Cet article contient une liste d’éléments à prendre en compte lors du déplacement d’une solution IoT vers un environnement de production.
Utiliser des empreintes de déploiement
Les empreintes sont des unités discrètes de composants de solution de base qui prennent en charge un nombre défini d’appareils. Chaque copie est appelée tampon. ou unité d'échelle. Par exemple, un tampon peut être constitué d’un remplissage d’appareil défini, d’un IoT Hub, d’un Event Hub ou d’un autre point de terminaison de routage et d’un composant de traitement. Chaque horodatage prend en charge un remplissage de périphérique défini. Vous choisissez le nombre maximal d’appareils que le tampon peut contenir. Au fur et à mesure que le nombre d’appareils augmente, vous ajoutez des instances de tampons plutôt que de mettre à l'échelle indépendamment différentes parties de la solution.
Si, au lieu d’ajouter des tampons, vous déplacez une seule instance de votre solution IoT en production, vous risquez de rencontrer les limitations suivantes :
Limites d’échelle : votre instance unique peut rencontrer des limites de mise à l’échelle. Par exemple, votre solution peut utiliser des services dotés de limites en termes de nombre de connexions entrantes, de noms d’hôtes, de sockets TCP ou d’autres ressources.
Mise à l'échelle ou coût non linéaire : certains composants de votre solution peuvent ne pas être mis à l’échelle de manière linéaire selon le nombre de requêtes ou la quantité de données. Pour certains composants, cependant, une baisse des performances ou une augmentation du coût une fois un seuil atteint peut se manifester. La montée en puissance avec davantage de capacité peut ne pas être aussi efficace que la mise à l’échelle par l’ajout de tampons.
Séparation des clients : vous devrez peut-être conserver de manière isolée certaines données clients des autres données clients. De même, certains clients peuvent nécessiter davantage de ressources système que d’autres, et envisager de les regrouper sur différents tampons.
Instances uniques et mutualisées : vous pouvez avoir pour clients de grandes entreprises qui ont besoin de leurs propres instances indépendantes de votre solution. Vous pouvez également avoir un pool de clients de plus petites entreprises qui peuvent partager un déploiement multilocataire.
Configuration requise pour le déploiement complexe : vous devrez peut-être déployer des mises à jour de votre service de manière contrôlée et les déployer sur des tampons différents à des moments différents.
Fréquence de mise à jour : certains de vos clients peuvent tolérer des mises à jour fréquentes de votre système, tandis que d’autres, sensibles au risque, peuvent souhaiter des mises à jour moins fréquentes de votre service.
Restrictions géographiques ou géopolitiques : pour réduire la latence ou respecter les exigences en matière de souveraineté des données, vous pouvez déployer certains de vos clients dans des régions spécifiques.
Pour éviter les problèmes précédents, envisagez de regrouper votre service dans plusieurs tampons. Les empreintes fonctionnent indépendamment les unes des autres et peuvent être déployées et mises à jour indépendamment. Une même région géographique peut contenir une, voire plusieurs empreintes pour permettre un scale-out horizontal dans la région. Chaque tampon contient un sous-ensemble de vos clients.
Utiliser la temporisation lorsqu’une erreur temporaire se produit
Toutes les applications qui communiquent avec des services à distance ou des ressources distantes doivent être sensibles aux erreurs temporaires. Cela est particulièrement vrai pour les applications exécutées dans le cloud, où la nature de l’environnement et la connectivité via Internet augmentent le risque de rencontrer ce type d’erreurs. Les erreurs temporaires sont les suivantes :
- Perte momentanée de la connectivité réseau aux composants et aux services
- Indisponibilité temporaire d’un service
- Délais d’attente survenant lorsqu’un service est occupé
- Collisions provoquées par la transmission simultanée des appareils
Ces erreurs se corrigent souvent d’elles-mêmes, et si l’action est répétée après un délai approprié, il est probable qu’elle aboutisse. Déterminer l’intervalle approprié entre les nouvelles tentatives est difficile cependant. Les stratégies classiques utilisent les types suivants d’intervalles avant nouvelles tentatives :
- Temporisation exponentielle. L’application attend un court délai avant la première nouvelle tentative, puis augmente l’intervalle de façon exponentielle entre chaque tentative suivante. Par exemple, elle peut retenter l’opération après 3 secondes, 12 secondes, 30 secondes et ainsi de suite.
- Intervalles réguliers. L’application attend le même laps de temps entre chaque tentative. Par exemple, elle peut retenter l’opération toutes les 3 secondes.
- Nouvelle tentative immédiate. Une erreur temporaire peut être courte, par exemple lorsqu’elle est causée par un événement tel qu’une collision de paquets réseau ou un pic dans un composant matériel. Dans ce cas, il est opportun de retenter l’opération immédiatement, car celle-ci peut aboutir si l’erreur a disparu le temps que l’application assemble et envoie la demande suivante. Cependant, il ne doit jamais y avoir plus d’une nouvelle tentative immédiate, et vous devez implémenter d’autres stratégies, telles que la temporisation exponentielle ou les actions de secours, en cas d’échec de la nouvelle tentative immédiate.
- Répartition aléatoire. Toutes les stratégies de nouvelle tentative précédentes peuvent inclure un élément de répartition aléatoire pour éviter que plusieurs instances du client effectuent les tentatives suivantes en même temps.
Évitez également les anti-modèles suivants :
- Les implémentations ne doivent pas inclure de couches dupliquées de code de nouvelle tentative.
- N’implémentez jamais de mécanisme de nouvelle tentative infini.
- N’effectuez jamais plus d’une nouvelle tentative immédiate.
- Évitez d’utiliser un intervalle de nouvelle tentative normal.
- Empêchez plusieurs instances du même client ou plusieurs instances de clients différents d’effectuer de nouvelles tentatives au même moment.
Utiliser un approvisionnement sans contact
L’approvisionnement consiste à inscrire un appareil dans Azure IoT Hub. L’approvisionnement informe IoT Hub de l’existence de l’appareil et du mécanisme d’attestation que l’appareil utilise. Vous pouvez utiliser le Service de provisionnement des appareils (DPS) Azure IoT Hub ou approvisionner directement via les API Registry Manager IoT Hub. L’utilisation de DPS offre l’avantage d’une liaison tardive, ce qui permet de supprimer et de réapprovisionner des appareils de champ pour IoT Hub sans modifier le logiciel de l’appareil.
L’exemple suivant montre comment implémenter un flux de travail de transition d’environnement de test en production à l’aide de DPS.
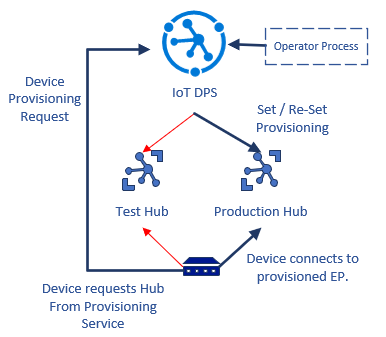
- Le développeur de solutions lie les clouds IoT de test et de production au service d’approvisionnement.
- L’appareil implémente le protocole DPS pour rechercher le hub IoT s’il n’est plus provisionné. L’appareil est initialement approvisionné dans l’environnement de test.
- L’appareil étant inscrit auprès de l’environnement de test, il se connecte à celui-ci et les tests sont effectués.
- Le développeur réapprovisionne l’appareil dans l’environnement de production et le supprime du hub de test. Le hub de test rejette l’appareil quand celui-ci se reconnecte.
- L’appareil se connecte et renégocie le processus d’approvisionnement. DPS dirige maintenant l’appareil vers l’environnement de production, et l’appareil se connecte et s’authentifie auprès de celui-ci.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Matthew Cosner | Principal Software Engineering Manager
- Ansley Yeo | Responsable de programme principal
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.