Effectuer l’apprentissage d’un modèle personnalisé à l’aide de l’exemple d’outil d’étiquetage
Ce contenu s’applique à :![]() v2.1.
v2.1.
Conseil
- Pour une expérience améliorée et une qualité de modèle avancée, essayez Studio Intelligence Documentaire v3.0.
- V3.0 Studio prend en charge n’importe quel modèle entraîné avec des données étiquetées v2.1.
- Vous pouvez consulter le guide de migration d’API pour obtenir des informations détaillées sur la migration de v2.1 vers v3.0.
- Consultez nos guides de démarrage rapide sur l’API REST ou sur les SDK C#, Java, JavaScript ou Python pour bien démarrer avec la version v3.0.
Dans cet article, vous allez utiliser l’API REST d’Intelligence documentaire avec l’outil d’étiquetage des exemples afin d’effectuer l’apprentissage d’un modèle personnalisé avec des données étiquetées manuellement.
Prérequis
Vous allez avoir besoin des ressources suivantes pour exécuter ce projet :
- Abonnement Azure - En créer un gratuitement
- Une fois que vous disposez de votre abonnement Azure, créez une ressource Intelligence documentaire dans le portail Azure pour obtenir votre clé et votre point de terminaison. À la fin du déploiement, sélectionnez Accéder à la ressource.
- Vous avez besoin de la clé et du point de terminaison de la ressource que vous créez pour connecter votre application à l’API Azure AI Intelligence documentaire. Vous insérez votre clé et votre point de terminaison dans le code plus loin dans ce guide de démarrage rapide.
- Vous pouvez utiliser le niveau tarifaire Gratuit (
F0) pour tester le service, puis passer par la suite à un niveau payant pour la production.
- Au minimum un ensemble de six formulaires du même type. Vous allez utiliser ces données pour entraîner le modèle et tester un formulaire. Pour ce guide de démarrage rapide, vous pouvez utiliser un exemple de jeu de données (téléchargez et extrayez sample_data.zip). Chargez les fichiers d’apprentissage à la racine d’un conteneur de stockage d’objets blob dans un compte Stockage Azure offrant un niveau de performance standard.
Créer une ressource Document Intelligence
Accédez au portail Azure et créer une nouvelle ressource Document Intelligence. Dans le volet Créer, indiquez les informations suivantes :
| Détails du projet | Description |
|---|---|
| Abonnement | Sélectionnez l’abonnement Azure auquel l’accès a été accordé. |
| Groupe de ressources | Groupe de ressources Azure qui contient votre ressource. Vous pouvez créer un groupe ou l’ajouter à un groupe préexistant. |
| Région | L’emplacement de votre ressource Azure AI Services. Des emplacements différents peuvent entraîner une latence. Toutefois, cela n’aura pas d’impact sur la disponibilité d’exécution de votre ressource. |
| Nom | Nom descriptif de votre ressource. Nous recommandons d’utiliser un nom explicite, par exemple MyNameFormRecognizer. |
| Niveau tarifaire | Le coût de la ressource dépend du niveau tarifaire que vous choisissez et de votre utilisation. Pour plus d'informations, consultez le détail des tarifs de l’API. |
| Vérifier + créer | Sélectionnez le bouton Vérifier + créer pour déployer votre ressource sur le portail Azure. |
Récupérer la clé et le point de terminaison
Lorsque le déploiement de la ressource Document Intelligence se termine, recherchez-la et sélectionnez-la dans la liste Toutes les ressources dans le portail. Votre clé et votre point de terminaison se trouvent dans la page Clé et point de terminaison de la ressource, sous Gestion des ressources. Enregistrez ces deux éléments à un emplacement temporaire avant de continuer.
Faire un essai
Essayez l’outil d’étiquetage des exemples Intelligence documentaire en ligne :
Il vous faut un abonnement Azure (en créer un gratuitement), un point de terminaison de ressource Intelligence documentaire et une clé pour essayer le service Intelligence documentaire.
Configurer l’outil d’étiquetage des exemples
Remarque
Si vos données de stockage se trouvent derrière un réseau virtuel ou un pare-feu, vous devez déployer l’outil d’étiquetage d’exemples Intelligence documentaire derrière votre réseau virtuel ou votre pare-feu, et lui accorder l’accès en créant une identité managée affectée par le système.
Vous allez utiliser le moteur Docker pour exécuter l’outil d’étiquetage des exemples. Procédez comme suit pour configurer le conteneur Docker. Pour apprendre les principes de base de Docker et des conteneurs, consultez la vue d’ensemble de Docker.
Conseil
OCR Form Labeling Tool est également disponible en tant que projet open source sur GitHub. L’outil est une application web TypeScript créée à l’aide de React + Redux. Pour en savoir plus ou apporter votre contribution, consultez le dépôt OCR Form Labeling Tool. Pour essayer cet outil en ligne, accédez au site web de l’outil d’étiquetage des exemples Intelligence documentaire.
Tout d’abord, installez Docker sur un ordinateur hôte. Ce guide vous montre comment utiliser un ordinateur local en tant qu’hôte. Si vous voulez utiliser un service d’hébergement Docker dans Azure, consultez le guide pratique Déployer l’outil d’étiquetage des exemples.
L’ordinateur hôte doit satisfaire à la configuration matérielle suivante :
Conteneur Minimum Recommandé Outil d’étiquetage d’exemples 2cœurs, 4 Go de mémoire4cœurs, 8 Go de mémoireInstallez Docker sur votre ordinateur en suivant les instructions appropriées pour votre système d’exploitation :
Récupérez le conteneur de l’outil d’étiquetage des exemples avec la commande
docker pull.docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1Vous êtes maintenant prêt à exécuter le conteneur avec
docker run.docker run -it -p 3000:80 mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1 eula=acceptCette commande rend l’outil d’étiquetage des exemples disponible à partir d'un navigateur web. Atteindre
http://localhost:3000.
Remarque
Vous pouvez également étiqueter des documents et entraîner des modèles à l’aide de l’API REST Intelligence documentaire. Pour effectuer un entraînement et une analyse avec l’API REST, consultez Entraîner avec des étiquettes en utilisant l’API REST et Python.
Configurer les données d’entrée
Tout d’abord, vérifiez que tous les documents d’entraînement ont le même format. Si vous avez des formulaires dans plusieurs formats, organisez-les en sous-dossiers en fonction du format. Pendant l’entraînement, vous devez diriger l’API vers un sous-dossier.
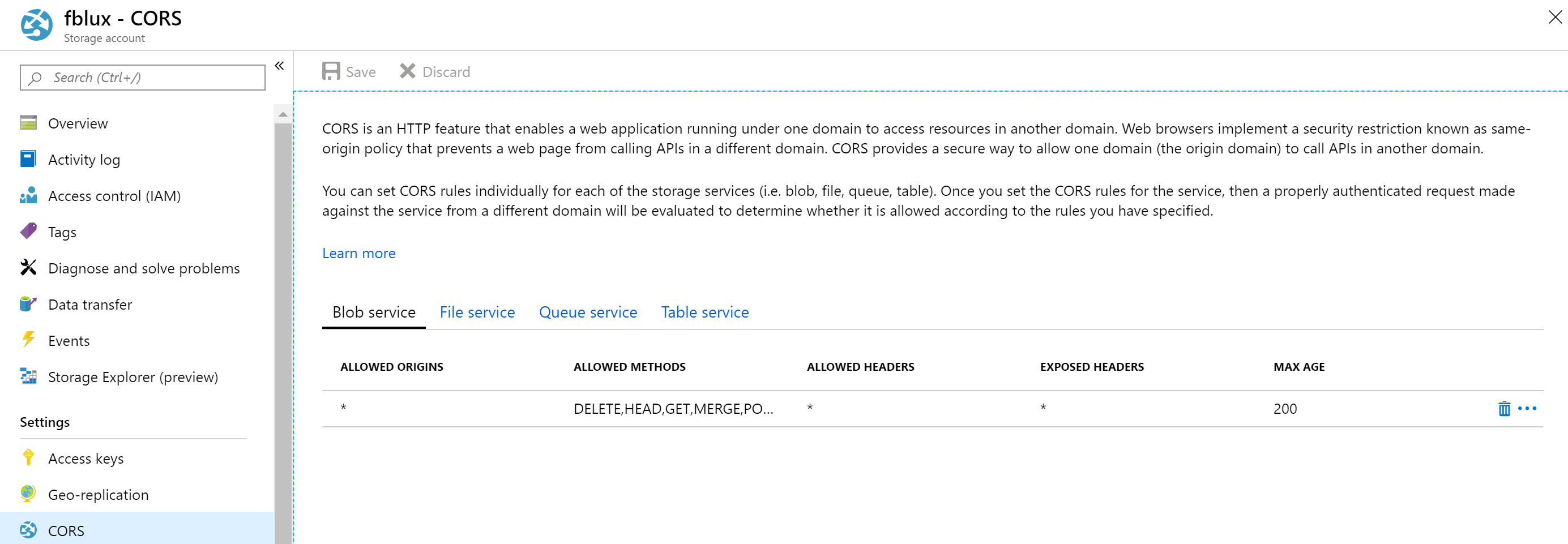
Configurer le partage des ressources inter-domaines (CORS)
Activez CORS sur votre compte de stockage. Sélectionnez votre compte de stockage dans le portail Azure, puis choisissez l’onglet CORS dans le volet gauche. Sur la ligne inférieure, renseignez les valeurs suivantes. Sélectionnez Enregistrer en haut.
- Origines autorisées = *
- Méthodes autorisées = [tout sélectionner]
- En-têtes autorisés = *
- En-têtes exposés = *
- Âge maximal = 200
Se connecter à l’outil d’étiquetage des exemples
L’outil d’étiquetage des exemples se connecte à une source (vos formulaires chargés d’origine) et à une cible (données de sortie et étiquettes créées).
Les connexions peuvent être configurées et partagées entre les projets. Elles utilisent un modèle de fournisseur extensible, ce qui vous permet d’ajouter facilement de nouveaux fournisseurs sources/cibles.
Pour créer une connexion, sélectionnez l’icône Nouvelles connexions (fiche électrique) dans la barre de navigation gauche.
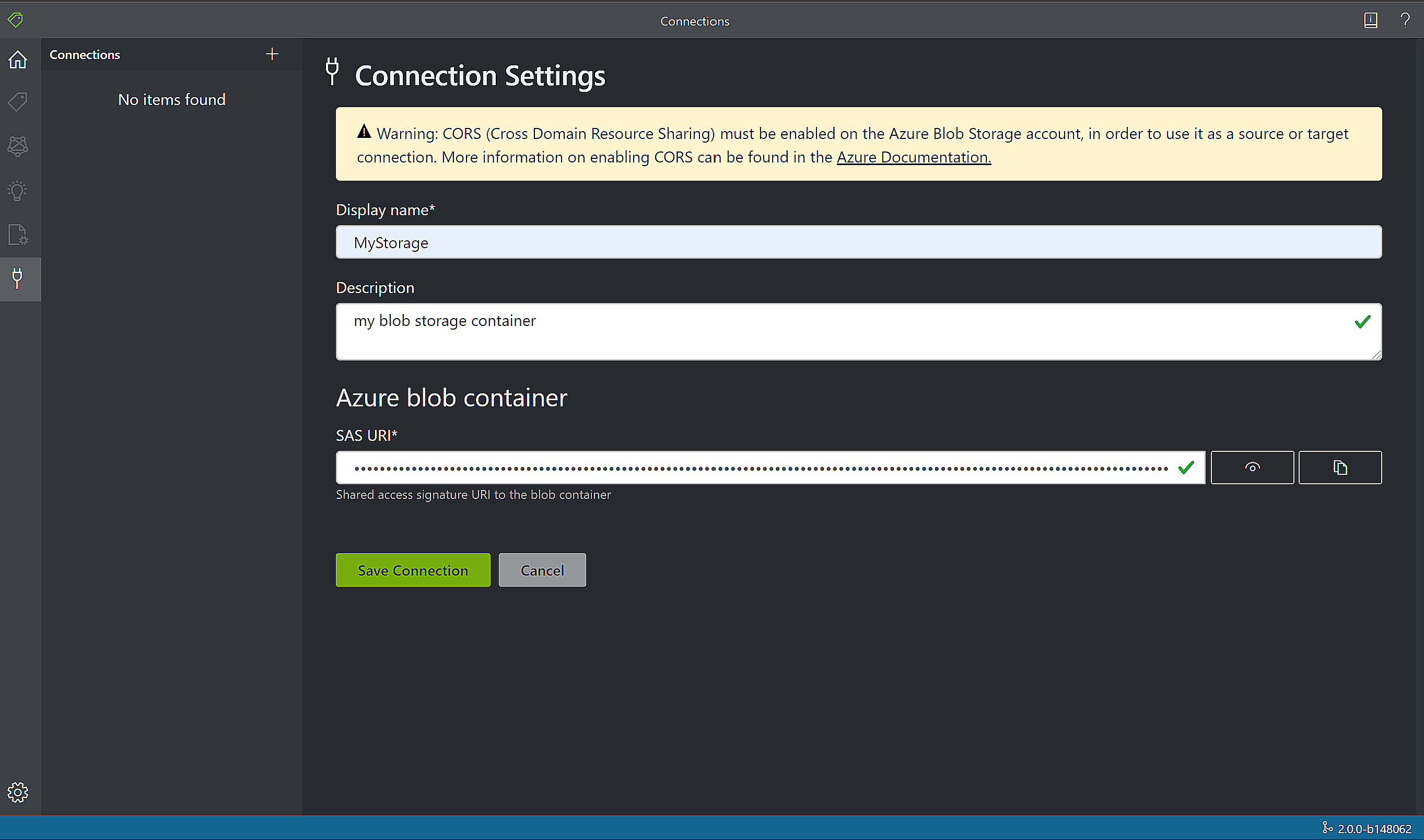
Renseignez les champs avec les valeurs suivantes :
Display Name (nom d’affichage) : nom d’affichage de la connexion.
Description : description de votre projet.
SAS URL (URL SAS) : URL de signature d’accès partagé (SAS) de votre conteneur Stockage Blob Azure. Si vous souhaitez récupérer l’URL SAS pour vos données d’entraînement de modèle personnalisé, accédez à votre ressource de stockage dans le portail Azure, puis sélectionnez l’onglet Explorateur Stockage. Accédez à votre conteneur, cliquez avec le bouton droit, puis sélectionnez Obtenir une signature d’accès partagé. Il est important d’obtenir la signature d’accès partagé de votre conteneur, et non celle du compte de stockage. Vérifiez que les autorisations de lecture, d’écriture, de suppression et de liste sont cochées, puis cliquez sur Créer. Copiez ensuite la valeur de la section URL dans un emplacement temporaire. Il doit avoir le format :
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>.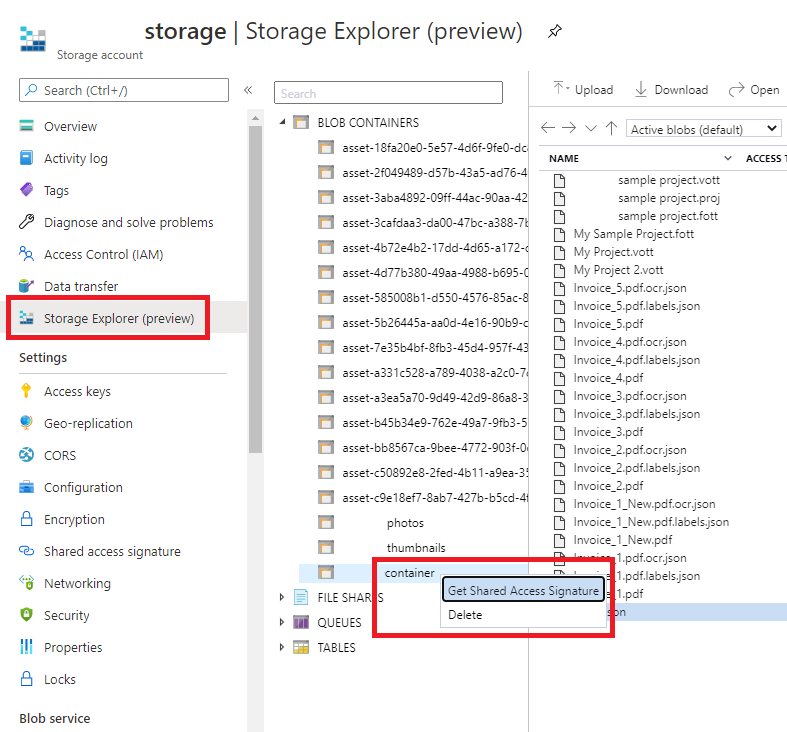
Création d'un projet
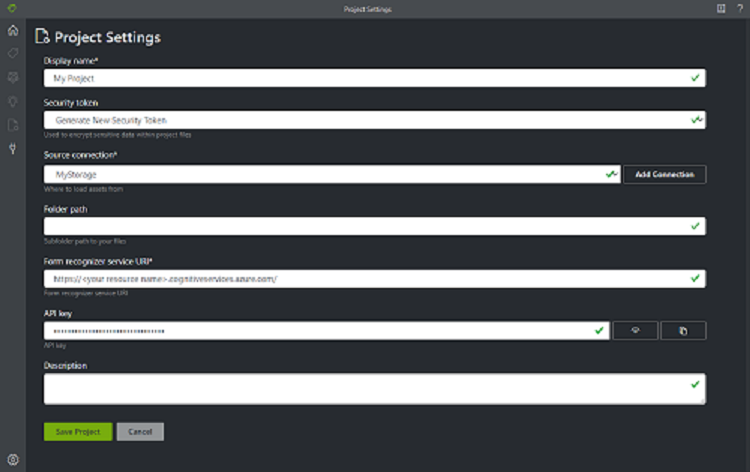
Dans l’outil d’étiquetage des exemples, les projets stockent vos configurations et paramètres. Créez un projet et renseignez les champs avec les valeurs suivantes :
- Display Name (Nom d’affichage) : nom d’affichage du projet
- Security Token (Jeton de sécurité) : certains paramètres de projet peuvent inclure des valeurs sensibles, telles que des clés ou d’autres secrets partagés. Chaque projet génère un jeton de sécurité pouvant servir à chiffrer/déchiffrer les paramètres sensibles du projet. Vous pouvez accéder aux jetons de sécurité dans les paramètres de l’application, en sélectionnant l’icône d’engrenage en bas de la barre de navigation gauche.
- Source Connection (Connexion source) : connexion au Stockage Blob Azure que vous avez créée à l’étape précédente et que vous souhaitez utiliser pour ce projet.
- Folder Path (Chemin du dossier) : (facultatif) Si vos formulaires sources se trouvent dans un dossier sur le conteneur d’objets blob, spécifiez le nom du dossier ici.
- URI du service Document Intelligence : URL de votre point de terminaison Document Intelligence.
- Clé – Votre clé Intelligence documentaire.
- Description : (facultatif) Description du projet
Étiqueter vos formulaires
Quand vous créez ou ouvrez un projet, la fenêtre principale de l’éditeur d’étiquettes s’ouvre. L’éditeur d’étiquettes est composé de trois parties :
- Un volet v3.0 redimensionnable, qui contient une liste déroulante de formulaires de la connexion source.
- Le volet principal de l’éditeur, qui vous permet d’appliquer des étiquettes.
- Le volet de l’éditeur d’étiquettes, qui permet aux utilisateurs de modifier, de verrouiller, de réorganiser et de supprimer des étiquettes.
Identifier du texte et des tables
Sélectionnez Run Layout on unvisited documents (Exécuter Disposition sur les fichiers non visités) dans le volet gauche pour obtenir les informations sur la disposition du texte et des tables pour chaque document. L’outil d’étiquetage dessine des rectangles englobants autour de chaque élément texte.
L’outil d’étiquetage indique également les tables ayant été automatiquement extraites. Sélectionnez l’icône de table/grille à gauche du document pour voir la table extraite. Dans ce démarrage rapide, le contenu des tables étant automatiquement extrait, nous ne procédons pas à l’étiquetage du contenu des tables et faisons confiance à l’extraction automatisée.
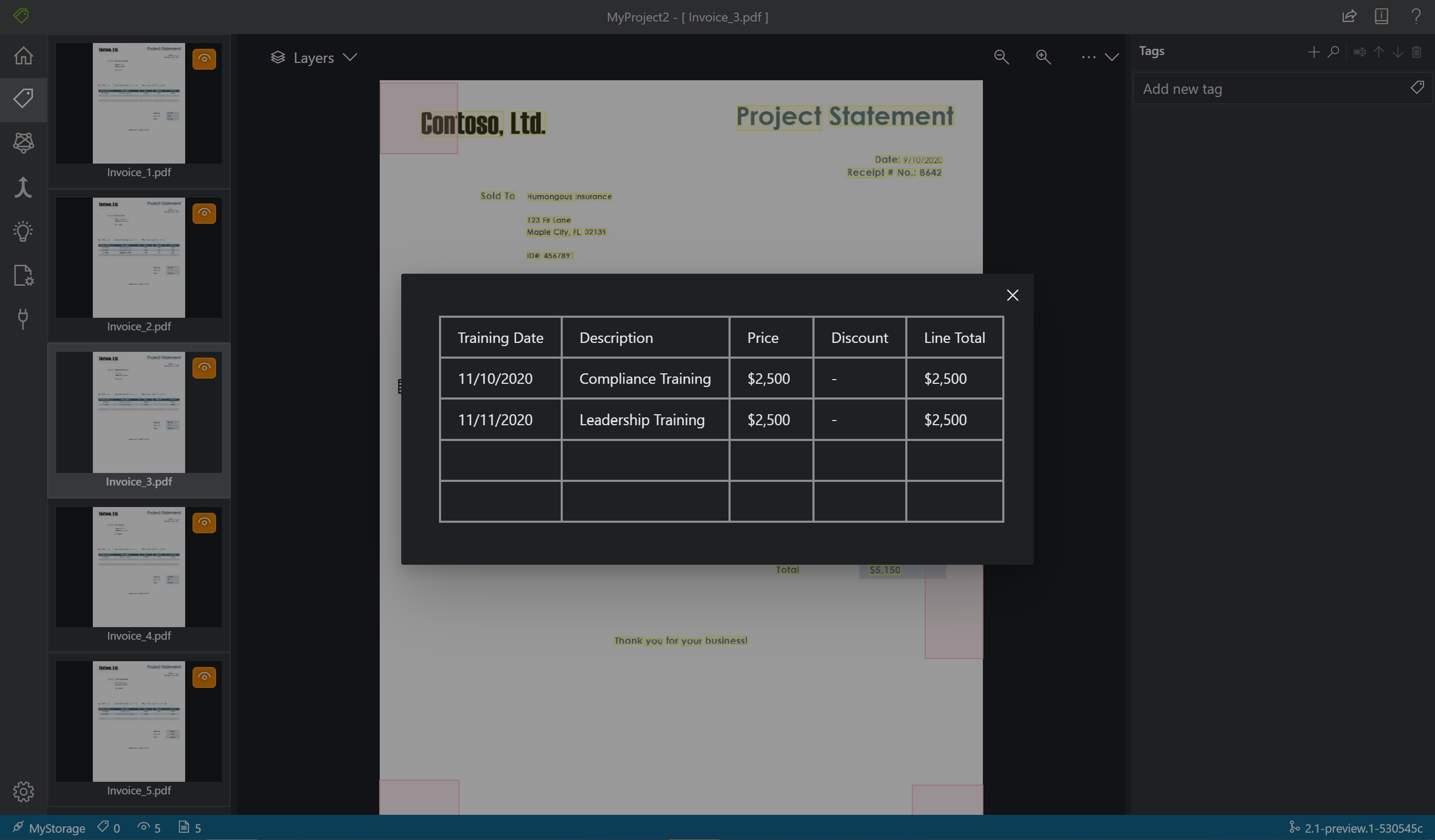
Dans v2.1, si votre document d’entraînement n’a pas de valeur renseignée, vous pouvez dessiner une zone là où la valeur devrait être. Utilisez la zone de dessin située dans le coin supérieur gauche de la fenêtre pour rendre la région étiquetable.
Appliquer des étiquettes à du texte
Vous allez ensuite créer des balises (étiquettes) et les appliquer aux éléments texte que vous souhaitez faire analyser par le modèle.
- Tout d’abord, utilisez le volet de l’éditeur d’étiquettes pour créer les étiquettes que vous souhaitez identifier.
- Sélectionnez + pour créer une étiquette.
- Entrez le nom de l’étiquette.
- Appuyez sur Entrée pour enregistrer l’étiquette.
- Dans l’éditeur principal, sélectionnez des mots parmi les éléments de texte en surbrillance ou dans une région que vous avez dessinée.
- Sélectionnez l’étiquette que vous souhaitez appliquer, ou appuyez sur la touche du clavier correspondante. Les touches numériques sont affectées comme touches d’accès rapide pour les 10 premières étiquettes. Vous pouvez réorganiser vos étiquettes à l’aide des icônes de flèches haut et bas dans le volet de l’éditeur d’étiquettes.
- Procédez comme suit pour étiqueter au moins cinq de vos formulaires.
Conseil
Gardez à l’esprit les conseils suivants quand vous étiquetez vos formulaires :
- Vous ne pouvez appliquer qu’une seule étiquette à chaque élément de texte sélectionné.
- Chaque étiquette ne peut être appliquée qu’une seule fois par page. Si une valeur apparaît plusieurs fois sur le même formulaire, créez des étiquettes différentes pour chaque instance, par exemple « facture n° 1 », « facture n° 2 », etc.
- Les étiquettes ne peuvent pas s’étendre sur plusieurs pages.
- Étiquetez les valeurs telles qu’elles apparaissent sur le formulaire ; n’essayez pas de fractionner une valeur en deux parties avec deux étiquettes différentes. Par exemple, un champ d’adresse doit être étiqueté avec une étiquette unique, même s’il s’étend sur plusieurs lignes.
- N’incluez pas de clés dans vos champs étiquetés, uniquement les valeurs.
- Les données de la table doivent être détectées automatiquement et seront disponibles dans le fichier JSON de sortie final. Toutefois, si le modèle ne parvient pas à détecter toutes les données de votre table, vous pouvez aussi étiqueter manuellement ces champs. Étiquetez chaque cellule de la table avec une étiquette différente. Si vos formulaires comportent des tables avec un nombre variable de lignes, veillez à étiqueter au moins un formulaire avec la table la plus grande possible.
- Servez-vous des boutons situés à droite de + pour rechercher, renommer, réorganiser et supprimer vos étiquettes.
- Pour supprimer une étiquette appliquée sans supprimer l’étiquette proprement dite, sélectionne lez rectangle étiqueté dans la vue du document et appuyez sur la touche de suppression.
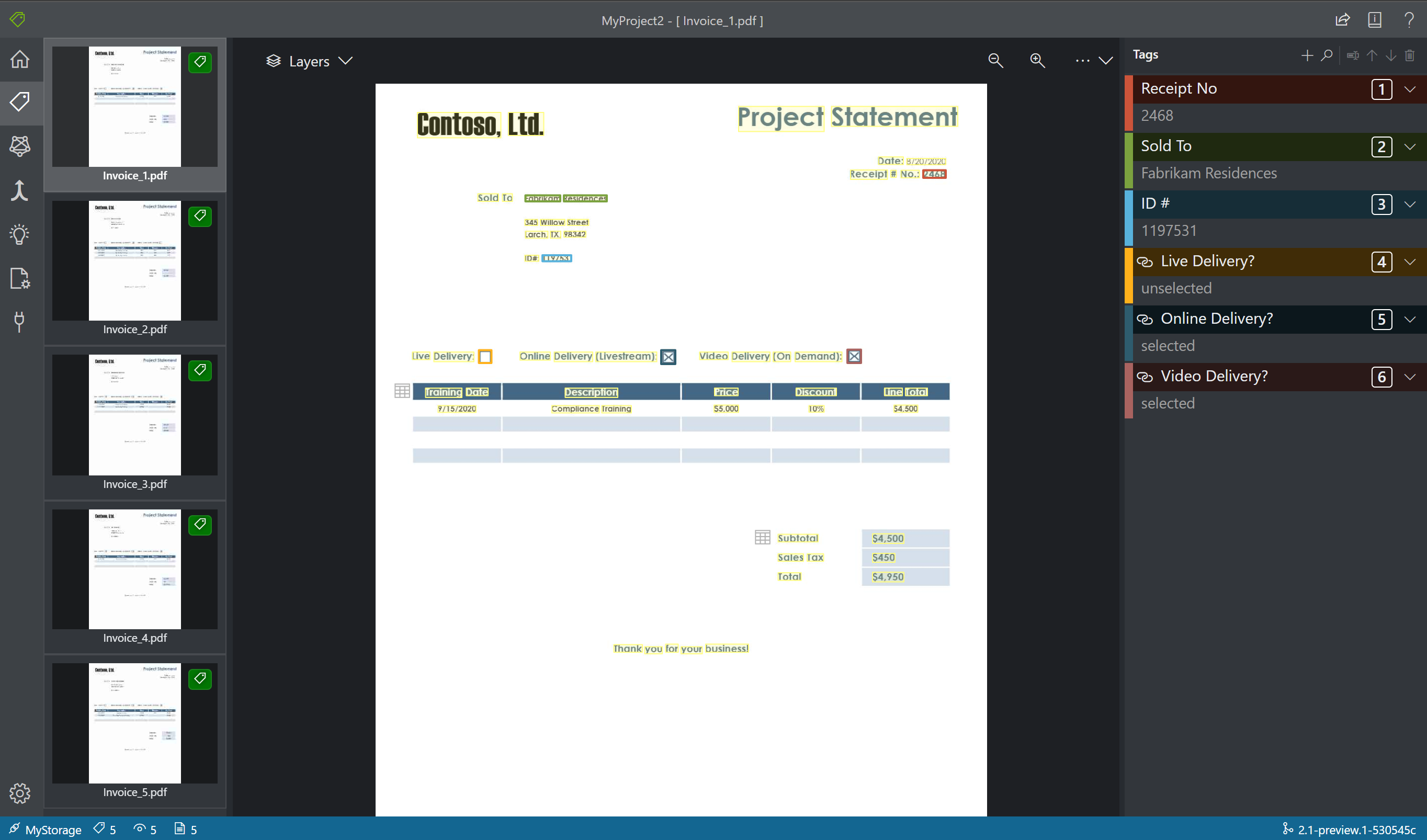
Spécifier des types de valeurs d’étiquettes
Vous pouvez définir le type de données attendu pour chaque étiquette. Ouvrez le menu contextuel à droite d’une étiquette et sélectionnez un type dans le menu. Cette fonctionnalité permet à l’algorithme de détection d’effectuer des hypothèses qui vont améliorer la justesse de la détection de texte. Elle garantit aussi le retour des valeurs détectées dans un format normalisé dans la sortie JSON finale. Les informations sur le type de valeur sont enregistrées dans le fichier fields.json sous le même chemin que vos fichiers d’étiquette.
Les types et variantes de valeurs suivants sont actuellement pris en charge :
string- default,
no-whitespaces,alphanumeric
- default,
number- default,
currency - Mise en forme en tant que valeur à virgule flottante.
- Exemple : 1234,98 dans le document sera sous la forme 1234.98 à la sortie
- default,
date- default,
dmy,mdy,ymd
- default,
timeinteger- Mise en forme sous forme de valeur entière.
- Exemple : 1234,98 dans le document sera sous la forme 123498 à la sortie.
selectionMark
Notes
Consultez les règles suivantes pour la mise en forme des dates :
Vous devez spécifier un format (dmy, mdy, ymd) pour le fonctionnement de la mise en forme de la date.
Les caractères suivants peuvent être utilisés comme délimiteurs de date : , - / . \. L’espace blanc ne peut pas être utilisé comme délimiteur. Par exemple :
- 01,01,2020
- 01-01-2020
- 01/01/2020
Le jour et le mois peuvent chacun être écrits avec un ou deux chiffres, et l’année peut être deux ou quatre chiffres :
- 1-1-2020
- 1-01-20
Si une chaîne de date comporte huit chiffres, le délimiteur est facultatif :
- 01012020
- 01 01 2020
Le mois peut également être écrit avec son nom complet ou abrégé. Si le nom est utilisé, les caractères du délimiteur sont facultatifs. Cependant, ce format peut être reconnu comme moins précis que les autres.
- 01/Jan/2020
- 01Jan2020
- 01 Jan 2020
Étiqueter des tables (v2.1 uniquement)
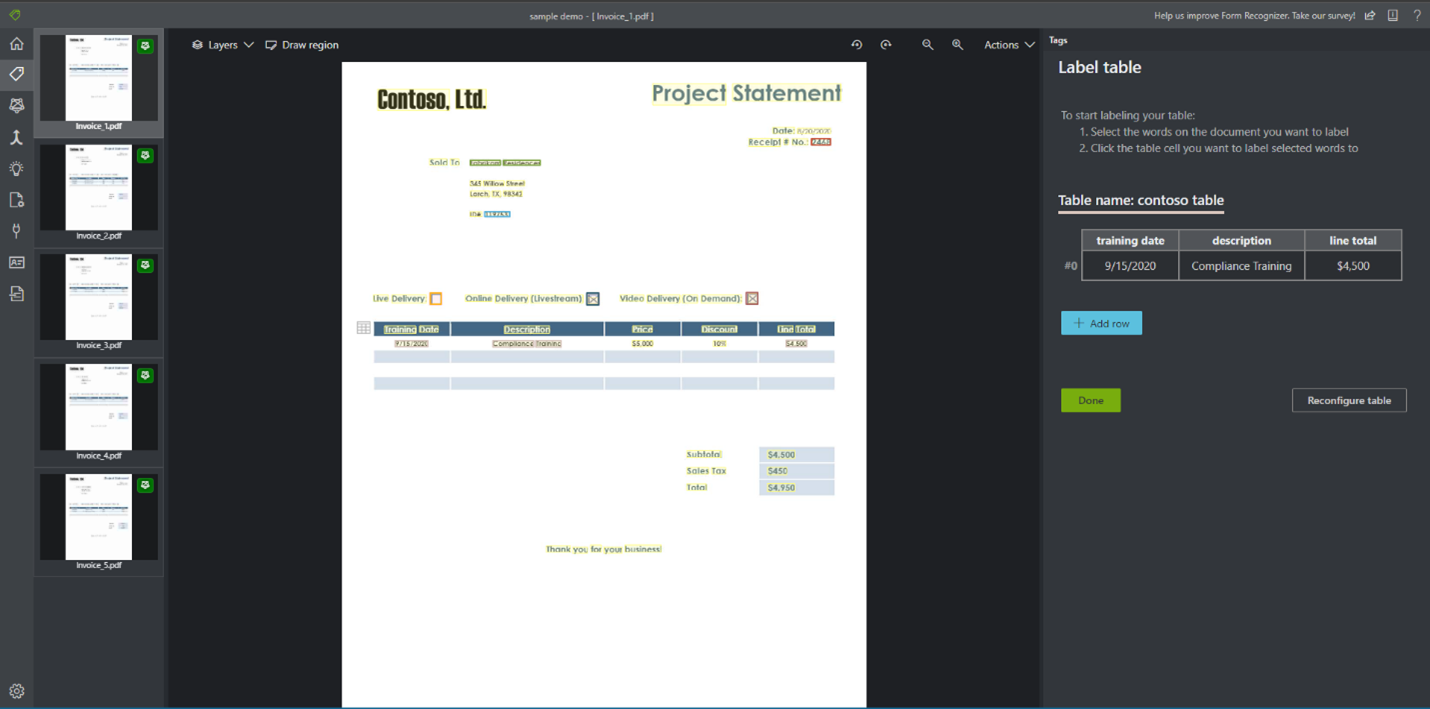
Il peut arriver que vos données se prêtent mieux à un étiquetage en tant que table plutôt que paires clé-valeur. Dans ce cas, vous pouvez créer une étiquette de table en sélectionnant Ajouter une étiquette de table. Indiquez si la table va avoir un nombre fixe ou variable de lignes en fonction du document et définissez le schéma.
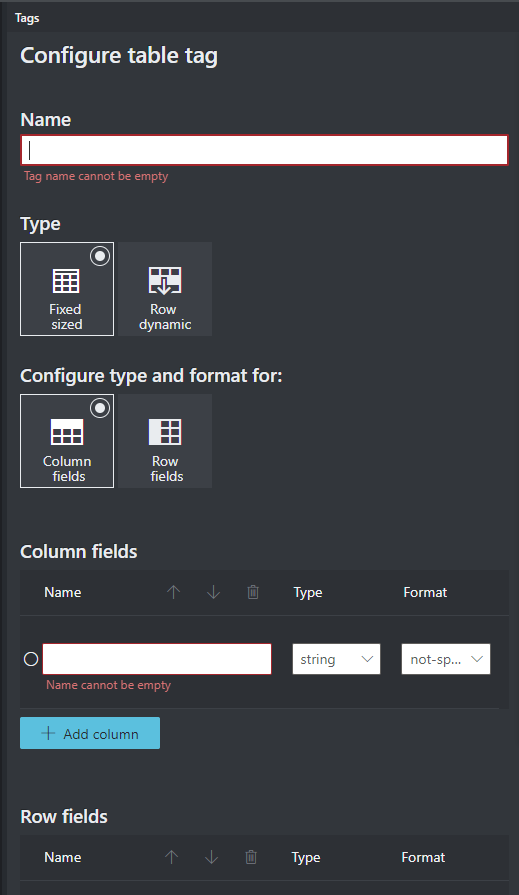
Une fois que vous avez défini votre étiquette de table, étiquetez les valeurs de cellules.
Entraîner un modèle personnalisé
Choisissez l’icône d’entraînement dans le volet gauche pour ouvrir la page Training (Entraînement). Sélectionnez ensuite le bouton Train pour commencer l’entraînement du modèle. Une fois le processus d’entraînement terminé, les informations suivantes s’affichent :
- Model ID : ID du modèle qui a été créé et entraîné. Chaque appel d’entraînement crée un modèle avec son propre ID. Copiez cette chaîne dans un emplacement sécurisé. Vous allez en avoir besoin si vous voulez effectuer des appels de prédiction par le biais de l’API REST ou du guide de la bibliothèque du client.
- Average Accuracy : justesse moyenne du modèle. Vous pouvez améliorer la précision du modèle en ajoutant et en étiquetant davantage de formulaires, puis en procédant à une nouvelle formation pour créer un nouveau modèle. Nous vous recommandons de commencer par étiqueter cinq formulaires et d’ajouter des formulaires en fonction des besoins.
- Liste des étiquettes et justesse estimée par étiquette.
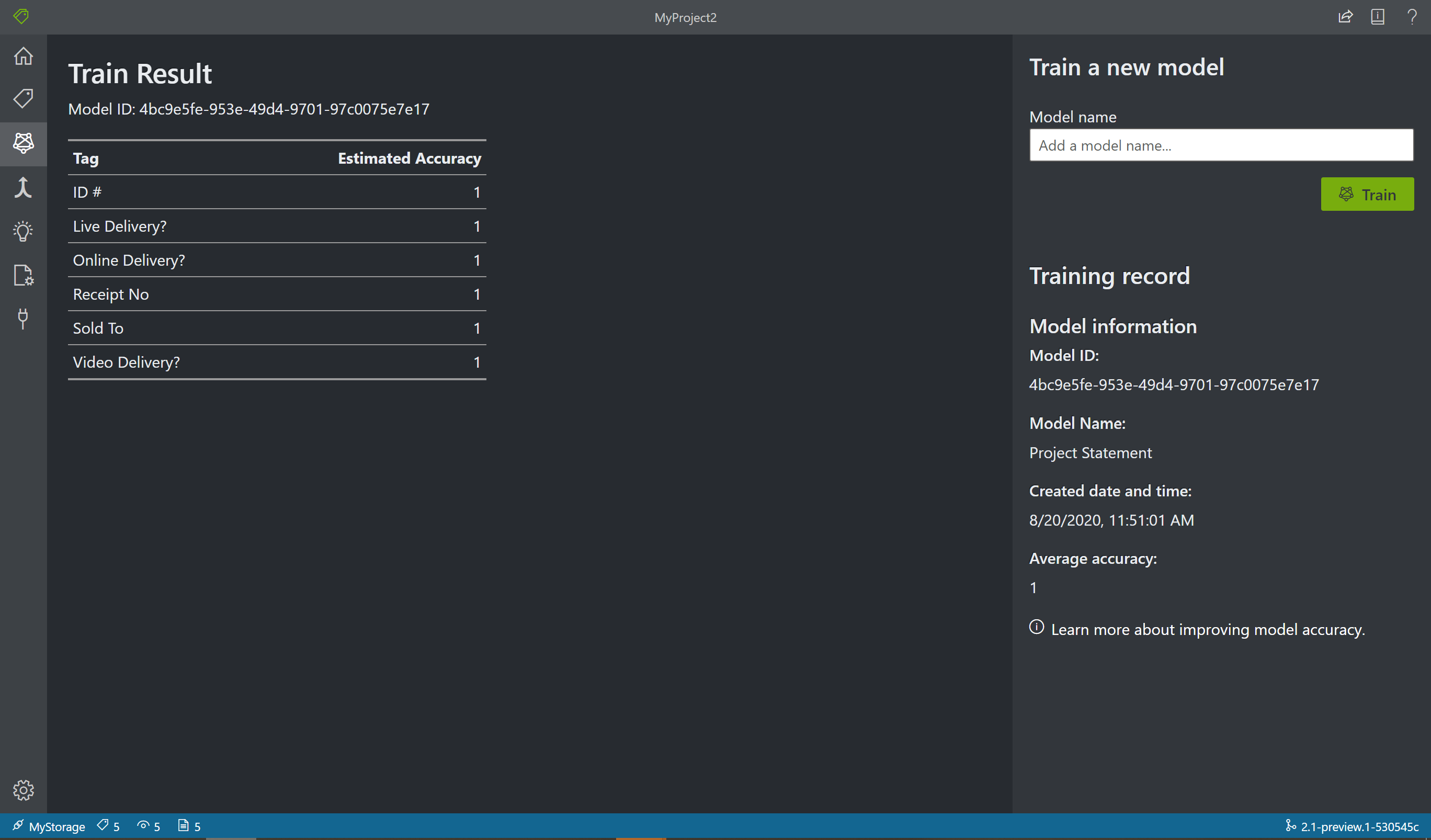
Une fois l’entraînement terminé, examinez la valeur Average Accuracy. Si cette valeur est basse, vous devez ajouter d’autres documents d’entrée et répéter les étapes d’étiquetage. Les documents que vous avez déjà étiquetés sont conservés dans l’index du projet.
Conseil
Vous pouvez également exécuter le processus d’entraînement avec un appel d’API REST. Pour savoir comment procéder, consultez Effectuer un entraînement avec des étiquettes à l’aide de Python.
Composer des modèles entraînés
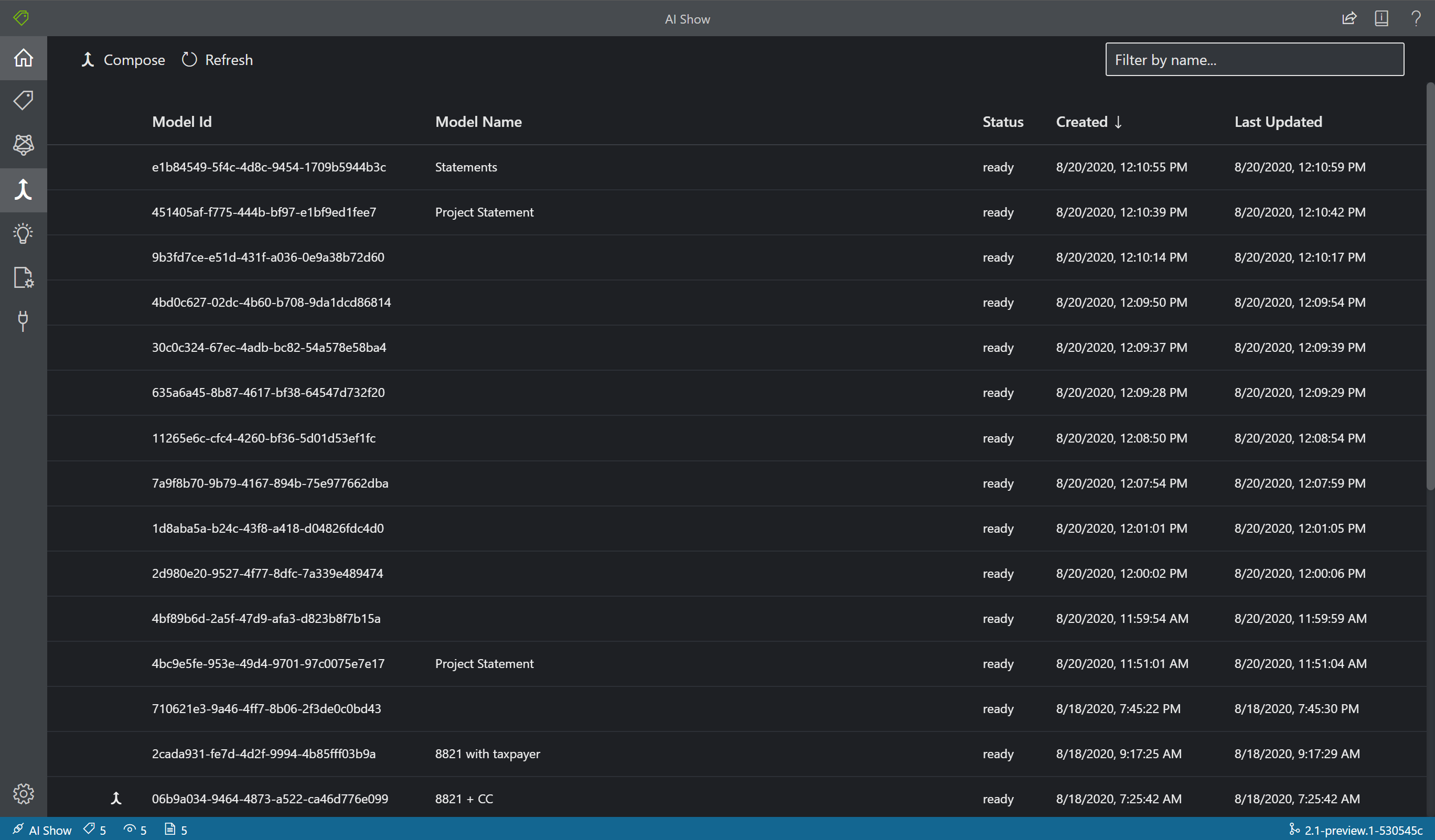
Avec Model Compose (Composition de modèles), vous pouvez composer jusqu’à 200 modèles pour un ID de modèle unique. Quand vous appelez la fonction d’analyse avec le modelID composé, Intelligence documentaire classifie d’abord le formulaire soumis, choisit le modèle correspondant le mieux, puis retourne les résultats pour ce modèle. Cette opération est utile quand les formulaires entrants sont susceptibles d’appartenir à l’un des différents modèles.
- Pour composer des modèles dans l’outil d’étiquetage des exemples, sélectionnez l’icône Composition du modèle (flèche de fusion) dans la barre de navigation.
- Sélectionnez les modèles que vous souhaitez composer conjointement. Les modèles présentant une icône de flèche sont déjà des modèles composés.
- Choisissez le bouton Compose. Dans la fenêtre contextuelle, nommez votre nouveau modèle composé, puis sélectionnez Compose.
- Une fois l’opération terminée, le nouveau modèle composé doit apparaître dans la liste.
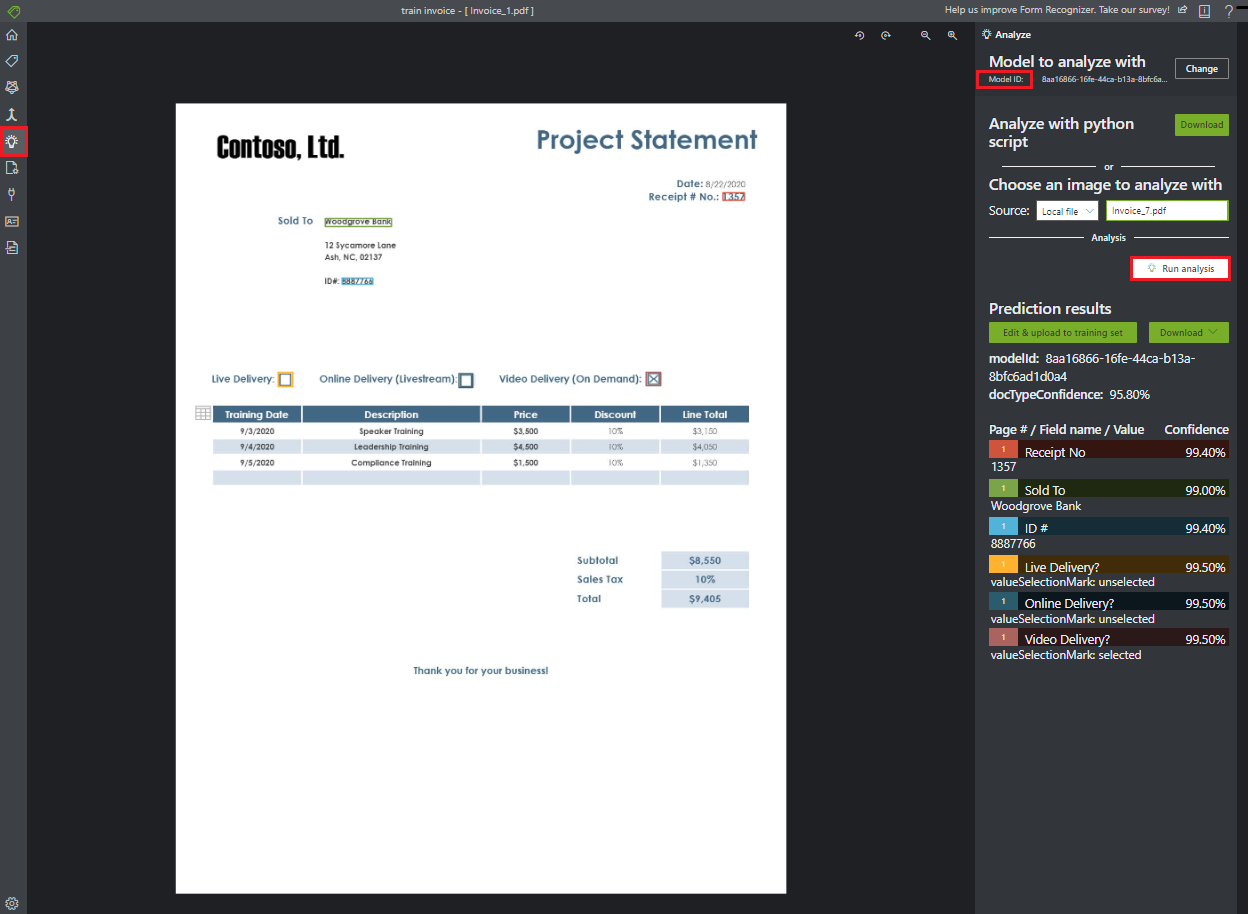
Analyser un formulaire
Sélectionnez l’icône Analyser dans la barre de navigation pour tester votre modèle. Sélectionnez la source Fichier local. Recherchez puis sélectionnez un fichier dans l’exemple de jeu de données que vous avez décompressez dans le dossier de test. Choisissez ensuite le bouton « Run analysis » (Exécuter l’analyse) pour obtenir des paires clé/valeur, du texte et des prédictions de tableaux pour le formulaire. L’outil applique des étiquettes dans les cadres englobants et indique la confiance en chaque étiquette.
Conseil
Vous pouvez également exécuter l’API Analyze (Analyser) avec un appel REST. Pour savoir comment procéder, consultez Effectuer un entraînement avec des étiquettes à l’aide de Python.
Améliorer les résultats
Selon la justesse signalée, vous souhaiterez peut-être effectuer d’autres entraînements pour améliorer le modèle. Une fois que vous avez effectué une prédiction, examinez les valeurs de confiance de chacune des étiquettes appliquées. Si la valeur d’entraînement de justesse moyenne est élevée, alors que les scores de confiance sont faibles (ou les résultats imprécis), ajoutez le fichier de prédiction au jeu d’entraînement, l’étiqueter et renouveler l’entraînement.
La justesse moyenne signalée, les scores de confiance et la justesse réelle peuvent être incohérents quand les documents analysés diffèrent de ceux utilisés lors de l’entraînement. N’oubliez pas que certains documents peuvent sembler similaires aux yeux de l’utilisateur, mais distincts du point de vue du modèle IA. Par exemple, vous pouvez effectuer l’entraînement avec un type de formulaire qui a deux variantes, où le jeu d’entraînement est constitué de 20 % de variante A et de 80 % de variante B. Au cours de la prédiction, les scores de confiance des documents de variante A sont susceptibles d’être inférieurs.
Enregistrer un projet et le reprendre plus tard
Pour reprendre votre projet à un autre moment ou dans un autre navigateur, vous devez enregistrer son jeton de sécurité et le retaper ultérieurement.
Récupérer les informations d’identification du projet
Accédez à la page des paramètres du projet (icône en forme de curseurs) et prenez note du nom du jeton de sécurité. Accédez ensuite aux paramètres d’application (icône en forme d’engrenage), où apparaissent tous les jetons de sécurité dans votre instance de navigateur actuelle. Recherchez le jeton de sécurité de votre projet et copiez son nom et sa valeur de clé en lieu sûr.
Restaurer les informations d’identification du projet
Quand vous souhaitez reprendre votre projet, vous devez d’abord créer une connexion au même conteneur de stockage d’objets blob. Pour ce faire, répétez les étapes. Ensuite, accédez à la page des paramètres de l’application (icône en forme d’engrenage) et vérifiez si le jeton de sécurité de votre projet y figure. Si ce n’est pas le cas, ajoutez un nouveau jeton de sécurité et copiez le nom et la clé de votre jeton obtenus à l’étape précédente. Sélectionnez Save pour conserver vos paramètres.
Reprendre un projet
Pour finir, accédez à la page principale (icône en forme de maison), puis sélectionnez Open Cloud Project (Ouvrir le projet cloud). Sélectionnez ensuite la connexion au stockage d’objets blob, puis le fichier .fott de votre projet. L’application charge tous les paramètres du projet, car ils contiennent le jeton de sécurité.
Étapes suivantes
Dans ce guide de démarrage rapide, vous avez appris à utiliser l’outil d’étiquetage des exemples Intelligence documentaire pour entraîner un modèle avec des données étiquetées manuellement. Si vous souhaitez créer votre propre utilitaire pour étiqueter des données d’apprentissage, utilisez les API REST dédiées à l’apprentissage de données étiquetées.