Antimodèle de persistance monolithique
Rassembler toutes les données d’une application dans un magasin de données unique peut nuire aux performances car cela provoque un conflit de ressources ou bien parce que le magasin de données n’est pas adapté à toutes les données.
Description du problème
Historiquement, les applications ont souvent utilisé un magasin de données unique, quels que soit les types de données qu’elles devaient stocker. Généralement, le but était de simplifier la conception de l’application, ou bien de s’adapter aux compétences de l’équipe de développement.
Les systèmes cloud modernes ont souvent des exigences fonctionnelles et non fonctionnelles supplémentaires et doivent stocker de nombreux types de données hétérogènes, tels que des documents, des images, des données mises en cache, des messages en attente, des journaux d’activité d’applications et des données de télémétrie. Suivre l’approche traditionnelle et placer toutes ces informations dans un même magasin de données peut nuire aux performances, principalement pour deux raisons :
- Stocker et récupérer de grandes quantités de données non liées dans le même magasin de données peut provoquer des conflits, conduisant à un ralentissement du temps de réponse et à des échecs de connexion.
- Quel que soit le magasin de données choisi, il est possible qu’il ne soit le plus adapté à tous les types de données, ou bien il peut ne pas être optimisé pour les opérations réalisées par l’application.
L’exemple suivant montre un contrôleur d’API Web ASP.NET qui ajoute un nouvel enregistrement à une base de données et enregistre également le résultat dans un journal. Le journal est conservé dans la même base de données que les données d’entreprise. Vous trouverez l’exemple complet ici.
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
La vitesse à laquelle les enregistrements de journal sont générés va probablement affecter les performances des opérations d’exploitation. Et si un autre composant, par exemple un moniteur de processus d’application, lit et traite régulièrement les données de journal, qui peuvent également affecter les opérations d’exploitation.
Comment corriger le problème
Séparez les données en fonction de leur utilisation. Pour chaque jeu de données, sélectionnez un magasin de données correspondant le mieux à leur future utilisation. Dans l’exemple précédent, l’application doit se connecter à un magasin distinct de la base de données contenant les données d’entreprise :
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
Considérations
Séparez les données selon leur accès et la manière dont elles sont utilisées. Par exemple, ne stockez pas des informations de journal et des données d’entreprise dans le même magasin de données. Ces types de données ont des exigences et des modèles d’accès considérablement différentes. Les enregistrements de journal sont séquentiels par nature, tandis que les données d’entreprise sont plus susceptibles de demander un accès aléatoire et sont souvent relationnelles.
Prenez en compte le modèle d’accès aux données pour chaque type de données. Par exemple, stockez les rapports et documents mis en forme dans une base de données de documents, telle que Azure Cosmos DB, mais utilisez le Azure Cache pour Redis pour mettre en cache les données temporaires.
Si vous suivez ces instructions mais que vous atteignez toujours les limites de la base de données, vous devez peut-être mettre à l’échelle la base de données. Envisagez également la mise à l’échelle horizontale et le partitionnement de la charge entre les serveurs de base de données. Toutefois, le partitionnement peut nécessiter une reconception de l’application. Pour plus d’informations, consultez Partitionnement des données.
Comment détecter le problème
Il est probable que le système ralentisse considérablement et échoue, car il manque de ressources, telles que les connexions de base de données.
Vous pouvez procédez de la manière suivante pour identifier la cause.
- Instrumentez le système pour enregistrer les statistiques de performance clés. Capturez les informations de minutage pour chaque opération, ainsi que les points où l’application lit et écrit des données.
- Si possible, surveillez le système en cours d’exécution pendant quelques jours dans un environnement de production pour obtenir une vision réelle de l’utilisation du système. Si ce n’est pas possible, exécutez des tests de charge scriptés avec un volume réaliste d’utilisateurs virtuels exécutant une série classique d’opérations.
- Utilisez les données de télémétrie pour identifier les périodes présentant des problèmes de performance.
- Identifiez les magasins de données consultés durant ces périodes.
- Identifiez les ressources de stockage de données pouvant rencontrer des problèmes de contention.
Exemple de diagnostic
Les sections suivantes appliquent ces étapes à l’exemple d’application décrit précédemment.
Instrumenter et surveiller le système
Le graphique suivant montre les résultats du test de charge de l’exemple d’application décrit précédemment. Le test a utilisé une charge d’étape allant jusqu'à 1 000 utilisateurs simultanés.
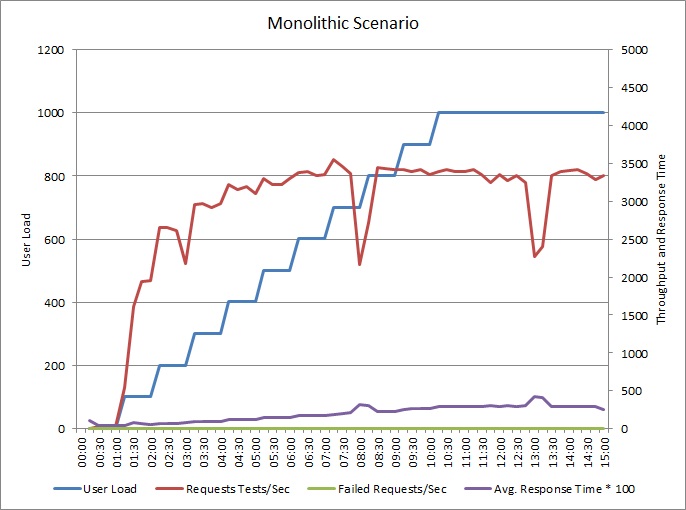
À mesure que la charge augmente jusqu’à 700 utilisateurs, le débit augmente également. À ce stade, sans considérer les niveaux de débit, le système semble être en cours d’exécution à sa capacité maximale. La réponse moyenne augmente progressivement avec une charge d’utilisateur, indiquant que le système ne peut pas suivre la demande.
Identifier les périodes présentant des problèmes de performance
Si vous surveillez le système de production, vous pouvez remarquer des modèles. Par exemple, les temps de réponse s’allonge de façon significative au même moment chaque jour. Cela peut être dû à une charge de travail normale ou à une tâche planifiée, ou simplement parce que le système accueille davantage d’utilisateurs à certains moments. Vous devriez vous concentrer sur les données de télémétrie de ces événements.
Recherchez des corrélations entre les temps de réponse allongés et l’augmentation de l’activité de la base de données ou des E/S vers des ressources partagées. S’il existe des corrélations, cela signifie que la base de données est susceptible d’être un goulot d’étranglement.
Identifier les magasins de données consultés durant ces périodes
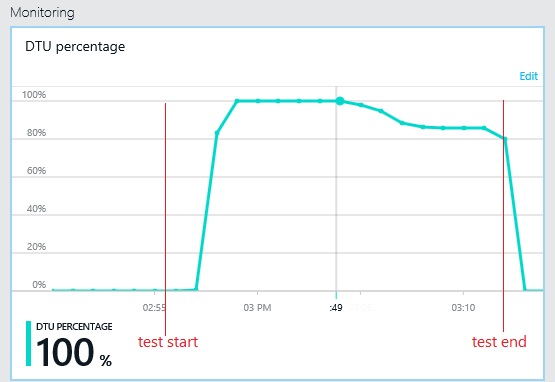
Le graphique suivant illustre l’utilisation des unités de débit de base de données (UDBD) pendant le test de charge. (Une UDBD est une mesure de la capacité disponible, et une combinaison de l’utilisation du processeur, de l’allocation de mémoire et du taux d’E/S.) L’utilisation des UDBD atteint rapidement 100 %. C’est à peu près le point où le débit a atteint un pic dans le graphique précédent. L’utilisation de la base de données est restée très élevée jusqu'à la fin du test. Il y a une légère baisse vers la fin, peut être due à la limitation, la concurrence pour les connexions de base de données ou d’autres facteurs.
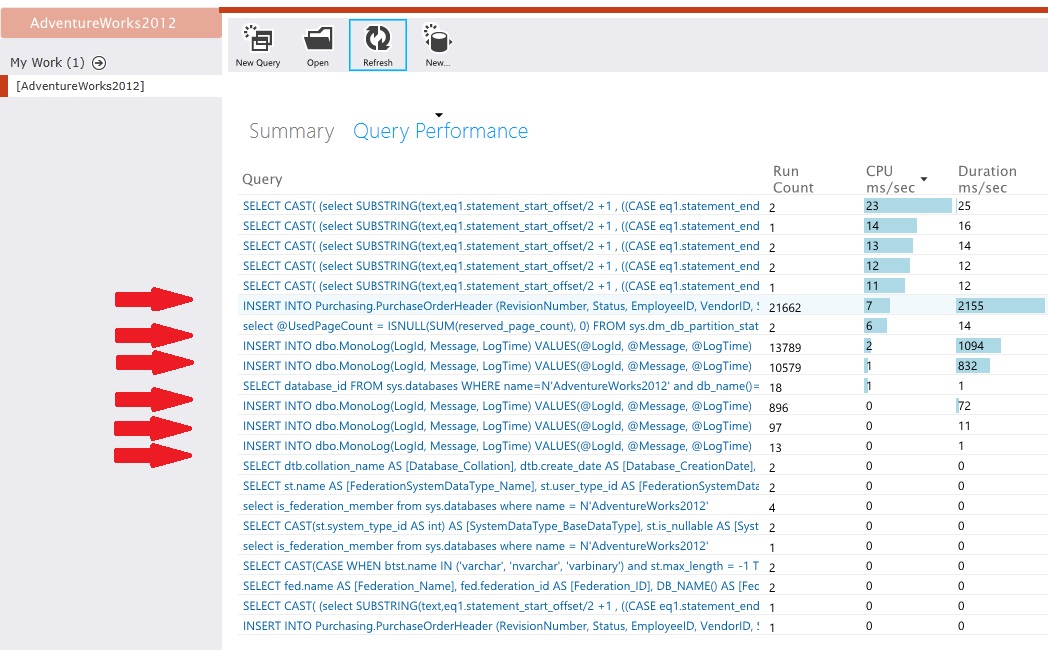
Examiner les données de télémétrie pour les magasins de données
Instrumentez les magasins de données pour capturer les détails de bas niveau de l’activité. Dans l’exemple d’application, les statistiques d’accès aux données ont montré un grand nombre d’opérations d’insertion effectuées sur les tables PurchaseOrderHeader et MonoLog.
Identifier les contentions de ressources
À ce stade, vous pouvez examiner le code source, en mettant l’accent sur les points où les ressources objets d’une contention sont accessibles par l’application. Recherchez des situations telles que :
- Des données logiquement séparées et écrites dans le même magasin. Des données telles que des journaux d’activité, rapports et messages en attente ne devraient pas être conservées dans la même base de données en tant qu’informations d’entreprise.
- Une incompatibilité entre le choix du magasin de données et le type de données, tels que des objets BLOB volumineux ou des documents XML dans une base de données relationnelle.
- Des données avec des modèles d’utilisation très différents qui partagent le même magasin, telles que des données d’écriture élevée-lecture basse stockées avec des données d’écriture basse-lecture élevée.
Implémenter la solution et vérifier le résultat
L’application a été modifiée pour écrire des journaux d’activité dans un magasin de données distinct. Voici les résultats des tests de charge :
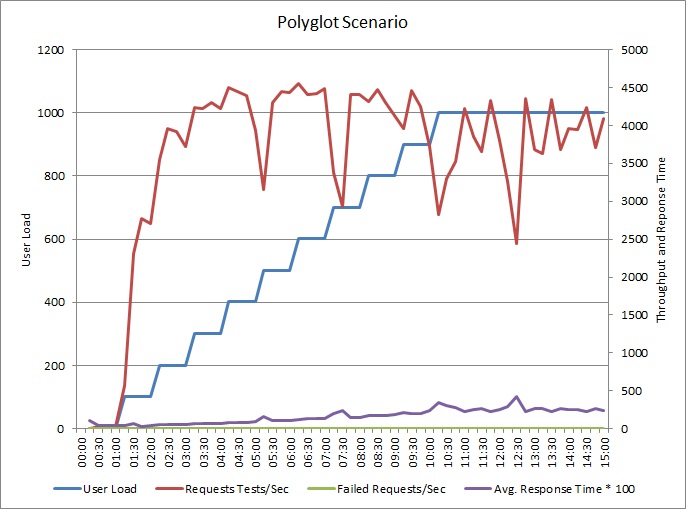
Le modèle de débit est similaire au graphique antérieur, mais le point du pic de performances est plus élevé d’environ 500 demandes par seconde. Le temps de réponse moyen est légèrement plus court. Toutefois, ces statistiques ne disent pas tout. Les données de télémétrie pour la base de données d’entreprise montrent que la UDBD a un pic d’utilisation à environ 75 %, au lieu de 100 %.
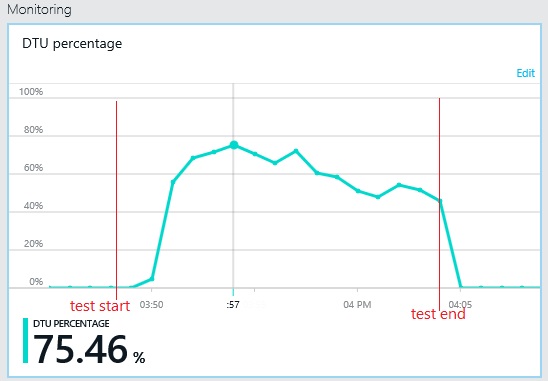
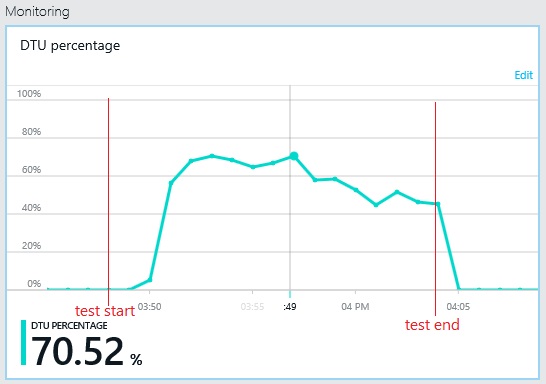
De même, l’utilisation maximale de la UDBD de la base de données de journaux n'atteint environ que 70 %. Les bases de données ne sont plus le facteur de limitation pour les performances du système.
Ressources associées
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour