modèle de lecture d’Intelligence documentaire
Important
- Les mises en production de préversion publique Document Intelligence fournissent un accès anticipé aux fonctionnalités en cours de développement actif.
- Les fonctionnalités, approches et processus peuvent changer, avant la disponibilité générale (GA), en fonction des commentaires des utilisateurs.
- La version d'aperçu publique des bibliothèques clientes Document Intelligence est par défaut la version 2024-02-29-preview de l'API REST.
- La version d’évaluation publique 2024-02-29-preview est actuellement disponible uniquement dans les régions Azure suivantes :
- USA Est
- USA Ouest 2
- Europe Ouest
Ce contenu s’applique à :![]() v4.0 (préversion) | Versions précédentes :
v4.0 (préversion) | Versions précédentes :![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Ce contenu s’applique à :![]() version 3.1 (GA) | Dernière version :
version 3.1 (GA) | Dernière version :![]() v4.0 (préversion) | Versions précédentes :
v4.0 (préversion) | Versions précédentes :![]() v3.0
v3.0
Ce contenu s’applique à :![]() v3.0 (GA) | Dernières versions :
v3.0 (GA) | Dernières versions :![]() v4.0 (préversion)
v4.0 (préversion)![]() v3.1
v3.1
Remarque
Pour extraire du texte contenu dans des images externes, par exemple des étiquettes, des panneaux de signalisation et des affiches, utilisez la fonctionnalité Lecture de l’analyse d’image Azure AI version 4.0 ; elle est optimisée pour les images générales non liées à des documents et reposant sur une API synchrone aux performances améliorées qui facilite l’incorporation de l’OCR dans vos scénarios d’expérience utilisateur.
Le modèle de reconnaissance optique de caractères (OCR) Document Intelligence Read s'exécute à une résolution supérieure à celle d'Azure AI Vision Read et extrait les textes imprimés et manuscrits des documents PDF et des images numérisées. Il comprend également une prise en charge de l’extraction de texte à partir de documents Microsoft Word, Excel, PowerPoint et HTML. Il détecte les paragraphes, les lignes de texte, les mots, les localisations et les langues. Le modèle de lecture est le moteur d'OCR sous-jacent pour d'autres modèles prédéfinis de Document Intelligence tels que Disposition, Document général, Facture, Reçu, (ID) Document d’identité, Carte d’assurance maladie, W2 ainsi que des modèles personnalisés.
Qu’est-ce que l’OCR pour les documents ?
La reconnaissance optique de caractères (OCR) des documents est optimisée pour les documents volumineux contenant beaucoup de texte dans plusieurs formats de fichiers et langues internationales. Il comprend des fonctionnalités telles que la numérisation à plus haute résolution des images de document pour une meilleure gestion du texte plus petit et dense, la détection de paragraphes et la gestion des formulaires pouvant être remplis. Les fonctionnalités OCR incluent également des scénarios avancés tels que les zones à caractère unique et une extraction précise des champs clés couramment trouvés dans les factures, les reçus et d’autres scénarios prédéfinis.
Options de développement
Intelligence documentaire v4.0 (2024-02-29-preview, 2023-10-31-preview) prend en charge les applications, les bibliothèques et les outils suivants :
| Fonctionnalité | Ressources | ID de modèle |
|---|---|---|
| Modèle de lecture OCR | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-read |
Intelligence documentaire v3.1 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de lecture OCR | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-read |
Intelligence documentaire v3.0 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de lecture OCR | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-read |
Critères des entrées
Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Formats de fichiers pris en charge :
Modèle PDF Image :
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) et HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ (2024-02-29-preview) Pour PDF et TIFF, il est possible de traiter jusqu’à 2 000 pages (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse des documents est de 500 Mo pour le niveau payant (S0) et de 4 Mo pour le niveau gratuit (F0).
Les dimensions des images doivent être comprises entre 50 x 50 et 10 000 x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond à environ
8points de texte à 150 points par pouce (PPP).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’entraînement du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle et 1G-Mo pour le modèle neural.
Pour l’entraînement du modèle de classification personnalisée, la taille totale des données de formation est
1GB, avec un maximum à 10 000 pages.
Bien démarrer avec le modèle Read
Essayez d’extraire du texte à partir des formulaires et des documents à l’aide de Document Intelligence Studio. Vous avez besoin des ressources suivantes :
Un abonnement Azure. Vous pouvez en créer un gratuitement.
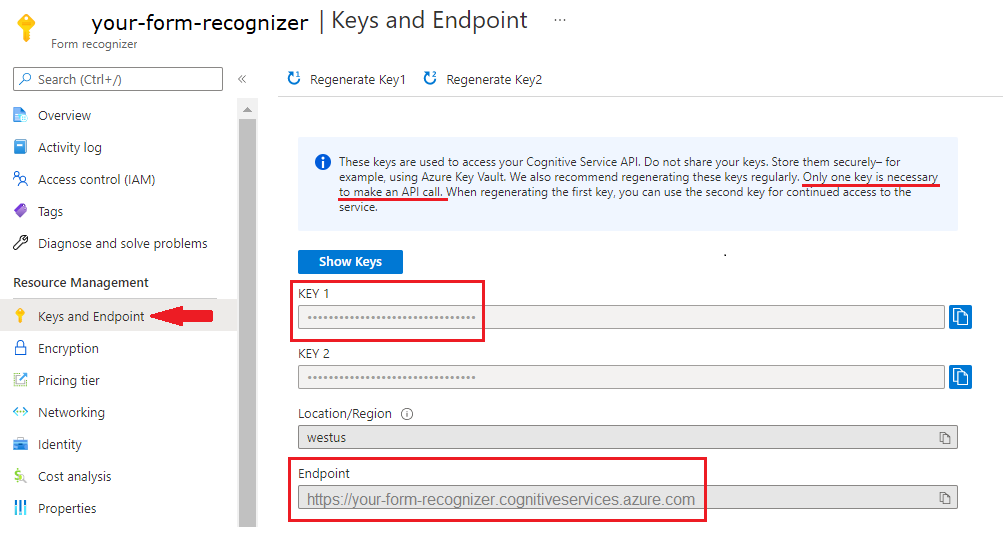
Instance Intelligence documentaire dans le Portail Azure. Vous pouvez utiliser le niveau tarifaire gratuit (
F0) pour tester le service. Une fois votre ressource déployée, sélectionnez Accéder à la ressource pour accéder à la clé et au point de terminaison.
Remarque
Actuellement, Document Intelligence Studio ne prend pas en charge les formats de fichiers Microsoft Word, Excel, PowerPoint et HTML.
Exemple de document traité avec Document Intelligence Studio
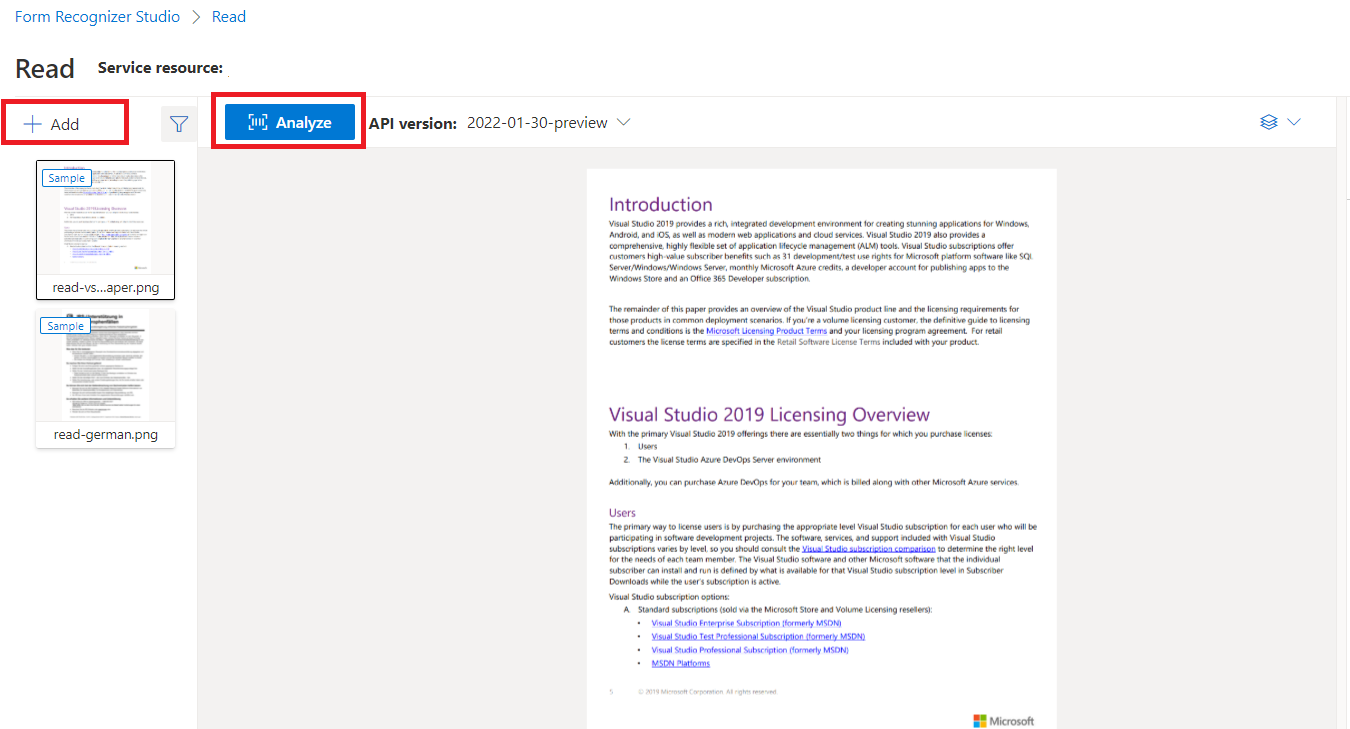
Dans la page d’accueil de Document Intelligence Studio, sélectionnez Read.
Vous pouvez analyser l’exemple de document ou charger vos propres fichiers.
Sélectionnez le bouton Exécuter l’analyse et, si nécessaire, configurez les Options d’analyse :

Langues et régions prises en charge
Pour obtenir la liste complète des langues prises en charge, consultez notre page Support linguistique – Modèles d’analyse de documents.
Extraction de données
Remarque
Les fichiers Microsoft Word et HTML sont pris en charge dans la version 3.1 et les versions ultérieures. Par rapport aux fichiers PDF et aux images, les fonctionnalités ci-dessous ne sont pas prises en charge :
- Il n’existe aucun angle, largeur/hauteur et unité avec chaque objet de page.
- Pour chaque objet détecté, il n’existe aucun polygone englobant ni région englobante.
- La plage de pages (
pages) n’est pas prise en charge en tant que paramètre. - Aucun objet
lines.
Pages
La collection de pages est une liste de pages dans le document. Chaque page est représentée séquentiellement dans le document, et inclut l’angle d’orientation indiquant si la page est pivotée et la largeur et la hauteur (dimensions en pixels). Les unités de page dans la sortie du modèle sont calculées comme indiqué :
| Format de fichier | Unité de page calculée | Nombre total de pages |
|---|---|---|
| Images (JPEG/JPG, PNG, BMP, HEIF) | Chaque image = 1 unité de page | Nombre total d'images |
| Chaque page du PDF = 1 unité de page | Nombre total de pages dans le fichier PDF | |
| TIFF | Chaque image dans le fichier TIFF = 1 unité de page | Nombre total d’images dans le fichier TIFF |
| Word (DOCX) | Jusqu’à 3 000 caractères = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de pages allant jusqu’à 3 000 caractères chacune |
| Excel (XLSX) | Chaque feuille de calcul = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de feuilles de calcul |
| PowerPoint (PPTX) | Chaque diapositive = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de diapositives |
| HTML | Jusqu’à 3 000 caractères = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de pages allant jusqu’à 3 000 caractères chacune |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
Sélectionner des pages pour l’extraction de texte
Pour les documents PDF volumineux comportant plusieurs pages, utilisez le paramètre de requête pages pour indiquer des numéros de page ou des plages de pages spécifiques pour l’extraction de texte.
Paragraphes
Le modèle OCR Read de Document Intelligence extrait tous les blocs de texte identifiés dans la collection paragraphs en tant qu’objet de premier niveau sous analyzeResults. Chaque entrée de cette collection représente un bloc de texte et inclut le texte extrait sous la forme content et les coordonnées polygon limitrophes. Les informations de span pointent vers le fragment de texte de la propriété content de premier niveau contenant le texte intégral du document.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Texte, lignes et mots
Le modèle OCR Read extrait le texte imprimé et manuscrit sous forme de lines et de words. Le modèle génère des coordonnées englobantes polygon et confidence pour les mots extraits. La collection styles inclut tout style manuscrit pour les lignes détectées, ainsi que les étendues pointant vers le texte associé. Cette fonctionnalité s’applique aux langues manuscrites prises en charge.
Pour Microsoft Word, Excel, PowerPoint et HTML, le modèle Read d’Intelligence documentaire version 3.1 et versions ultérieures extrait tout le texte incorporé tel quel. Les textes sont extraits sous forme de mots et de paragraphes. Les images incorporées ne sont pas prises en charge.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Style manuscrit des lignes de texte
La réponse inclut le classement de chaque ligne de texte selon qu’elle est de style manuscrit ou non, avec un score de confiance. Pour plus d’informations, consultezPrise en charge des langues manuscrites. L’exemple suivant montre un exemple d’extrait JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Si vous avez activé la fonctionnalité de complément de police/style, vous obtenez également le résultat de police/style dans le cadre de l’objet styles.
Étapes suivantes
Suivez un guide de démarrage rapide Document Intelligence :
Découvrir notre API REST :