Cet article décrit comment une équipe de développement a utilisé des métriques pour détecter des goulets d’étranglement et améliorer les performances d’un système distribué. L’article est basé sur des tests de charge réels que nous avons effectués pour un exemple d’application.
Cet article fait partie d’une série. Lisez la première partie ici.
Scénario : traiter un flux d’événements à l’aide d’Azure Functions.

Dans ce scénario, une flotte de drones envoie des données de position en temps réel à Azure IoT Hub. Une application Functions reçoit les événements, convertit les données en au format GeoJSON, et écrit les données transformées dans Azure Cosmos DB. Azure Cosmos DB offre une prise en charge native des données géospatiales, et les collections Azure Cosmos DB peuvent être indexées pour des requêtes spatiales efficaces. Par exemple, une application cliente peut interroger tous les drones se trouvant dans un rayon de 1 km autour d’un emplacement donné, ou rechercher tous les drones se trouvant à l’intérieur d’une zone donnée.
Ces exigences de traitement sont suffisamment simples pour ne pas nécessiter de moteur de traitement de flux à part entière. En particulier, le traitement ne joint pas de flux, n’agrège pas de données et ne traite pas de fenêtres de temps. Compte tenu de ces exigences, Azure Functions est une solution adaptée au traitement des messages. Azure Cosmos DB peut également opérer une mise à l’échelle pour prendre en charge un débit d’écriture très élevé.
Surveillance du débit
Ce scénario présente un défi intéressant en matière de performances. Le débit de données par appareil est connu, mais le nombre d’appareils risque de fluctuer. Pour ce scénario métier, les exigences de latence ne sont pas particulièrement strictes. La position signalée d’un drone ne doit avoir une précision que d’une minute. Cela dit, l’application de fonction doit suivre le taux d’ingestion moyen au fil du temps.
IoT Hub stocke les messages dans un flux de journal. Les messages entrants sont ajoutés à la fin du flux. Un lecteur du flux (dans ce cas, l’application de fonction) contrôle son propre taux de parcours du flux. Ce découplage des chemins de lecture et d’écriture rend IoT Hub très efficace, mais cela signifie également qu’un lecteur lent peut prendre du retard. Pour détecter une telle situation, l’équipe de développement a ajouté une métrique personnalisée pour mesurer le retard des messages. Cette métrique enregistre l’écart entre le moment où un message parvient au service IoT Hub et le moment où la fonction reçoit le message pour traitement.
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
La méthode TrackMetric écrit une métrique personnalisée dans Application Insights. Pour plus d’informations sur l’utilisation de TrackMetric à l’intérieur d’une fonction Azure, consultez Télémétrie personnalisée dans la fonction C#.
Si la fonction suit le volume des messages, cette métrique doit rester à un état stable faible. Une certaine latence étant inévitable, la valeur ne sera jamais égale à zéro. Toutefois, si la fonction prend du retard, l’écart entre le moment de mise en file d’attente et le moment du traitement commence à augmenter.
Test 1 : Ligne de base
Le premier test de charge a révélé un problème immédiat : l’application de fonction a reçu systématiquement des erreurs HTTP 429 d’Azure Cosmos DB, indiquant qu’Azure Cosmos DB limitait les demandes d’écriture.
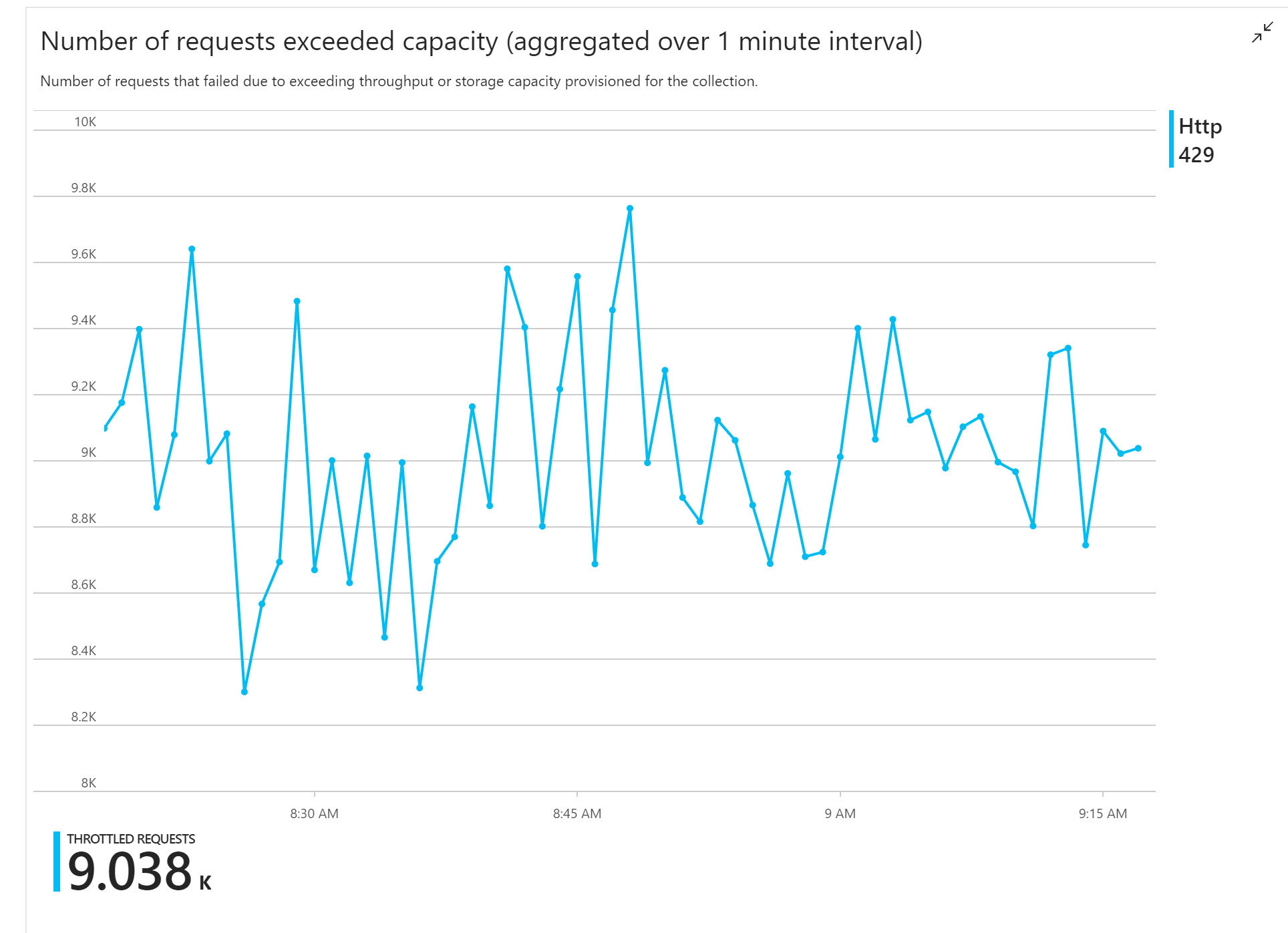
En réponse, l’équipe a mis à l’échelle Azure Cosmos DB en augmentant le nombre d’unités de requête allouées pour la collecte, mais les erreurs ont persisté. Cela semblait étrange, parce que leur calcul indiquait qu’Azure Cosmos DB n’aurait pas dû pas avoir de problème à suivre le volume des demandes d’écriture.
Plus tard dans la journée, l’un des développeurs a envoyé le message suivant à l’équipe :
J’ai examiné Azure Cosmos DB pour voir le chemin à chaud. Il y a une chose que je ne comprends pas. La clé de partition est deliveryId, mais nous n’envoyons pas de deliveryId à Azure Cosmos DB. Est-ce que quelque chose m’échappe ?
C’était l’indice. En examinant la carte thermique de partition, il s’est avéré que tous les documents atterrissaient sur la même partition.
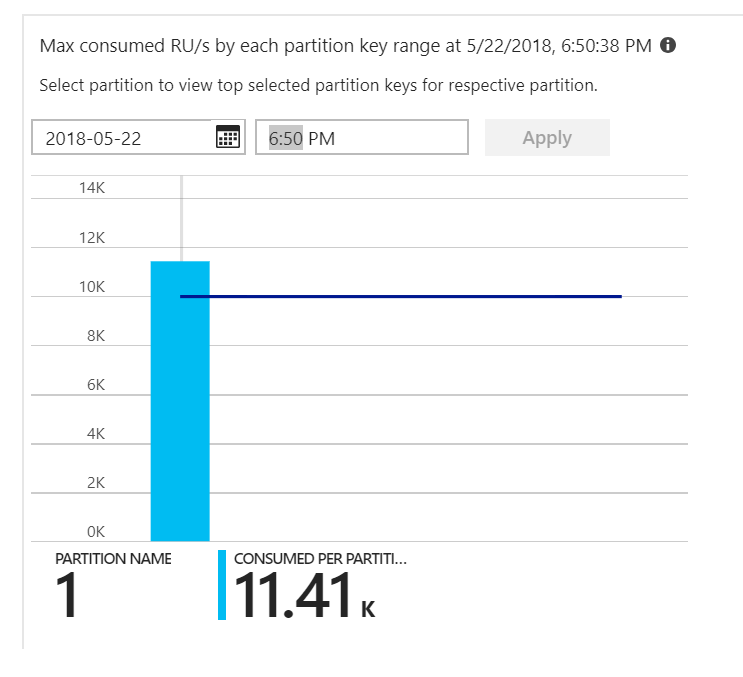
Ce que vous souhaitez voir dans la carte thermique, c’est une répartition uniforme sur toutes les partitions. Dans ce cas, étant donné que chaque document était écrit dans la même partition, l’ajout d’unités de requête n’a pas aidé. Il s’est avéré que le problème était dû à un bogue dans le code. Malgré le fait que la collecte d’Azure Cosmos DB avait une clé de partition, la fonction Azure n’incluait pas réellement la clé de partition dans le document. Pour plus d’informations sur la carte thermique de partition, consultez Déterminer la distribution du débit entre les partitions.
Test 2 : résoudre un problème de partitionnement
Lorsque l’équipe a déployé un correctif de code et réexécuté le test, Azure Cosmos DB a cessé de limiter. Pendant un certain temps, tout a semblé bien se passer. Mais à une certaine charge, la télémétrie a montré que la fonction écrivait moins de documents qu’elle n’aurait dû. Le graphique suivant montre les messages reçus d’IoT Hub et les documents écrits dans Azure Cosmos DB. La ligne jaune indique le nombre de messages reçus par lot et la ligne verte le nombre de documents écrits par lot. Ces nombres doivent être proportionnels. Au lieu de cela, le nombre d’opérations d’écriture dans la base de données par lot chute considérablement à environ 07:30.
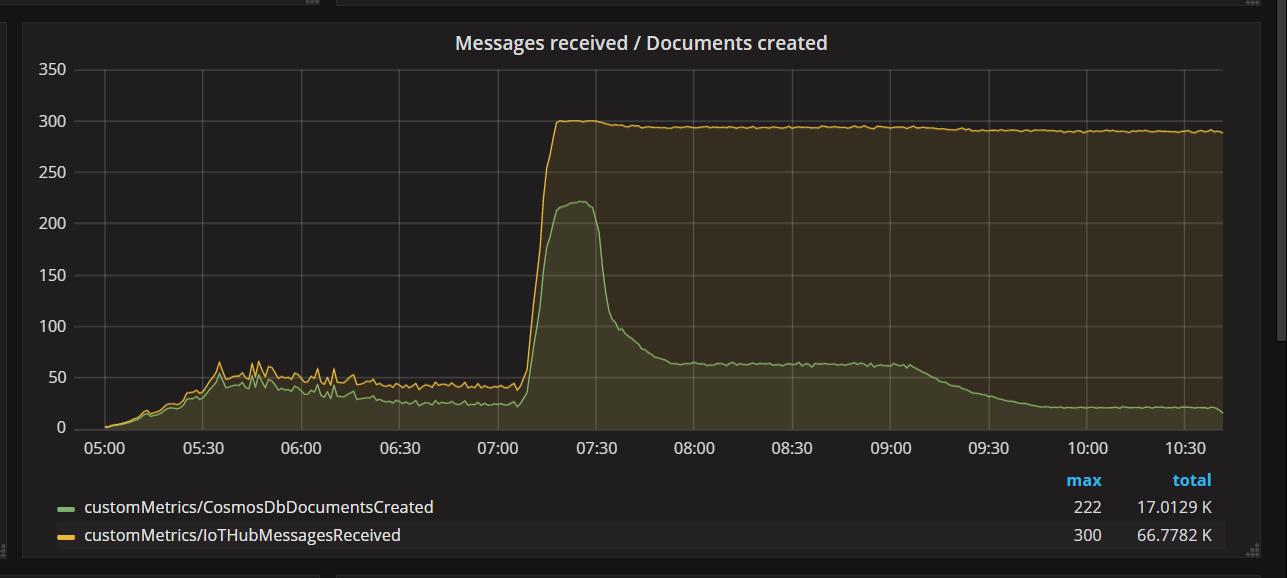
Le graphique suivant montre la latence entre le moment où un message parvient à IoT Hub en provenance d’un appareil, et le moment où l’application de fonction traite ce message. Vous pouvez voir qu’au même moment, les retards augmentent considérablement, se stabilisent et diminuent.
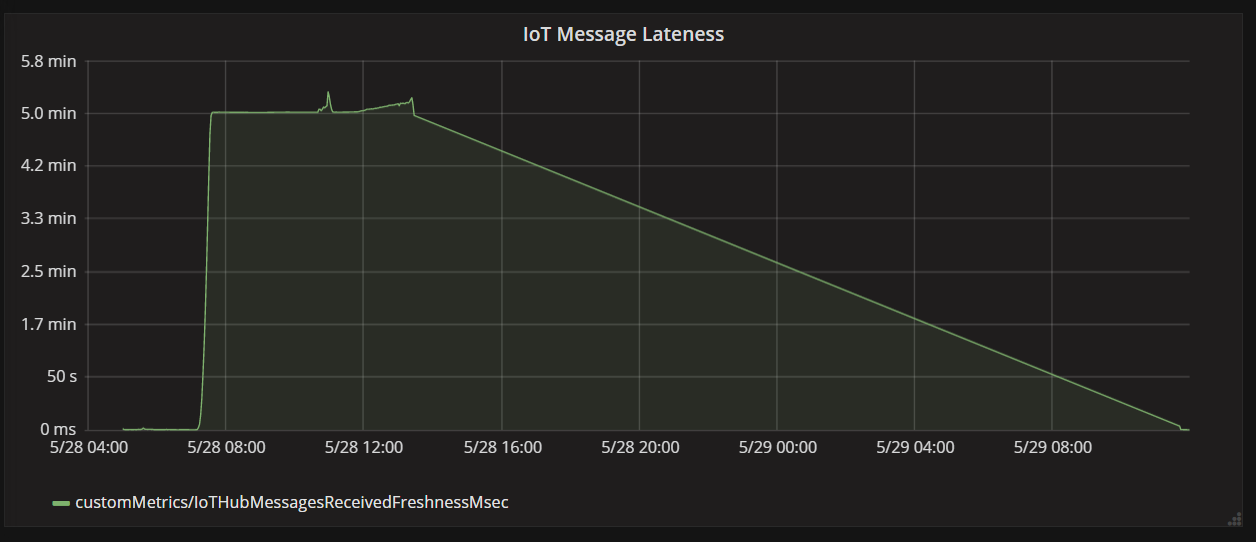
La raison est que la valeur culmine à 5 minutes, puis chute à zéro parce que l’application de fonction ignore les messages qui sont en retard de plus de 5 minutes :
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
Vous pouvez voir cela dans le graphique lorsque la métrique de retard retombe à zéro. En attendant, des données ont été perdues parce que la fonction rejetait des messages.
Que s’est-il passé ? Pour ce test de charge particulier, la collecte d’Azure Cosmos DB avait des unités de requête à économiser, de sorte que le goulet d’étranglement ne se situait pas au niveau de la base de données. Au lieu de cela, le problème se situait dans la boucle de traitement des messages. En bref, la fonction n’écrivait pas les documents assez rapidement pour suivre le volume des messages entrants. Au fil du temps, elle a pris beaucoup de retard.
Test 3 : écritures parallèles
Si le temps de traitement d’un message est la cause du goulet d’étranglement, une solution consiste à traiter plus de messages en parallèle. Dans ce scénario :
- Augmentez le nombre de partitions d’IoT Hub. Chaque partition d’IoT Hub se voit assigner une instance de fonction à la fois. Par conséquent, le débit devrait s’adapter de façon linéaire au nombre de partitions.
- Paralléliser les écritures du document dans la fonction.
Pour explorer la deuxième option, l’équipe a modifié la fonction pour prendre en charge les écritures parallèles. La version d’origine de la fonction utilisait la liaison de sortie d’Azure Cosmos DB. La version optimisée appelle directement le client Azure Cosmos DB et effectue les écritures en parallèle à l’aide de Task.WhenAll :
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
Notez que des conditions de concurrence sont possibles avec cette approche. Supposons que deux messages du même drone arrivent dans le même lot de messages. Avec une écriture en parallèle, le message plus précoce pourrait remplacer le message plus tardif. Pour ce scénario particulier, l’application peut tolérer la perte d’un message occasionnel. Les drones envoient les données de nouvelle position toutes les 5 secondes afin que les données dans Azure Cosmos DB soient continuellement mises à jour. Toutefois, dans d’autres scénarios, il peut être important de traiter les messages strictement dans l’ordre.
Après le déploiement de ce changement de code, l’application pouvait ingérer plus de 2 500 demandes par seconde, en utilisant un IoT Hub avec 32 partitions.
Considérations côté client
L’expérience globale du client risque d’être dégradée par une parallélisation agressive côté serveur. Envisagez d’utiliser la bibliothèque d’exécuteurs en bloc d’Azure Cosmos DB (non illustrée dans cette implémentation), ce qui réduit considérablement les ressources de calcul côté client nécessaires pour saturer le débit alloué à un conteneur Azure Cosmos DB. Une application monothread qui écrit des données à l’aide de l’API d’importation en bloc atteint un débit d’écriture 10 fois supérieur à celui d’une application multithread qui écrit des données en parallèle tout en saturant l’UC de l’ordinateur client.
Résumé
Pour ce scénario, les goulets d’étranglement suivants ont été identifiés :
- Partition d’écriture à chaud, en raison d’une valeur de clé de partition manquante dans les documents écrits.
- Écriture de documents en série par partition d’IoT Hub.
Pour diagnostiquer ces problèmes, l’équipe de développement s’est appuyée sur les mesures suivantes :
- Requêtes limitées dans Azure Cosmos DB.
- Carte thermique de partition et nombre maximal d’unités de requête consommées par partition.
- Messages reçus et documents créés.
- Retard des messages.
Étapes suivantes
Consultez Anti-modèles de performance