Décentralisez la logique du flux de travail et répartissez les responsabilités sur d’autres composants d’un système.
Contexte et problème
Une application cloud est souvent divisée en plusieurs petits services qui fonctionnent ensemble pour traiter une transaction commerciale de bout en bout. Même une seule opération métier (au sein d’une transaction) peut entraîner plusieurs appels point à point parmi tous les services. Dans l’idéal, ces services doivent être faiblement couplés. La conception d’un flux de travail distribué, efficace et évolutif est un véritable défi, car il implique souvent une communication interservices complexe.
Un modèle commun pour la communication consiste à utiliser un service centralisé ou un orchestrateur. Les requêtes entrantes passent par l’orchestrateur qui délègue les opérations aux services respectifs. Chacun d’entre eux s’acquitte de ses responsabilités sans prendre en compte le flux de travail global.
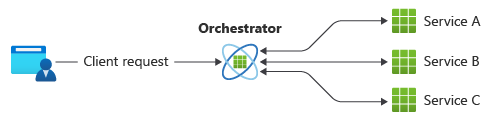
Le modèle d’orchestrateur est généralement implémenté sous la forme d’un logiciel personnalisé et possède une connaissance du domaine concernant les responsabilités de ces services. L’avantage est que l’orchestrateur peut consolider l’état d’une transaction en fonction des résultats des opérations individuelles réalisées par les services en aval.
Toutefois, il existe aussi des inconvénients. L’ajout ou la suppression de services risque de rompre la logique existante, parce qu’il faut reconnecter certaines parties du chemin de communication. Cette dépendance complique la mise en œuvre de l’orchestrateur ainsi que sa maintenance. Ce dernier peut avoir un impact négatif sur la fiabilité de la charge de travail. Sous charge, il peut générer des goulets d’étranglement en termes de performances et constituer le point de défaillance unique. Il peut également entraîner des défaillances en cascade dans les services en aval.
Solution
Déléguer la logique de gestion des transactions entre les services. Laisser chaque service décider et participer au workflow de communication pour une opération métier.
Le modèle est un moyen de réduire la dépendance vis-à-vis des logiciels personnalisés qui centralisent le workflow de communication. Les composants implémentent une logique commune en chorégraphiant le workflow entre eux sans être en communication directe les uns avec les autres.
Une façon courante d’implémenter la chorégraphie consiste à utiliser un répartiteur de messages qui met en mémoire tampon les requêtes jusqu’à ce que les composants en aval les réclament et les traitent. L’image montre la gestion des requêtes à travers un modèle éditeur-abonné.
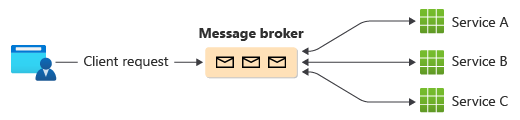
Les demandes d’un client sont mises en file d’attente sous forme de messages dans un répartiteur de messages.
Les services ou l’abonné interrogent le répartiteur pour déterminer s’ils peuvent traiter ce message en fonction de la logique métier qu’ils ont implémentée. Le répartiteur peut également envoyer des messages aux abonnés qui sont intéressés par ce message.
Chaque service abonné effectue son opération comme indiqué par le message et répond au répartiteur par une réussite ou un échec de l’opération.
En cas de réussite, le service peut envoyer un message à la même file d’attente ou à une file d’attente de messages différente pour qu’un autre service puisse continuer le flux de travail si nécessaire. Si l’opération échoue, le répartiteur de messages collabore avec d’autres services pour compenser cette opération ou l’ensemble de la transaction.
Problèmes et considérations
La décentralisation de l’orchestrateur peut provoquer des problèmes lors de la gestion du flux de travail.
La gestion des échecs peut relever du défi. Les composants d’une application peuvent effectuer des tâches atomiques, mais présenter tout de même un certain niveau de dépendance. La défaillance d’un composant peut avoir des répercussions sur les autres, ce qui peut entraîner des retards dans l’exécution de la requête globale.
Pour gérer correctement les défaillances, l’implémentation de transactions de compensation peut s’avérer complexe.
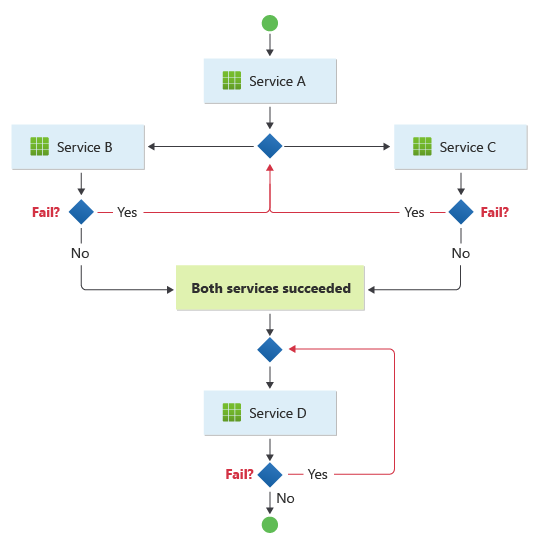
Le modèle convient à un workflow dans lequel des opérations métier indépendantes sont traitées en parallèle. Le workflow peut devenir compliqué lorsque la chorégraphie doit se produire dans une séquence. Par exemple, le service D peut démarrer son opération uniquement après que le service B et le service C ont terminé leurs opérations avec succès.
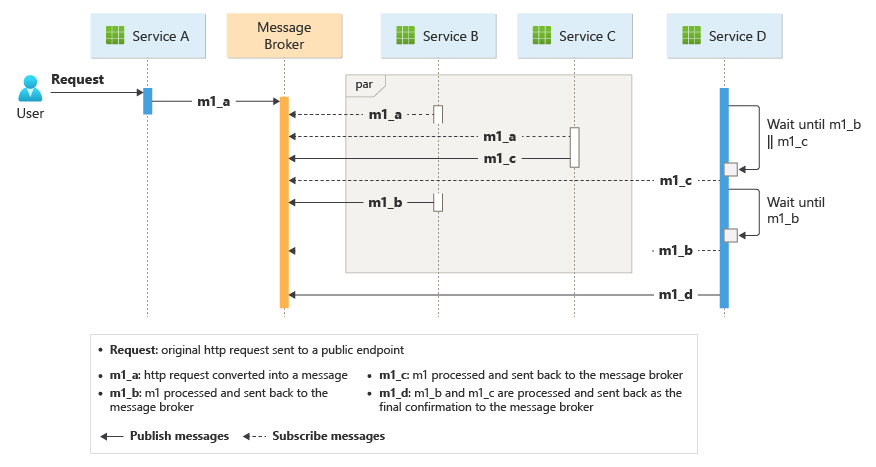
Le modèle pose un défi si le nombre de services augmente rapidement. Étant donné le nombre élevé de parties mobiles indépendantes, le flux de travail entre les services tend à se complexifier. En outre, le suivi distribué devient difficile.
Dans une conception pilotée par un orchestrateur, le composant central peut participer partiellement et déléguer la logique de résilience à un autre composant qui effectue de nouvelles tentatives pour les défaillances temporaires, non transitoires et de délais d’expiration, de manière cohérente. Avec la dissolution de l’orchestrateur dans le modèle de chorégraphie, les composants en aval ne doivent pas récupérer ces tâches de résilience. Celles-ci doivent toujours être gérées par le gestionnaire de résilience. Mais maintenant, les composants en aval doivent communiquer directement avec le gestionnaire de résilience, ce qui augmente la communication point à point.
Quand utiliser ce modèle
Utilisez ce modèle dans les situations suivantes :
Les composants en aval gèrent les opérations atomiques indépendamment. Considérez cela comme un mécanisme « fire and forget ». Un composant est responsable d’une tâche qui n’a pas besoin d’être gérée activement. Une fois la tâche accomplie, il envoie une notification aux autres composants.
Les composants sont censés être mis à jour et remplacés fréquemment. Le modèle permet de modifier plus facilement l’application et de réduire au minimum la perturbation des services existants.
Ce modèle s’adapte naturellement aux architectures sans serveur qui conviennent aux workflow simples. Les composants peuvent être à courte durée de vie et basés sur les événements. Lorsqu’un événement survient, les composants sont lancés, effectuent leurs tâches et sont supprimés une fois la tâche accomplie.
L’orchestrateur central crée un goulot d’étranglement en termes de performances.
Ce modèle peut ne pas avoir d’utilité dans les cas suivants :
L’application est complexe et nécessite un composant central capable de gérer une logique partagée afin de préserver la légèreté des composants en aval.
Dans certaines situations, la communication point à point entre les composants est inévitable.
Vous devez consolider toutes les opérations gérées par les composants en aval à l’aide de la logique métier.
Conception de la charge de travail
Un architecte doit évaluer la façon dont le modèle de chorégraphie peut être utilisé dans la conception de leurs charges de travail pour se conformer aux objectifs et principes abordés dans les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| L’excellence opérationnelle permet de fournir une qualité de charge de travail grâce à des processus standardisés et à la cohésion d’équipe. | Les composants distribués de ce modèle étant autonomes et conçus pour être remplaçables, il est possible de modifier la charge de travail en limitant les modifications globales du système. - OE :04 Outils et processus |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | Ce modèle offre une solution de rechange en cas de goulots d’étranglement des performances dans une topologie d’orchestration centralisée. - PE :02 Planification de la capacité - PE :05 Mise à l’échelle et partitionnement |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
Cet exemple montre le modèle de chorégraphie en créant une charge de travail native dans le cloud, pilotée par les événements, qui exécute des fonctions avec des microservices. Lorsqu’un client demande l’expédition d’un colis, la charge de travail affecte un drone. Une fois que le drone est prêt à récupérer le colis, le processus de livraison commence. Pendant le transit, la charge de travail gère la livraison jusqu’à ce que sont état soit « expédié ».
Cet exemple est une refactorisation de l'implémentation de livraison par drones qui remplace le modèle d'orchestrateur par celui de chorégraphie.
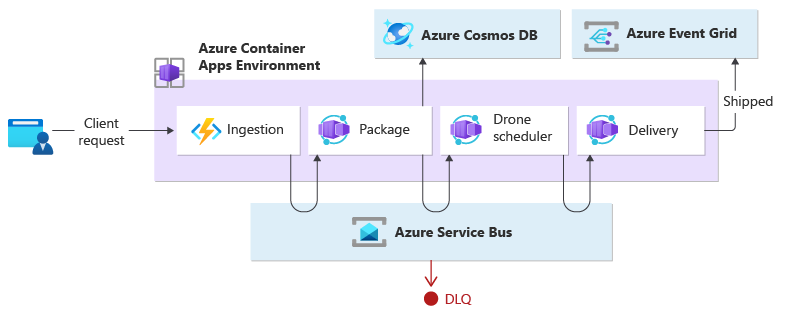
Le service d’ingestion gère les demandes du client et les convertit en messages, y compris les détails de livraison. Les transactions commerciales sont lancées une fois ces nouveaux messages consommés.
Une transaction commerciale pour un cliente unique requiert trois opérations commerciales distinctes :
- Créer ou mettre à jour un package
- Affecter un drone pour livrer le package
- Gérer la livraison, ce qui consiste à vérifier la marchandise et sensibiliser les personnes concernées lors de l’expédition.
Ces opérations sont effectuées par trois microservices : Colis, Planification des drones et Livraison. Au lieu d’un orchestrateur central, les services communiquent entre eux à l'aide d'un système de messagerie. Chaque service est chargé de mettre en œuvre en amont un protocole qui coordonne de manière décentralisée le flux de travail commercial.
Conception
La transaction commerciale est traitée dans une séquence par le biais de plusieurs tronçons. Chaque tronçon partage un seul bus de messages entre tous les services d’entreprise.
Lorsqu’un client envoie une demande de livraison via un point de terminaison HTTP, le service d'ingestion la reçoit et la convertit en message, qui est ensuite publié dans le bus de messages partagé. Les services d’entreprise abonnés consommeront les nouveaux messages ajoutés au bus. Lors de la réception du message, les services commerciaux peuvent terminer l’opération par une réussite, un échec ou une expiration du délai d’attente de la requête. En cas de réussite, les services répondent au bus avec le code d’état Ok, déclenchent un nouveau message d’opération et l’envoie au bus de messages du tronçon suivant. En cas d’échec ou d’expiration, le service signale l’échec en envoyant le code de motif au bus de messages. En outre, le message est ajouté à une file d’attente de lettres mortes. Les messages qui n’ont pas pu être reçus ou traités dans un délai raisonnable et approprié sont également déplacés vers la file d'attente des lettres mortes.
La conception utilise plusieurs bus de messages pour traiter l’ensemble de la transaction commerciale. Microsoft Azure Service Bus et Microsoft Azure Event Grid vous permettent de fournir la plateforme de service de messagerie pour cette conception. La charge de travail est déployée sur Azure Container Apps, qui héberge les fonctions Azure d’ingestion et les applications qui gèrent le traitement piloté par les événements qui exécute la logique commerciale.
Grâce à la conception, la chorégraphie se déroule dans une séquence. L'espace de noms Azure Service Bus unique contient une rubrique avec deux abonnements et une file d’attente prenant en compte les sessions. Le service d’ingestion publie des messages dans la rubrique. Le service Colis et le service de planification des drones s’abonnent à la rubrique et publient des messages qui communiquent le succès à la file d’attente. Inclure un identifiant de session commun, qui inclut un GUID associé à l'identifiant de livraison, permet de traiter de manière ordonnée les séquences non liées de messages connexes. Le service de livraison attend deux messages connexes par transaction. Le premier message indique que le colis est prêt à être expédié, et le deuxième signal qu’un drone est attribué.
Cette conception utilise Azure Service Bus pour gérer les messages à valeur élevée à ne pas perdre ni dupliquer pendant l’ensemble du processus de livraison. Lorsque le colis est expédié, l'état est modifié dans Azure Event Grid. Dans cette conception, l’expéditeur de l’événement n’a aucune attente quant à la façon dont le changement d’état est géré. Les services d’organisation en aval qui ne sont pas inclus dans le cadre de cette conception peuvent écouter ce type d’événement. Ils peuvent également réagir à l’exécution d’une logique d’objectif commercial spécifique (autrement dit, envoyer l’état de la commande livrée à l’utilisateur).
Si vous envisagez de le déployer dans un autre service de calcul, comme AKS, l'application du modèle pub-sub boilplate pourrait être mise en œuvre avec deux conteneurs dans le même pod. Un conteneur exécute l’ambassadeur qui interagit avec le bus de messages de votre choix, tandis que l’autre exécute la logique commerciale. L’approche avec deux conteneurs dans le même pod améliore les performances et la scalabilité. L’ambassadeur et le service commercial partagent le même réseau, ce qui permet une faible latence et un débit élevé.
Pour éviter les tentatives en cascade qui pourraient conduire à des efforts multiples, les services d’entreprise doivent immédiatement signaler les messages inacceptables. Il est possible d’enrichir ces messages à l’aide de codes de raison connus ou d’un code d’application défini, afin qu’il puisse être déplacé vers une file d’attente de lettres mortes. Envisagez de gérer les problèmes de cohérence qui implémentent Saga à partir de services en aval. Par exemple, un autre service pourrait traiter les messages en lettres mortes à des fins de remédiation uniquement en exécutant une transaction de compensation, de rétablissement ou de pivot.
Les services commerciaux sont idempotents pour s’assurer que les nouvelles tentatives n’entraînent pas la duplication des ressources. Par exemple, le service de package utilise des opérations upsert pour ajouter des données au magasin de données.
Ressources associées
Tenez compte de ces modèles dans votre conception pour la chorégraphie.
Modularisez le service commercial à l’aide du modèle de conception ambassadeur.
Implémentez le modèle de nivellement de charge basé sur une file d’attente pour gérer les pics de charge de travail.
Utilisez la messagerie distribuée asynchrone via le modèle éditeur-abonné.
Utilisez les transactions de compensation pour annuler une série d’opérations réussies en cas d’échec d’une ou de plusieurs opérations connexes.
Pour plus d’informations sur l’utilisation d’un courtier de messages dans une infrastructure de messagerie, consultez Options de messagerie asynchrone dans Azure.